- The paper introduces FairLRF, a novel framework leveraging sparse low rank factorization and Hessian-based scoring to mitigate fairness bias in neural models.
- It employs truncated SVD and group-conditioned metrics to selectively sparsify model weights without retraining, achieving improved equalized odds and opportunity.
- Experimental results on CelebA and Fitzpatrick-17k show FairLRF improves precision and compression while significantly reducing bias compared to baselines.
FairLRF: Achieving Fairness through Sparse Low Rank Factorization
Overview and Motivation
FairLRF introduces a novel paradigm for enhancing fairness in deep learning (DL) models via sparse low rank factorization (LRF), leveraging singular value decomposition (SVD) beyond its conventional use for model compression. While prior work focused on pruning and quantization to promote fairness, FairLRF uniquely exploits the underlying structure of neural weight matrices to mitigate bias, specifically addressing disparities arising from sensitive attributes. The framework targets resource-constrained deployments, such as in medical diagnosis, where both efficiency and fairness are critical.
Methodology
Problem Definition and Metrics
FairLRF operates on classification tasks where data points are annotated with both target and sensitive attributes. Fairness enhancement is quantitatively assessed using equalized opportunity (recall rate differences across groups) and equalized odds (aggregate of differences in recall and false positive rates), as formalized by Hardt et al. These metrics facilitate objective comparisons of model outcomes across privileged and unprivileged groups.
Sparse SVD for Fairness
Traditional SVD decomposes a layer's weight matrix W into three matrices: U, S, and V, allowing for rank reduction (truncated SVD) and model compression with negligible impact on predictive performance, as validated on VGG-11 and the Fitzpatrick-17k dataset.
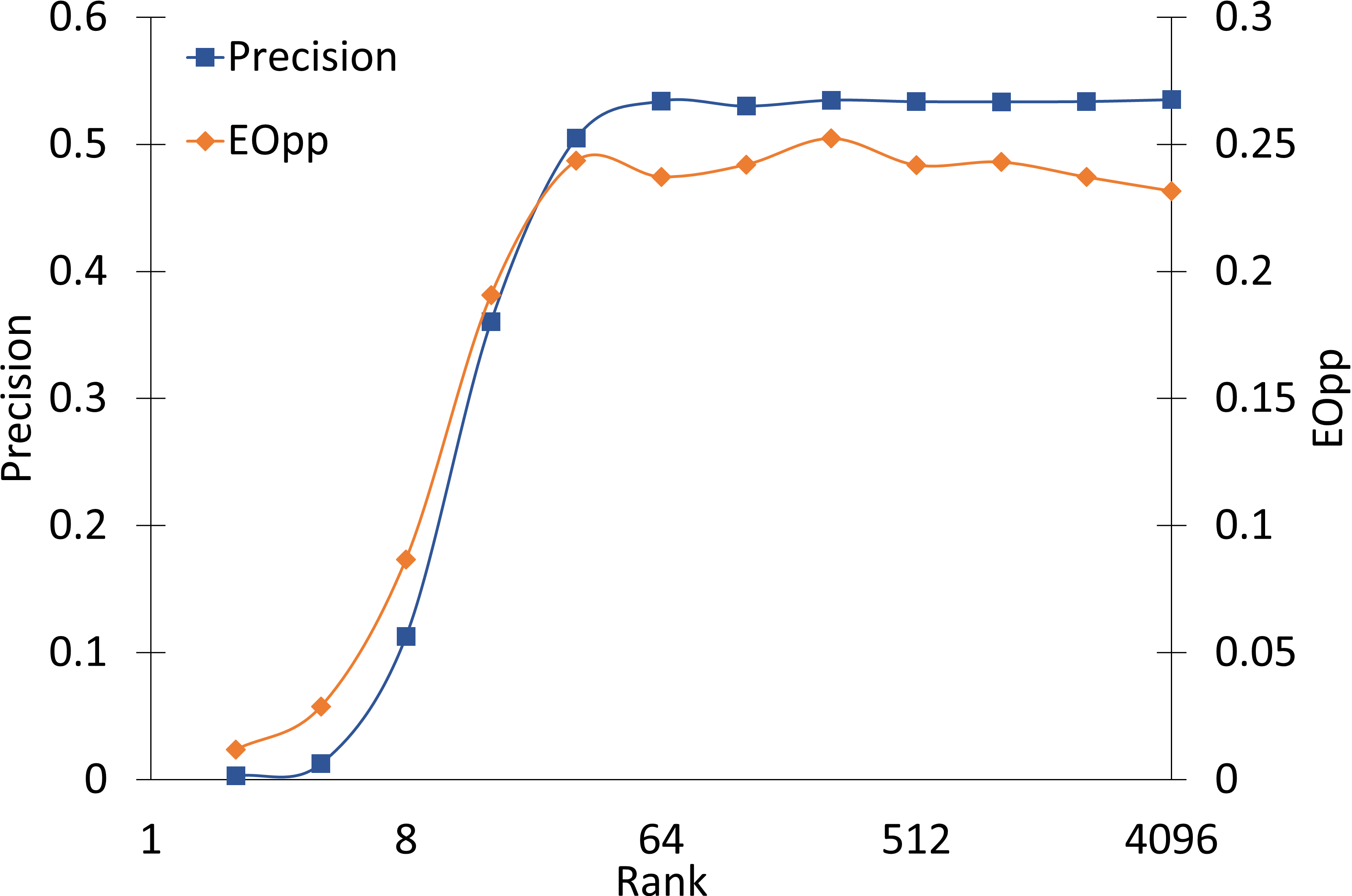
Figure 1: Performance of truncated SVD with different ranks k illustrates negligible precision and fairness degradation until aggressive rank reduction.
