- The paper introduces D-GARA, a framework that injects realistic anomalies using rule-based evaluations to enhance GUI agent robustness.
- It employs state-centered success validation and flexible configuration to accurately measure agent recovery in dynamic environments.
- Experimental results show up to a 33% drop in task success, highlighting the need for advanced multi-modal state tracking.
D-GARA: A Dynamic Benchmarking Framework for GUI Agent Robustness in Real-World Anomalies
Motivation and Limitations of Prior Work
Robust autonomous control of GUIs is a crucial challenge for the deployment of generalist agents on mobile devices. State-of-the-art GUI agents powered by Vision-LLMs (VLMs) demonstrate impressive performance on static and idealized benchmarks, yet these settings do not reflect the non-determinism, uncertainty, and interruptions pervasive in real-world environments. Most static datasets only pair screenshots with actions, lacking the ability to evaluate agent adaptability and recovery under dynamic system events such as permission dialogs, update prompts, network failures, and app crashes.
Existing dynamic benchmarks, e.g., AndroidWorld, fail to provide interruption-rich complex tasks, and static anomaly benchmarks, e.g., GUI-Robust, simply overlay deterministic interruptions, which can be easily bypassed and do not require true decision-theoretic replanning. There is a conspicuous absence of benchmarks that simultaneously support dynamic environments and fine-grained, systematic anomaly injection for agent evaluation.
D-GARA Framework: Architecture and Methodology
D-GARA (Dynamic Benchmarking Framework for GUI Agent Robustness in Real-World Anomalies) addresses this gap via a modular, extensible evaluation pipeline for GUI agents on Android. It supports seamless integration of new apps, task goals, and anomaly conditions. The pipeline incorporates three critical components:
- Semantic-Based Interruption Triggering: D-GARA parses the UI view hierarchy (XML) and uses rule-based evaluators to inject realistic anomalies triggered by contextual conditions, such as the presence of specific keywords or widgets in the interface. This mechanism supports complex, chained interactions—e.g., a permission dialog with multistage outcomes influencing the subsequent task flow—rather than naïve pop-up overlays.
- State-Centered Success Validation: Completion detection is based on declarative rules expressing desired UI states rather than fixed action sequences or self-reported signals. This allows benchmarking across various agent architectures and accommodates recovery paths, detours, and errors, as long as the required terminal state is eventually reached.
- Flexible, Human-Validated and Automated Benchmark Construction: D-GARA supports efficient benchmark expansion, decoupling anomaly logic and success criteria as configuration files, and providing tool support for human demonstration collection and annotation.
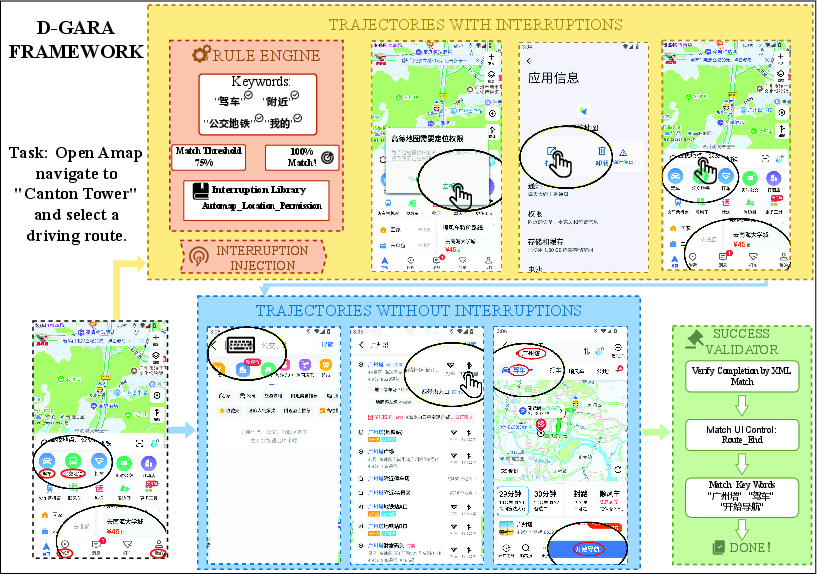
Figure 1: The D-GARA evaluation pipeline exemplifies modular integration of rule-based interruption injection and declarative goal-state validation, supporting robust and extensible anomaly-rich environment creation.
