SPIDER: Spatial Image CorresponDence Estimator for Robust Calibration
Abstract: Reliable image correspondences form the foundation of vision-based spatial perception, enabling recovery of 3D structure and camera poses. However, unconstrained feature matching across domains such as aerial, indoor, and outdoor scenes remains challenging due to large variations in appearance, scale and viewpoint. Feature matching has been conventionally formulated as a 2D-to-2D problem; however, recent 3D foundation models provides spatial feature matching properties based on two-view geometry. While powerful, we observe that these spatially coherent matches often concentrate on dominant planar regions, e.g., walls or ground surfaces, while being less sensitive to fine-grained geometric details, particularly under large viewpoint changes. To better understand these trade-offs, we first perform linear probe experiments to evaluate the performance of various vision foundation models for image matching. Building on these insights, we introduce SPIDER, a universal feature matching framework that integrates a shared feature extraction backbone with two specialized network heads for estimating both 2D-based and 3D-based correspondences from coarse to fine. Finally, we introduce an image-matching evaluation benchmark that focuses on unconstrained scenarios with large baselines. SPIDER significantly outperforms SoTA methods, demonstrating its strong ability as a universal image-matching method.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SPIDER, a computer program that can find which tiny points (pixels) in one photo match the same real-world points in another photo. This is called “image correspondence.” Getting these matches right is the foundation for building 3D models, figuring out where a camera is in space (camera pose), and “calibrating” cameras so measurements are accurate. SPIDER is designed to work even when the two photos look very different—for example, when one is taken from the ground and the other from a drone, or when the angle and lighting change a lot.
What questions are the authors trying to answer?
They focus on two big questions:
- How can we find many true matches even when photos look very different (high sensitivity)?
- How can we avoid being tricked by look‑alike areas (high specificity), like matching a window on one building to a different window on another building?
Most older methods are good at one of these but not both. The authors want one system that balances both at the same time, and that stays strong in tough, real-world situations.
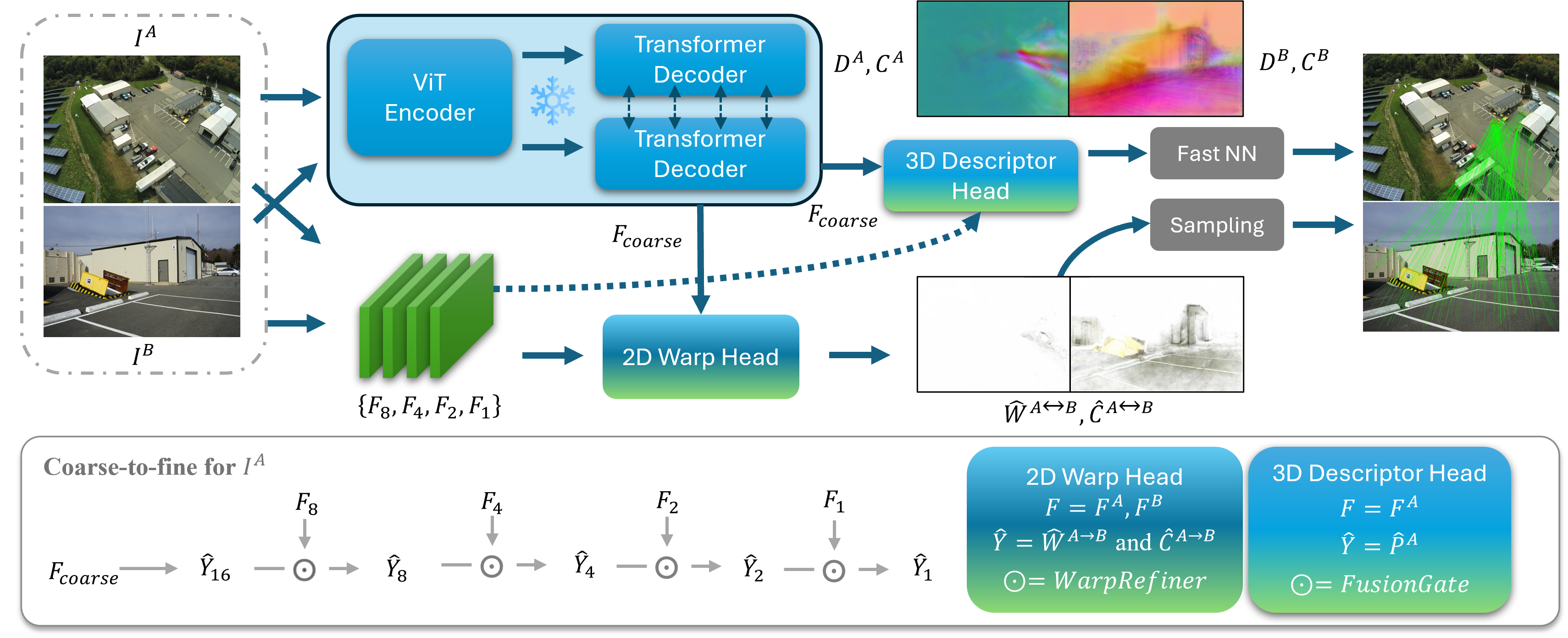
How does SPIDER work?
