- The paper introduces the SA-FARI dataset, providing large-scale, dense, and manually verified segmentation masks for multi-animal tracking in wild settings.
- The paper demonstrates rigorous benchmarking using modern vision-language segmentation models, yielding significant improvements in metrics like pHOTA and ℓ1.
- The paper underlines the dataset's broad taxonomic diversity and ecological realism, pushing the frontier for robust, real-world conservation monitoring.
The SA-FARI Dataset: A New Benchmark for Multi-Animal Tracking in the Wild
Introduction
The SA-FARI dataset represents a significant milestone in the development of resources for multi-animal tracking (MAT) in unconstrained wildlife settings. Addressing a recurring limitation in current benchmarks—namely, their restricted scale, taxonomic breadth, ecological diversity, or annotation quality—SA-FARI provides large-scale, dense, and manually verified spatio-temporal segmentations for 99 animal species categories across 11,609 camera trap videos, sourced from 741 independent sampling sites on four continents over a ten-year period. This essay provides an in-depth analysis of the dataset's structure, methodological contributions, benchmarking results, and the broader implications for computer vision-based biodiversity monitoring.

Figure 1: Overview of the SA-FARI dataset, including global site distribution, species coverage, and dense manual annotation workflow.
Dataset Composition and Annotation Protocol
SA-FARI aggregates video data from various ecological projects, yielding over 46 hours of annotated footage capturing highly heterogeneous real-world scenarios: multi-animal scenes, frequent occlusions, dynamic behavior, diurnal and nocturnal conditions, a range of animal sizes, and partial/camouflaged views.
Each video is labeled exhaustively with species identities, date, time, and site metadata. An expert-driven protocol—initiated by automatic segmentation using SAM 3 and followed by multi-stage human verification and correction—produces high-fidelity segmentation masks (masklets) for every individual animal. The resulting 16,224 masklets are organized into train/test splits that maximize both taxonomic and site diversity with strict non-overlap to ensure robust benchmarking.
SA-FARI’s taxonomic breadth surpasses all prior MAT datasets, spanning most orders of Mammalia, substantial Aves representation, and notable inclusion of Reptilia and Amphibia. Its distribution exhibits marked long-tailed properties characteristic of natural settings: a small number of species dominate the sample count, while many rare species or open-set categories are only present in the test partition.
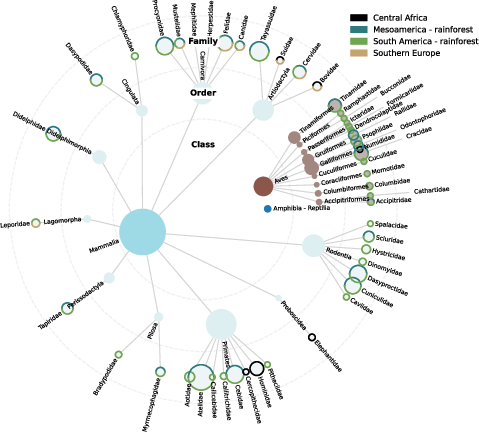
Figure 2: Visualization of taxonomic and geographic diversity within SA-FARI, highlighting abundance across major animal lineages and continents.
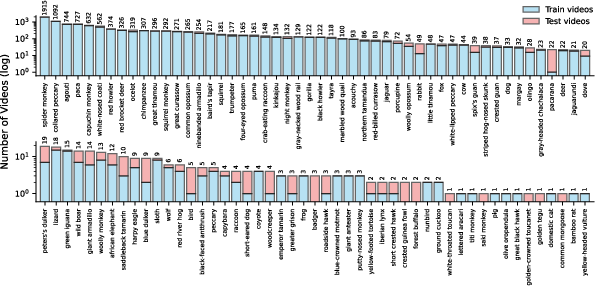
Figure 3: Species category distributions reveal the long-tailed structure typical of real-world eco-acoustic data, crucial for evaluating open-set model generalization.
The train/test split design further partitions the test set into challenging, night, multi-masklet, large-masklet, and small-masklet subsets, supporting granular model diagnostics across ecological and perceptual axes.
