A Primer on Quantum Machine Learning
Abstract: Quantum machine learning (QML) is a computational paradigm that seeks to apply quantum-mechanical resources to solve learning problems. As such, the goal of this framework is to leverage quantum processors to tackle optimization, supervised, unsupervised and reinforcement learning, and generative modeling-among other tasks-more efficiently than classical models. Here we offer a high level overview of QML, focusing on settings where the quantum device is the primary learning or data generating unit. We outline the field's tensions between practicality and guarantees, access models and speedups, and classical baselines and claimed quantum advantages-flagging where evidence is strong, where it is conditional or still lacking, and where open questions remain. By shedding light on these nuances and debates, we aim to provide a friendly map of the QML landscape so that the reader can judge when-and under what assumptions-quantum approaches may offer real benefits.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper gives a friendly, big-picture tour of quantum machine learning (QML). QML tries to use quantum computers—special machines that follow the rules of quantum physics—to help with learning tasks like classification, clustering, optimization, reinforcement learning, and making new data (generative modeling). The authors explain where QML might help, where it probably won’t, and what we still don’t know. Their goal is to help readers judge when quantum approaches might offer real benefits and under what assumptions.
Key Questions
The paper looks at a few simple but important questions:
- When and why could a quantum computer learn better or faster than a classical (normal) computer?
- What kinds of data are best suited for QML (classical data vs. data that’s naturally quantum, like states from physics experiments)?
- How should we fairly compare classical and quantum learning methods?
- Which claimed “quantum speedups” are solid, which depend on special conditions, and which disappear when examined closely?
- What open problems remain, and where should future research focus?
How the Paper Approaches the Topic
The authors explain QML using everyday ideas from machine learning and then show how those ideas translate to the quantum world.
Learning, simply explained
- In machine learning, we learn “rules” from examples rather than writing rules by hand. For instance, we feed a program many labeled pictures of cats and dogs, and it learns to tell them apart.
- Two key pieces:
- The model family (hypothesis class): the kinds of rules the learner is allowed to consider (e.g., linear separators, neural networks).
- The training process: how the learner adjusts its rule using a loss function (a score for how wrong it is) and aims to do well not just on the training data but also on new, unseen data (this is called generalization).
A common theoretical framework is PAC learning (“probably approximately correct”), which asks: with how many examples can we learn a rule that is “good enough” with high probability? This connects model complexity, sample size, and how confident we are in the results.
A simple toy task and classical solutions
The paper uses a one-dimensional example: numbers between −π and π belong to class 0 in the middle interval and class 1 in the two outer intervals. This is NOT linearly separable in 1D (no single cut splits the classes perfectly).
Classical fixes:
- Feature maps: transform the input into a higher-dimensional space (e.g., use both x and x²) so a straight-line separator becomes possible there.
- Kernels and SVMs: use a “similarity function” (kernel) so you don’t have to explicitly build the higher-dimensional features. An SVM then finds a separating boundary using that kernel.
- Neural networks (NNs): learn both the useful features and the decision rule end-to-end. Even tiny NNs can solve the toy problem; bigger/deeper ones can approximate very complex functions. Training can be tricky (non-convex loss surfaces), but NNs are powerful.
Quantum versions of those ideas
To bring quantum into learning, the paper explains several building blocks:
- Embedding classical data into quantum states: map inputs (like real vectors or bitstrings) to quantum states using different strategies (e.g., angle-rotation encodings or amplitude encodings). This places data into a larger “stage” (Hilbert space), where new kinds of patterns may be easier to separate.
- Quantum kernel methods: compute quantum similarities between embedded states (for example, the overlap between two quantum states), then train a classical SVM using that quantum Gram matrix. Estimating these overlaps can be done with circuits like the SWAP test. Any advantage here comes from either richer embeddings or from similarities that a classical computer can’t efficiently replicate.
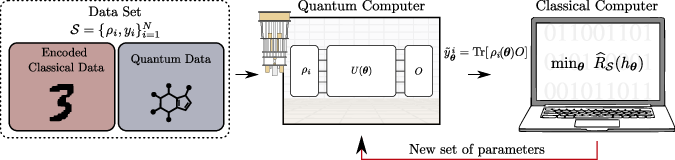
- Variational QML (hybrid approach): use a parametrized quantum circuit (often called a quantum neural network, QNN) as the model and a classical optimizer to tune its parameters by minimizing a loss. You repeatedly: 1) Prepare/encode data on the quantum device, 2) Run a QNN with adjustable gates, 3) Measure an output (an expectation value), 4) Update parameters on a classical computer, 5) Repeat until the loss is small.
