- The paper introduces an iterative visual rumination approach that employs closed-loop frame selection and zooming to refine pixel-grounded reasoning for text-rich videos.
- It uses a multi-stage training protocol combining supervised and reinforcement learning to optimize atomic-to-compositional reasoning, achieving significant improvements like 64.21% accuracy on specific tasks.
- The approach generalizes across diverse video QA benchmarks and applications, enhancing interpretability and robustness in multimodal reasoning.
Video-R4: Reinforcing Multimodal Video Reasoning via Iterative Visual Rumination
Motivation and Overview
Contemporary video QA systems struggle with text-rich videos due to small, transient textual cues that require iterative inspection across frames and spatial regions. Most existing architectures process fixed sets of frames in a single pass, relying on text-only chain-of-thought (CoT) reasoning, and lack mechanisms to revisit or refine evidence, causing failures on fine-grained, pixel-grounded queries. To address these limitations, "Video-R4: Reinforcing Text-Rich Video Reasoning with Visual Rumination" (2511.17490) introduces Video-R4, a Large Multimodal Model (LMM) that operationalizes visual rumination — mimicking human strategies such as pausing, zooming, and re-reading — through explicit decision steps: selecting frames, zooming on critical regions, re-encoding high-resolution pixels, and updating its internal state with new evidence.

Figure 1: Video-R4 executes closed-loop visual rumination cycles, iteratively selecting frames and regions for refined pixel-grounded reasoning.
Data Curation and Rumination Trajectories
A key innovation is the construction of two complementary datasets for learning deliberate and compositional visual rumination:
- Video-R4-CoT-17k: Supervised, fine-grained, multi-step CoT trajectories synthesized from the M4-ViteVQA benchmark and additional sources. Evidence matching employs rule-based alignment between answers and OCR tokens/object labels with fuzzy search, yielding explicit chains of visual and textual operations.
- Video-R4-RL-30k: Samples curated for reinforcement learning, targeting unanswered or difficult cases for further exploration and policy improvement.
This pipeline enables the supervision of both atomic visual operations (frame clipping/cropping) and their composition across temporal and spatial domains.
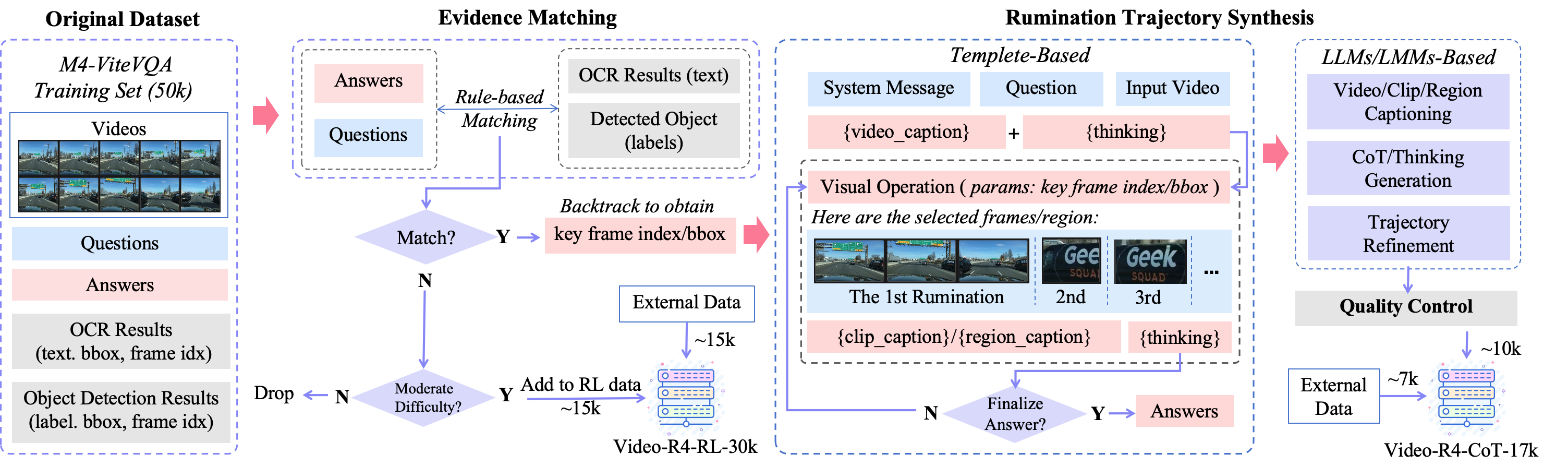
Figure 2: The data curation pipeline produces deliberate and compositional rumination trajectories for both supervised and reinforcement learning stages.
