- The paper introduces CIMinus, a framework that integrates sparsity abstraction (FlexBlock) with hardware-level mapping to optimize DNN computations on SRAM-based CIM architectures.
- It employs a declarative interface, integrated pruning workflow, and hierarchical cost engine to systematically evaluate latency, energy, and accuracy trade-offs.
- Validation against accelerators like MARS and SDP demonstrates its accuracy, with performance predictions aligning within a 5.27% error margin.
Authoritative Summary of "CIMinus: Empowering Sparse DNN Workloads Modeling and Exploration on SRAM-based CIM Architectures"
Introduction and Motivation
The rapidly escalating scale of DNNs demands significant improvements in computational efficiency to address the growing data movement and energy costs in traditional architectures. Compute-In-Memory (CIM) architectures, especially those based on SRAM, are recognized for their potential to reduce the von Neumann bottleneck through near-memory processing. However, efficient exploitation of sparsity within CIM remains highly non-trivial due to rigid crossbar structures, limited mapping flexibility, and under-explored co-design methodologies. In particular, design choices in sparsity patterning and mapping strategies are empirically driven, lacking a unified and systematic modeling framework.
To address these challenges, this paper presents CIMinus, a framework for system-level cost modeling and co-design space exploration of sparse DNN workloads on digital SRAM-based CIM architectures. The framework bridges the gap between model-level sparsity exploitation and hardware-level mapping, supporting detailed latency, energy, and accuracy analyses, and validated against state-of-the-art CIM accelerators.
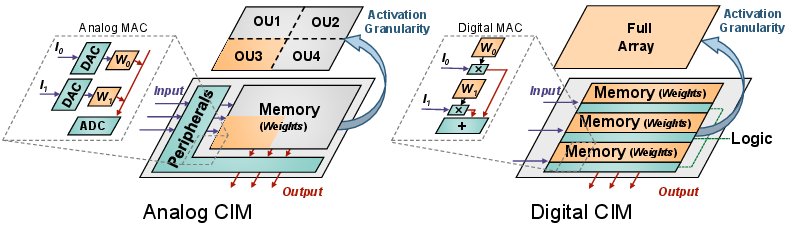
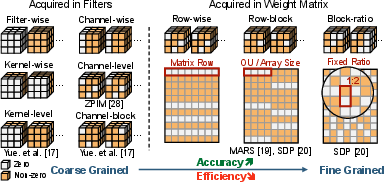
Figure 1: Comparative overview of CIM architectures and sparsity patterns, highlighting architectural evolution and pattern design diversity.
FlexBlock: A Unified Abstraction for Sparse Workloads
CIMinus introduces FlexBlock, a block-oriented and compositional abstraction for representing a broad array of hardware-constrained sparsity patterns. The abstraction supports two primary compositional modes:
- FullBlock sparsity: Coarse-grained pruning where entire blocks are zeroed, often matching hardware macro or operational unit boundaries.
- IntraBlock sparsity: Fine-grained control within blocks, selecting unstructured or semi-structured zeros constrained by hardware alignment requirements.
By compositing up to two blockwise patterns, FlexBlock encapsulates mainstream and emerging sparsity schemes found in contemporary CIM designs, ensuring compatibility with the rigid requirement of row/column alignment inherent in crossbar architectures. The abstraction allows workload-adaptive patterning, critical for optimizing hardware utilization while preserving model accuracy.
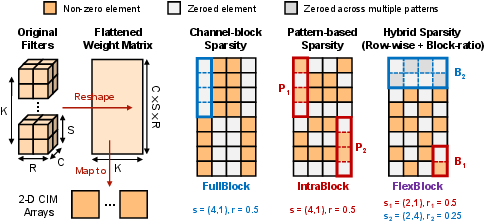
Figure 2: Examples of sparsity pattern representation in reshaped weight matrices using the FlexBlock abstraction.
The CIMinus Framework: Architecture, Interface, and Methodology
CIMinus comprises three primary components:
- Declarative Programming Interface: Users describe DNN workloads as DAGs (imported from ONNX or specified manually), hardware compositions (compute units, memory units, and sparsity support), and mapping strategies (data reshaping and loopnest-based spatial/temporal mapping). Sparsity patterns are specified using FlexBlock descriptors, which are automatically converted into pruning masks.
- Integrated Pruning Workflow: Flexible specification of pruning criteria at both coarse and fine blocks enables magnitude-based or pattern-constrained weight elimination, generating hardware-compatible sparse weights and indices.