Think of matching points between two photos like identifying the same spots on a map: you want both a lot of correct dots and to avoid dots that look similar but are actually wrong.
SPIDER combines two kinds of “experts,” supported by a strong shared “backbone” that understands 3D.
The shared backbone: a 3D‑aware starting point
- SPIDER starts with a “3D vision foundation model” as its base. This is a deep neural network trained on many pairs of images so it learns how scenes look from different viewpoints.
- Because it has a sense of depth and geometry, this backbone helps SPIDER look beyond surface appearance (colors and textures) and think in 3D.
Adding fine details: a high‑resolution helper
- The 3D backbone is powerful but a bit “blurry” in fine detail (because it works on image patches).
- SPIDER adds a classic convolutional network that works at higher resolution to bring back crisp, local details—like sharp edges and small textures.
Two heads (two “experts”) that make matches
SPIDER has two matching heads that run from coarse to fine (first a rough guess, then refined):
- The geometry‑driven descriptor head
- It creates a “fingerprint” (a short numeric description) for each pixel. Matching is done by comparing fingerprints between the two images.
- Because it is guided by 3D understanding, it’s good at avoiding false matches on different objects that just look similar (high specificity).
- It uses “Fusion Gates,” which you can imagine as smart dimmer switches that blend coarse 3D knowledge with fine image details at multiple scales. This keeps the 3D consistency while adding local sharpness.
- The pattern‑driven warp head
- It directly predicts, for each pixel in image A, where that pixel should land in image B—like drawing a little arrow from one image to the other. This is called a dense “warp field.”
- It’s great at finding lots of matches even when the photos look different (high sensitivity), because it focuses on patterns in the images.
Putting it together
- SPIDER runs both heads and then picks confident matches from each, combining them. This blend brings the best of both worlds: the warp head finds many matches, and the descriptor head filters out look‑alike mistakes.
- Everything is done from rough to precise (coarse‑to‑fine), like zooming in step by step to refine the answer.
What did they find?
The authors tested SPIDER on many challenging benchmarks, including:
- Classic indoor and outdoor scenes (like ScanNet and MegaDepth).
- Aerial‑to‑ground scenes (drone vs. ground photos), which are especially hard because of huge viewpoint and scale changes.
- A large “zero‑shot” test (ZEB) with many unseen scenarios.
- New, tough “unconstrained” pairs they collected (city blocks with look‑alike buildings, warehouses, campuses with very different camera heights).
Across these tests, SPIDER:
- Achieved state‑of‑the‑art results, often scoring best or second‑best overall, and especially strong on the hardest cases like aerial‑to‑ground.
- Balanced sensitivity and specificity: it found many correct matches and avoided false ones on similar‑looking but different parts of the scene.
- Reduced “planarity bias” (the tendency to match mostly on big flat surfaces like walls or ground). Their measure of planarity dropped by about 30% (from 0.22 to 0.16), meaning matches were spread across different depths instead of clustering on one plane.
- Outperformed well-known single‑style methods:
- RoMa (appearance/pattern‑focused) often finds many matches but can mix up similar structures (like different windows).
- MASt3R (geometry‑focused) avoids look‑alike mistakes but sometimes misses matches when the view changes a lot.
- SPIDER combines their strengths for better overall performance.
In short, SPIDER keeps working when photos are taken from very different places, heights, or angles, and when scenes contain confusing repeating patterns.
Why does this matter?
