AutoEnv: Automated Environments for Measuring Cross-Environment Agent Learning
Abstract: Humans naturally adapt to diverse environments by learning underlying rules across worlds with different dynamics, observations, and reward structures. In contrast, existing agents typically demonstrate improvements via self-evolving within a single domain, implicitly assuming a fixed environment distribution. Cross-environment learning has remained largely unmeasured: there is no standard collection of controllable, heterogeneous environments, nor a unified way to represent how agents learn. We address these gaps in two steps. First, we propose AutoEnv, an automated framework that treats environments as factorizable distributions over transitions, observations, and rewards, enabling low-cost (4.12 USD on average) generation of heterogeneous worlds. Using AutoEnv, we construct AutoEnv-36, a dataset of 36 environments with 358 validated levels, on which seven LLMs achieve 12-49% normalized reward, demonstrating the challenge of AutoEnv-36. Second, we formalize agent learning as a component-centric process driven by three stages of Selection, Optimization, and Evaluation applied to an improvable agent component. Using this formulation, we design eight learning methods and evaluate them on AutoEnv-36. Empirically, the gain of any single learning method quickly decrease as the number of environments increases, revealing that fixed learning methods do not scale across heterogeneous environments. Environment-adaptive selection of learning methods substantially improves performance but exhibits diminishing returns as the method space expands. These results highlight both the necessity and the current limitations of agent learning for scalable cross-environment generalization, and position AutoEnv and AutoEnv-36 as a testbed for studying cross-environment agent learning. The code is avaiable at https://github.com/FoundationAgents/AutoEnv.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper builds a new way to create many different “worlds” (think: game-like environments with rules) so we can test how AI agents learn across very different situations, not just in one familiar place. The authors introduce AutoEnv, a system that automatically makes these worlds cheaply and reliably, and AutoEnv-36, a set of 36 varied environments. They also propose a simple, clear way to describe how agents improve themselves, then test different learning strategies to see what actually works when environments vary a lot.
What questions are the researchers trying to answer?
- Can we automatically generate many, high-quality, different environments so agents can practice learning in diverse settings?
- Is there a unified, easy-to-use way to describe how an agent learns (so we can compare methods fairly)?
- Do learning methods that work in one kind of environment still work when the environments become more diverse?
- Does choosing different learning strategies for different environments help agents perform better?
How did they do it? (Methods explained simply)
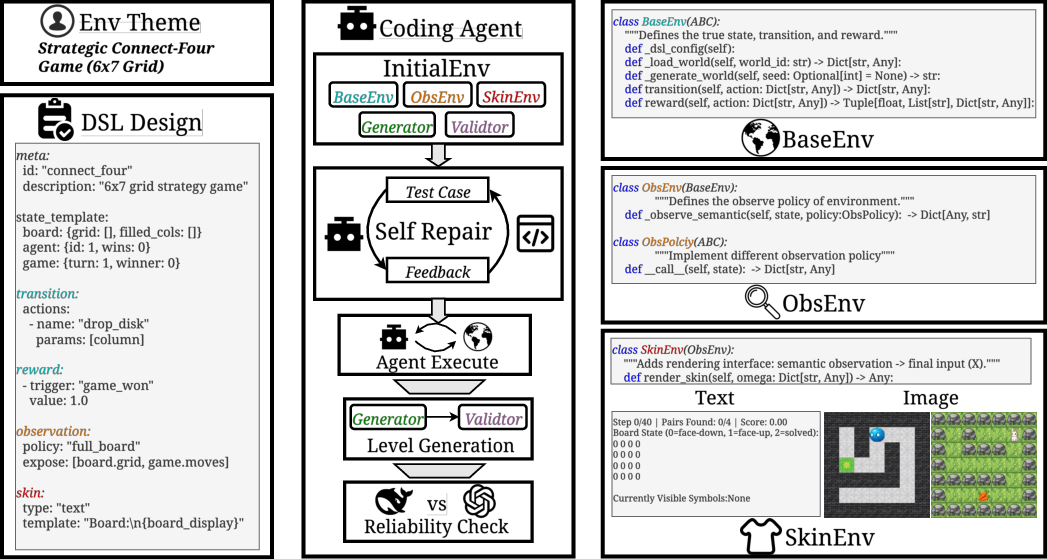
Think of an “environment” like a game world with rules: how the world behaves, what the agent can do, what it can see, and how it gets points (rewards). AutoEnv breaks each environment into three simple layers, a bit like making a board game, deciding what the player can see, and then choosing the artwork:
- BaseEnv: the core rules of the world (like the board game’s rules). It defines:
- States: what the world looks like right now (e.g., your position).