D-GARA-152: Benchmark Composition and Interruption Taxonomy
Built atop D-GARA, the D-GARA-152 benchmark comprises 152 tasks distributed across 8 high-frequency Android applications including e-commerce, social media, content consumption, navigation, and travel services. Task distribution is weighted towards high-use, functionally complex applications, producing a realistic operational profile.
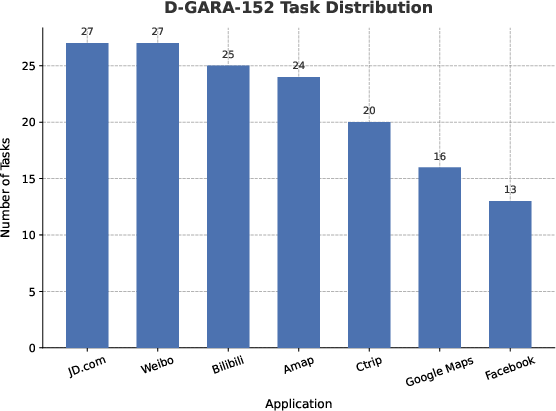
Figure 2: Task distribution within D-GARA-152 emphasizes functionally diverse, high-activity, and variable interaction contexts in modern mobile usage.
Interruption modalities are categorized into five archetypal dimensions:
- System Resource: e.g., battery warnings, thermal alerts
- System Network: e.g., Wi-Fi drops, mobile data handovers
- App Malfunction: e.g., app crashes, freezes
- Permission Control: e.g., runtime permission dialogs
- UX Disruption: e.g., update prompts, survey pop-ups
The disturbance profile for D-GARA-152 mirrors real-world user interactions, with system network/resource issues constituting the majority, app- and UX-level events at moderate rates, and permission dialogs as less frequent but critical anomalies.
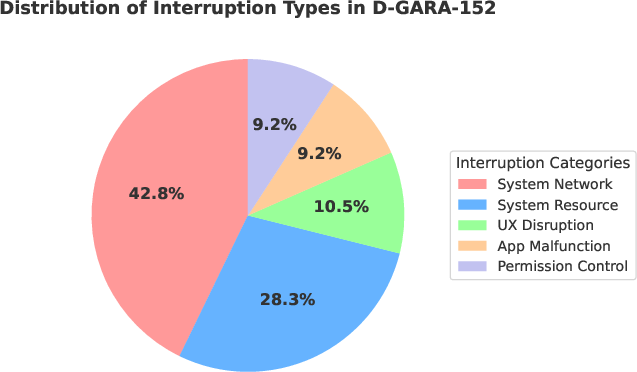
Figure 3: Distribution of interruption types in D-GARA-152 reveals an emphasis on frequent, device-level anomaly scenarios for agent evaluation.
Experimental Results: Agent Robustness Analysis
Overall Degradation under Anomalies
Empirical results show substantial degradation in task success for all evaluated agents—including leading models such as UI-TARS, AgentCPM-GUI, GPT-4o, Gemini2.5, and Qwen2.5-VL—when exposed to interruption-rich executions. Relative drops of up to 33% in success rates are observed.
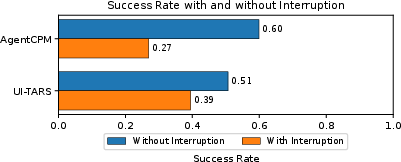
Figure 4: Success rates for UI-TARS and AgentCPM plummet under real-world interruptions, confirming the inadequacy of static benchmarks for assessing agent robustness.
Large proprietary MLLMs (GPT-4o, Gemini2.5) exhibit greater robustness, likely attributed to advanced planning and contingency reasoning capabilities, while GUI-specialized agents relying on visual grounding display particular fragility, mainly limited by their minimal adaptation for dynamic replanning.