Reliable matching between photos is the backbone of many things we use or want to build:
- Camera calibration and pose estimation (making sure cameras are measured and positioned accurately)
- 3D reconstruction (building 3D models from photos)
- Robotics and drones (understanding where they are and what’s around them)
- AR/VR and navigation (placing virtual objects correctly, localizing in the world)
By making matching both broad (sensitive) and careful (specific), SPIDER helps these systems become more robust in the real world—where images aren’t neat and controlled, and viewpoints can be wildly different.
Extra notes and limitations (in simple terms)
- SPIDER’s dual‑expert design and multi‑scale refinements make it a bit slower than some methods (about 30% more time than one of the backbones it uses).
- Combining the two heads’ confidence scores isn’t trivial, because each head measures “confidence” differently. Figuring out the best way to merge them is still an open research question.
Overall, SPIDER shows a practical path forward: use a 3D‑aware base to stay geometrically honest, add high‑res details to be precise, and blend two kinds of matchers to get both many good matches and fewer mistakes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed to inform actionable follow-up research.
- Optimal backbone choice: While linear probing suggests 3D VFM decoders outperform 2D backbones, the “optimal VFM choice” is left open; systematic comparisons across newer/backbone variants (e.g., different ViT patch sizes, hybrid ViT+CNN, deformable tokens, multi-scale ViT) and training scales are not explored.
- ViT patchification limitation: The claim that 16×16 patchification suppresses local details is not quantified; it remains unclear how smaller patches, learned tokenization, or multi-scale tokenization affect sensitivity/specificity and runtime.
- Confidence calibration across heads: The descriptor and warp heads produce confidence values under different objectives; there is no calibration analysis (e.g., ECE, Brier) and no principled fusion (e.g., probabilistic ensembling, evidential methods, temperature scaling) for comparable confidence across heads.
- Fusion strategy: Match fusion currently “evenly samples the two heads based on confidence” because other attempts degraded diversity; the best fusion strategy is open—e.g., adaptive per-scene fusion, graph-based joint reasoning, cross-head consistency checks, or meta-learned selectors.
- Joint training of dual heads: Joint training is found “suboptimal” due to gradient conflicts; the paper does not test task balancing techniques (e.g., uncertainty weighting, GradNorm, PCGrad, decoupled optimizers) or architectural decoupling to enable end-to-end joint optimization.
- Head interference mechanisms: Beyond anecdotal “objective conflicts,” the mechanisms by which warp and descriptor supervision interfere are not analyzed; quantifying gradient directions, representation overlap, and feature space drift could guide better multi-task design.
- Generalization to unknown or inaccurate intrinsics: Evaluation computes essential matrices with ground-truth intrinsics; robustness to unknown/approximate intrinsics, lens distortion, rolling shutter, and cross-sensor (e.g., fisheye, smartphone vs. drone) intrinsics is unexplored.
- Pose ground truth quality: Real scenes rely on COLMAP constrained by RTK-GPS; the impact of pose errors on training labels and evaluation is not quantified, nor are methods proposed to mitigate supervision noise (e.g., label smoothing, robust losses).
- Evaluation metrics coverage: Performance is reported via AUC@5°/20°; translation errors, reprojection RMSE, scale drift, and uncertainty metrics are not assessed, limiting understanding of failure modes and downstream calibration quality.
- Downstream tasks: Claims of benefits for SfM/novel view synthesis/3D reconstruction are not empirically validated; assessing improvements in complete pipelines (e.g., track length, triangulation rate, reconstruction completeness, NeRF quality) remains open.
- Extreme low-overlap and repetitive structures: Although unconstrained scenarios are included, systematic stress-testing under controlled overlap (<5%), strong parallax, repetitive textures, and fine-grained symmetries is limited; curated benchmarks and diagnostics would clarify boundaries of robustness.
- Dynamic scenes and occlusions: Robustness to dynamic objects, transient occlusions, and non-rigid motion is not evaluated; adaptation of SIM to motion segmentation or dynamic masking is an open avenue.
- Radiometric robustness: Sensitivity to illumination changes, weather, seasons, nighttime, exposure/gain differences, and sensor noise is not quantified; targeted experiments and augmentation strategies could close this gap.
- Scale/resolution scaling: All training/evaluation resize max dimension to 512 px; scalability to high-resolution inputs (e.g., 2–4K) and the associated memory/runtime trade-offs are untested, as are patch-size and feature-pyramid scaling laws.