Multi-Stage Rumination Training Framework
Video-R4 adopts a four-stage training protocol for optimal acquisition and compositionality:
- Deliberate Rumination Practice (DRP-SFT): Supervised learning of isolated atomic operations (cropping or clipping) to establish strong spatial/temporal selection skills.
- First RL Stage (RL-d): GRPO-based policy optimization incentivizing correct use of atomic operations.
- Compositional Rumination Practice (CRP-SFT): Supervised interleaving of cropping and clipping with multi-step reasoning, distilled from DRP-SFT checkpoints.
- Second RL Stage (RL-c): Final policy refinement using compositional trajectories, optimizing when to stop, when to revisit, and allocation of rumination depth.
Group Relative Policy Optimization (GRPO) drives reinforcement, using group-wise advantages for sampled trajectories — stabilizing RL by relative rather than absolute ranking. The reward integrates answer correctness, operational diversity, representativeness (viz. coverage in feature space), and a curiosity-driven exploration term to balance operation frequency.
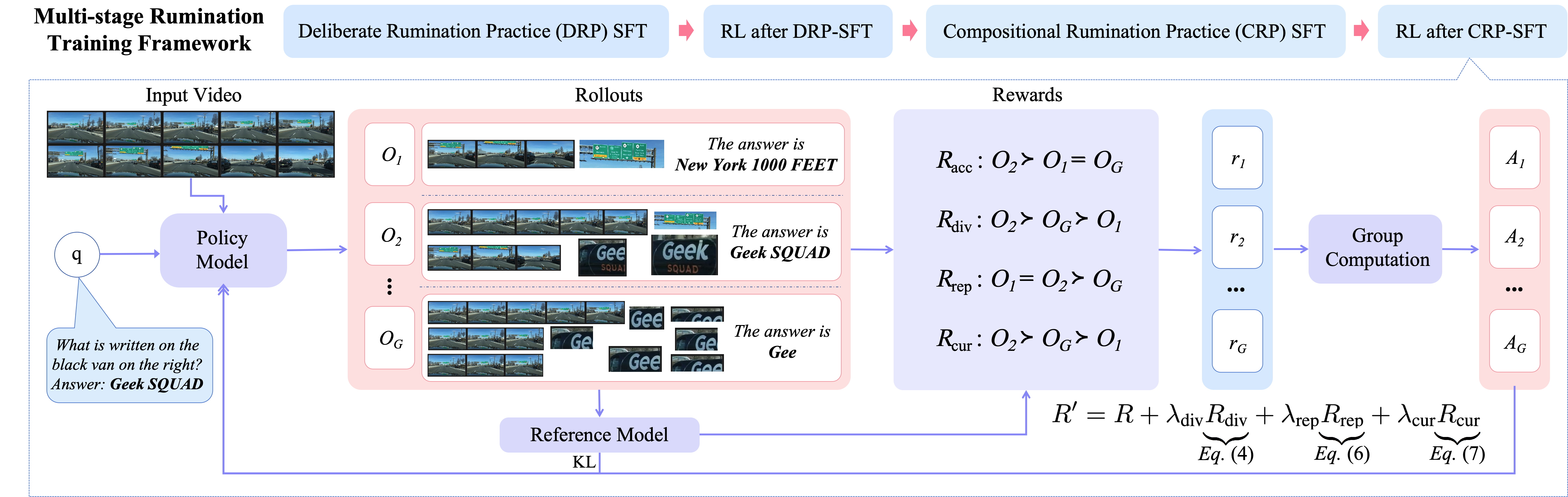
Figure 3: Overview of the multi-stage rumination training pipeline guiding Video-R4 from atomic skills to full compositional reasoning.