- Actions: what moves you can make.
- Transitions: what happens when you act (e.g., move right → new position).
- Rewards: how you score points (e.g., reach the goal).
- When the game ends (termination).
- ObsEnv: what the agent is allowed to see (full view or partial view). This is like giving the player full information or adding “fog-of-war.”
- SkinEnv: how information is presented (text or images). This is the “art style” or interface—same rules underneath, different look on top.
To build environments automatically, AutoEnv:
- Starts from a theme (like “maze navigation” or “resource management”).
- Turns the theme into a structured description (a YAML file) with the rules for all three layers.
- Uses coding agents (program-writing models) to generate the environment’s code.
- Runs a “self-repair” loop: if tests fail, the agent fixes the code.
- Verifies the environment in three steps:
- Execution: does it run without crashing?
- Level generation: can it make valid playable levels?
- Reliability: do stronger models usually score higher than weaker ones (so the task isn’t random)?
They then created AutoEnv-36, a collection of 36 verified environments, balanced across different rule types:
- Reward: “binary” (win/lose) and “accumulative” (score points over time).
- Observation: “full” vs “partial” view of the world.
- Semantics: “aligned” (natural language matches the rules) vs “inverse” (misleading descriptions, like “poison heals you”).
Finally, they define a simple way to describe how agents learn, using three stages:
- Selection: which version of the agent do we keep improving? (e.g., pick the best so far or use Pareto to balance reward and cost)
- Optimization: how do we change the agent? (e.g., rewrite its instructions or edit its code based on what went wrong)
- Evaluation: test the agent in the environment and measure its reward.
Using these stages, they combine different strategies (like “optimize the prompt” vs “optimize the agent code”) and test eight methods across the environments.
What did they find, and why does it matter?
- AutoEnv works well and is cheap:
- About $4.12 per environment on average.
- High success rates in building runnable, valid, and reliable environments.
- AutoEnv-36 is challenging and separates strong models from weaker ones:
- Across seven LLMs, normalized rewards ranged roughly from 12% to 49%.
- This shows the benchmark is tough but fair.
- Environment properties matter:
- Binary rewards were easier than accumulative rewards.
- Full observation was easier than partial observation (more info helps).
- “Inverse semantics” (misleading descriptions) tended to look easier in the dataset, but a controlled test showed they actually make tasks harder—those inverse tasks were probably simpler in other ways during generation.
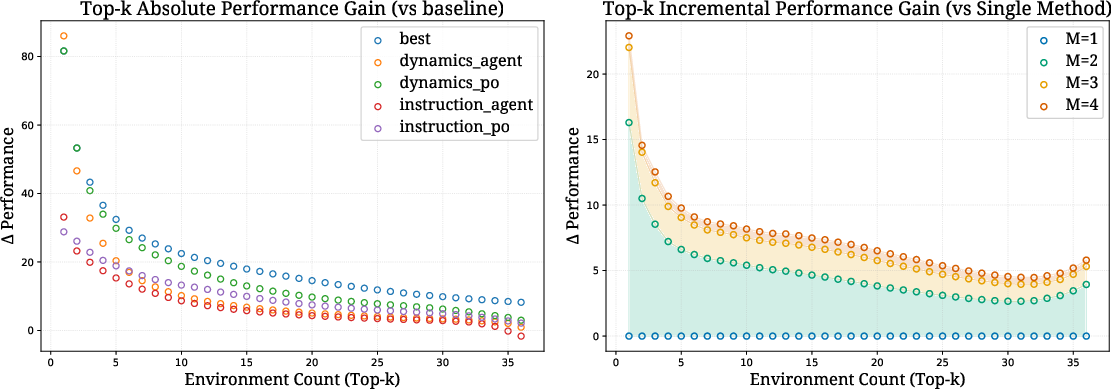
- Learning across many environments is hard:
- A single, fixed learning method that helps in a small set loses power when applied across all 36 environments.