Building upon prior work showing redundancy in DL weight matrices, FairLRF introduces a critical observation: the contribution of individual elements in SVD’s unitary matrices to prediction bias is group-dependent. The method computes Hessian-based scores to assess the impact of weight removal on fairness for each demographic group, following a tailored version of the Taylor series approximation for loss change.
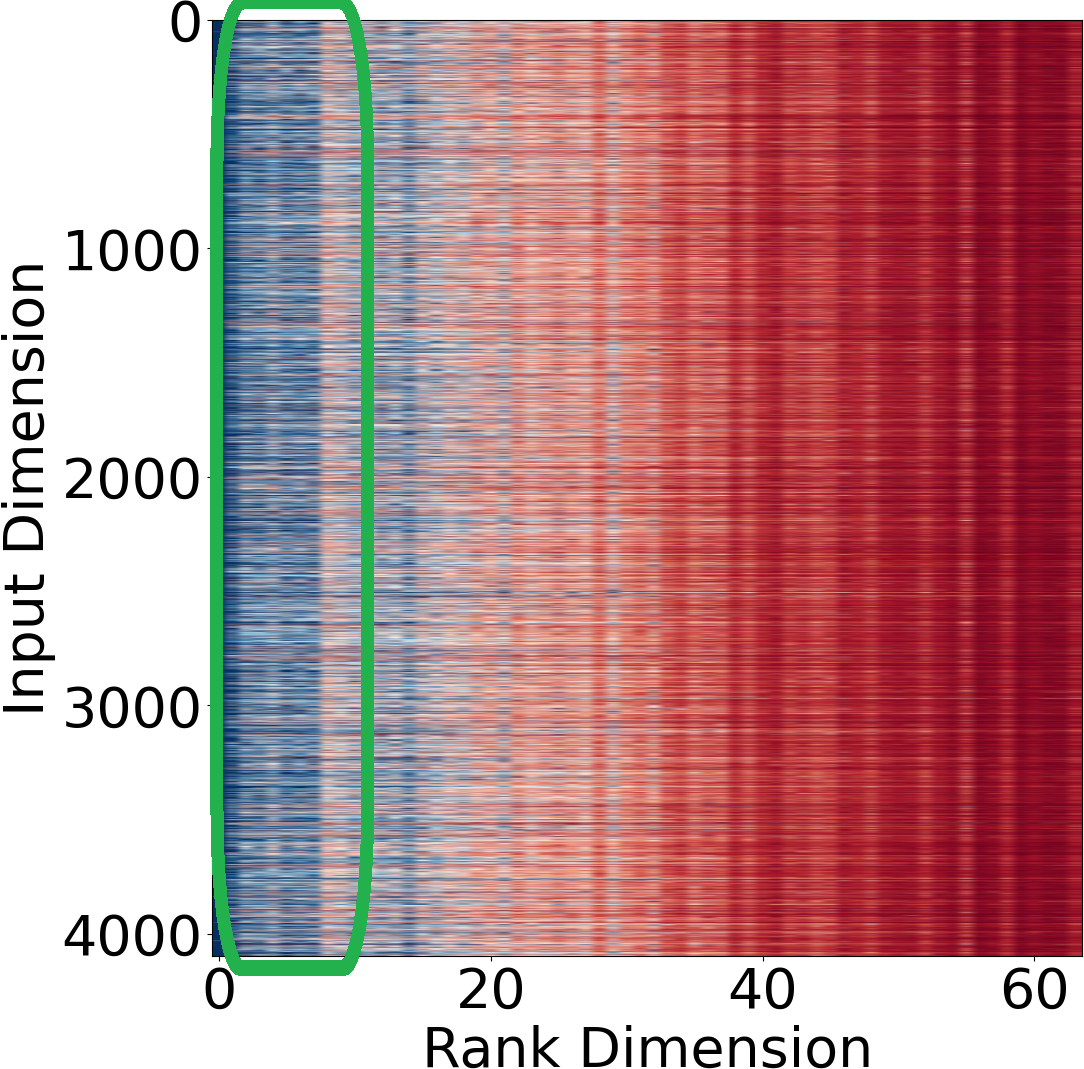
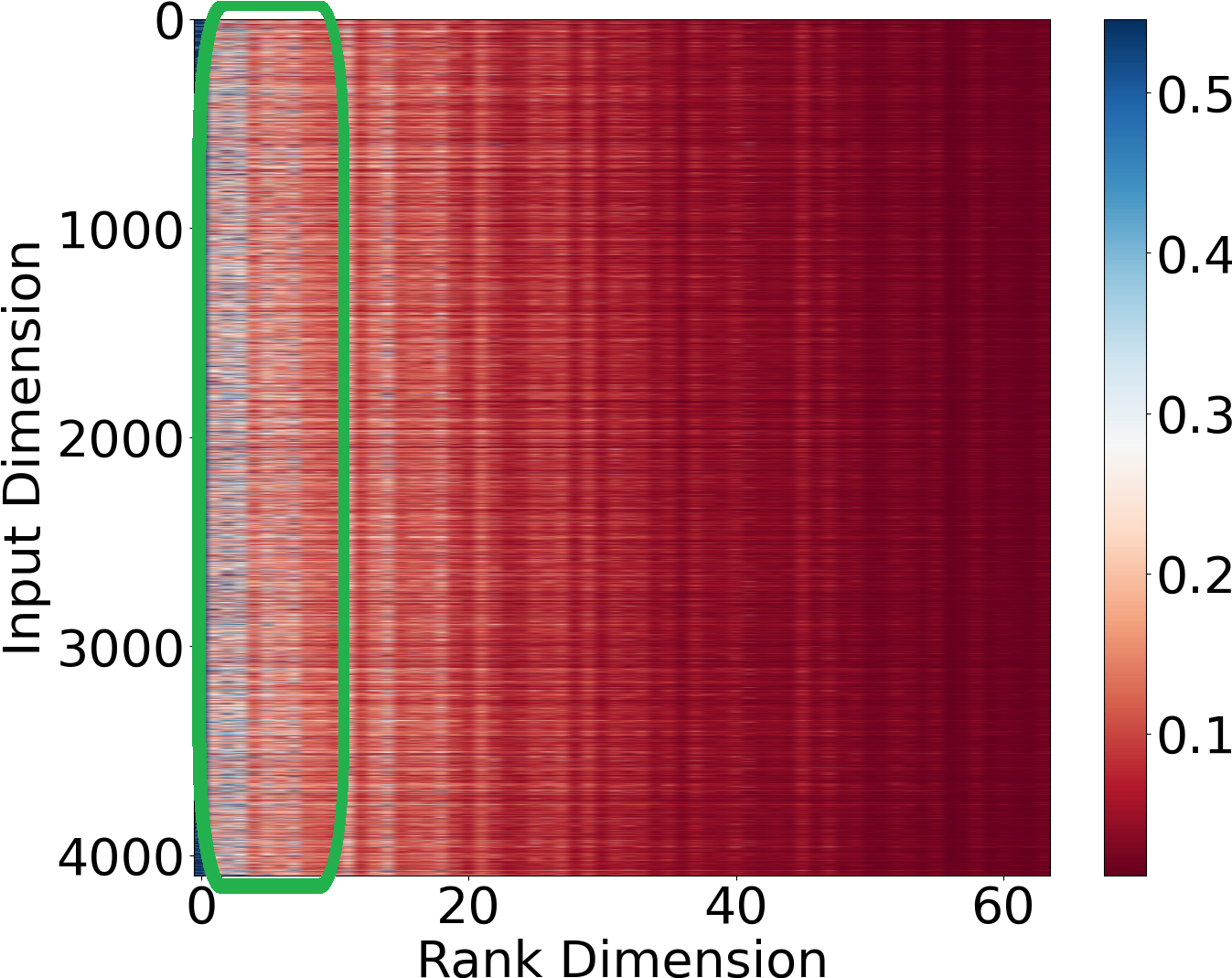
Figure 2: Distributions of Hessian values for privileged and unprivileged groups reveal actionable differences in bias contributions.
Fairness-Oriented Sparse SVD
By measuring weight-wise importance via group-conditioned Hessians, FairLRF constructs fairness-aware scores:
si=21θi2(hii0−βhii1)
where hiic is computed per group c. The framework selectively sparsifies rows/columns associated with high bias contributions, removing those with minimal impact on privileged groups while maximizing the reduction for the unprivileged.