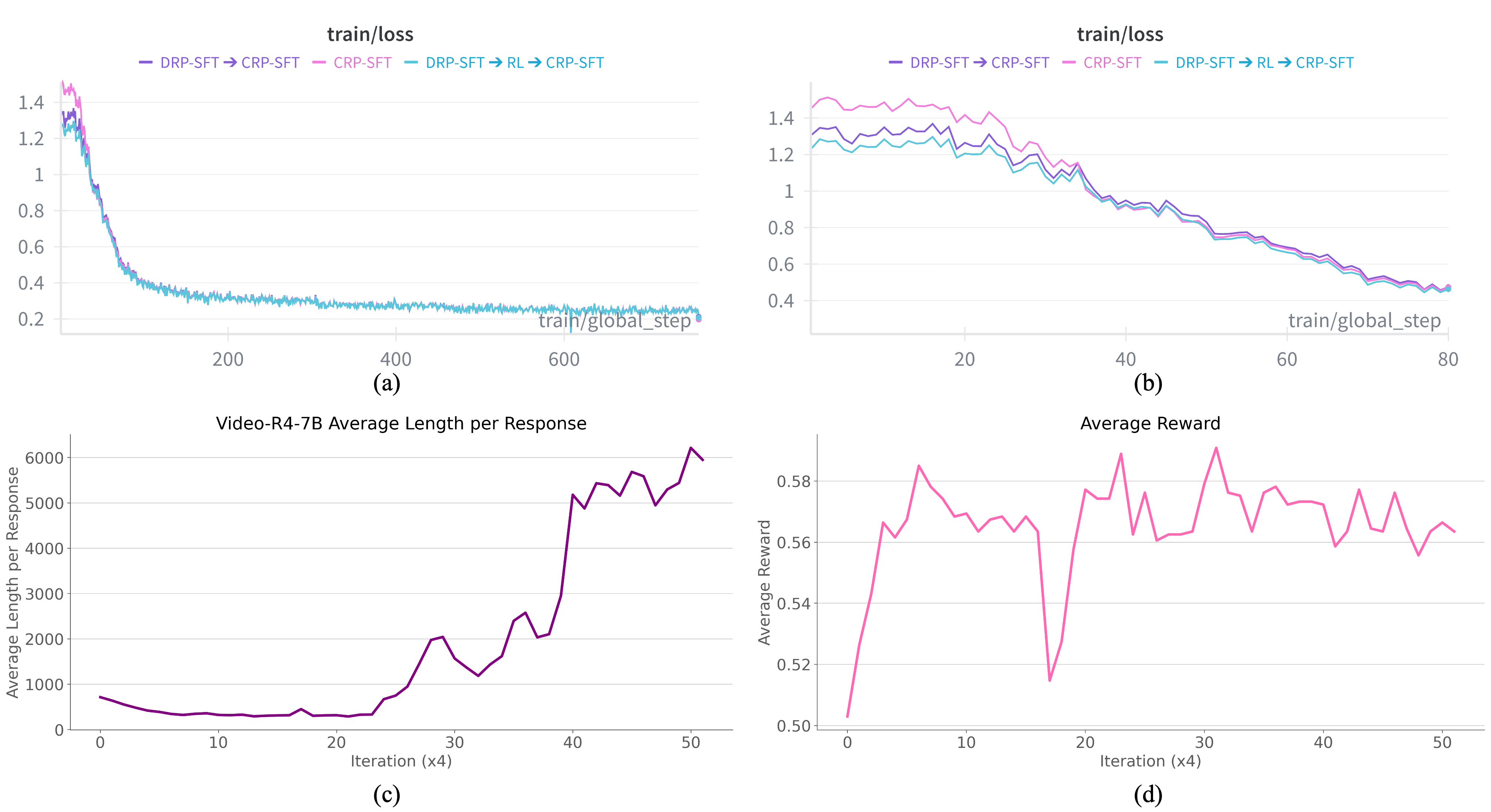
Figure 4: Models initialized with DRP-SFT converge faster and attain lower loss; RL stages induce longer chains and stable reward profiles, evidencing better allocation of reasoning steps.
Experimental Results and Ablations
Video-R4-7B achieves state-of-the-art results on M4-ViteVQA, substantially surpassing all non-human baselines. Notably:
- Task 2: 64.21% accuracy (vs. 43.16% for Video-R1-7B; previous SOTA).
- Test-time Scaling: Allowing more visual rumination steps monotonically increases accuracy.
- Generalization: Without dataset adaptation, Video-R4-7B is near-top or best on MVBench, Video-MME, and sets a new best (52.2%) on Video-MMMU.
The ablation of the training recipe demonstrates that the DRP-SFT → RL-d → CRP-SFT → RL-c curriculum yields the highest accuracy, faster convergence, and more robust policy formation than collapsed or single-stage alternatives. Diversity and representativeness rewards prevent policy collapse to redundant or outlier selections; curiosity rewards regulate tool invocation frequency.