- Picking different learning methods for different environments helps, but each added method gives smaller gains (diminishing returns).
- There’s still a noticeable gap between the best single method and the “upper bound” where you can choose the best method per environment, meaning smarter adaptive learning could do better.
These findings matter because they reveal a core problem: methods that look great in one domain (like coding or searching) don’t automatically generalize to many different kinds of environments. If we want agents that learn like humans—adapting to new rules and worlds—we need systems that can choose or design the right learning strategy for each environment.
What does this mean for the future?
- AutoEnv and AutoEnv-36 give researchers a practical testbed for studying “learning how to learn” across different worlds.
- The simple three-stage learning framework (Selection → Optimization → Evaluation) makes learning methods easier to compare and improve.
- There’s a clear need for smarter adaptive controllers that can automatically pick and combine learning strategies based on the environment’s rules and feedback.
- Future work can expand to multimodal (text+images), real-world-like, or embodied settings (robots), and develop richer learning method spaces to close the gap to the upper bound.
In short, this paper lays the foundation for building agents that don’t just get better at one game—they learn to improve themselves across many different games with different rules.
Knowledge Gaps
Below is a consolidated list of concrete gaps, limitations, and open questions the paper leaves unresolved. Each point is phrased to guide follow-up research.
Environment generation and dataset
- Limited modality and embodiment: AutoEnv-36 is predominantly text-only; there is no systematic evaluation of image, audio, GUI, or embodied/physics-based environments despite the framework’s stated support for continuous states.
- Scale and diversity constraints: Only 36 environments (358 levels) are released; it is unclear how success rates, costs, and quality scale to hundreds/thousands of environments and whether rule diversity saturates or collapses with scale.
- Confounded semantic difficulty: Inverse semantics unexpectedly yield higher scores due to co-varying task simplicity; there is no difficulty calibration procedure to disentangle rule complexity from semantic alignment.
- Single-agent, single-task focus: No multi-agent environments, competitive/cooperative dynamics, or hierarchical/multi-task settings are included.
- Short horizons and limited memory demands: Average episode lengths (~25–30 steps) suggest limited long-horizon planning and memory requirements; benchmarks for sparse rewards, delayed credit assignment, and persistent memory are missing.
- Partial observability is narrow: Partial observability is varied only through observation masking and text skins; richer sensor models (e.g., egocentric views, noisy sensors) are not explored.
- DSL expressiveness and correctness: The YAML DSL’s coverage of environment constructs, typing/validation guarantees, and ability to express complex stochastic/continuous dynamics is not analyzed.
- Reliability filtering is coarse: Differential model testing (strong vs. weak) is used as a proxy for “skill-based” reward; robustness to model idiosyncrasies, overfitting, or reward hacking is not rigorously assessed.
- Reward normalization uncertainty: Validator-based upper bounds are approximate (agents sometimes exceed 100%); there is no use of exact solvers, admissible heuristics, or stronger guarantees to calibrate normalized rewards.
- Train–test leakage risk: Training and testing levels are produced by the same generator/validator distribution; out-of-distribution generalization (e.g., alternative generators or rule-perturbed test sets) is not evaluated.
- Environment selection bias: From 100 themes to 65 verified to 36 published—criteria beyond broad “diversity/difficulty” are under-specified, risking hidden biases in the released set.
- Safety and robustness of generated code: There is no audit for security (e.g., prompt/code injection), resource misuse, or adversarial artifacts in auto-generated environments.
Evaluation protocol and metrics
- Lack of human or oracle baselines: No human performance, scripted optimal/near-optimal solvers, or theoretical optima are provided to contextualize model scores.
- Limited diagnostic coverage: Beyond reward and steps, there are no standardized metrics for sample efficiency, generalization gaps, or attribution of failure modes (e.g., perception vs. planning vs. credit assignment).
- Model-drift reproducibility: Results rely on proprietary black-box models that can change over time; robustness to model updates and reproducibility guarantees (seeds, pinned versions) are not provided.
- Cost and efficiency reporting: USD costs are reported but token usage, wall-clock time, compute budgets, and variance in pipeline latency are not analyzed for both generation and learning.
Learning framework and methods
- Narrow method space: The instantiated eight methods cover only prompts and agent code; tools, memory modules, planning/search components, reward models, and model-level RL are not treated as improvable components.