Important practical details:
- Measurements are noisy: you estimate expectation values by repeating the circuit many times (“shots”) and averaging, so more shots give better estimates.
- Quantum data has limits: you can’t freely copy unknown quantum states (no-cloning), so the number of available copies (“copy complexity”) matters.
- The embedding design matters a lot: poor choices can make kernels nearly diagonal (no shared structure), or make reduced states uninformative, hurting generalization.
Main Findings and Why They Matter
This is a review, so the “results” are a careful map of the field rather than a single new experiment. The key messages:
- Strong promise for quantum data: QML has already helped extract more information from quantum experiments and predict measurement outcomes with fewer resources in some cases. If the data is genuinely quantum, QML can be a natural fit.
- Mixed evidence for classical data: while there are many promising heuristics, there are also “no-go” results and trainability challenges. Some claimed quantum speedups for practical tasks have been “dequantized,” meaning classical algorithms were found that match the performance once you account for how data is accessed.
- Assumptions matter: how you access data (classical samples, special oracles, superpositions over datasets) can make or break advantages. Many speedups appear only under specific data-access models that may be hard to realize in practice.
- Inductive bias comes from the embedding: in kernel methods, the learner is classical, so any edge comes from the quantum feature map. If the embedding doesn’t match the structure of the data, performance suffers.
- Variational QML is flexible but faces real-world hurdles: it’s the most popular approach for today’s noisy devices and has seen successes, but optimization can be hard, measurements add noise, and certain architectures may not train well in practice.
Together, these points highlight both the excitement and the caution around QML: it’s powerful in the right settings, but claims must be backed by clear assumptions and fair baselines.
Implications and Potential Impact
- Near-term use: Hybrid, variational QML is likely the most practical path on current hardware. It can complement classical ML, especially in problems tied to quantum physics, chemistry, and materials where data is truly quantum.
- Long-term vision: As quantum hardware improves, QML may unlock new learning regimes and speedups that are hard or impossible classically, especially for tasks involving quantum states, processes, and simulations.
- What to watch:
- Better embeddings and kernels tailored to real data.
- Clear benchmarking against strong classical baselines.
- Honest accounting of data-access assumptions.
- Methods that reduce shot-noise costs and improve trainability.
- Bottom line: QML is promising, especially for quantum-native problems, but it’s not a universal upgrade for all ML. Knowing when and why quantum helps is the key—and this paper helps map that path.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps, limitations, and open questions the paper leaves unresolved, intended to guide future research:
- Data-access realism and standardization
- Lack of a standardized, transparent framework to specify data-access assumptions (classical vs. quantum example access, QRAM availability, number of copies K for quantum states), and to incorporate them into resource accounting and sample complexity.
- Unclear which access models (e.g., quantum example oracles or QRAM) are physically realistic in near-term and medium-term settings, and how to benchmark algorithms fairly under those constraints.
- Copy complexity and PAC learning with quantum data
- No explicit characterization of PAC sample complexity that includes the copy limit K for quantum states; need tight upper/lower bounds and learning guarantees that account for measurement disturbance and no-cloning.
- Missing practical strategies for optimal use of limited copies (adaptive measurement/active learning policies) and their impact on generalization.
- Demonstrable quantum advantage on practical tasks
- Lacking rigorous, end-to-end demonstrations of advantage (not just subroutines) on realistic distributions and tasks that resist dequantization; need clearly specified assumptions under which advantages provably persist.
- Insufficient criteria to certify that a quantum kernel or PQC cannot be efficiently simulated by classical methods (including randomized or tensor-network approaches) for target problem instances.
- Embedding design for classical data
- Absence of principled methods to design or learn feature maps (angle rotations, entangling patterns) that induce an inductive bias aligned with the task, avoid periodicity artifacts, and control bandwidth without collapsing kernels to diagonality.
- No guidance on feature scaling/normalization for rotation-based encodings to prevent angle wrap-around and saturation, nor on automated hyperparameter tuning for encoding axes and entangling strengths.
- Quantum kernels: informativeness and robustness
- Unclear conditions (in terms of data structure and entanglement) under which fidelity-based or projected kernels yield informative Gram matrices rather than near-diagonal or near-constant matrices.
- Missing analysis of shot-noise requirements: how many shots per kernel entry are needed to guarantee SVM margin constraints and generalization, and how measurement noise propagates through the dual optimization.