Workflow and Implementation
The complete workflow encompasses:
- Truncated SVD on a pre-trained network.
- Group-specific Hessian-based scoring using inference on sampled data.
- Calculation of fairness-aware weight scores.
- Guided sparse SVD for targeted compression and fairness gains.
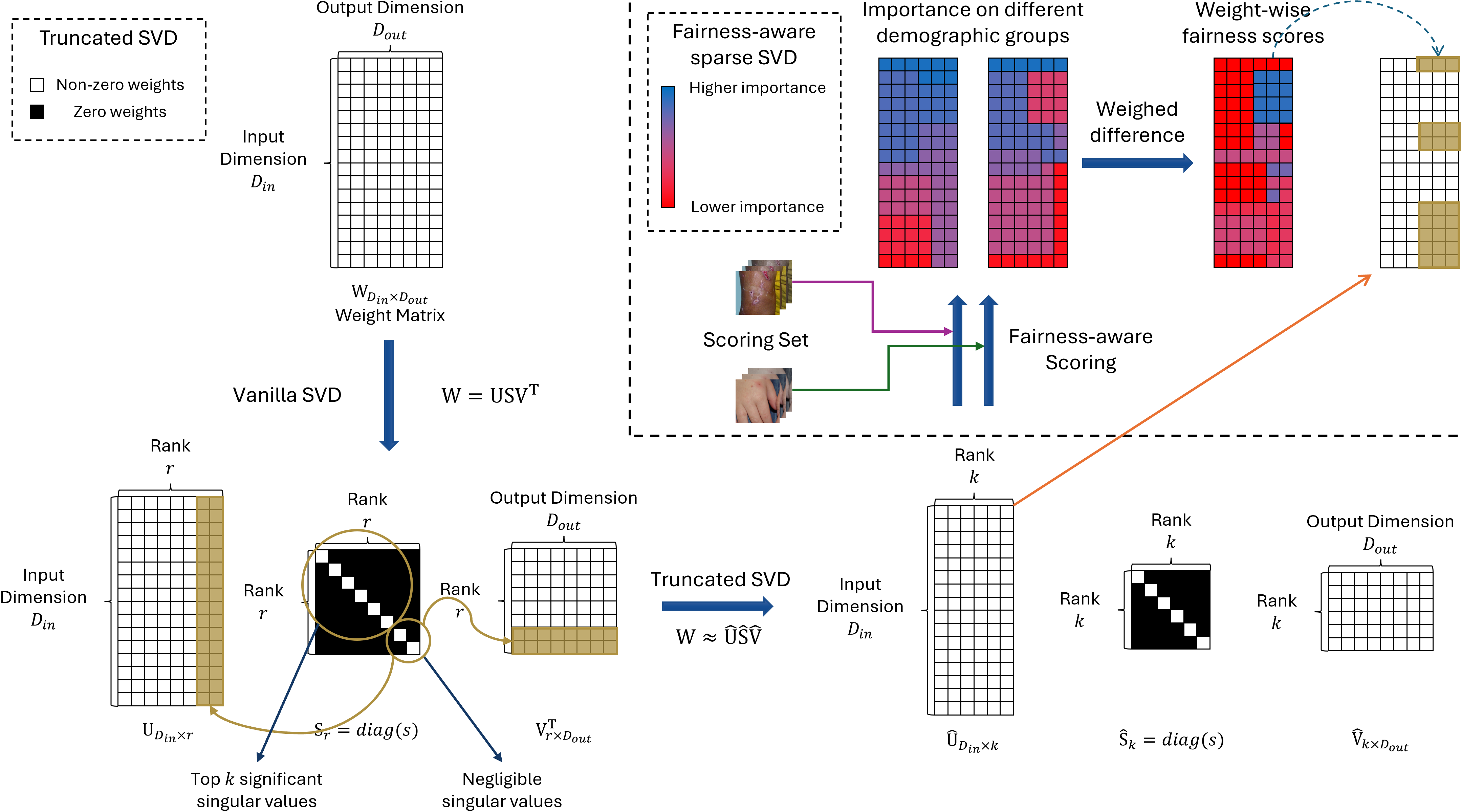
Figure 3: The FairLRF pipeline integrates SVD, group-based scoring, and guided sparsification for fairness-driven model optimization.
FairLRF obviates the need for retraining or fine-tuning, unlike methods such as FairQuantize, due to the theoretical guarantees provided by SVD structure.
Experimental Evaluation
Datasets and Settings
Experiments utilize CelebA (focusing on gender) and Fitzpatrick-17k (focusing on skin tone), covering broad and clinical image classification scenarios. VGG-11, with its dense fully connected layers, serves as the model backbone. FairLRF is compared against truncated SVD, sparse SVD (absolute-weight/activation strategies), FairPrune, and FairQuantize using precision, recall, F1-score, equalized opportunity, equalized odds, and compression rate.
Results on CelebA
FairLRF achieves the lowest equalized odds of all methods (0.029 versus 0.032 for vanilla, 0.034 for truncated SVD, and 0.034 for FairQuantize), with negligible precision loss. Compression rate improvements are on par with other SVD-based methods, demonstrating effectiveness without sacrificing model efficiency.
Results on Fitzpatrick-17k
On the clinically relevant Fitzpatrick-17k benchmark, FairLRF further distinguishes itself, attaining an equalized opportunity of 0.264 and equalized odds of 0.132, outperforming both conventional and fairness-oriented baselines. Notably, the method reaches a 6.2% higher average precision than FairQuantize and superior compression efficacy.
Hyperparameter and Layer Analysis
Ablation studies detail the effects of sparsity rate (sr), reduction rate (rr), and score trade-off parameter (β), confirming the robustness of FairLRF to hyperparameter choices, with sr being most critical, and highlight the importance of layer selection for practical deployments.