- No true meta-learning: The “upper bound” comes from per-environment oracle selection among fixed methods; there is no learner that infers environment characteristics and adapts its learning strategy online.
- Absent cross-environment transfer: There is no evaluation of whether learning in some environments improves performance in unseen environments (transfer/meta-RL/continual learning).
- Training paradigms underexplored: Reinforcement learning from interaction, offline RL/IL, preference learning, and policy-gradient updates over the agent policy are not compared to prompt/code editing.
- Selection policy learning is missing: Best/Pareto selection is hand-specified; learning a selection/controller policy that maps environment features and trajectory signals to learning strategies is not attempted.
- Limited component–signal interactions: The framework does not study how different optimization signals (e.g., dynamics inference vs. instruction edits) interact with specific components (e.g., memory, planners, tool routers).
- Negative transfer and safety: Method misalignment sometimes harms performance, but there is no systematic mechanism to detect and prevent regressions, catastrophic forgetting, or unsafe/self-damaging edits.
- Sample efficiency and data budgets: The number of interactions/levels required to realize gains is not characterized across methods; learning curves and data-efficiency comparisons are absent.
- Theoretical characterization: There is no formal analysis of when Selection–Optimization–Evaluation combinations should succeed or fail given environment properties (e.g., observability, reward sparsity).
Agents and architectures
- Execution model bias: All interactions use a ReAct-style agent; generality across other control paradigms (tree search, planning with learned world models, program-of-thought, tool-centric planners) is not evaluated.
- Memory and tool-use are static: Agents’ memory mechanisms and tool sets are not treated as first-class adaptive components; the impact of learnable retrieval, episodic memory, or dynamic tool acquisition is unknown.
- Multimodal agents and environments: Although multimodal skins are mentioned in the appendix, there is no systematic study of vision-conditioned agents or cross-modal observability on performance and learning efficacy.
Open questions for future work
- How to calibrate and equalize task difficulty while independently manipulating reward, observation, and semantic factors to enable controlled studies?
- What meta-features of environments best predict which learning method will work, and can a selection policy be learned from such features?
- How to design principled reward normalization and reliability checks (e.g., optimal solvers, certified bounds, adversarial testing) that avoid model-specific biases?
- Can meta-RL or hierarchical controllers discover and compose learning strategies automatically, closing the gap between single-method and oracle upper bounds?
- How well do agents transfer learned rules and strategies across dissimilar environments and modalities, and what representations enable such transfer?
- What are the limits of automated generation regarding coverage of real-world dynamics (continuous control, physics, partial observability, multi-agent) and how can the DSL be extended to express them?
- How to design benchmarks and protocols that measure long-horizon credit assignment, memory, and multi-step generalization in a reproducible, scalable way?
Glossary
- Accumulative rewards: Reward signals that accumulate over time rather than being binary success/failure. "including those with accumulative rewards and continuous numerical states."
- Agent code optimization: Methods that automatically improve an agent’s program or workflow to boost performance. "agent code optimization \citep{zhang2024aflow}"
- Agentic learning: A paradigm where agents improve themselves through interaction by updating internal components. "we formalize agentic learning as a component-centric process"
- Agentic reinforcement learning: Reinforcement learning approaches tailored for autonomous agents operating in complex environments. "agentic reinforcement learning \citep{wang2025ragen}"
- Agentic workflow optimization: Techniques that optimize the sequence of actions or modules within an agent’s workflow. "AFlow \citep{zhang2024aflow} for agentic workflow optimization"
- Aligned semantics: Environment descriptions whose natural language semantics match the underlying rules. "In aligned environments, the natural language semantics match the underlying rules"
- AutoEnv: An automated framework for generating diverse, controllable environments with factorizable rule distributions. "we propose AutoEnv, an automated framework that creates many environments with different rule distributions."
- AutoEnv-36: A curated dataset of 36 validated environments generated by AutoEnv for benchmarking cross-environment learning. "From this verified pool, we selected 36 environments to form AutoEnv-36 (AutoEnv-36)."
- BaseEnv: The layer that implements core environment dynamics, including states, actions, transitions, rewards, and termination. "BaseEnv implements the core dynamics "
- Best Selection: A selection strategy that keeps only the top-performing candidate based on the primary metric. "Best Selection keeps the candidate with the highest normalized reward."