- Limited discussion of alternatives to the SWAP test (interferometric or direct overlap estimation) with better noise robustness or lower depth, and their comparative resource trade-offs.
- Variational quantum circuits (QNNs): expressivity vs. trainability
- No quantification of the capacity/generalization (e.g., VC dimension, Rademacher complexity) of QNN hypothesis classes under realistic depth and noise constraints.
- Absent systematic characterization of training landscapes (including barren plateaus and noise-induced gradients) for the ansätze discussed, and concrete prescriptions to avoid or mitigate them in practice.
- Lack of guidelines for choosing hardware-efficient vs. problem-inspired ansätze that balance expressivity, optimization tractability, and noise resilience, including the role of data re-uploading and measurement design.
- Resource accounting and scalability
- Insufficient end-to-end resource accounting (state preparation costs, circuit depth, shots, classical optimization complexity) to compare QML pipelines against strong classical baselines on equal footing.
- No scaling laws linking qubit count, circuit depth, shot budget, and training set size to achievable generalization error for QNNs and quantum kernel SVMs.
- Benchmarking and evaluation protocols
- Missing standardized benchmarks (datasets, metrics, compute budgets) and ablation protocols that ensure fair comparisons to tuned classical baselines and report uncertainty (shot-noise/error bars).
- Need for task suites that reflect “quantum-native” data (e.g., many-body states, chemistry) while remaining reproducible and resistant to known dequantization techniques.
- Learning from quantum data: states and processes
- Unclear PAC frameworks and sample complexity for learning states/channels (process learning), including optimal measurement strategies and guarantees under noise and limited copies.
- Absent analysis of how learnability depends on physical properties (e.g., locality, sparsity, approximate symmetries) of the unknown state/channel and on measurement families available.
- SVMs with quantum kernels: classical bottlenecks
- Training remains classical; the paper does not address how large, shot-noisy Gram matrices impact the computational feasibility of SVM training and what preconditioning or noise-aware solvers are needed.
- No exploration of approximate kernel methods (Nyström, random features adapted to quantum kernels) to reduce training cost while preserving advantage.
- Robustness to noise and errors
- Incomplete treatment of noise and error mitigation: how device noise (depolarization, readout errors, crosstalk) affects kernel estimates and QNN gradients, and which mitigation strategies yield reliable gains without negating advantages.
- Need for certified uncertainty quantification in predictions (e.g., confidence intervals that incorporate shot noise and device drift) and their impact on PAC-style guarantees.
- Interpretability and diagnostics
- Missing methods to interpret learned quantum models (kernels or QNNs), diagnose failure modes (e.g., kernel collapse, gradient vanishing), and attribute performance to specific quantum mechanisms (entanglement, interference).
- Practical guidance for feature map and measurement choices
- The toy examples do not translate to actionable design rules for multi-qubit, high-dimensional data; future work should provide selection criteria for encoding axes, entangling topology, and observables that are task-consistent and hardware-realistic.
- Open theoretical bridges
- Lack of formal links between quantum Hilbert-space similarity measures and families of classical kernels (including provable separations or equivalences) to clarify when quantum-induced inductive biases are genuinely distinct.
- Unresolved question of how PAC/VC generalization bounds adapt to shot-based training and measurement collapse, including concentration inequalities tailored to quantum estimators.
Practical Applications
Immediate Applications
Below are concrete use cases that can be built or piloted with today’s NISQ hardware and hybrid classical–quantum stacks, acknowledging their pragmatic limits (noise, depth, and scaling). Each item includes sectors, potential tools/workflows, and feasibility assumptions.