Comparative Dataset Features
SA-FARI is unique among animal tracking datasets for its combination of:
- Scale: 11,609 videos, 741 sites, and nearly one million frame-level mask annotations.
- Diversity: 99 annotated species categories, covering broad taxonomic groups and ecological zones.
- Annotation Quality: All segmentation masks are manually reviewed, far exceeding earlier datasets that rely on noisy automated masks or bounding boxes alone.
- Ecological Validity: Videos are sourced from in-situ camera traps, not online media or captive settings, maximizing real-world relevance and generalizability.
Compared to existing datasets such as AnimalTrack, GMOT, and specialized UAV collections, SA-FARI is at least 5× larger in total duration, covers over 2× as many animal categories, and uniquely combines multi-region, multi-habitat, and multi-species properties with exhaustive mask-based identity tracking.
Benchmarking and Model Evaluation
SA-FARI's utility for advancing MAT systems is demonstrated through extensive benchmarking. Evaluated models fall into two primary categories: modern vision-language promptable segmentation systems (e.g., SAM 3, GLEE, LLMDet) and traditional vision-only detection/tracking pipelines (e.g., MegaDetector + ByteTrack/OCSort/BoostSort++).
Species-Specific Prompting: When evaluated under the open-vocabulary, species-specific prompt setting using the Phrase-based HOTA (pHOTA), TETA, and classification-gated F1 (ℓ1) metrics, SAM 3—especially when fine-tuned on SA-FARI—substantially outperforms competitors, showing a +32.9 improvement on ℓ1, +19.6 on TETA, and +19.1 on pHOTA relative to its standard baseline. Absolute scores show high mask and association accuracy and sharply improved generalization to challenging, rare, and occluded scenarios.
Species-Agnostic Detection: Using generic "animal" prompts, SAM 3 (SA-FARI) again dominates, with a +23.9 IDF1 and +18.9 HOTA margin over its closest vision-only competitors.
Analytical Insights from Subset Evaluations