- Binary rewards: Rewards given as success/failure at the end of an episode. "we distinguish between binary rewards (success/failure at the end) and accumulative rewards"
- Component-centric process: A learning formulation that focuses on updating specific improvable components of the agent. "Our component-centric formulation is used to define a search space over learning methods."
- Differential model testing: A reliability check that compares performance across stronger vs. weaker models to detect random reward structures. "we perform differential model testing with two ReAct agents backed by GPT-4o-mini and DeepSeek-V3.1."
- Domain-specific language (DSL): A specialized configuration language for specifying environment dynamics, observations, rendering, and level generation. "using a domain-specific language (DSL)"
- Evaluation (learning stage): The stage that runs candidates in environments and computes metrics from trajectories. "Evaluation runs candidates in the environment and measures how well they perform."
- Execution model: The model or engine used to execute agent candidates within environments to produce trajectories. "uses an execution model to run a candidate in environment and obtain a trajectory"
- Experience models: Models that simulate environment interactions to enable training via cheap rollouts. "distilling environment dynamics into world or experience models"
- Full observability: A setting where the agent can access all relevant state information. "from full observability to strong partial observability."
- Inverse semantics: Environment descriptions that intentionally invert intuitive meanings to test robustness. "In inverse environments, the semantics are intentionally counterintuitive"
- Learning Upper Bound: The best achievable performance when selecting the optimal learning method per environment. "We also define a Learning Upper Bound for each environment"
- Level generator: A component that programmatically creates candidate levels for an environment. "a level generator that can produce candidate levels"
- LLM-as-a-judge: Using a LLM to score agent trajectories or behaviors as part of evaluation. "an LLM-as-a-judge that scores the trajectory"
- max_reward function: A validator function estimating the upper bound of attainable reward for normalization. "includes a max_reward function used later for normalized evaluation."
- Normalized accuracy: Accuracy computed as achieved reward divided by an estimated upper bound on level reward. "Normalized accuracy is computed as the achieved reward divided by a validator-estimated upper bound on the level reward;"
- Normalized reward: Reward scaled by a normalization factor (e.g., an estimated maximum) to enable comparisons. "seven strong LLMs reach only 12--49\% normalized reward on AutoEnv-36"
- Observation function: The mapping from environment state to agent-visible observations. " where , , , , , and represent state space, action space, transition function, reward function, observation function, and termination predicate respectively."
- Observation policy: Configurable rules determining what information from the state is exposed to the agent. "specializes the observation function through configurable observation policies"
- ObsEnv: The layer that applies observation policies on top of BaseEnv to control information exposure. "On top of this, ObsEnv specializes the observation function through configurable observation policies"
- Optimization model: The model used to propose edits to agent components based on trajectories and metrics. "uses an optimization model (such as a LLM)"
- Optimization scheme: The specific approach for updating components (e.g., dynamics-based or instruction-based). "Optimization schemes ."
- Pareto Selection: A selection strategy that keeps candidates not dominated across multiple metrics (e.g., reward and cost). "Pareto Selection keeps all candidates that are not dominated in the space of reward and cost."
- Partial observability: A setting where the agent sees only a subset of the environment state. "from full observability to strong partial observability."
- PDDL: The Planning Domain Definition Language used in symbolic planning; contrasted with code-implementable RL formulations. "symbolic planning formalisms such as PDDL"
- Prompt optimization: Methods that refine natural-language instructions or prompts to improve agent performance. "prompt optimization \citep{xiang2025spo}"
- ReAcT framework: An agent framework that synergizes reasoning and acting via tool-augmented chains. "All agents begin with the ReAcT\citep{yao2023react} framework"
- ReAct-style agent: An agent that interleaves reasoning and action steps following the ReAct paradigm. "we run a simple ReAct-style agent"
- Reinforcement learning-based formulation: An RL tuple-based definition enabling code-implementation across diverse environment types. "this reinforcement learning-based formulation can be naturally implemented in code"
- Reward model: A learned model that evaluates trajectories to provide scalar feedback signals. "or a trained reward model."