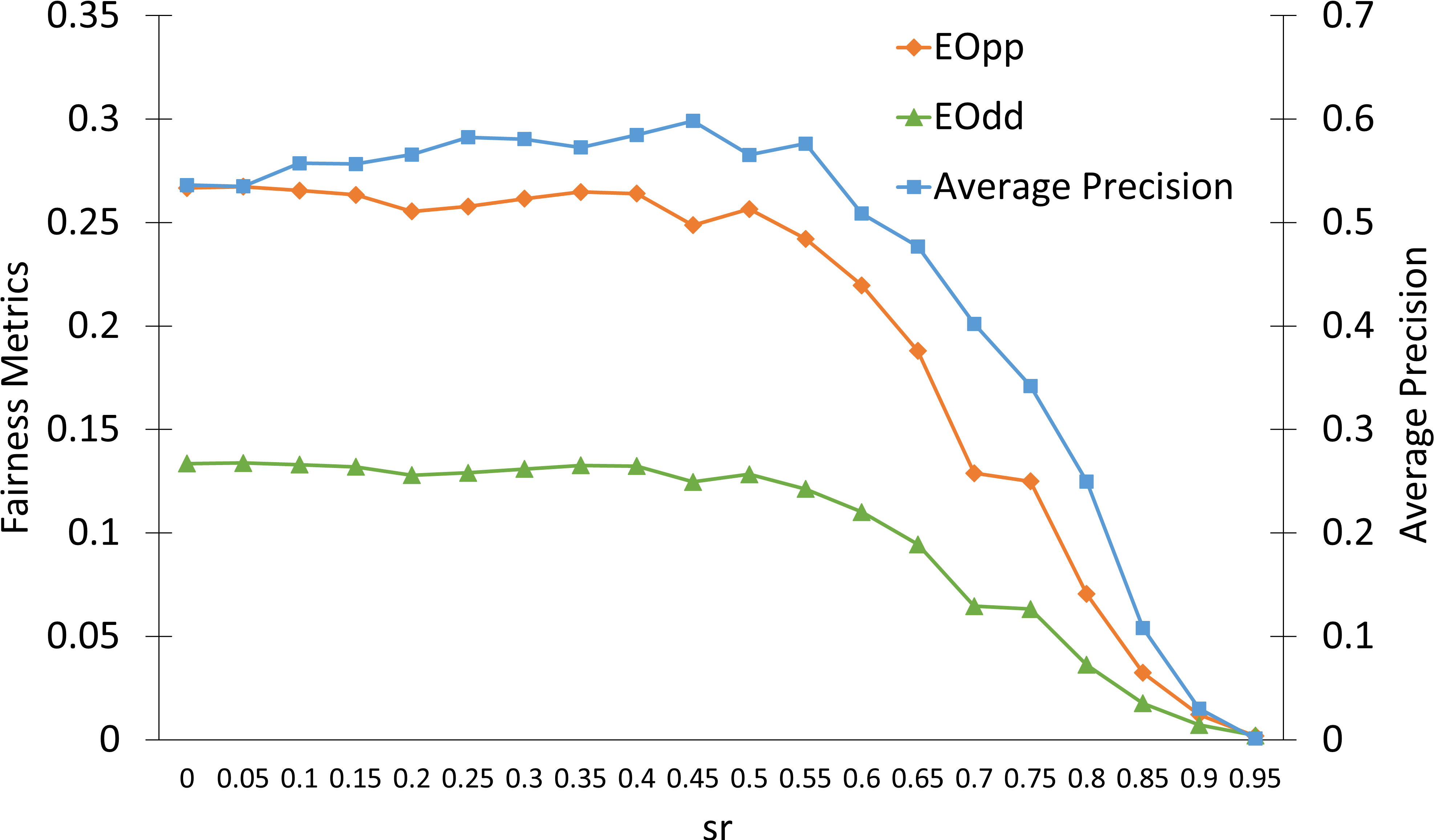
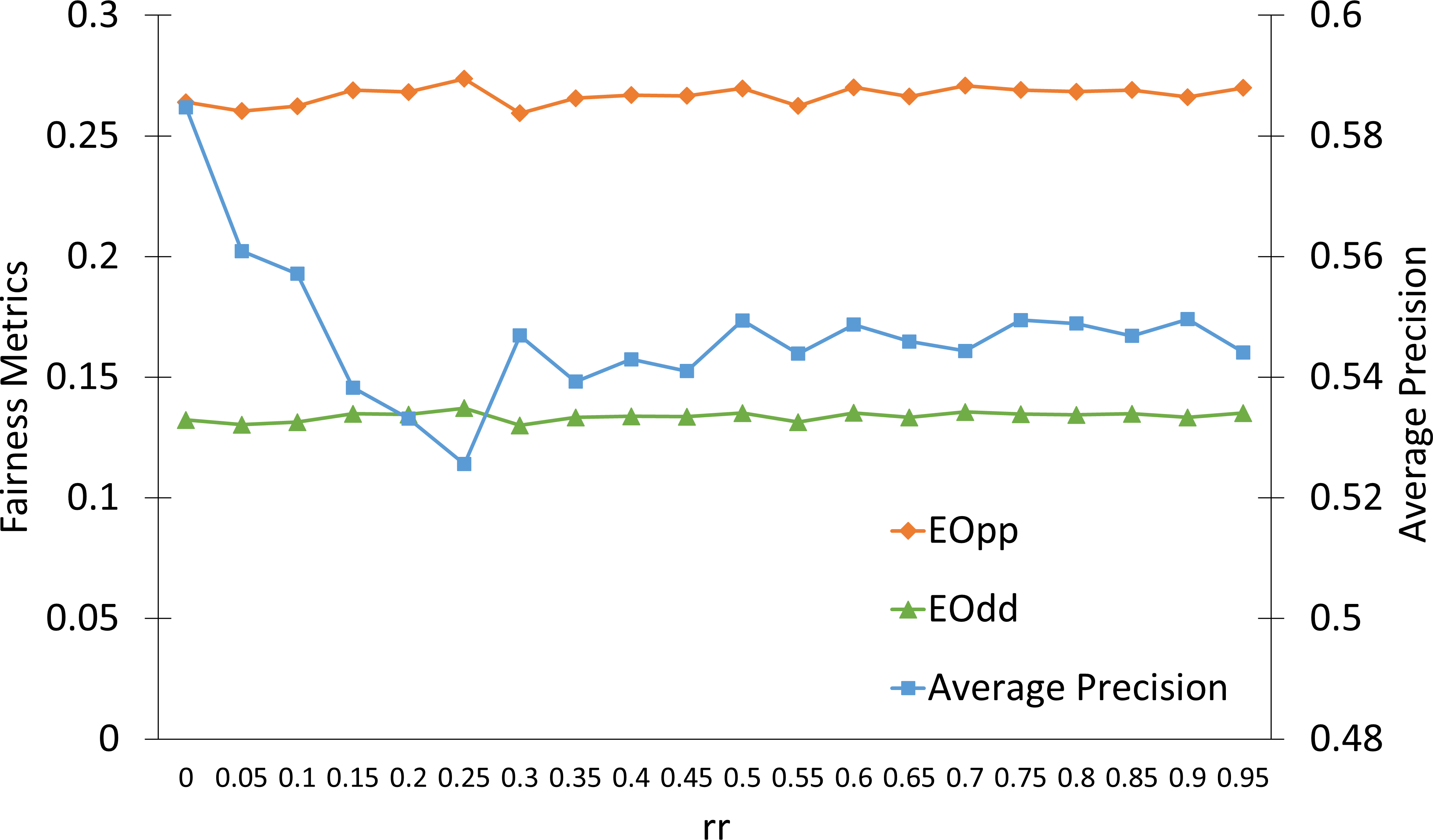
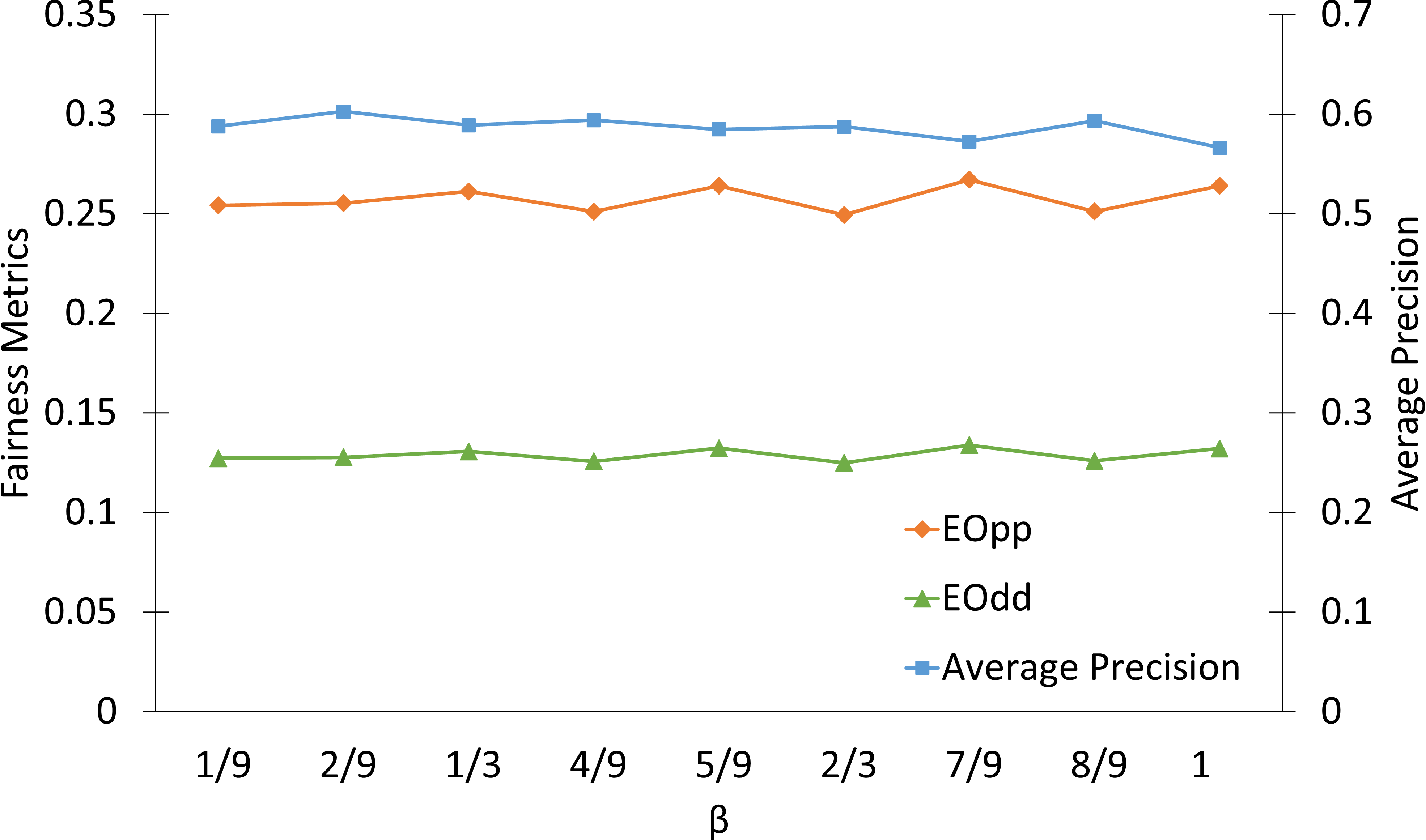
Figure 4: Precision/fairness metrics across hyperparameters reveal FairLRF's stable performance and sensitivity profile.
Implications and Future Directions
Theoretical implications include the extension of SVD's utility from pure compression to active fairness control, suggesting novel directions for matrix factorization in ethical ML. Practically, FairLRF's independence from retraining and compatibility with standard neural architectures positions it for deployment in edge devices and real-world decision systems.
Potential future enhancements include automated hyperparameter optimization, adaptation to multi-class sensitive attributes, and integration into multi-layer or entire-model fairness pipelines. There is also scope for extending the approach to non-linear model architectures and further theoretical analysis of its bias-minimizing effect in adversarial settings.
Conclusion
FairLRF presents an effective approach for fairness enhancement in deep neural networks, utilizing group-aware sparse SVD guided by Hessian-based scoring. Results on both general and medical image classification tasks validate its superiority over existing compression and fairness techniques, balancing accuracy, compression, and equity without additional retraining. The method offers a practical, theoretically grounded tool for deploying fair DL models in sensitive and resource-limited contexts, with significant opportunities for both further empirical and theoretical refinement.