- Hierarchical Cost Modeling Engine: The framework aggregates per-access dynamic and static energy for each hardware component, determines latency from critical path pipeline analyses, and models sparsity-support overheads (index management, multiplexers, accumulators) in detail. Energy and performance estimation leverages user-provided or PCACTI/PTPX-derived microarchitectural parameters.
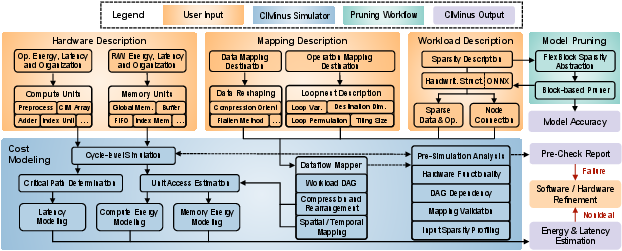
Figure 3: Overview of the CIMinus framework, showing integration of workload/dataflow description, hardware modeling, pruning, and mapping exploration.
Validation and Quantitative Analysis
CIMinus is validated against two recent digital SRAM-based sparse CIM accelerators:
- MARS: Group-wise structured pruning and multi-macro data mapping.
- SDP: Hierarchical pattern-based pruning with both intra-block and inter-block sparsity.
The framework's predictions for system-level speedup and energy saving closely align with reported silicon/simulation results, with an overall error bound of 5.27%. The tool also achieves strong accuracy parity for model validation, confirming the fidelity of its pruning and mapping abstractions.
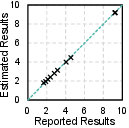
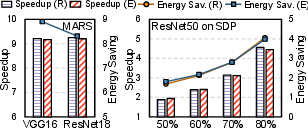
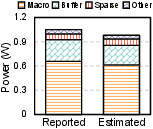
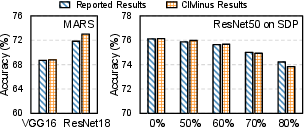
Figure 4: Validation results against MARS and SDP, showing close correlation for speedup, energy, and accuracy metrics.
Framework runtime is shown to scale with workload size and sparsity pattern granularity, remaining practical (<100s) for models up to 138M parameters and macro counts to 64. Indexed mapping and sparsity management dominate the runtime for fine-grained patterns; mapping and sparsity support scale sublinearly with hardware macro counts, profiling input sparsity where appropriate.
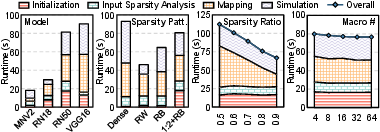
Figure 5: Framework runtime and scalability analysis across models, sparsity patterns, and hardware configurations.
Design Space Exploration: Sparsity and Mapping Strategies
Sparsity Pattern Trade-offs
CIMinus enables systematic evaluation of pattern granularity, block size, and ratio across ResNet50, VGG16, and MobileNetV2:
- Coarse patterns (e.g., channel-wise, large FullBlock): Maximize efficiency (speedup/energy) but cause severe accuracy degradation due to excessive model capacity reduction.
- Fine-grained and hybrid patterns (IntraBlock + FullBlock): Achieve higher accuracy due to fine-grained control but often misalign with hardware, resulting in non-optimal efficiency. Routing and multiplexing overheads non-trivially offset potential sparsity benefits.
- Optimal efficiency/accuracy trade-off is reached when sparsity matches hardware block boundaries without excessive fragmentation or index complexity.
