- The paper presents TimeViper, a hybrid architecture that compresses long video frames into text tokens via a novel TransV module for efficient processing of over 10,000 frames.
- It combines a ViT encoder, token merging, and a hybrid MLLM backbone to reduce token redundancy and computational cost while maintaining high performance on video benchmarks.
- Ablation studies indicate that both uniform and attention-guided token dropping methods effectively compress tokens with negligible accuracy loss in QA, grounding, and captioning tasks.
Introduction
The challenges of long video understanding stem from the need to efficiently process extended temporal contexts and eliminate redundancy. Standard Transformer-based MLLMs possess expressive multimodal reasoning but are limited by quadratic attention complexity, impeding practical handling of hour-long videos. State-space models such as Mamba provide linear-time sequence modeling but have less robust multimodal capabilities. This paper introduces TimeViper, a hybrid architecture integrating Mamba-2 and Transformer layers with TransV, an internal token transfer module designed to enable scalable video understanding with over 10,000 frames by compressing visual information into text instruction tokens within the LLM.
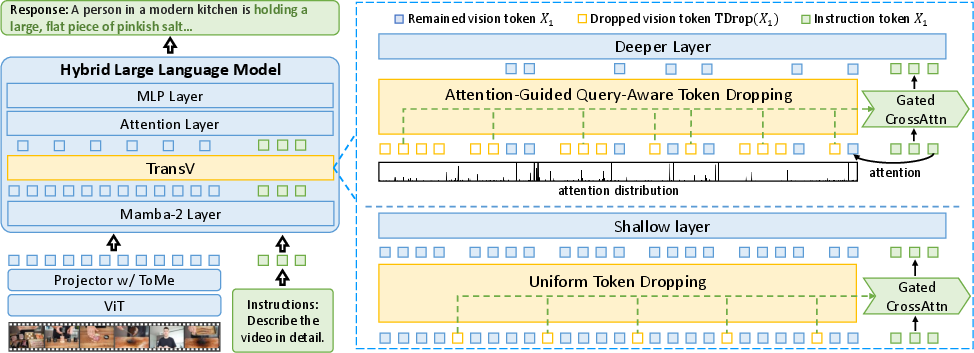
Figure 1: Overview of the TimeViper architecture, featuring a ViT encoder, projector with token merging, and a hybrid Mamba-Transformer LLM equipped with the TransV module.
Architecture and Internal Compression Mechanism
The TimeViper model comprises three main components: a ViT visual encoder, a token-merging projector, and a hybrid LLM backbone combining 27 Mamba-2 layers, 4 self-attention layers, and 25 MLP layers. Video frames are encoded and projected using Token Merging (ToMe) to compress each frame into 16 tokens, feeding long video sequences into the multimodal LLM.
The central innovation is TransV, which operates within the LLM to explicitly transfer and compress redundant vision tokens into instruction tokens. TransV utilizes gated cross-attention and adaptive learnable scalars, supporting both uniform and attention-guided dropping strategies at different layer depths. Experimental attention analysis reveals that in both instruction-centric and vision-centric tasks, vision token information progressively transfers to text tokens in deeper layers, leading to significant redundancy among vision tokens.
