SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame Preservation
Abstract: Preserving first-frame identity while ensuring precise motion control is a fundamental challenge in human image animation. The Image-to-Motion Binding process of the dominant Reference-to-Video (R2V) paradigm overlooks critical spatio-temporal misalignments common in real-world applications, leading to failures such as identity drift and visual artifacts. We introduce SteadyDancer, an Image-to-Video (I2V) paradigm-based framework that achieves harmonized and coherent animation and is the first to ensure first-frame preservation robustly. Firstly, we propose a Condition-Reconciliation Mechanism to harmonize the two conflicting conditions, enabling precise control without sacrificing fidelity. Secondly, we design Synergistic Pose Modulation Modules to generate an adaptive and coherent pose representation that is highly compatible with the reference image. Finally, we employ a Staged Decoupled-Objective Training Pipeline that hierarchically optimizes the model for motion fidelity, visual quality, and temporal coherence. Experiments demonstrate that SteadyDancer achieves state-of-the-art performance in both appearance fidelity and motion control, while requiring significantly fewer training resources than comparable methods.










Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
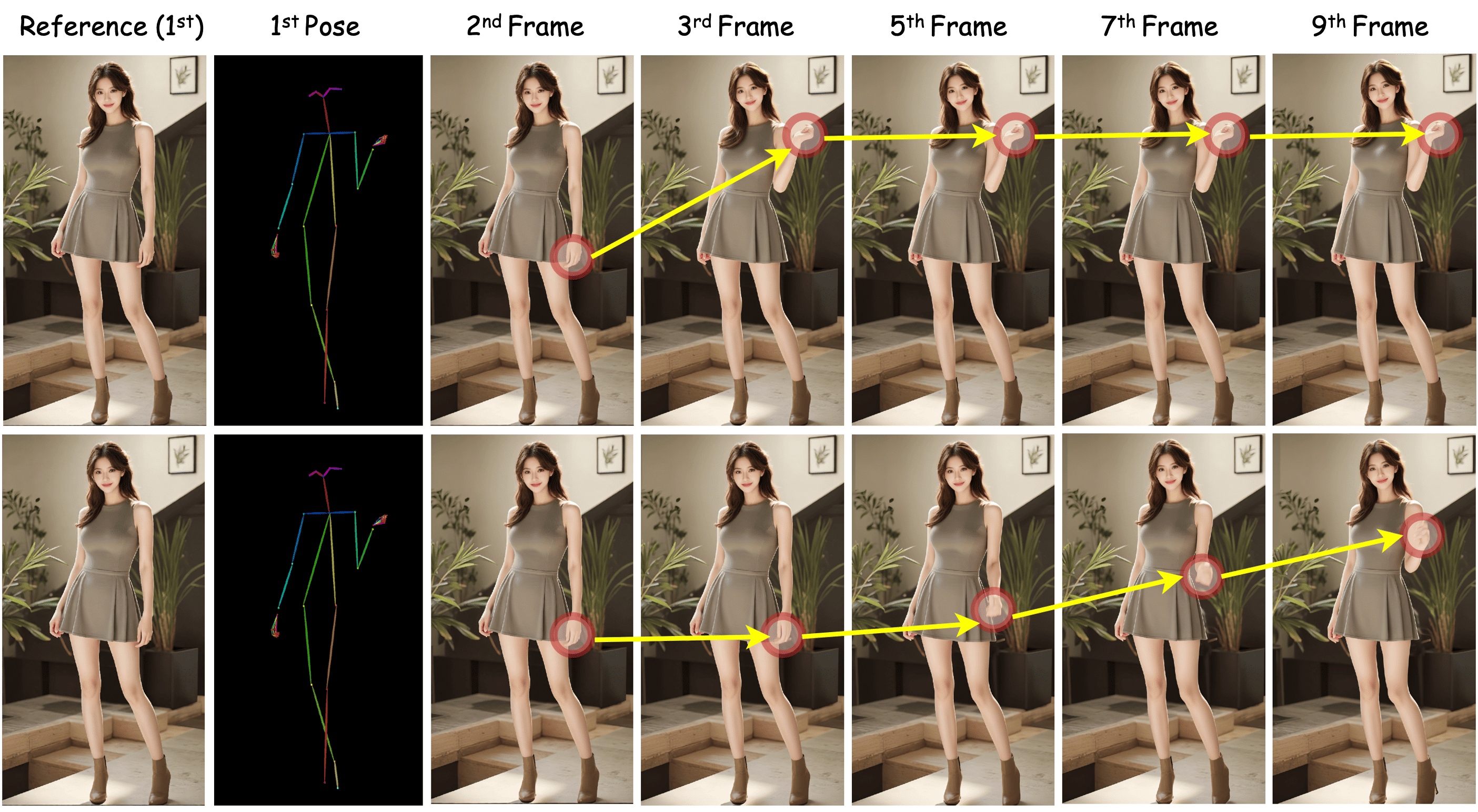
This paper introduces SteadyDancer, an AI system that turns a single photo of a person into a short, realistic video where the person moves according to a given “pose sequence” (like dance steps). The big promise is that the video starts by looking exactly like the original photo (first-frame preservation) and then moves smoothly, without changing the person’s face or outfit into someone else.