- Self-repair loop: Iterative code editing driven by execution errors to fix generated environments. "we employ the same coding agents in a simple self-repair loop:"
- SkinEnv: The rendering layer that converts observations into agent-facing modalities (e.g., text, images). "SkinEnv applies rendering on top of ObsEnv and converts observations into agent-facing modalities"
- Symbolic planning formalism: Planning frameworks that describe environments declaratively rather than via executable dynamics. "Unlike existing symbolic planning formalisms such as PDDL"
- Termination predicate: The condition specifying when an environment episode ends. " where , , , , , and represent state space, action space, transition function, reward function, observation function, and termination predicate respectively."
- Trajectory: The sequence of states, actions, observations, and rewards produced by an agent interacting with an environment. "it produces a trajectory "
- Transition function: The stochastic or deterministic dynamics mapping state-action pairs to next states. " where , , , , , and represent state space, action space, transition function, reward function, observation function, and termination predicate respectively."
- Validator: A component that checks environment properties and supports reward normalization via max_reward. "and a validator that includes a max_reward function"
- World models: Models that approximate environment dynamics for simulation-based training. "distilling environment dynamics into world or experience models"
- YAML: A human-readable data serialization format used to express the environment DSL. "We then convert this description into a YAML file"
Practical Applications
Below is a synthesized view of practical applications arising from the paper’s findings, methods, and innovations. Each item states who can use it, how, and what tools/workflows and dependencies are involved.
Immediate Applications
- Cross-environment agent benchmarking and diagnostics for product teams
- Sector: software, AI platforms
- Use case: Adopt AutoEnv-36 to measure and compare agent/LLM performance under diverse rule distributions (binary vs accumulative rewards, full vs partial observability, aligned vs inverse semantics).
- Workflow: Plug agents into the provided ReAct-compatible interface; record normalized rewards across environments; stratify performance by environment dimensions to pinpoint weaknesses (e.g., partial observability gaps).
- Tools: AutoEnv-36 dataset, the AutoEnv codebase, environment validators, ReAct-style agent runners.
- Assumptions/Dependencies: Requires access to modern LLMs; normalized reward is based on validator-estimated bounds (can exceed 100% when bounds are conservative); results are primarily text-centric.
- CI/CD gating for agent releases
- Sector: software engineering, MLOps
- Use case: Integrate AutoEnv as a pre-release gate to detect regressions and overfitting to a single task family.
- Workflow: For each release, run AutoEnv-36 (or a curated subset) and require minimum normalized reward across representative environment dimensions; produce automatic regression and changelog reports.
- Tools: AutoEnv API + YAML DSL generation; unit tests via execution and level-generation validators; differential model reliability checks.
- Assumptions/Dependencies: Stable compute budgets; agents must expose a consistent interaction API; relies on differential model checks to weed out near-random reward structures.
- Prompt and agent-code optimization inside development loops
- Sector: software, AI tooling
- Use case: Use the component-centric learning framework (Selection–Optimization–Evaluation) to tune prompts and agent code with environment feedback.
- Workflow: Configure Best or Pareto selection; alternate instruction- or dynamics-based optimization; evaluate on multi-level rollouts; log cost/metrics; deploy improved prompts/agent-code if gains persist.
- Tools: Optimization prompts from the paper, selection functions, normalized reward metrics, trajectory logs.
- Assumptions/Dependencies: Gains diminish as environment diversity grows; incorrect method–environment pairing can harm performance (observed mismatch penalties).
- Environment-adaptive method selection to recover performance
- Sector: AI platforms, applied research
- Use case: Choose different learning methods per environment (e.g., Dynamics + Agent for ID-like tasks; Instruction + Agent for TA-like tasks) to approach the paper’s “Learning Upper Bound.”
- Workflow: For each environment, run multiple methods; pick the best (or Pareto-efficient) method; deploy environment-specific policy updates for production or evaluation.
- Tools: Eight-method search space defined in the paper; Upper Bound analyses; per-environment metric dashboards.
- Assumptions/Dependencies: Additional cost and complexity; diminishing returns when adding many methods; still a gap to the upper bound.
- Synthetic task generation for internal QA and red-teaming
- Sector: security, QA, reliability
- Use case: Generate heterogeneous environments cheaply (≈$4.12 each) to stress-test agents beyond coding/search/game-only distributions.
- Workflow: Draft themes; convert to AutoEnv DSL; run coding agents for three-layer classes; verify via execution/level-generation/reliability; add inverse semantics to test susceptibility to misleading language.