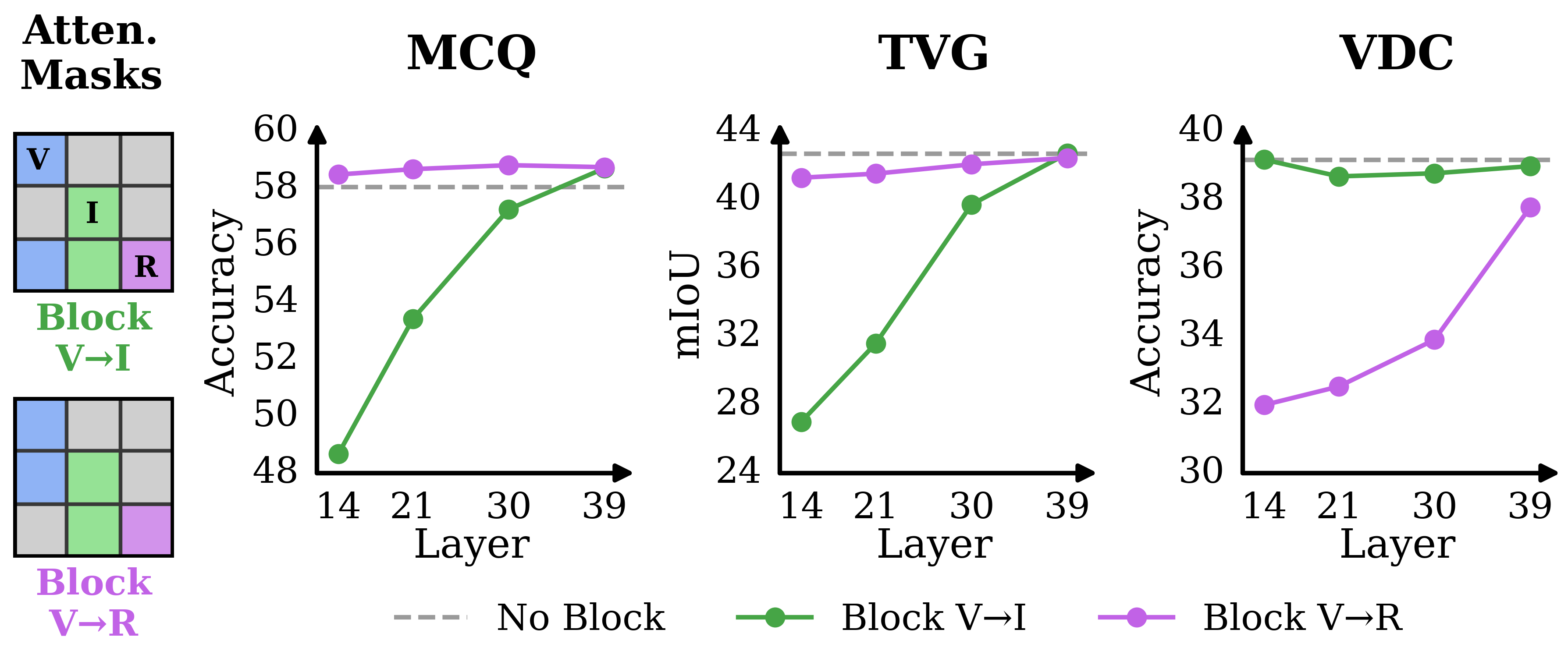
Figure 2: Illustration of the vision-to-text information aggregation phenomenon and information blocking in hybrid MLLMs for instruction- and vision-centric tasks.
Empirical Analysis of Token Redundancy
TimeViper's ablation studies examined two vision token dropping methods: uniform dropping and attention-guided dropping. Results demonstrate that token redundancy in hybrid MLLMs increases with layer depth. Uniform dropping is effective across layers, while attention-guided dropping becomes reliable in deeper layers only. In the deepest layers, removing all vision tokens does not significantly degrade performance, substantiating the model's internal aggregation of visual information into text tokens.
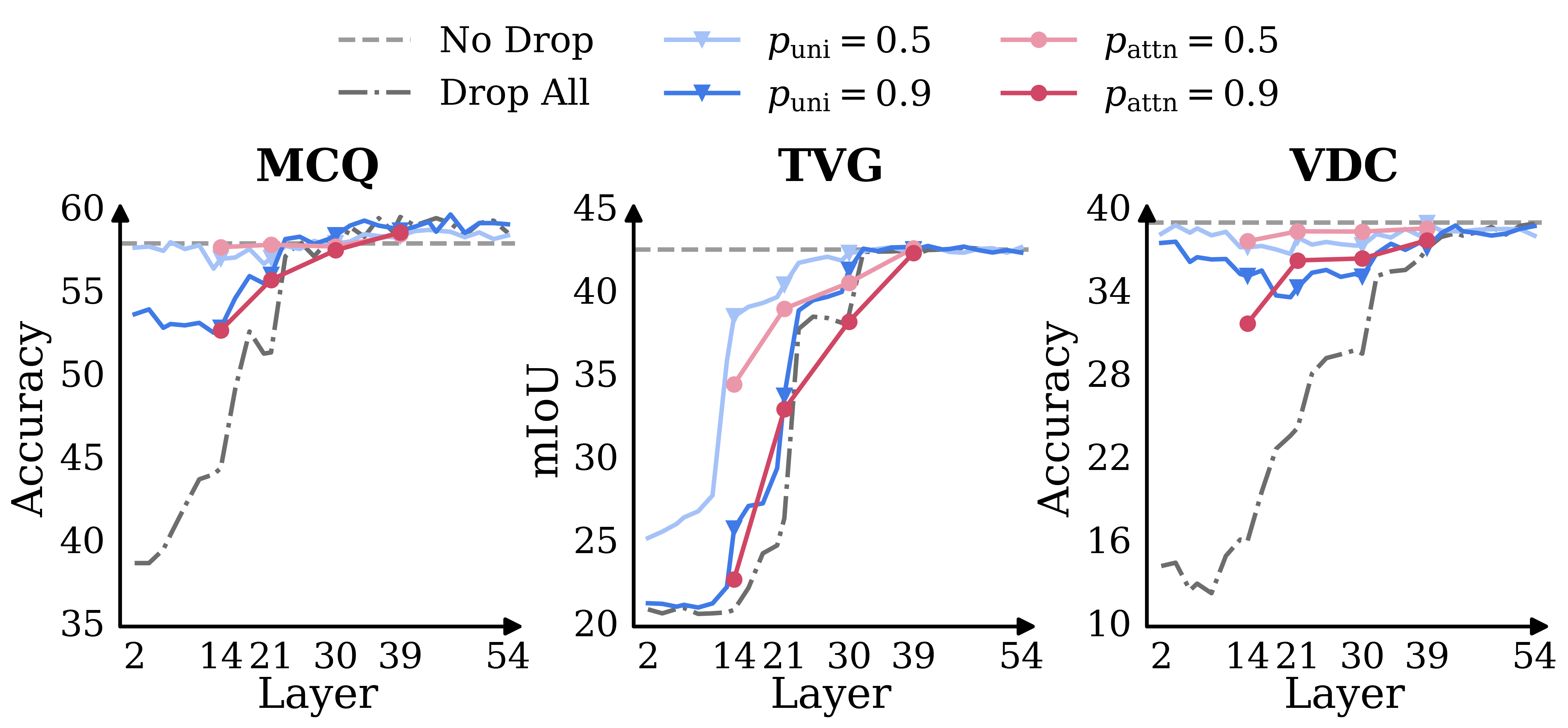
Figure 3: Token redundancy analysis: performance under different vision-token dropping rates using uniform and attention-guided strategies across layer depths.
These findings motivated the explicit token transfer mechanism of TransV, which effectively reduces computational costs for long video inputs while preserving multimodal task performance.
Benchmarking and Numerical Results
TimeViper was evaluated on diverse video understanding benchmarks: VideoMME (multi-choice QA), Charades (temporal video grounding), VDC (detailed video captioning), LVBench (hour-long video QA), and others. Despite not fine-tuning the ViT encoder, TimeViper with TransV matches or exceeds competing Transformer-based and hybrid models of similar scale:
- VideoMME (MCQ): TimeViper w/ TransV achieves 56.2 average accuracy vs 55.5 for Video-XL, using identical training data, and processes inputs exceeding 10,000 frames.
- Charades (TVG): TimeViper achieves an mIoU of 40.5, outperforming VTimeLLM-13B and matching models that employ explicit temporal positional embeddings.
- VDC (captioning): Achieves 39.7 accuracy, marginally exceeding task-specific AuroraCap.
TransV enables expansion of supported frame counts from 5k to over 10k with negligible accuracy loss (≤0.1 points) on VideoMME and without catastrophic loss on grounding and captioning tasks.

Figure 4: Qualitative results on MCQ, TVG, and VDC tasks, illustrating accurate reasoning, event localization (IoU=0.75), and detailed video captioning.