- Quantum-data classifiers for experiment readout and control
- Sectors: quantum hardware, materials science, high-energy physics
- Tools/workflows: train variational classifiers or quantum-kernel SVMs on measurements of quantum states (e.g., via SWAP-test kernels, projected/local kernels) to distinguish phases, detect drifts, or classify outcomes in spectroscopic/quantum-sensor experiments; integrate into lab control loops
- Assumptions/dependencies: availability of K copies of states (no-cloning constraint), stable state-preparation/measurement interfaces, finite-shot estimation handled via proper uncertainty quantification; performance hinges on well-chosen embeddings and kernels
- Automated calibration and tuning of quantum devices
- Sectors: quantum computing hardware manufacturing and operations
- Tools/workflows: reinforcement learning or variational circuits to optimize pulse schedules, gate parameters, and crosstalk mitigation; online learning with experiment-in-the-loop; transfer of learned policies across similar devices
- Assumptions/dependencies: stationarity over learning timescale, safe exploration constraints, robust optimization under shot noise and device drift
- Quantum-kernel SVMs for small-sample classification where inductive bias matches encoding
- Sectors: finance (niche signals), cybersecurity (rare-event detection), manufacturing quality control (sensor signatures)
- Tools/workflows: angle- or feature-hamiltonian encodings; Gram-matrix estimation on device; classical SVM training; careful bandwidth/norm scaling to avoid diagonal or flat kernels
- Assumptions/dependencies: problem instances small enough to tolerate shot costs; empirical validation against strong classical kernels; no dequantization path with comparable resources
- Similarity search and fingerprinting of quantum states
- Sectors: quantum networking/communications, distributed quantum sensing
- Tools/workflows: SWAP-test–based fidelity estimation for identity/authentication checks, device benchmarking, or rapid duplicate detection among state libraries
- Assumptions/dependencies: controlled two-register access to states, coherent depth for controlled-SWAP, error mitigation for small circuits
- Learning quantum processes for diagnostics and control
- Sectors: quantum hardware R&D, metrology
- Tools/workflows: PAC-style learning of channels/unitaries (e.g., predicting future measurement outcomes under limited-copy budgets), compressed “shadow” predictors for fast characterization; incorporate into diagnostics dashboards
- Assumptions/dependencies: copy complexity K budgeted explicitly; choice of measurement ensembles with efficient estimators; calibration of generalization gaps
- Educational, benchmarking, and governance workflows
- Sectors: academia, standards bodies, funding agencies
- Tools/workflows: standardized QML baselines that include classical counterparts, explicit data-access models (classical vs quantum example access), copy/shot complexity reporting, and dequantization checks; curriculum development around PAC learning for QML
- Assumptions/dependencies: community buy-in for reporting templates; reproducible pipelines in Qiskit/PennyLane/Cirq; well-documented datasets (classical and quantum)
- Small-instance combinatorial optimization heuristics with QAOA/QML hybrids
- Sectors: logistics (toy routing/assignment), scheduling, operations research (POCs)
- Tools/workflows: use QML for parameter transfer/landscape modeling, meta-learning of ansatz schedules, and hybrid warm-starts; compare fairly to tuned classical heuristics
- Assumptions/dependencies: instance sizes within NISQ reach; robust evaluation protocols; transparent resource accounting
Long-Term Applications
The following require fault tolerance, scalable state preparation/QRAM, and/or stronger evidence of advantage. Many also depend on maturing theory to avoid dequantization and on overcoming known trainability issues (e.g., barren plateaus).
- Scalable acceleration of classical ML via quantum linear algebra and QRAM
- Sectors: recommendation systems, large-scale regression/LS, kernel methods (NLP/vision), scientific data analysis
- Tools/workflows: qPCA for dimensionality reduction, HHL-style solvers, quantum example access for PAC learners, large quantum kernels beyond classical tractability
- Assumptions/dependencies: fast, practical QRAM; fault-tolerant depth; well-conditioned problems (or effective preconditioning); guarantees that survive input and output constraints; resistance to dequantization
- Quantum-native generative modeling for discovery
- Sectors: healthcare (drug/protein design), materials (catalysts, quantum materials), chemistry
- Tools/workflows: Born machines (QCBMs), quantum GANs, and variational generative circuits producing samples difficult to emulate classically; closed-loop “autonomous labs” to propose and test candidates
- Assumptions/dependencies: scalable trainability (mitigation of barren plateaus), expressive yet learnable ansätze, integration with robotic labs, validated advantage on domain-relevant metrics
- Quantum reinforcement learning with asymptotic speedups
- Sectors: robotics, finance/trading, adaptive control, traffic/logistics