Analysis across labeled subsets reveals several diagnostic insights:
- Small-object tracking remains the most challenging case for all models; large-masklet videos yield pHOTA scores +29.2 higher than small-masklet samples.
- Occlusion and movement further degrade association metrics; the challenging subset shows a −9.3 pHOTA-Ass drop relative to average.
- Multi-animal scenes are moderately more difficult, but the effect is mitigated by their correlation with larger, more salient masklets.
- Nighttime sequences induce a modest performance decline, but high annotation quality and exhaustive test set labeling prevent significant metric collapse.
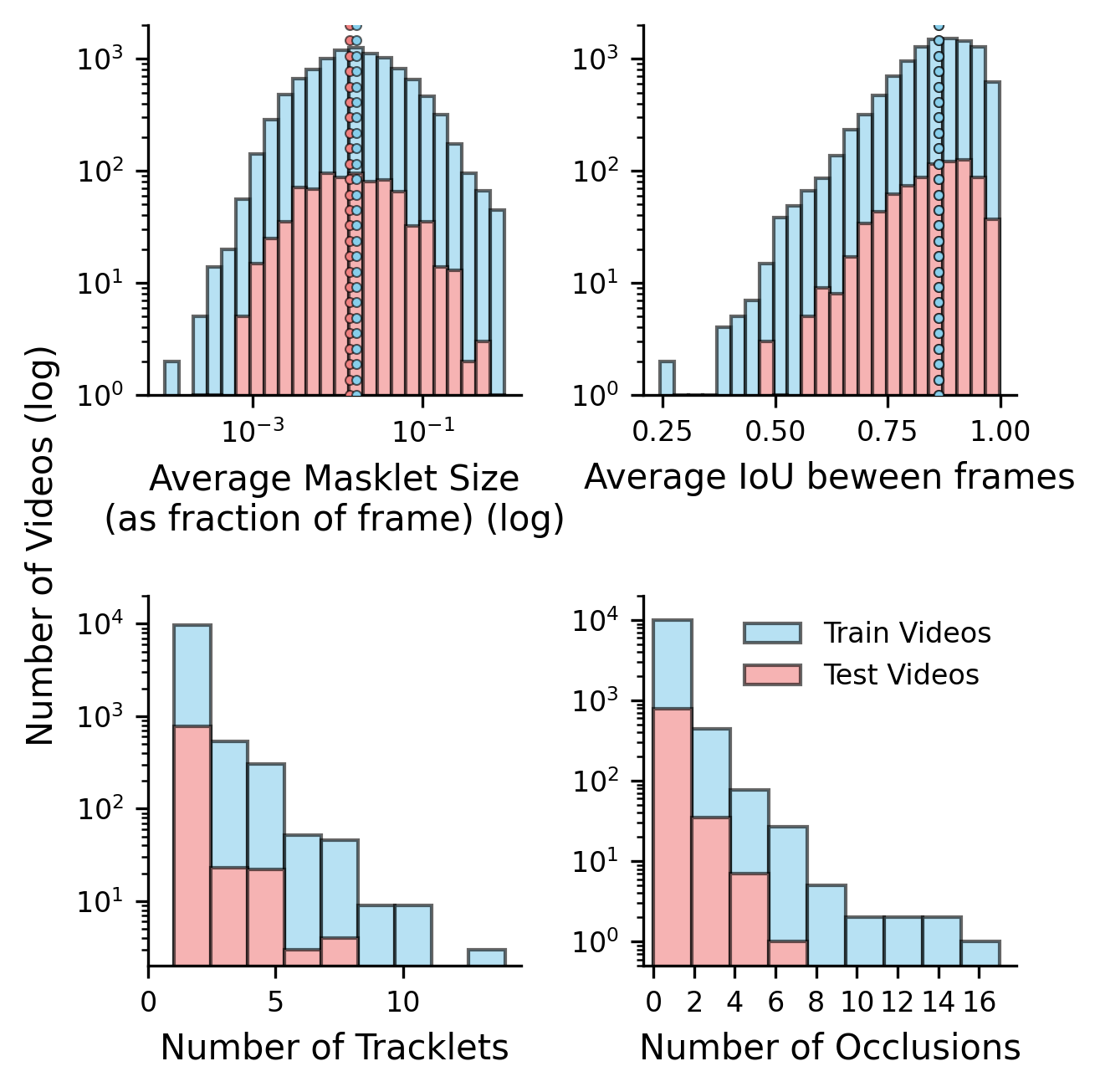
Figure 4: Distribution of key masklet-level metrics (size, IoU, occlusion) reveals the broad difficulty spectrum and supports detailed model evaluation.

Figure 5: Representative samples illustrate annotation density and scene complexity, including occlusions, re-identification, large groups, and heavily camouflaged instances.
Implications, Limitations, and Future Prospects
SA-FARI provides a pivotal resource for the training and rigorous evaluation of next-generation MAT systems, especially those seeking to operate in open-world, open-taxonomy ecological monitoring contexts. The demonstrated gains in state-of-the-art models confirm that current approaches underperform substantially on unconstrained data when deprived of diverse, high-quality supervision—SA-FARI directly enables robust improvements and realistic OOD performance measurement.
Nonetheless, the dataset is constrained by its current ecoregional coverage—additional biomes and underrepresented taxa (especially non-mammalian vertebrates and invertebrates) remain relevant expansion targets. While the annotation pipeline is exhaustive for visual data, accompanying audio channels, as well as animal pose, depth, and behavioral descriptors, remain untapped, presenting opportunities for future multi-modal model development.