Analysis of Attention Patterns and Model Behavior
Attention score visualization revealed that Mamba layers exhibit diverse and specialized patterns—sparsity, locality, globality—providing selective reinforcement of salient tokens and efficient long-term dependency modeling. Self-attention layers in the hybrid model demonstrate "attention sink" phenomena typical of Transformers, with strong concentration of attention on initial tokens.
On average, hybrid MLLMs like TimeViper maintain stronger attention to vision tokens across all layers compared to Transformer-only models, emphasizing their enhanced capacity for visual evidence extraction even with aggressive token compression.
Implications for AI and Future Directions
The TimeViper architecture illustrates that hybrid state-space/attention models with internal LLM token compression offer scalable, data-efficient solutions to long video understanding. The vision-to-text aggregation phenomenon and strong redundancy of vision tokens in deep layers present new opportunities for model interpretability and compression, suggesting that future research can exploit token transfer mechanisms for even greater scalability, lower latency, and resource efficiency.
Expansion of instruction- and vision-centric benchmarks, scaling with larger and more diverse datasets, and development of more sophisticated token transfer modules for multimodal sequence modeling are natural next steps. Integration of explicit temporal modeling, alternative attention strategies, and multimodal memory could further enhance the reasoning and localization capabilities of hybrid MLLMs.
Conclusion
TimeViper introduces a hybrid Mamba-Transformer vision-LLM equipped with TransV, enabling efficient and accurate hour-long video understanding via internal LLM token compression. The investigation of token redundancy and vision-to-text aggregation elucidates mechanisms for scalable multimodal inference, with empirical results supporting competitive or superior performance against contemporary benchmarks in multi-choice QA, temporal grounding, and captioning. The research provides foundational insights for future deployment and optimization of hybrid MLLMs in large-scale video and embodied AI environments (2511.16595).