- The paper introduces a JAX-native library for GFlowNets that leverages end-to-end JIT compilation to eliminate host-device synchronization bottlenecks.
- It employs a modular design with vectorized, stateless environments to facilitate large-scale parallel processing on CPUs, GPUs, and TPUs.
- Empirical results reveal dramatic wall-clock time reductions, achieving speedups ranging from 19× to nearly 80× over PyTorch-based implementations.
gfnx: A Fast and Scalable JAX Library for Generative Flow Networks
Introduction: Motivation and Positioning
Generative Flow Networks (GFlowNets) have emerged as a powerful approach for amortized sampling from complex discrete distributions, enabling sampling proportional to unnormalized rewards in settings such as molecular generation, structure learning, and sequence design. While substantial algorithmic advances have been made, widespread experimentation is hindered by the runtime inefficiencies of existing libraries, predominantly based on PyTorch and burdened by host-device synchronization bottlenecks. The paper "gfnx: Fast and Scalable Library for Generative Flow Networks in JAX" (2511.16592) addresses these constraints by introducing a JAX-native library that achieves end-to-end just-in-time compilation of both environments and training utilities. This advancement enables the full exploitation of hardware accelerators (CPU, GPU, TPU) and dramatically reduces wall-clock time for typical GFlowNet benchmarks.
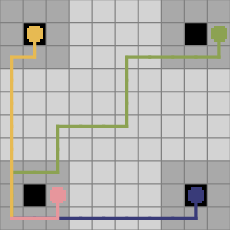

Figure 1: Visualization of GFlowNet environments: (Left) four sample trajectories in a hypergrid; (Right) sequential construction of a bit string, illustrating token-by-token generation.
Library Architecture and Design Principles
The architecture of gfnx centers around composability, transparency, and maximal hardware acceleration. Environments, reward modules, and metrics are implemented entirely in JAX with strict separation between logic and reward, facilitating reward/module swaps or dynamic learning of rewards without recompiling the core environment. Environments are stateless and vectorized, supporting efficient batch processing and enabling exploitation of JAX primitives such as vmap and pmap for large-scale parallelism.
The library's modules are structured as follows:
- Base primitives (state, parameter, and environment abstractions) define the shared typing and interaction patterns across use cases.
- Environments are vectorized, fully JIT-compiled, and support both discrete multi-action spaces and sequential construction (including acyclic and more generalized settings).
- Rewards modules are decoupled, supporting both fixed and learnable reward structures and enabling direct experimentation with proxy models.
- Metrics include domain-appropriate performance measurements (e.g., total variation, Jensen–Shannon divergence, Pearson correlation of reward and sampled distribution), beyond standard RL returns.
- Single-file Baselines mirror the CleanRL philosophy, providing transparent, hackable starting points with full environment and learning logic contained in one script.
The library deliberately trades tightly integrated training loops (as in torchgfn) for increased modularity; experimenters can mix and match trainers, environments, and reward modules for custom GFlowNet research pipelines.
Supported Environments and Algorithms
gfnx implements a comprehensive suite of standard GFlowNet benchmarks, including:
- Discrete hypergrids: high-dimensional, reward-heterogeneous cubes demonstrating mode discovery where closed-form solutions enable direct metric computation.
- Bit sequences: both autoregressive and non-autoregressive formulations, rewarding Hamming proximity to mode sets, supporting variable block sizes and complex mode distributions.
- TFBind8 and QM9: domain-driven sequence and molecular generation leveraging proxy predictors trained on real datasets, enabling assessment in sequence design and chemistry.
- AMP: peptide design with proxy rewards, supporting autoregressive, variable-length sequence generation over large alphabets.
- Phylogenetic tree construction: sequential merge environments with well-defined parsimony-based Gibbs rewards.
- Bayesian network structure learning: acyclicity-enforcing sequential graph construction with efficient, modular reward decomposition, leveraging local score changes for incremental updates.
- Ising model sampling: combinatorial energy-based environments where energy and GFlowNet policies are learned from data, supporting MCMC-informed training alternatives.
Across benchmarks, gfnx consistently attains strong statistical parity with existing implementations, as measured by mode coverage, population diversity, and sample quality. Crucially, it achieves dramatic speedups—frequently by an order of magnitude or more—over prior PyTorch-based systems.
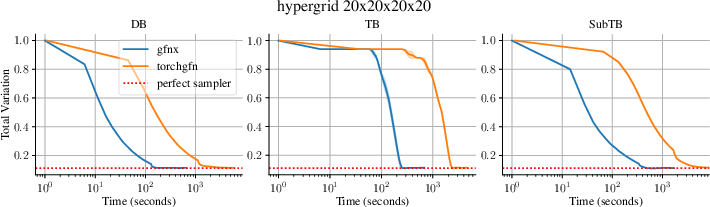
Figure 2: Total variation between reward and empirical sample distributions vs. training time in Hypergrid, demonstrating convergence at a fraction of the time cost.
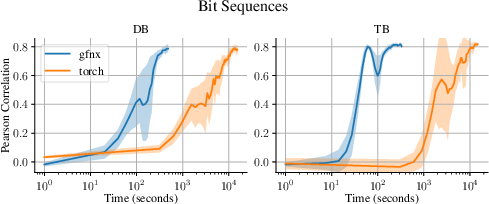
Figure 3: Bit sequence environment—gfnx and torch-based implementations display identical Pearson correlations, but with gfnx converging in vastly less wall-clock time.