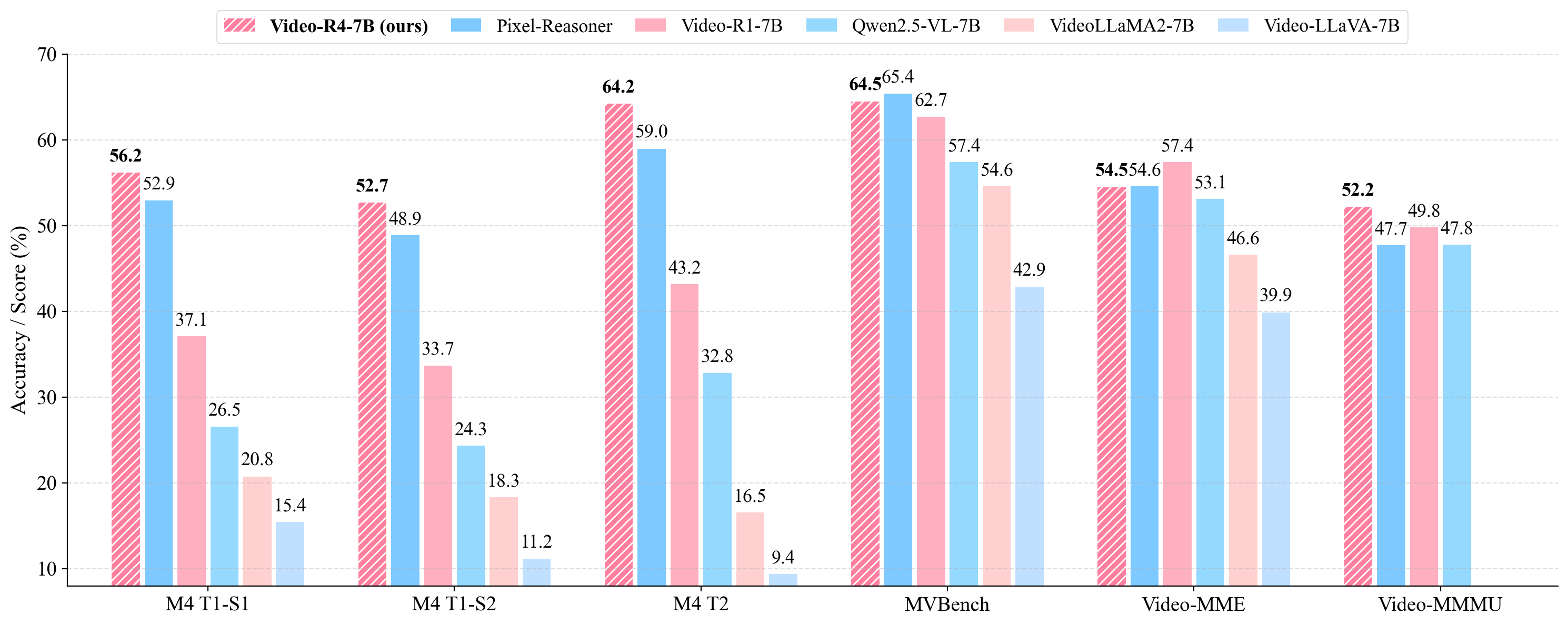
Figure 5: Video-R4-7B delivers optimal performance on text-rich video and general video QA benchmarks, outperforming competitive LMMs of equivalent scale.
Annotation and Visualization
A specialized annotation tool streamlines the verification and correction of multi-step chain-of-thought trajectories, ensuring high-quality supervision at scale. Visualizations illustrate model behaviors: preference for cropping (fine-grained zoom), emergent extended reasoning chains under RL, and stepwise evidence accumulation.