- Efficiency and memory: Inference is ~30% slower than Aerial-MASt3R; there is no analysis of memory footprint, batch size sensitivity, or speed/accuracy trade-offs nor attempts at acceleration (e.g., pruning, distillation, quantization, mixed precision).
- Descriptor diversity vs. homography bias: Planarity ratio is reported for Aerial-MegaDepth only; broader measurement across domains and architectural interventions to encourage layer-wise depth coverage (e.g., diversity losses, anti-collapse regularizers) are open.
- Matching selection policy: “Even sampling” from both heads is heuristic; optimal selection count per head, spatial coverage constraints, and adaptive sampling based on scene geometry or confidence calibration are not explored.
- Mutual NN vs. global assignment: Descriptor matching uses nearest-neighbor filtering; global assignment formulations (e.g., Sinkhorn, graph matching, robust assignment with geometric priors) are not investigated for improved specificity.
- Robust geometric verification: The pipeline relies on essential matrix estimation; combining multi-homography, piecewise planar models, or hybrid fundamental–homography reasoning to handle mixed geometries is unaddressed.
- Multi-view and temporal integration: SPIDER is two-view; extension to N-view sequences, temporally consistent tracking, bundle adjustment integration, and leveraging multi-view constraints during training/inference are open questions.
- Self-supervised/weakly supervised training: Supervision requires ground-truth correspondences/pairs; self-supervised or synthetic supervision (e.g., cycle-consistency, photometric consistency, synthetic warps) to reduce reliance on labeled pairs is not examined.
- Dataset composition effects: The paper trains on 10 datasets with equal sampling; ablating dataset contributions, domain weighting, curriculum learning by difficulty, and active sampling are not studied.
- Backbone freezing vs. fine-tuning: Freezing the VFM backbone improves generalization in one setup; the conditions under which fine-tuning helps (e.g., limited-domain specialization) and strategies like LoRA/adapters are not explored.
- Bidirectional inference: The model runs both (A→B) and (B→A) at inference; the incremental benefit, consistency enforcement between directions, and methods to reduce computation while preserving accuracy are not analyzed.
- Cross-modal extension: Applicability to multimodal pairs (e.g., RGB–IR, RGB–depth, thermal, SAR) and to different sensors/domains (satellite, endoscopy) is untested.
- Robustness to extreme viewpoint changes: While wide-baseline is targeted, upper bounds of tolerable viewpoint and scale changes are not quantified; controlled synthetic experiments could map the performance envelope.
- Theoretical understanding: There is no theoretical analysis explaining the sensitivity–specificity trade-off and why dual heads succeed; formalizing the bias–variance trade-offs and deriving principled objectives remains open.
- Codebook or dictionary-based descriptors: Beyond learned dense descriptors, structured descriptors (e.g., codebooks, hashed embeddings) for efficiency/specificity are not explored.
- Open-source benchmarking: The unconstrained benchmark is introduced, but broader community adoption, detailed annotations, and standardized evaluation protocols (including dynamic scenes and intrinsics-unknown cases) are needed.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging SPIDER’s dual-head dense correspondence, wide-baseline robustness, and improved calibration and pose estimation.
- Robust aerial-to-ground image registration in photogrammetry pipelines
- Sector: geospatial, construction, civil engineering
- Workflow: plug SPIDER in place of or alongside existing matchers in COLMAP/MVS tools (e.g., OpenMVG, Metashape, RealityCapture) to align drone imagery with ground photographs; estimate essential matrix and refine camera poses; proceed with SfM/MVS.
- Potential tools/products: SPIDER-COLMAP matcher plugin; QGIS/ArcGIS extension for mixed-view alignment.
- Assumptions/dependencies: camera intrinsics known or approximated; minimal overlap >5–10%; GPU inference; handle repetitive structures via descriptor+warp fusion.
- Drone-based inspection alignment (wind turbines, solar farms, warehouses)
- Sector: energy, industrial inspection
- Workflow: fuse drone images with handheld or fixed camera views to localize defects and track changes; export correspondences to downstream analytics (crack detection, panel misalignment).
- Potential tools/products: inspection software module “SPIDER-Align” for mixed-view pose estimation.
- Assumptions/dependencies: consistent acquisition timestamps or metadata; enough multi-view coverage; onsite GPU/CPU resources.