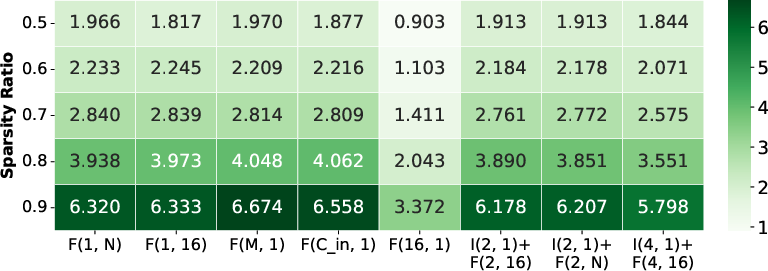
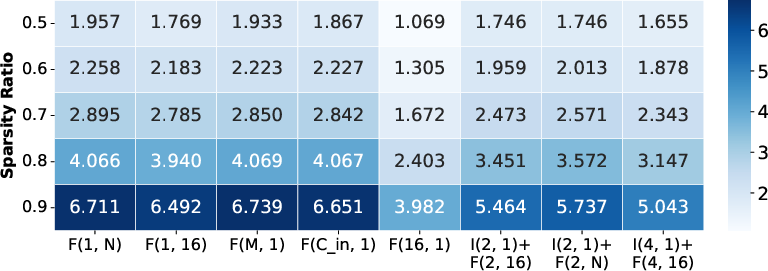
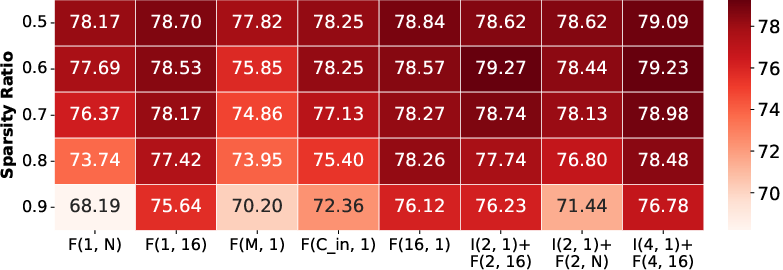
Figure 6: Speedup, energy saving, and accuracy results for ResNet50 across sparsity patterns.
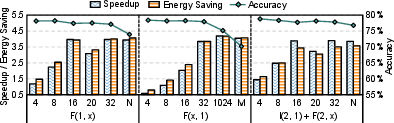
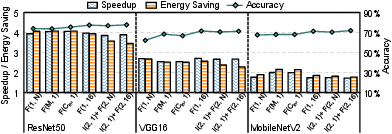
Figure 7: Block size and architecture-level analysis, illustrating pattern alignment, fragmentation, and their impact on efficiency and accuracy.
Input sparsity, implemented through bitline-level zero detection and skipping, provides orthogonal improvements (1.2×–1.4×). Its synergistic effects with weight sparsity vary by pattern: highest when weight patterns are column-aligned so input zeros naturally map to skipped rows.
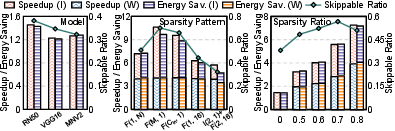
Figure 8: Analysis of input sparsity exploitation across models and weight sparsity settings.
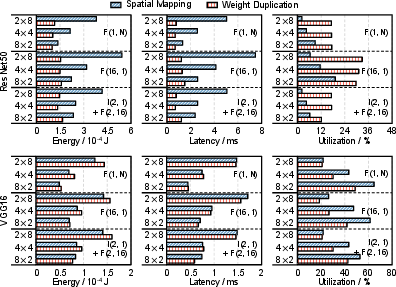
Advanced Mapping Strategies
Strategies such as weight duplication, spatial mapping, and data rearrangement are systematically explored:
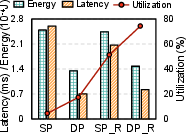
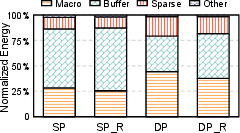
Figure 10: Component-level energy breakdown and performance trends with/without data rearrangement.
Implications and Future Directions
CIMinus demonstrates that careful co-design of sparsity patterns, block sizes, and mapping strategies is essential for harnessing the efficiency potential of SRAM-based CIM architectures without sacrificing model accuracy. The FlexBlock abstraction enables methodical exploration across this space for both emerging and established paradigms. Practitioners are equipped to quantify not only theoretical gains but actual overheads (indexing, routing, mapping), supporting rational hardware-software co-design decisions.
The framework's extensibility toward more granular or hybrid abstraction, dynamic activation profiling, and circuit-level optimization is immediate, serving as a foundation for both academic research and industrial design cycles. Future research should address further automation in hardware-aware sparsity pattern generation, integration with high-level synthesis flows, and support for non-SRAM (e.g., ReRAM or MRAM) technologies.
Conclusion
CIMinus establishes a rigorous, validated workflow for modeling and exploring sparse DNN workloads on SRAM-based CIM architectures, addressing a critical gap in hardware-aware sparsity research. Through the FlexBlock abstraction and holistic system-level modeling, it empowers systematic co-design exploration, offering actionable insights into efficiency, accuracy, and practicality of sparse neural acceleration. The framework is positioned to accelerate further innovation in sparse DNN deployment on custom silicon.
Reference: "CIMinus: Empowering Sparse DNN Workloads Modeling and Exploration on SRAM-based CIM Architectures" (2511.16368)