- Tools/workflows: quantum-enhanced exploration/credit assignment using coherent memory/query access; hybrid model-based pipelines where quantum subroutines accelerate planning
- Assumptions/dependencies: fault-tolerant devices, quantum-accessible environment models/oracles, problem structures that admit provable or robust empirical speedups
- High-energy physics and large-scale detector data classification
- Sectors: HEP experiments, astrophysics
- Tools/workflows: quantum kernels/feature maps aligned with physics symmetries for event classification/anomaly detection at scale; integration with quantum sensors
- Assumptions/dependencies: scalable devices co-designed with readout pipelines; embeddings that avoid kernel collapse; evidence of resource-normalized gains over advanced classical models
- Large-scale learning of quantum states and processes
- Sectors: quantum error correction/design, quantum networks
- Tools/workflows: PAC learners and shadow-based predictors for tomography-lite at scale; learning noise channels to automate code and decoder selection
- Assumptions/dependencies: abundant copies (or continuous streams) of states/channels, efficient measurement design, error-corrected execution for deep characterization routines
- Finance: quantum-enhanced scenario generation and portfolio/risk optimization
- Sectors: asset management, risk, derivatives
- Tools/workflows: QML generative models for heavy-tailed scenarios; QAOA/QNN hybrids for QCQP-like optimization with learned encodings; end-to-end risk backtesting
- Assumptions/dependencies: robust mapping from finance constraints to hardware-friendly cost functions; fault tolerance; regulatory acceptance and auditability; clear, out-of-sample benefits vs. tuned classical pipelines
- Energy and infrastructure optimization at grid scale
- Sectors: power systems (unit commitment, optimal power flow), mobility
- Tools/workflows: QML-informed encodings + variational optimizers/QAOA; meta-learning to generalize across daily instances
- Assumptions/dependencies: problem-size scaling, hardware connectivity aligned to problem graphs, competitive runtimes including I/O
- Secure quantum biometrics and authentication
- Sectors: quantum communications, identity systems
- Tools/workflows: fidelity/kernal-based state comparisons for authentication; QML-based anomaly detection in quantum channels
- Assumptions/dependencies: widespread quantum network deployment; robust photonic/ion implementations; formal security proofs under realistic noise/adversaries
- Scientific autonomy loops for hypothesis generation and experiment planning
- Sectors: materials discovery, chemistry, biology
- Tools/workflows: QML agents that propose experiments (active learning), update generative models, and steer instrumentation; tight integration with classical Bayesian optimization
- Assumptions/dependencies: mature lab automation; reproducible quantum hardware operations; cross-validation against classical autonomous-lab baselines
Cross-cutting assumptions and dependencies (impacting feasibility across use cases)
- Hardware: error rates, coherent depth, qubit counts, connectivity, and availability of fault-tolerant operations
- Data access: QRAM or equivalent memory models; quantum example access; copy complexity K for quantum datasets; i.i.d. sampling assumptions
- Trainability: avoidance/mitigation of barren plateaus; optimizer robustness to shot noise; effective initialization and inductive bias via embedding design and kernel bandwidth
- Benchmarking: strong classical baselines; resource-normalized comparisons; avoidance of contrived tasks and careful treatment of dequantization results
- Compliance and trust: interpretability/explainability needs in regulated sectors; reproducibility, auditing, and model risk management for hybrid pipelines
These applications directly reflect the paper’s emphasis on: (1) the centrality of access models and inductive bias (encodings/kernels); (2) variational QML as the pragmatic near-term path; (3) quantum-data–native tasks where advantages are already measurable; and (4) conditional, longer-horizon opportunities that will require scalable hardware and stronger guarantees.
Glossary
- Amplitude encoding: A method to embed real-valued classical data into a quantum state by using the components as amplitudes. "a widely used option is amplitude encoding"
- Ancilla qubit: An auxiliary qubit used to control or facilitate operations within a quantum circuit. "we denote the ancilla qubit with the sub-index "
- Binary-basis embedding: Encoding classical bitstrings as computational-basis quantum states. "is binary-basis embedding: given , prepare the computational-basis state "
- Bloch sphere: The geometric representation of the state space of a single qubit. "maps to points on the Bloch sphere"
- BQP: The complexity class of decision problems solvable by a quantum computer in polynomial time. "BQP (the class of decision problems solvable by a quantum computer in polynomial time)"
- Controlled SWAP operation: A three-qubit gate that swaps two target registers conditioned on a control qubit. "Above, denotes the controlled SWAP operation."