Key Objectives
The researchers wanted to solve three main problems:
- Keep the first frame of the video identical to the input photo.
- Make the person follow the requested motion (the pose sequence) exactly and smoothly.
- Prevent common glitches, like the person’s look changing over time (identity drift), jumpy movements, or weird visual artifacts.
How the Research Was Done
Two ways to animate from a photo
There are two common approaches to photo animation:
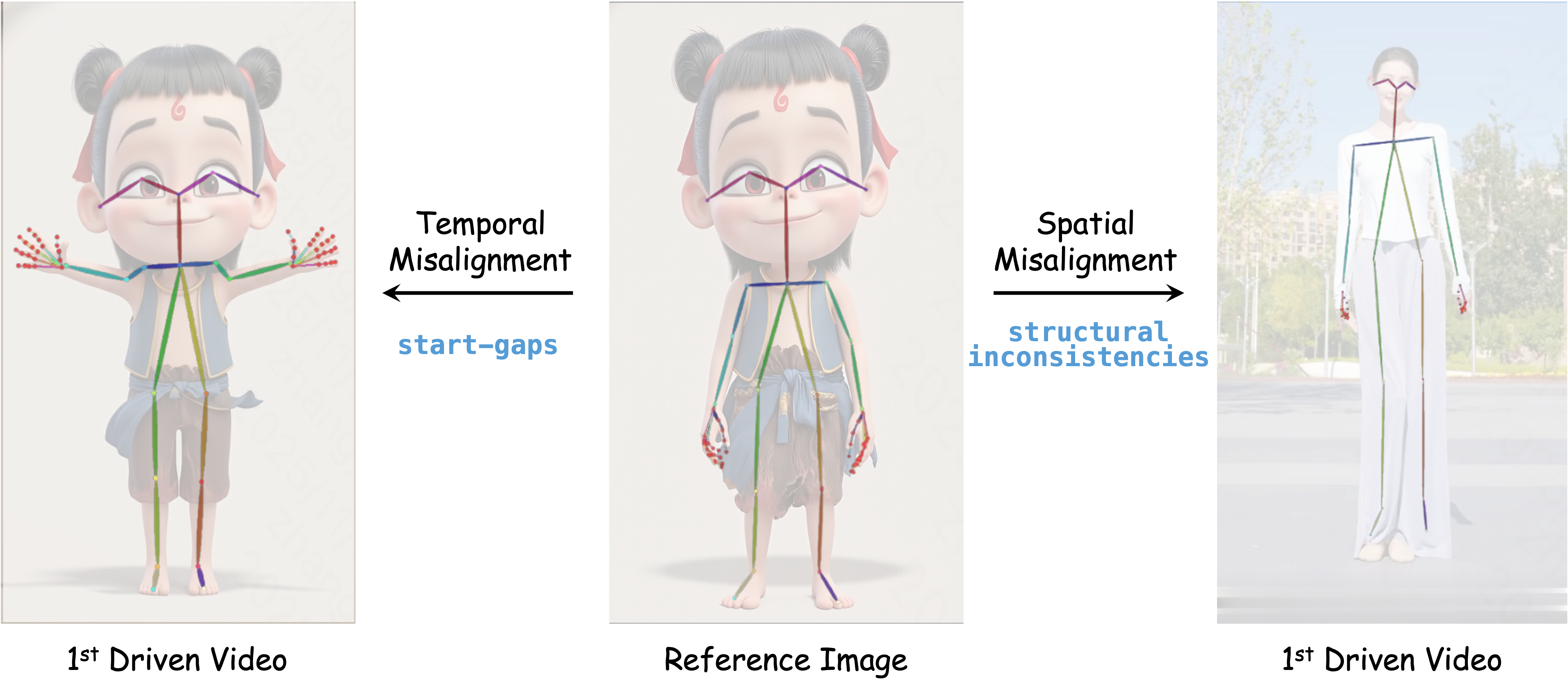
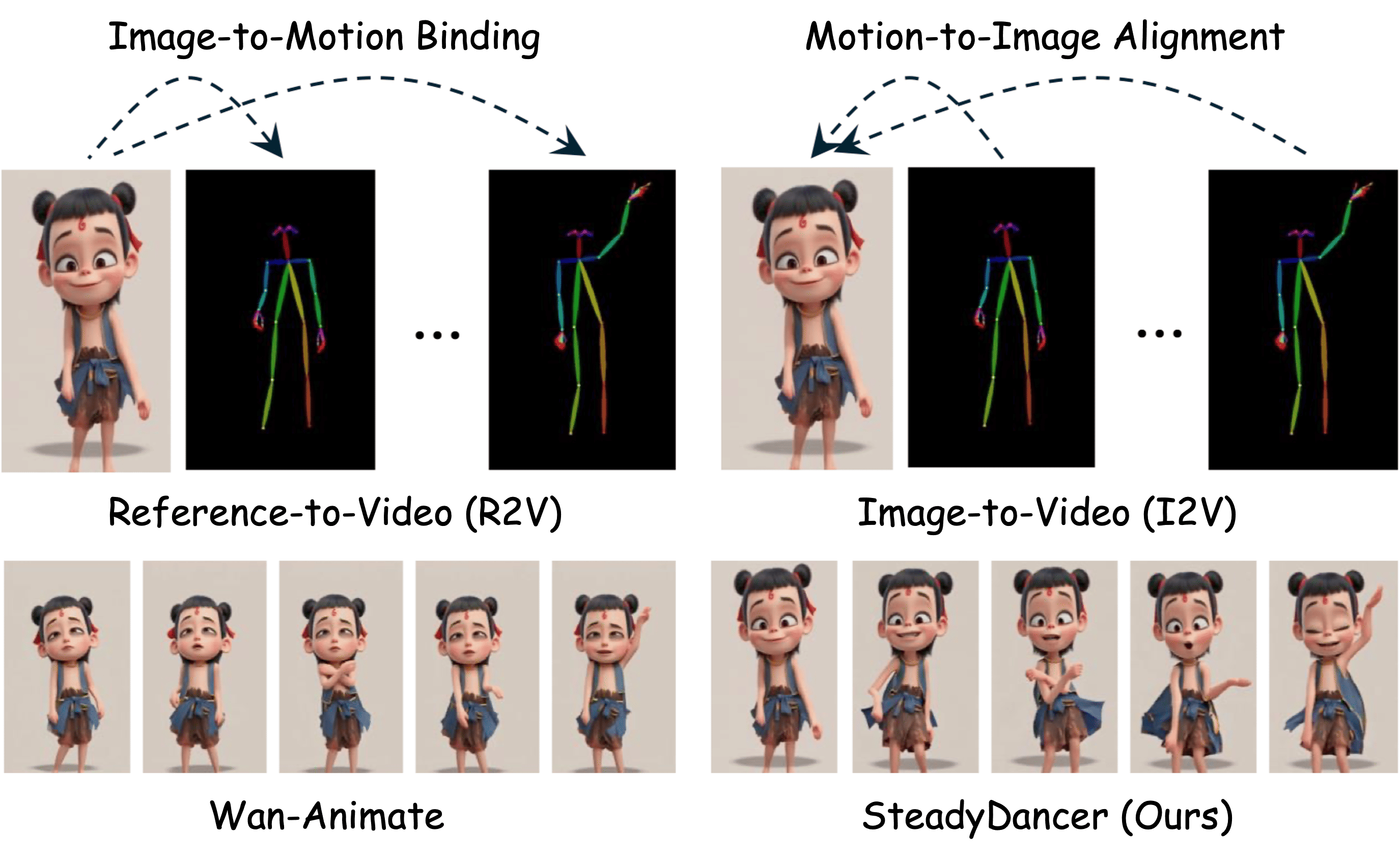
- Reference-to-Video (R2V): Think of this like “sticking” the photo onto the motion. It often ignores differences between the photo and the motion, which can cause identity changes and visual mistakes—especially if the motion doesn’t match the person’s body shape or the first move is very different from the photo’s pose.