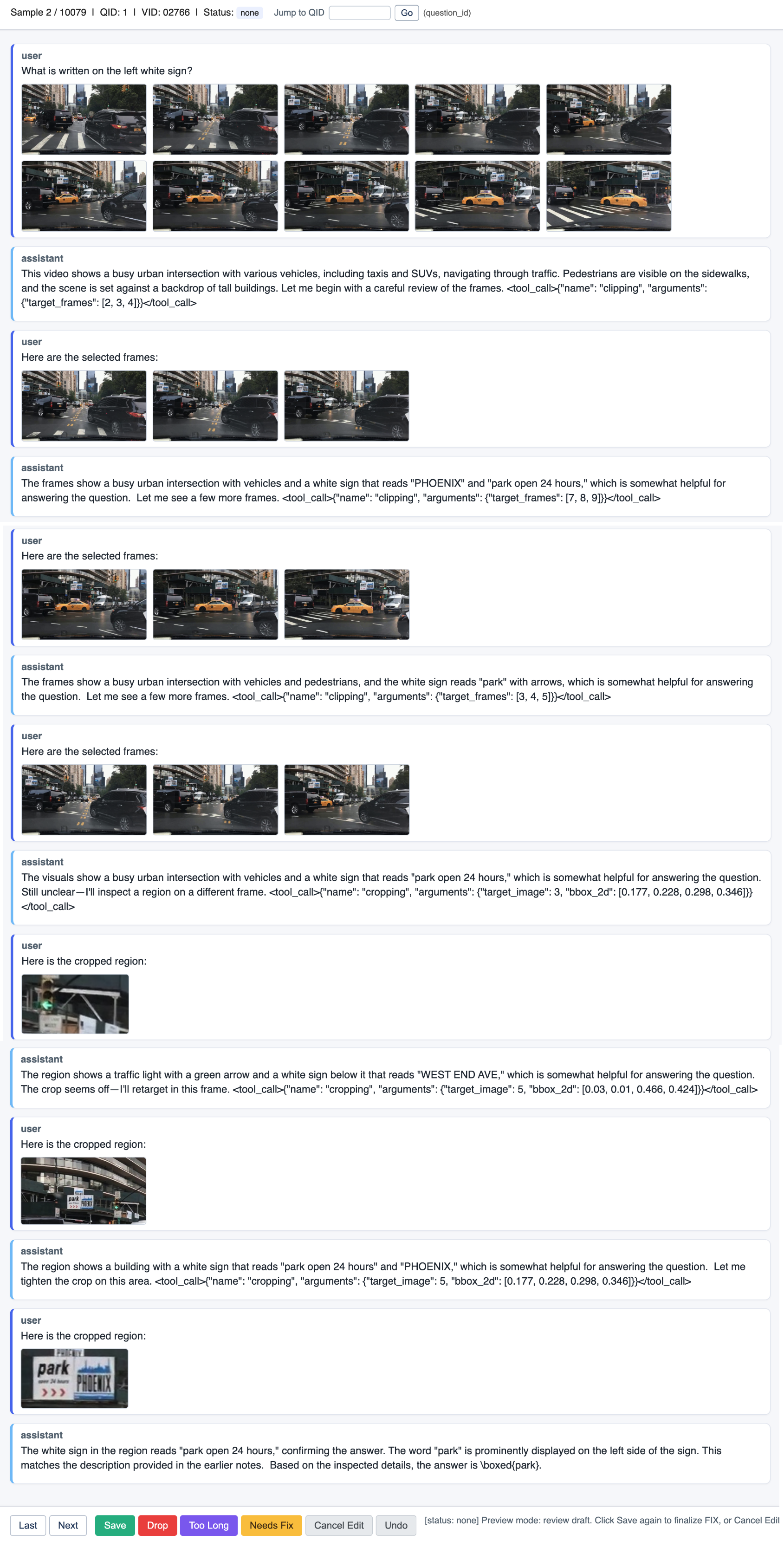
Figure 6: Interface for reviewing and refining QA chains with visual regional annotations, supporting precise trajectory curation.

Figure 7: Visualization of model rumination trajectories shows explicit chaining of spatial-temporal reasoning operations.

Figure 8: Example longer trajectories reflect emergent multi-step pixel-grounded reasoning.
Implications and Future Directions
The results substantiate several claims:
- Atomic → Compositional Instruction: Incremental, operation-specific learning interleaved with RL is essential for efficient rumination policy formation.
- Pixel-Grounded Reasoning: Iterative read–retrieve–refocus cycles enable robust retrieval and verification of small, transient textual cues.
- Cross-Domain Generalization: Training exclusively on text-rich video tasks fosters transfer to document QA and slides QA benchmarks, with no architecture changes nor further fine-tuning — directly challenging the notion that video QA must be domain-specialized.
Practically, Video-R4 demonstrates that equipping LMMs with explicit visual rumination tools and reinforcement-driven compositional curricula results in strong, robust, and interpretable performance on complex pixel-grounded multimodal tasks. Theoretically, this signals further research into tool augmentation (tracking, retiming, multimodal fusion), reward function design aligning closer to human concepts of faithfulness, and scaling to longer, more diverse video contexts.
Conclusion
Video-R4 establishes an explicit, iterative rumination paradigm for pixel-grounded video reasoning, operationalized via closed-loop selection and examination of informative frames and regions. Through a multi-stage supervised and RL-based training protocol, Video-R4 achieves state-of-the-art results on text-rich video benchmarks and generalizes robustly to other pixel-grounded multimodal reasoning tasks. Its curriculum and reward design highlight the foundational role of atomic-to-compositional learning and structured operation control for next-generation multimodal LMMs. The work opens avenues for longer-context reasoning, open-ended tool interfaces, and scalable curriculum RL frameworks in AI video understanding.