- City-scale campus mapping from mixed sources
- Sector: urban planning, facilities management
- Workflow: align campus drone flights with mobile-phone tours to update 3D digital twins; reduce planarity bias to avoid homography-only reconstructions; feed into GIS.
- Potential tools/products: “SPIDER-Map Update” service; municipal digital twin integration.
- Assumptions/dependencies: privacy-compliant data collection; calibration of varied devices; policy compliance for public spaces.
- Visual relocalization and loop closure for robots under large viewpoint changes
- Sector: robotics, autonomy
- Workflow: use SPIDER’s geometry-aware descriptors for loop closure in SLAM; fall back to warp-based matches in low-texture regions; refine pose.
- Potential tools/products: ROS node “spider_match”; integration into ORB-SLAM/SuperGlue-based stacks.
- Assumptions/dependencies: compatibility with existing SLAM pose-graph optimizers; stable framerate/GPU.
- AR navigation and outdoor occlusion handling
- Sector: AR/VR, mobile software
- Workflow: calibrate phone camera to existing map imagery (drone/ground); robustly register views with significant scale differences; place virtual content accurately.
- Potential tools/products: SDK “SPIDER-AR Calibrate” for mixed-view anchoring.
- Assumptions/dependencies: access to reference imagery; mobile-optimized inference or cloud offload.
- Media stitching and time‑lapse alignment across wide baselines
- Sector: media/creative software
- Workflow: stabilize and stitch frames from different cameras/angles; use dense warp fields for sub-pixel alignment in timelapse or panorama editors.
- Potential tools/products: plugin for Adobe After Effects/Premiere/DaVinci “SPIDER Warp+Match”.
- Assumptions/dependencies: sufficient overlap and scene rigidity; compute overhead tolerance.
- Forensic and cultural‑heritage reconstruction from diverse imagery
- Sector: public safety, heritage preservation
- Workflow: align crowd-sourced images with official drone or archival photos to reconstruct scenes; use descriptor confidence to triage reliable correspondences.
- Potential tools/products: “SPIDER-Reconstruct” toolkit for mixed-media alignment.
- Assumptions/dependencies: chain-of-custody and metadata management; bias handling in repetitive structures.
- Cross-elevation visual place recognition
- Sector: location-based services
- Workflow: match ground photos to drone/survey imagery for place verification; improve retrieval by seeding with SPIDER’s correspondences.
- Potential tools/products: hybrid retrieval+matching service.
- Assumptions/dependencies: retrieval corpus availability; manageable inference latency.
- Academic benchmarking and method evaluation
- Sector: academia
- Workflow: adopt SPIDER as a baseline for image matching studies; use proposed unconstrained benchmark and linear probing to compare 2D/3D VFMs.
- Potential tools/products: research code, datasets, evaluation scripts.
- Assumptions/dependencies: reproducible training/inference; access to GPUs and datasets listed in the paper.
- Survey/GIS field workflows (rapid calibration on site)
- Sector: surveying, GIS
- Workflow: field operators capture ground photos; align to recent drone coverage; perform quick pose estimation to annotate features.
- Potential tools/products: “SPIDER Field Calibrate” mobile app with cloud backend.
- Assumptions/dependencies: network access for cloud inference if on-device compute is limited; basic camera intrinsics.
Long-Term Applications
Below are use cases that will benefit from further research, scaling, optimization, or domain adaptation before broad deployment.
- Real-time edge deployment on drones and smartphones
- Sector: robotics, mobile computing
- Potential tools/products: quantized SPIDER variants running on NPUs; on-drone calibration for autonomous flights in GPS‑denied or cluttered environments.
- Dependencies: model compression, latency/energy optimization, memory footprint reduction; robust fusion of dual-head confidences.
- Satellite-to-street view alignment for urban analytics
- Sector: geospatial, urban planning
- Potential tools/products: “SPIDER-GeoBridge” aligning high-altitude imagery with street-level views for change detection and asset mapping.
- Dependencies: domain adaptation to extreme resolution/appearance gaps; multi-sensor intrinsics; policy compliance for surveillance data.
- Automated insurance and claims assessment
- Sector: finance/insurtech
- Potential tools/products: claims platform using SPIDER to align pre/post event aerial/ground images to quantify damage.
- Dependencies: standardized capture protocols; liability and auditability; robust matching in heavily altered scenes.
- Disaster response mapping with citizen imagery fusion
- Sector: public policy, emergency management
- Potential tools/products: workflows to ingest ad hoc images and align to authoritative aerial surveys for rapid situational awareness.