- Image-to-Video (I2V): This starts the video from the photo’s exact first frame and continues from there. It’s more faithful to the original look but harder to control because the motion must fit the photo very carefully.
SteadyDancer uses the I2V approach so the first frame looks exactly like the input photo.
Three key ideas in SteadyDancer
To make I2V work well, the paper introduces three main techniques. Here’s what they do, in simple terms:
- Condition-Reconciliation Mechanism
- Challenge: The photo tells the AI how the person looks, while the pose sequence tells it how the person should move. These two instructions can clash (for example, the motion might expect longer arms than the person has in the photo).
- Solution: Instead of mashing the photo and pose signals together, SteadyDancer keeps them separate and carefully combines them so neither one “overpowers” the other.
- Analogy: It’s like mixing music and vocals on two different tracks so you can balance them—clear voice, steady rhythm.
- Synergistic Pose Modulation Modules
- Challenge: The pose sequence can be noisy (jittery), mismatched (different body proportions), or start with a big jump from the photo’s pose.
- Solution: SteadyDancer “refines” and “aligns” the pose signals in three steps:
- Spatial refiner: Adjusts the pose so it better fits the person in the photo (like tailoring a suit to the person’s body).
- Temporal coherence: Smooths out the motion over time (like stabilizing a shaky camera).
- Frame-wise alignment: Matches each video frame’s look with the pose for that frame (like a translator ensuring both sides understand each other at each step).
- Staged Decoupled-Objective Training Pipeline
- Challenge: Training a huge video model can be slow and fragile if you try to learn everything at once.
- Solution: Train in three simple stages, each with a clear goal:
- Stage 1: Motion learning with light-weight tuning (LoRA), so the model learns to follow poses without forgetting how to make good-looking videos.
- Stage 2: Quality boosting via “teacher–student” distillation, but done carefully so the student keeps motion control while learning the teacher’s overall visual quality.