- Tools: AutoEnv DSL (YAML), coding agents, validators, differential model checks.
- Assumptions/Dependencies: Success rate improves with human review of themes; inverse semantics can make tasks harder, but comparability depends on matching base rules.
- Academic reproducibility and curriculum development
- Sector: academia, education
- Use case: Use AutoEnv-36 as a lab and assignment foundation for RL, agentic learning, and generalization courses; reproduce experiments on selection and optimization schemes.
- Workflow: Students implement agents; run across environment dimensions; compare single-method vs adaptive selection; analyze learning upper bounds and mismatch penalties.
- Tools: AutoEnv-36, learning-method prompts/configs, ReAct baselines.
- Assumptions/Dependencies: Primarily text-based settings; multi-modal examples exist but are exploratory.
- Procurement evaluation and vendor claims assessment
- Sector: policy, enterprise procurement
- Use case: Independently assess “general, agentic” vendor systems with a standardized heterogeneous benchmark rather than single-domain tasks.
- Workflow: Require vendors to run on AutoEnv-36; report stratified normalized rewards and robustness under partial observability/inverse semantics; use method-adaptive results to detect overfitting to specific workflows.
- Tools: AutoEnv-36, selection/evaluation protocols, reporting templates.
- Assumptions/Dependencies: Agreement on test protocols; access to vendor models; the benchmark is text-centric (extensions needed for GUI/embodied domains).
- Model selection and routing for consumer assistants
- Sector: daily life, consumer AI
- Use case: Evaluate different assistants across AutoEnv subsets capturing common household/planning patterns; route tasks to the model/method that demonstrates robustness under similar rule distributions.
- Workflow: Build a small “home” suite (e.g., planning, navigation-like puzzles, partial information tasks); log performance; choose model/method combos for calendar, smart-home, or shopping subtasks.
- Tools: AutoEnv generation to tailor domains; method-selection layer; lightweight ReAct agents.
- Assumptions/Dependencies: Synthetic-to-real gap; privacy and safety constraints for real deployments.
- Internal dataset/program design for embodied or UI agents (proto-multimodal)
- Sector: robotics, UI automation
- Use case: Use AutoEnv’s layered design (BaseEnv, ObsEnv, SkinEnv) to prototype partial-observation and rendering variations for UI or simulated robotics tasks before moving to high-fidelity sims.
- Workflow: Start text-only; add image SkinEnv for UI screenshots or simplified scenes; vary observation to simulate occlusion; validate learning strategy sensitivity.
- Tools: AutoEnv layered classes; multimodal SkinEnv prototypes; level generators.
- Assumptions/Dependencies: Current paper’s core results are text-focused; multimodal extensions are exploratory and need further verification.
Long-Term Applications
- Standardized certification for general-purpose agents
- Sector: policy, standards, compliance
- Use case: Develop recognized certifications based on cross-environment performance (reward normalization, partial observability, inverse semantics stress) to reduce cherry-picked benchmarks.
- Workflow: Create tiered test batteries; require upper-bound analyses and environment-adaptive method disclosures; audit for reliability and non-random reward structures.
- Tools: Expanded AutoEnv suite (multimodal/embodied/GUI domains), standardized evaluation protocols, certified auditing pipelines.
- Assumptions/Dependencies: Multi-stakeholder agreement; coverage of real-world apps beyond text; governance for benchmark updates to avoid overfitting.
- Meta-learning controllers that automatically design learning strategies
- Sector: AI research, platforms
- Use case: Build controllers that learn to select/compose learning methods per environment, closing the gap to the upper bound without manual design.
- Workflow: Treat method selection as a policy; train controllers on environment families; use cost-aware Pareto objectives; generalize across unseen environments.
- Tools: The paper’s component-centric framework; method libraries; meta-learning or bandit-style controllers; telemetry on trajectories and costs.
- Assumptions/Dependencies: Requires robust signals across diverse environments; computationally heavy; careful avoidance of overfitting to the benchmark.
- Multimodal and embodied AutoEnv for robotics and UI automation
- Sector: robotics, UI/enterprise automation
- Use case: Extend AutoEnv to high-fidelity image/video/3D rendering and device/app APIs to train/test agents under realistic dynamics and partial observability.
