- The paper introduces SAM2S, an extended surgical video segmentation model that integrates DiveMem, TSL, and ARL to enhance long-term tracking and semantic consistency.
- The methodology utilizes the SA-SV benchmark—the largest surgical video dataset—to bridge the domain gap and support robust, zero-shot evaluations across procedures.
- Empirical results highlight significant gains in segmentation accuracy and real-time performance, indicating SAM2S's potential for autonomous surgical assistance and intraoperative guidance.
SAM2S: Enhanced Surgical Video Segmentation via Semantic Long-term Tracking
Motivation and Contributions
Surgical video segmentation plays a pivotal role in computer-assisted surgery, supporting instrument and tissue localization, intraoperative guidance, and skill assessment. However, foundational iVOS models such as SAM2 are challenged by the domain gap between natural and surgical videos and are particularly limited by long-term tracking failures, suboptimal semantic modeling, and inconsistencies arising from multi-source annotations.
This work introduces two cornerstone advancements:
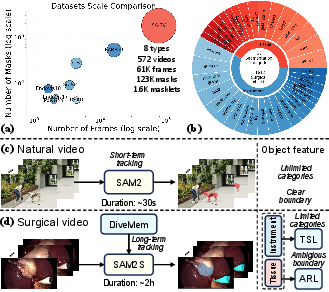
- SA-SV Benchmark: The largest and most comprehensive surgical iVOS dataset to date, offering instance-level, temporally consistent masklets spanning eight distinct surgical procedures with 61k frames and 1.6k annotated masklets. This enables robust model development and zero-shot evaluation under realistic, long-duration, and ambiguous clinical conditions.
- SAM2S Model: An extension of SAM2 tailored for surgical video, comprising:
Benchmark Construction and Dataset Analysis
The SA-SV benchmark addresses the deficiencies of existing surgical datasets by unifying diverse video sources with systematic masklet annotation, temporal ID consistency, and large-scale manual corrections vetted by surgical experts. It integrates annotations from 17 open-source datasets, enabling multi-institutional generalization assessment and cross-procedure transfer learning. In addition, it contains long-duration test sets (e.g., CIS-Test with 1,807s mean length), exceeding the temporal coverage of conventional VOS datasets by an order of magnitude, directly confronting the memorization and domain constraints seen in surgical environments.
Methodological Innovations in SAM2S
1. Diverse Memory Mechanism (DiveMem)
SAM2's original memory is predominantly short-term and heavily biased towards recent frames, resulting in viewpoint overfitting and memory saturation in lengthy surgical procedures. DiveMem addresses this through:
- Probabilistic temporal sampling during training: Ensuring representation of both local and distant contexts.
- Diversity-based frame selection at inference: Prioritizing frames most divergent (in feature space) from current long-term memory state and backed by confident IoU predictions, thereby augmenting resilience to camera motion, occlusions, and target reappearances.
2. Temporal Semantic Learning (TSL)
Surgical instruments are drawn from a finite taxonomy and are semantically consistent across datasets. TSL integrates a CLS token that fuses historical and current features, further guided by a CLIP-based vision-language objective to align masklet features with semantic instrument types. This step preserves the class-agnostic flexibility of the model while strengthening temporal coherence and category disambiguation, particularly during instrument switching or prolonged absences.
3. Ambiguity-Resilient Learning (ARL)
Tissue boundary labeling is inherently ambiguous and heterogeneous across datasets. ARL generates soft labels by applying Gaussian smoothing to discrete, hard labels, thus transforming ambiguous margin annotations into probabilistic guidance. Training with focal loss on these softened targets curtails overconfidence and increases robustness in uncertain or contentious regions.
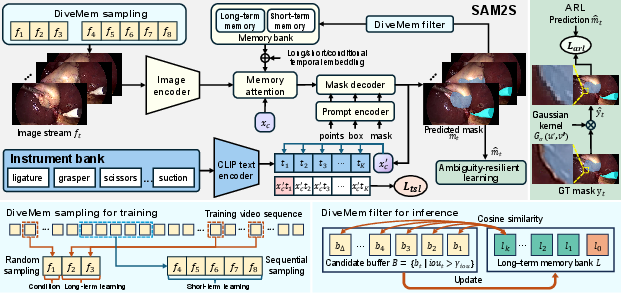
Figure 2: Architecture of SAM2S, illustrating the integration of DiveMem for memory, TSL for semantic alignment, and ARL for ambiguity management in surgical video segmentation.
Empirical Evaluation and Analysis
Extensive cross-benchmark experiments demonstrate:
- Fine-tuning on SA-SV yields a 12.99 point increase in average JF for SAM2 over vanilla, underscoring the necessity of domain-adaptive data.
- SAM2S achieves 80.42 average JF, further outperforming both vanilla SAM2 (by 17.10 points) and fine-tuned SAM2 (by 4.11 points), while sustaining 68 FPS real-time inference on an A6000 GPU.
- Zero-shot generalization: On the nephrectomy test sets (not seen during training), SAM2S preserves superior performance, establishing a strong foundation for cross-procedural deployment and robust domain transfer.
Prompt ablation reveals SAM2S's improvements persist across minimal (1-click) and maximal (GT mask) initialization regimes. Additionally, multi-component ablation isolates the impact of each proposed module, showing DiveMem and TSL provide marked gains for prolonged instrument tracking, while ARL particularly benefits tissue segmentation in ambiguous settings.

Figure 3: Qualitative segmentation results on RARP50, revealing SAM2S's persistent identity tracking and error mitigation over long temporal gaps compared to various SAM2 and baseline variants.
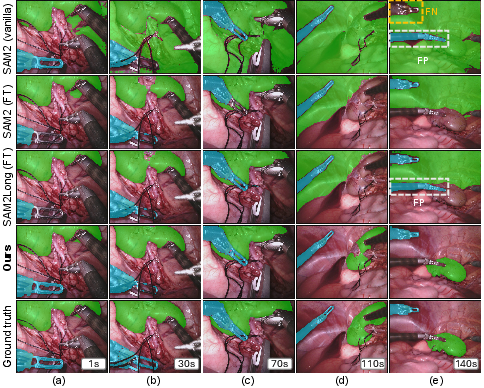
Figure 4: Qualitative comparison on EndoVis18, demonstrating SAM2S's superior tissue and boundary segmentation under rapid motion and occlusion.
Implications and Future Prospects
Practically, robust surgical video segmentation as enabled by SAM2S has immediate implications for autonomous robotic assistance, augmented intraoperative navigation, and real-time decision support. Theoretically, the work substantiates the synergy of semantic and temporal memory modeling, and highlights ambiguity-aware supervision as critical for deploying AI in high-stakes clinical settings.
Future research directions include:
- Extension to multi-modal and multi-camera surgical video fusion, leveraging persistent semantic tracking.
- More granular ambiguity modeling, integrating surgical ontology knowledge and probabilistic boundary estimation.
- Continuous learning to accommodate novel instrument types, patient-specific anatomical variations, and evolving surgical standards.
Conclusion
This work delivers a cohesive framework—dataset, methodology, and evaluation—for advancing interactive surgical video object segmentation. The introduction of SA-SV and SAM2S substantially narrows the gap between generic video segmentation models and the domain-adapted requirements of real-world surgical environments, providing a reference toolkit for future research at the intersection of vision foundation models and medical robotics.