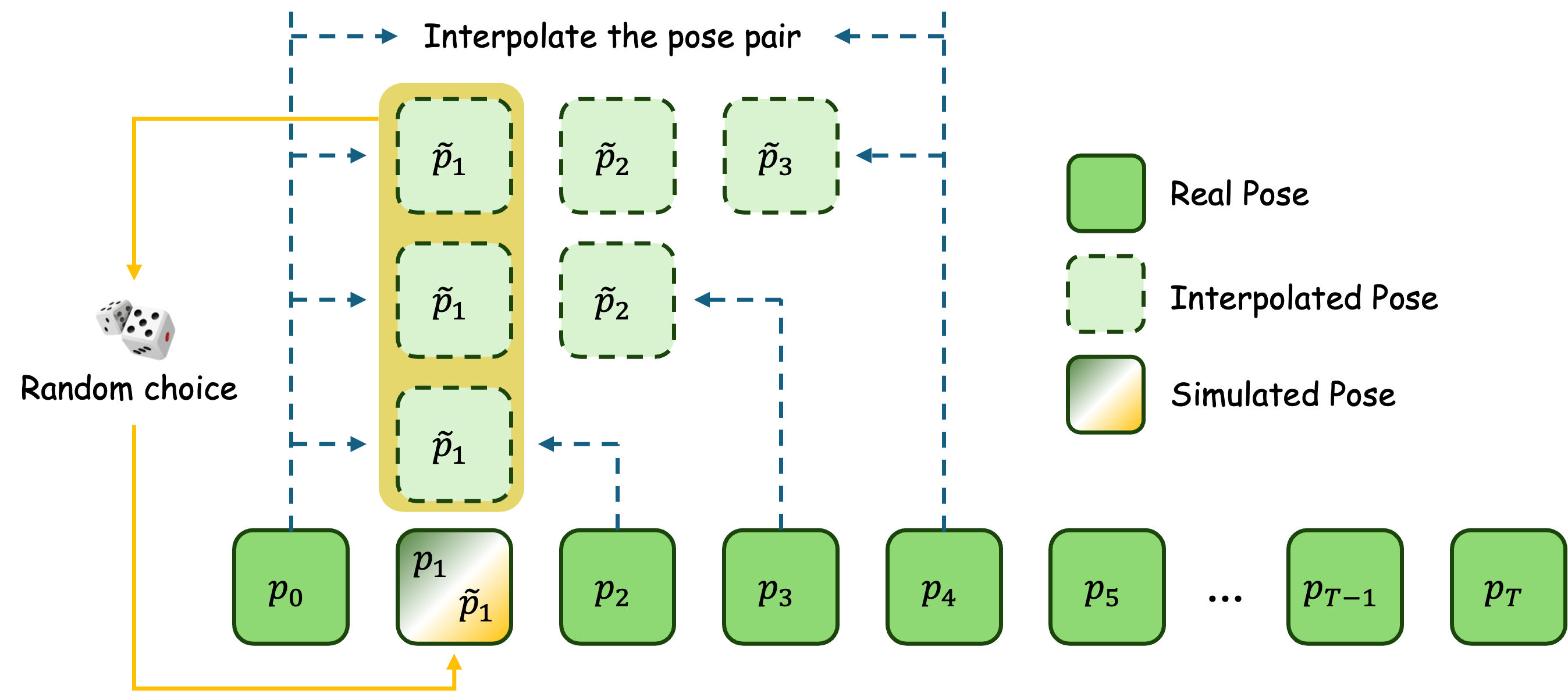
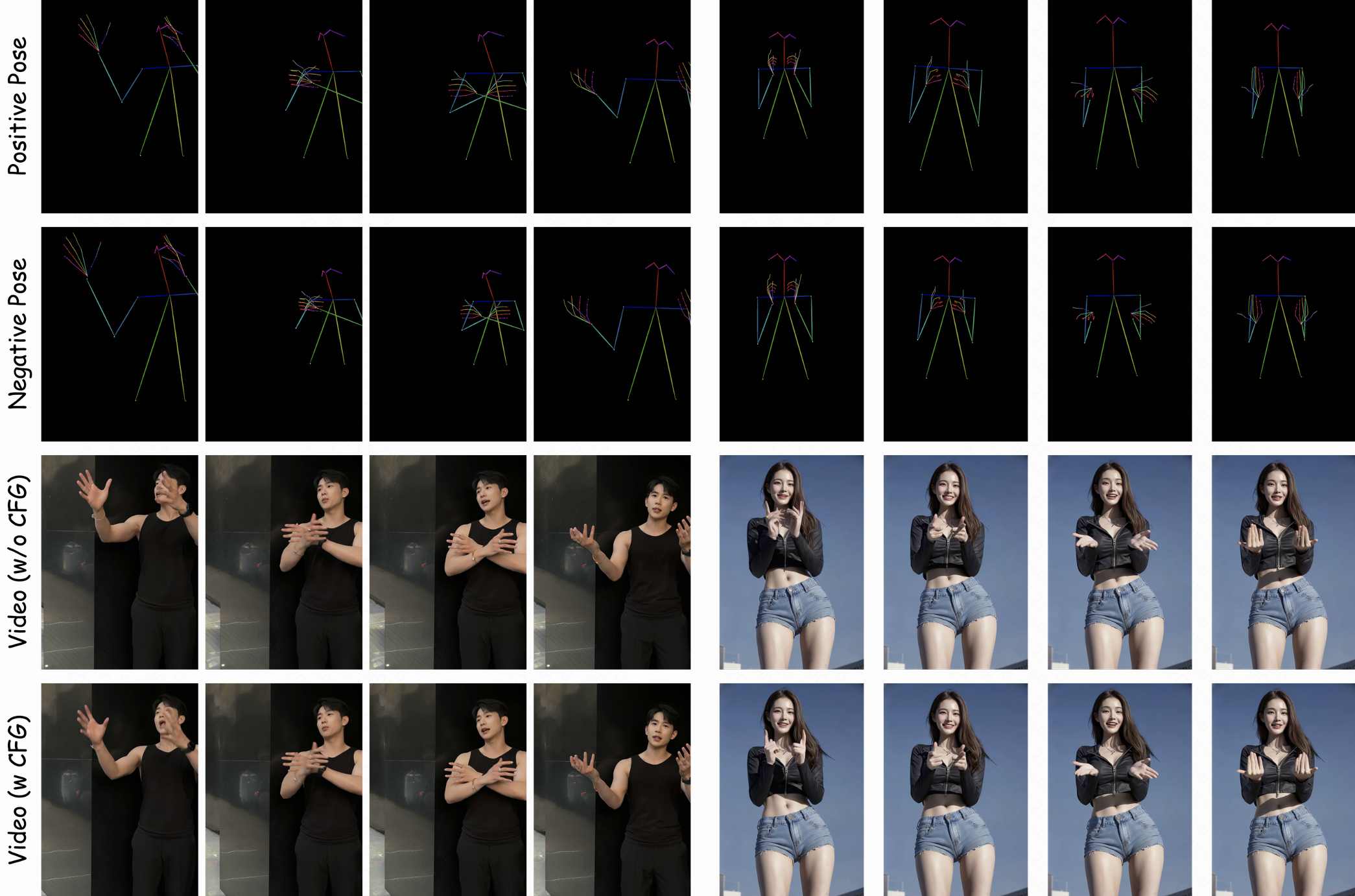
- Stage 3: Motion discontinuity mitigation: simulate realistic “start-gap” cases (where the first pose is quite different from the photo) and teach the model to transition smoothly instead of “jumping.”
Explaining a few technical terms in everyday language
- Pose sequence: A series of body positions over time—like choreography written as keypoints for arms, legs, and torso.
- Diffusion Transformer (DiT): A powerful AI that starts from noisy video and learns to remove the noise step-by-step until a clean video appears (like revealing a picture from static).
- VAE (Variational Autoencoder): A compressor–decompressor for images and videos that helps the model work efficiently.
- CLIP features: A way for the AI to understand images and text together (like a translator between pictures and words).
- LoRA: A small add-on that lets you adjust a big model without retraining everything (like adding gentle tweaks instead of rebuilding a whole engine).
- Distillation: A teacher–student process where a smaller or more focused model learns good habits from a stronger, pre-trained model.
Main Findings
- First-frame preservation: The first frame of the generated video consistently matches the input photo, avoiding identity drift.
- Precise motion control: The model follows complex pose sequences accurately and smoothly, even when the motion is challenging or the first move doesn’t match the photo perfectly.
- Fewer glitches: The videos show fewer artifacts, less jitter, and better continuity over frames.
- Efficient training: SteadyDancer reaches high quality with far fewer training steps and less data than many similar methods.
- Strong benchmarks: On test sets (like TikTok and RealisDance-Val), SteadyDancer scores very well, especially on metrics that reflect realistic, smooth video (like FVD and VBench).
- Bonus: Even when the motion involves interacting with objects, the model produces believable object movements—rare for systems guided only by human pose signals.
Why It Matters
SteadyDancer makes it practical to turn a single photo into a controlled, high-quality, and coherent video. This can help:
- Creators and studios animate still photos for films, ads, or social media without expensive motion capture.
- Game developers prototype character animations quickly while keeping the character’s look consistent.