Interruption-Type Sensitivity
Per-category analysis uncovers heterogeneous agent resilience. LLMs generalize better on permission and network-related anomalies, leveraging world knowledge and basic pattern matching. In contrast, GUI-specialized agents can outperform in app-level interruptions, due to direct training on interface manipulation. Critically, when agents are forced through non-trivial recovery paths (e.g., only the "Install" button is active), success rates collapse, exposing the inadequacy of current policy learning paradigms under non-reversible, multi-stage failures.
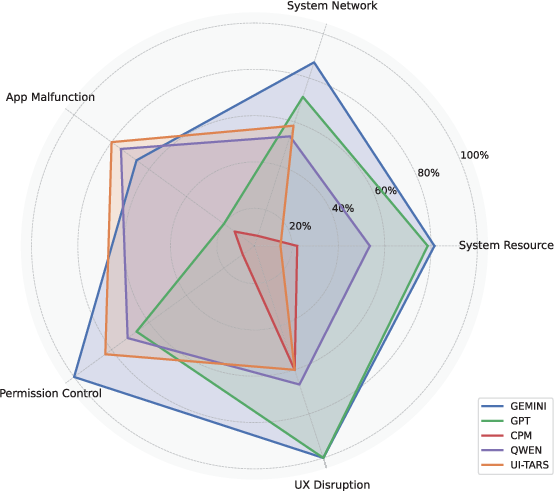
Figure 5: Robust success rates (RSRs) show agents are differentially sensitive to interruption types, with complex anomaly resolution severely limiting most models.
Perceptual Drift and Recovery Failure
D-GARA highlights recurrent failures in agent trajectory recovery, especially after disruptive anomalies such as application crashes. Agents often continue execution as if the UI state matches past history, neglecting to re-infer true context and becoming stuck in suboptimal or inconsistent behaviors. The design of D-GARA enables systematic observation and diagnosis of these drift phenomena.
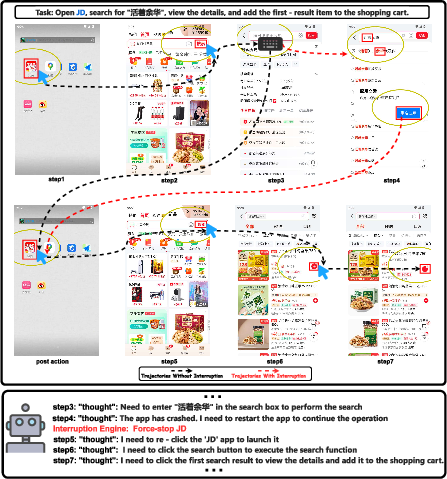
Figure 6: Example of perceptual drift post-app crash—agents fail to re-enter lost state information following abnormal UI transitions, reflecting a key limitation of current memory-mapping strategies.
Ablation studies indicate strong reliance on XML-based spatial coordinates for action selection. Vision-only input results in a sharp drop in performance, even for advanced MLLMs, emphasizing the gap between current architectural input fusion and human visual learning models.
Implications and Future Research Directions
D-GARA reveals that progress on static GUI benchmarks does not signal true agent robustness or real-world deployability. Practical deployment requires explicit robustness-aware training, advanced multi-modal state tracking, and contingency planning.
Implications are profound for both practical system engineering and fundamental AI research:
- Model Architecture: Future work must pursue tightly integrated perception-planning-memory stacks, shifting from teacher-forced imitation to interactive, error-recovering agents.
- Dynamic Training/Evaluation: Training datasets and curriculum should match the dynamic profiles of D-GARA, fostering robustness to non-reversible, real-time disturbances.
- Benchmarking Standards: D-GARA's modular anomaly injection and outcome validation should become a de facto standard for benchmarking GUI agents aimed at real-world high-variance operational contexts.
Conclusion
D-GARA establishes the first dynamic, extensible framework for systematic robustness evaluation of GUI agents under real-world anomaly conditions. Experimental evidence demonstrates strong performance vulnerability of contemporary agents, motivating a shift towards robustness- and recovery-centered agent design. D-GARA—open-sourced and readily extensible—constitutes a critical infrastructure for advancing GUI agent reliability and generalization research, with far-reaching implications for the next generation of embodied and interactive AI systems (2511.16590).