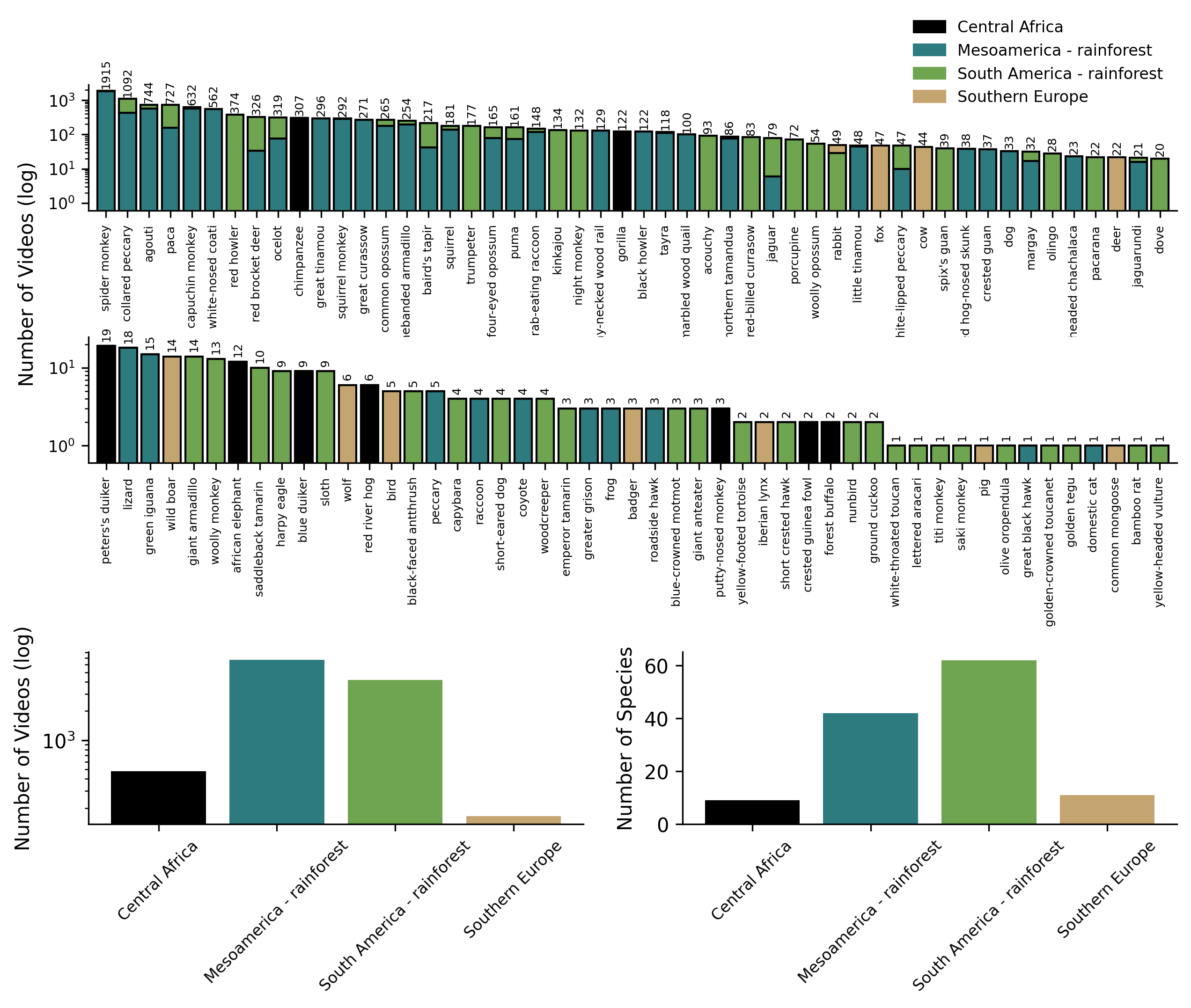
Figure 6: Video and species distribution across SA-FARI ecoregions emphasizes sampling breadth and site redundancy prevention.