- Curse of dimensionality: The phenomenon where high-dimensional input spaces make learning and computation difficult due to data sparsity and resource growth. "combat the curse of dimensionality arising from the fact that is usually a very high-dimensional space"
- Eckart–Young theorem: A result stating that the best low-rank approximation (e.g., PCA) maximizes retained variance. "by the EckartâYoung theorem"
- Empirical loss: The average training loss computed over a finite dataset. "the empirical loss (or the training error) is"
- Expectation value: The mean value of a measurement of an observable on a quantum state, used as a model output. "finite-shot estimates of expectation values"
- Feature map: A transformation that embeds data into a higher-dimensional space to enable linear separation. "consider the feature map "
- Gram matrix: The matrix of pairwise kernel evaluations over a dataset, which must be positive semidefinite. "the Gram matrix is positive semi-definite"
- Hamiltonian: The operator that generates the time evolution of quantum states. "For a Hamiltonian , the state evolves as "
- Hardware efficient ansatz: A parametrized quantum circuit designed to match the native gates and connectivity of the hardware. "leading to the so-called hardware efficient ansatz"
- HHL-style solvers: Quantum algorithms for solving linear systems of equations based on the Harrow–Hassidim–Lloyd method. "HHL-style solvers for linear systems"
- Hilbert space: The vector space in which quantum states live. "where denotes the Hilbert space of some quantum system"
- Hilbert–Schmidt kernel: A quantum kernel defined as the Hilbert–Schmidt inner product of density matrices. "a basic choice is the HilbertâSchmidt kernel"
- Hypothesis class: The set of candidate models considered by a learning algorithm. "one fixes a hypothesis class "
- Inductive biases: Prior structural assumptions embedded in models that guide generalization. "inductive architectural biases"
- i.i.d.: Independently and identically distributed samples assumed in many learning frameworks. "drawn independently and identically distributed (i.i.d.)"
- Kernel trick: Computing inner products in an implicit feature space via a kernel function, avoiding explicit mapping. "Support vector machines (SVMs) implement this idea implicitly via the kernel trick"
- No-cloning theorem: A fundamental result stating that unknown quantum states cannot be copied. "as a consequence of the no-cloning theorem"
- No-go theorems: Formal impossibility or limitation results that rule out certain advantages or methods. "no-go theorems for worst- or average-case performance"
- Noisy intermediate-scale quantum (NISQ): The current generation of quantum devices with limited qubit counts and significant noise. "noisy intermediate-scale quantum (NISQ)"
- Observable: A Hermitian operator measured to obtain outcomes or expected values from a quantum state. "and is a task-dependent observable"
- PAC learning: The Probably Approximately Correct framework for formalizing learnability and generalization. "PAC learning, introduced in~\cite{valiant1984theory}"
- (ε,δ)-PAC learner: An algorithm that returns a hypothesis whose risk is within ε of optimal with probability at least 1−δ. "an -PAC learner"
- Parametrized quantum circuit (PQC): A quantum circuit with tunable parameters, often used as a model in QML. "parametrized quantum circuit (PQC), or quantum neural network (QNN), ansatz"
- Pauli observable: Measurement of a Pauli operator (X, Y, or Z) on a qubit. "measuring the Pauli observable "
- Population risk: The expected loss over the data-generating distribution (true risk). "generalization error (also known as the true or population risk)"
- Projected quantum kernel: A kernel that compares reduced (marginal) states to capture local similarities. "such as the projected quantum kernel"
- Quantum channels: Completely positive trace-preserving maps describing general quantum processes. "quantum channels"
- Quantum example access: Access model where a learner is provided superpositions over training examples. "quantum example access / quantum PAC setting"
- Quantum kernel: A kernel defined via overlaps or fidelities of quantum-embedded states. "one can use the quantum kernel"
- Quantum neural network (QNN): A parametrized quantum model analogous to classical neural networks. "parametrized quantum circuit (or quantum neural network) "
- Quantum PCA: A quantum algorithm for principal component analysis. "quantum PCA~\cite{rebentrost2014quantum}"
- Sample complexity: The number of samples required to achieve specified accuracy and confidence in PAC learning. "is known as the sample complexity"
- Shot noise: Statistical fluctuations arising from finite measurement repetitions (shots). "standard error due to shot noise scaling as "
- Support vector machine (SVM): A margin-based classifier often trained with kernels. "Support vector machines (SVMs) implement this idea implicitly via the kernel trick"
- SWAP test: A quantum circuit used to estimate overlaps between states. "the SWAP test"
- Unitary: A norm-preserving linear operator representing quantum evolution. "unitary "
- Vapnik–Chervonenkis (VC) theory: A framework in statistical learning theory relating capacity and generalization. "VapnikâChervonenkis (VC) theory"
- VC dimension: A capacity measure indicating how many points a hypothesis class can shatter. "VC dimension "
- VC theorem: Results that bound generalization error in terms of VC dimension and sample size. "one of the variants of the VC theorem states that"
Collections
Sign up for free to add this paper to one or more collections.