- Workflow: Define BaseEnv in physics or app-interaction terms; ObsEnv to control sensor/views; SkinEnv for camera/UI rendering; validate with reliability checks adapted to action spaces.
- Tools: Simulators (e.g., physics engines), GUI automation frameworks, multimodal LLMs, AutoEnv layered abstractions.
- Assumptions/Dependencies: Significant engineering; reward specification and reliability checks become harder; costs will exceed text-only generation.
- Curriculum generation for training foundation agents on cross-environment generalization
- Sector: AI research, model training
- Use case: Use AutoEnv’s level generators to produce progressive curricula (varying reward types/observability/semantics) for RL or supervised fine-tuning.
- Workflow: Start from simpler aligned, fully observable tasks; introduce inverse semantics and partial observation; periodically update prompts/agent code; measure gains under distribution shifts.
- Tools: AutoEnv generators/validators; RL pipelines; data curation for SFT/RLAIF; controllers for method selection.
- Assumptions/Dependencies: Bridging synthetic-to-real remains challenging; careful evaluation required to avoid Goodharting on the benchmark.
- Sector-specific sandboxes (healthcare, finance, logistics) with heterogeneous rule regimes
- Sector: healthcare, finance, logistics/supply chain
- Use case: Create domain-specific environment families (vary protocols, costs, observability, reward structures) to evaluate decision-support agents under regime changes.
- Workflow: Map domain principles to AutoEnv DSL; generate validated environments; evaluate agents on conservative vs aggressive reward regimes; monitor performance stability.
- Tools: Domain-specific rule specifications; AutoEnv DSL; reliability checks adapted for domain metrics.
- Assumptions/Dependencies: Requires expert input to avoid unrealistic or unsafe abstractions; compliance and privacy constraints for real data; synthetic-to-real generalization risks.
- Agent reliability and safety stress-testing under language deception
- Sector: safety, red-teaming
- Use case: Scale inverse-semantic environments and partial-observation traps to probe susceptibility to misleading cues and anchoring effects.
- Workflow: Generate matched aligned/inverse variants; measure drop under semantic inversion; combine with cost-aware Pareto selection to avoid over-optimization on one metric.
- Tools: AutoEnv generation with semantic toggles; method-selection controllers; audit dashboards.
- Assumptions/Dependencies: Must carefully control difficulty to isolate semantic effects; interpretability tooling needed to explain failure modes.
- “EnvHub” marketplace and internal repositories for environment assets
- Sector: ecosystem tooling, enterprise platforms
- Use case: Host reusable AutoEnv themes, DSLs, and validated levels for teams to assemble test suites quickly.
- Workflow: Versioned environment packages; metadata on dynamics/observation/reward types; reliability scores; integration adapters for agent frameworks.
- Tools: Package registries; CI integration; environment linting/validation services.
- Assumptions/Dependencies: Governance for quality and reliability; IP/licensing of environment code; maintenance to prevent benchmark gaming.
- Cost-aware learning orchestration in production
- Sector: MLOps, applied AI
- Use case: Deploy a “Learning Strategy Orchestrator” that weighs expected gain vs cost (tokens, compute, time) and selects optimized update paths (prompt-only vs agent-code changes).
- Workflow: Monitor live task distributions; periodically run small AutoEnv subsets as proxies; use Pareto selection to keep cost-performance balance; roll out updates safely.
- Tools: Cost telemetry; selection functions; optimization engines; rollout/rollback gates.
- Assumptions/Dependencies: Requires robust proxies linking synthetic performance to real KPI gains; careful change management to prevent regressions.
Notes on feasibility and dependencies across applications:
- The current benchmark is mainly text-based; multimodal/embodied extensions are feasible but require significant engineering and stronger reliability verification.
- Environment generation quality improves with human review of themes; fully automated pipelines may produce rule inconsistencies if themes are too abstract.
- Normalized reward depends on validator-estimated upper bounds; occasional >100% scores indicate conservative bounds, not metric error.
- Fixed learning methods show diminishing returns as environment diversity grows; environment-adaptive selection helps but does not close the gap—motivating meta-learning controllers.
- Synthetic-to-real generalization must be validated per domain before policy or safety-critical adoption.
Collections
Sign up for free to add this paper to one or more collections.