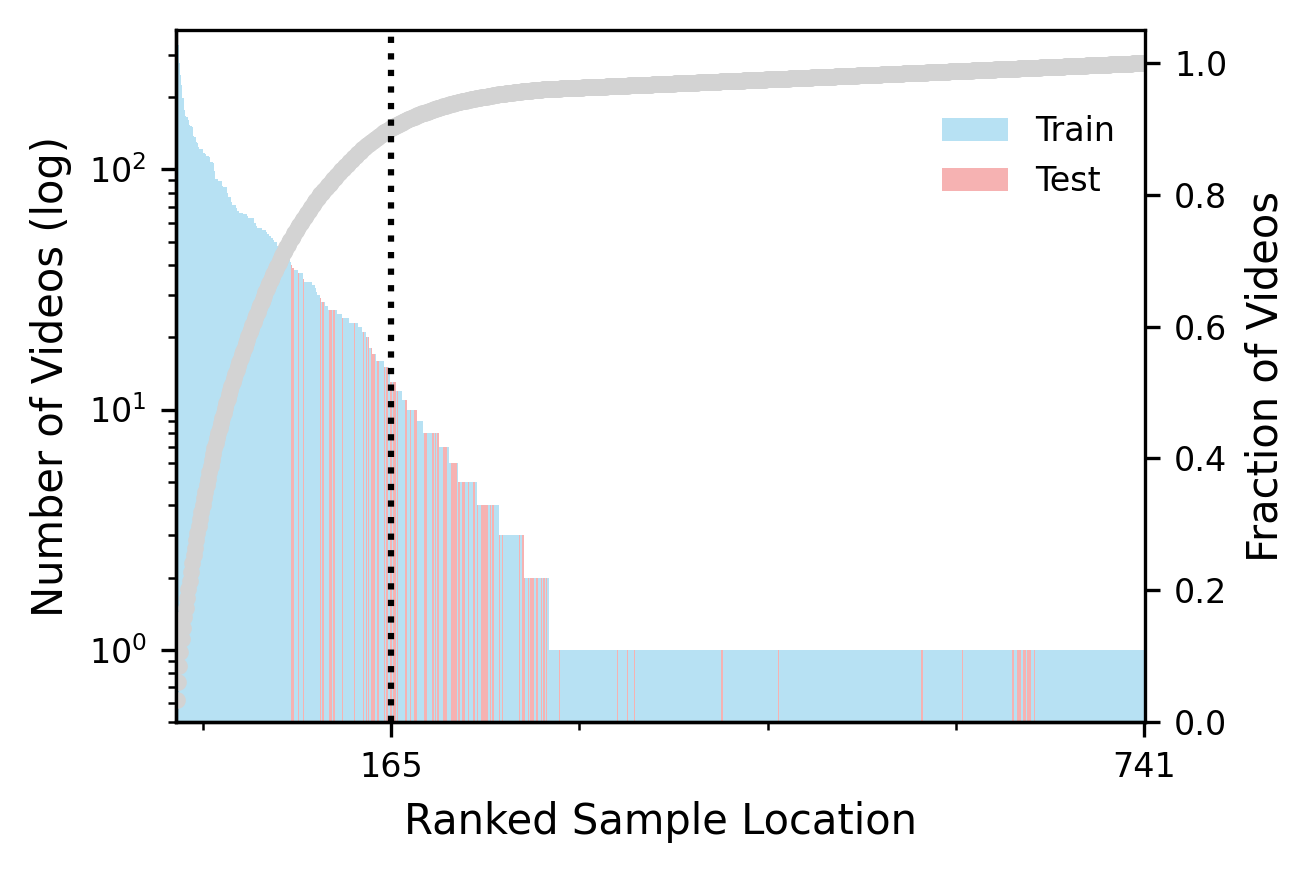
Figure 7: Ranked visualization of video contributions per sampling location, indicating strong geographic dispersion and split integrity.
Conclusion
SA-FARI establishes a new standard in open-source MAT datasets for wildlife computer vision, setting benchmarks with unprecedented scale, annotation rigor, taxonomic breadth, and ecological realism. It underlines the critical need for diverse, expertly validated training data to close the gap between laboratory metrics and real-world deployment in conservation technology. As the field advances, further integration of underrepresented regions, multi-modal signals, and fine-grained behavioral annotation—alongside synthetic and semi-automatic augmentation strategies—will be instrumental in constructing truly generalizable AI for large-scale biodiversity monitoring.