- Dependencies: privacy safeguards, consent frameworks, trust scoring for correspondences; resilient performance under debris/occlusions.
- Digital twin maintenance for infrastructure at scale
- Sector: construction, transportation, energy
- Potential tools/products: continuous “SPIDER-Twin Sync” that merges multi-source imagery to keep BIM/GIS twins up to date.
- Dependencies: scalable pipelines; pose/mesh update governance; handling repetitive structures and very low overlap.
- Medical imaging scene mapping (e.g., endoscopy/laparoscopy)
- Sector: healthcare
- Potential tools/products: cross-view correspondences to calibrate camera trajectories in minimally invasive procedures, enabling 3D reconstructions.
- Dependencies: significant domain-specific retraining; handling specular highlights, non-rigid tissue motion; regulatory clearance.
- Autonomous driving map updates from aerial fleets
- Sector: automotive
- Potential tools/products: align aerial sweeps with vehicle dashcam data to refresh HD maps and validate lane-level geometry.
- Dependencies: temporal synchronization; robust matching in dynamic urban scenes; OEM integration and safety assurance.
- Privacy-preserving cross-view calibration services
- Sector: policy, platform governance
- Potential tools/products: federated or on-device correspondence estimation to avoid centralizing raw images; confidence-calibrated sharing.
- Dependencies: privacy-preserving ML (federated, differential privacy), policy frameworks, explainability of match confidence.
- Unified multi-sensor calibration (cameras + LiDAR/Radar)
- Sector: robotics, surveying
- Potential tools/products: extend SPIDER’s geometry-aware descriptors to guide cross-modal registration.
- Dependencies: multimodal training regimes; sensor synchronization; robust cross-domain feature fusion.
- Consumer-grade 3D scanning across heterogeneous cameras
- Sector: consumer software
- Potential tools/products: apps that aggregate family/friend photos and occasional drone shots to create detailed models.
- Dependencies: UX for capture guidance; cloud scaling; deconflicting repetitive structures and extremely low-overlap cases.
Cross-cutting assumptions and dependencies to consider
- Compute and latency: current SPIDER inference adds ~30% overhead versus Aerial-MASt3R; GPU or NPU acceleration often required; mobile/edge optimization necessary for real-time.
- Image conditions: minimal overlap, some scene rigidity, and access to camera intrinsics (or good estimates) improve success; highly repetitive textures can cause head disagreement.
- Confidence fusion: dual-head confidences are not directly comparable, and naive fusion can yield inconsistent matches; application-specific fusion strategies may be needed.
- Data and domain: performance depends on training coverage; domain shifts (satellite, medical) require adaptation; ethical and legal constraints (privacy, consent) apply in public spaces.
- Integration: best results arise when SPIDER outputs feed established geometry estimators (e.g., essential matrix via RANSAC) and SfM/MVS pipelines; robust pose-graph optimization remains important.
Glossary
- Aerial-MegaDepth: A large-scale aerial-to-ground dataset used for training and evaluation of image matching methods. "Aerial-MegaDepth~\cite{vuong2025aerialmegadepth} subset"
- AUC@20°: Area under the cumulative distribution of camera pose errors up to 20 degrees, used to assess pose estimation accuracy. "evaluate using unconstrained matching with camera pose error AUC@20\degree."
- AUC@5°: Area under the cumulative distribution of camera pose errors up to 5 degrees, measuring two-view geometry accuracy. "measured by AUC@5\degree."
- BCE (Binary Cross-Entropy): A loss function used for binary classification tasks, here to supervise confidence prediction. "binary cross-entropy (BCE) term for confidence prediction"
- bidirectional evaluation: Running a model on both image orderings to improve robustness of correspondence estimation. "we perform a bidirectional evaluation"
- Charbonnier: A robust loss function (generalized Charbonnier distribution) that reduces sensitivity to outliers in regression tasks. "formulated as a generalized Charbonnier~\cite{barron2019general} distribution"
- COLMAP: A photogrammetry pipeline for structure-from-motion and multi-view stereo used for camera calibration. "calibrated using COLMAP constrained by RTK-grade GPS."