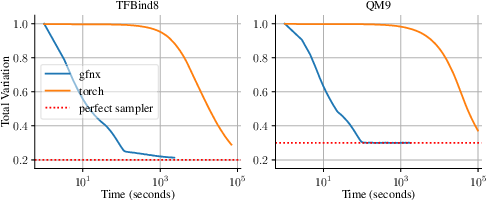
Figure 4: On TFBind8 and QM9, gfnx matches or exceeds torch baselines in sample quality while typically achieving 30× or more speedup.
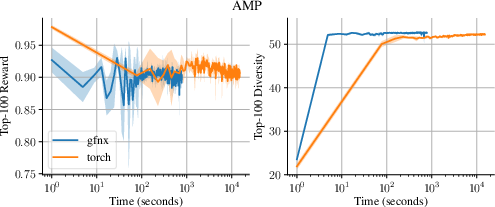
Figure 5: AMP environment: comparable reward/diversity achieved, with a 19× reduction in total time required.
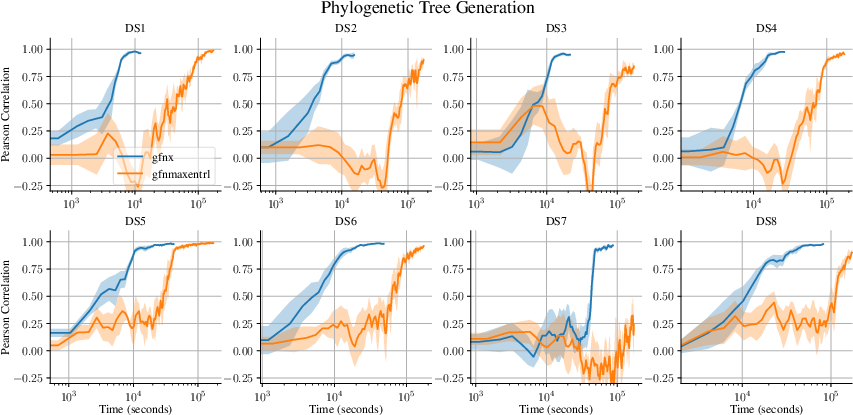
Figure 6: Phylogenetic tree generation—gfnx consistently converges faster and in many datasets is the only implementation to reach final metrics within compute budgets.
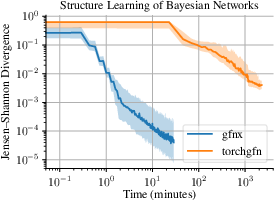
Figure 7: Structure learning for Bayesian DAGs—gfnx matches torchgfn in Jensen–Shannon divergence with nearly 80× wall-clock acceleration.
Notably, in structure learning and Bayesian inference, support for vectorized, JIT-compiled environments enables fast incremental updates of graph adjacency structures, efficient constraint enforcement (e.g., acyclicity via online mask updates), and rapid computation of reward delta scores, yielding a substantial reduction in per-iteration latency.
Implementation Details and Methodological Rigor
All core objectives (DB, TB, SubTB, FLDB, MDB) are carefully implemented to allow identical evaluation and training regimes as in canonical PyTorch benchmarks, ensuring comparability of empirical studies and reproducibility. For each setting, batch sizes, model architectures, optimizers, and exploration strategies are aligned with the original studies or improved to leverage vectorization/parallelism offered by JAX.
In environments where the empirical target can be computed exactly (e.g., small hypergrids, TFBind8), all sampling statistics are directly matched to the closed-form ground truth, providing unbiased measurement of convergence and mode coverage.
Implications for Practitioners and Directions for Future Research
Practically, gfnx enables rapid large-scale experimentation for tasks such as hyperparameter search, statistical ranodmization, and empirical benchmarking—core requirements for rigorous RL and GFlowNet research. The full JAX stack positions the package for integration with existing JAX RL environments and ecosystem tools, enabling seamless experimentation with distributed training, novel architectural variants, and advanced optimization pipelines.
On a theoretical level, easy manipulation of reward and environment dynamics lowers the barrier for developing and validating new GFlowNet objectives, backward policy learning algorithms, multi-objective extensions, and exploration techniques. Rapid iteration and benchmarking will directly accelerate advances in model-based and amortized sampling domains.
The current package is limited to discrete action/state spaces and environments with strict acyclicity assumptions. The roadmap for future development includes:
- Continuous action/state extensions for tasks requiring mixed discrete-continuous structure.
- Non-acyclic and partially acyclic environments, in response to recent theoretical advances relaxing standard GFlowNet constraints.
- Multi-objective sampling—native support for Pareto-optimal diversity exploration.
- Expanded RL algorithm baselines (e.g., entropy-regularized/maximum-entropy RL, backward policy optimization, novel exploration heuristics).
- Full trainer vectorization for massive-scale hyperparameter sweeps and ensemble runs.
Conclusion
gfnx represents a substantial technical advance for GFlowNet research by delivering a performant, fully JAX-based library with broad environment support, objective transparency, and far superior runtime characteristics relative to legacy systems. The design choices—modularity, end-to-end compilation, decoupling of reward/environment/training code—facilitate method development and empirical comparison at scale. With open-source code and comprehensive documentation, gfnx is poised to become the new reference platform for researchers and practitioners seeking rapid, reproducible, and scalable experimentation in generative flow network modeling (2511.16592).