- confidence map: A per-pixel map indicating the reliability of predicted correspondences or descriptors. "confidence map at scale~16"
- coarse-to-fine: A hierarchical approach that refines predictions from low-resolution (coarse) to high-resolution (fine) scales. "operates in a coarse-to-fine manner"
- covisibility ratio: The fraction of scene content visible in both images of a pair, used to characterize overlap. "covisibility ratios between 0.1 and 0.2."
- cross-attention: A transformer mechanism that aligns features across views, learning geometric relations. "cross-attention decoders employed by common 3D VFMs"
- cross-view completion: A pretext task where a model reconstructs one view from another to learn geometry-aware features. "introduces cross-view completion as a pretext task"
- dense correspondences: Pixel-level matches between two images enabling fine-grained geometric estimation. "Dense Correspondences."
- DUSt3R: A 3D foundation model that regresses pointmaps and learns view transformations via cross-attention. "DUSt3R~\cite{wang2024dust3r}"
- end-point error (EPE): Average Euclidean distance between predicted and ground-truth correspondences, measuring precision. "Lower EPE and higher PCK@32 indicate better performance."
- essential matrix: A 3×3 matrix encoding relative rotation and translation between two calibrated cameras. "by computing the essential matrix using the ground-truth camera intrinsics."
- fastNN: A fast nearest-neighbor strategy used to sample correspondences from descriptors. "Final correspondences are sampled from the predicted warp and fastNN."
- feed-forward pass: A single inference pass through the network without iterative optimization. "in a single feed-forward pass."
- fundamental matrix inlier ratio: The proportion of correspondences that fit a fundamental matrix model, used for geometric verification. "fundamental matrix inlier ratio 0.6."
- Fusion Gate: An attention-based module that blends multi-scale features to refine descriptors. "Fusion Gate modules."
- homography: A planar projective transformation relating two views of a plane, which can dominate matches on planar scenes. "when all the matches lie on one plane and lead to homography"
- InfoNCE: A contrastive loss that pulls matched descriptors together while pushing non-matches apart. "InfoNCE-based objective"
- kernel nearest-neighbor matching: A correspondence strategy that uses kernelized similarity to find nearest neighbors. "via kernel nearest-neighbor matching."
- linear probe: Evaluating pretrained features by training only a simple linear layer on top for a downstream task. "linear probe experiments"
- Masked Image Modeling: A self-supervised learning paradigm where masked pixels or patches are reconstructed to learn representations. "Masked Image Modeling methods such as DINOv2~\cite{oquab2023dinov2}"
- monocular depth: Depth estimation from a single image without stereo or multi-view input. "Single-view 3D models estimate monocular depth"
- multi-view supervision: Training with paired or set images of the same scene to enforce geometric consistency. "learn from multi-view supervision"
- mutual nearest-neighbor matching: A filtering strategy that keeps pairs which are each other’s nearest neighbors to improve specificity. "mutual nearest-neighbor matching, ensuring high specificity"
- patchification: Splitting an image into non-overlapping patches for transformer-based encoding. "Vision Transformer patchification"
- PCK@32: Percentage of Correct Keypoints within a 32-pixel error threshold, measuring robustness of matches. "PCK@32 "
- planarity ratio: The proportion of pairs that are better explained by a homography than by a fundamental matrix, indicating planar bias. "Planarity Ratio"
- pointmaps: Per-pixel 3D point estimates that encode scene geometry and facilitate reconstruction. "regression of pointmaps"
- reprojection error: The pixel error between observed points and their projections under an estimated model. "with reprojection error below 32 pixel"
- RTK-grade GPS: High-precision GPS using Real-Time Kinematic corrections for accurate camera pose ground truth. "RTK-grade GPS"
- self-supervised learning: Learning representations without explicit labels, using pretext tasks or consistency objectives. "self-supervised learning"
- two-view geometry: The geometric relations between two images, including epipolar constraints and camera pose. "two-view geometry"
- Vision Foundation Models (VFMs): Large pretrained vision models that provide transferable representations across tasks and domains. "Vision Foundation Models (VFMs)"
- Vision Transformer (ViT): A transformer architecture that processes images as sequences of patches for visual tasks. "Vision Transformer (ViT)"
- warp field: A dense mapping from pixels in one image to corresponding locations in another image. "predicts an initial coarse warp field"
- warp head: A network head that directly regresses dense pixel-wise correspondences (warps). "dense warp head"
- zero-shot: Evaluation on datasets unseen during training to measure generalization. "zero-shot setting"
Collections
Sign up for free to add this paper to one or more collections.