- Anyone who wants a realistic “dance” or movement video from a favorite photo, with smooth transitions and fewer visual mistakes.
Because it needs less training data and compute, similar systems could be developed and deployed more easily, speeding up creative workflows while keeping the person’s identity and style intact.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed at guiding future research.
- Pose representation is underspecified: the paper does not detail the type of pose input (2D keypoints, 3D SMPL/mesh, dense pose), extraction pipeline, error sources (occlusion, blur), or confidence handling; actionable next steps include benchmarking different pose modalities and adding confidence-aware weighting in the modulation modules.
- Camera motion and background dynamics are not explicitly modeled or controlled; the I2V setup assumes first-frame preservation but does not address moving cameras, parallax, or dynamic backgrounds; future work should incorporate camera parameters and background control signals (e.g., segmentation, depth, optical flow).
- Long-horizon stability and identity retention beyond ~81 frames are untested; assess identity drift, visual fatigue, and motion realism on longer sequences (e.g., 30–120 seconds) and larger motion amplitudes.
- Multi-person scenes and inter-person interactions are not supported/assessed; extend the framework to multi-subject pose control, conflict resolution among multiple conditions, and identity disentanglement across subjects.
- Human–object interaction (HOI) evaluation is qualitative and lacks metrics; develop quantitative HOI metrics (e.g., contact consistency, object trajectory plausibility, deformation realism) and controlled benchmarks with annotated object interactions.
- Domain generalization is uncertain due to a dance-heavy training set that excludes extreme/complex movements; measure performance under diverse domains (sports, acrobatics, crowded scenes, outdoor environments) and high-speed motions.
- X-Dance benchmark details are incomplete: dataset composition, selection criteria, annotations, and quantitative protocols for misalignment measurement are not provided; release the benchmark with standardized metrics (e.g., pose alignment error, temporal transition smoothness, ID preservation scores).
- Fair-comparison protocol is non-uniform: the paper uses first-frame references while baselines use middle frames on same-source evaluations; re-run baselines under identical first-frame settings to isolate paradigm-related gains.
- Identity preservation is not quantitatively measured; add ID similarity metrics (e.g., ArcFace cosine similarity, face recognition true accept rate) and garment/attribute consistency metrics to objectively validate first-frame fidelity.
- Inference efficiency and scalability are unreported: latency, memory footprint, throughput, and real-time feasibility on commodity GPUs/edge devices need measurement; explore pruning, distillation, and low-rank adaptation for deployment.
- Condition-Decoupled Distillation lacks implementation clarity: how unconditional vs conditional velocity components are realized in a shared DiT, loss weighting, and architectural separation are unspecified; provide precise network diagrams, parameter sharing strategy, and sensitivity analyses to training hyperparameters.
- Robustness of Pose Simulation to large start-gap mismatches is unclear; evaluate with more severe and diverse discontinuities (e.g., T* > 4, different actions, camera cuts) and compare against alternative remedies (warm-start scheduling, pose easing functions, transitional blending).
- The synergy and relative contribution of augmentation choices (temporal concat of z_{c0}, z_{p0}, CLIP of first pose) are not fully ablated; systematically vary and quantify their effects on fidelity, motion adherence, and collapse risk.
- Synergistic Pose Modulation Modules lack reproducibility details: exact architectures (kernel sizes, ranks, attention heads, feature dimensions), dynamic kernel generation procedure, and LoRA injection points/ranks are missing; release implementation specs and hyperparameter sweeps.
- Failure modes are not characterized: catalog typical breakdowns (e.g., occluded limbs, severe blur, extreme proportions, cartoon/stylized domains), trigger conditions, and mitigation strategies.
- 3D geometric consistency under large view changes and rotations is not evaluated; investigate adding 3D cues (depth, surface normals, SMPL) or geometry-aware constraints to reduce structural distortions.
- Compositional control beyond pose (camera, face expression, hands, audio, text) is not integrated; explore multi-condition reconciliation and conflict resolution with gating/mixture-of-experts rather than simple channel concatenation.
- Theoretical grounding of the reconciliation strategy is limited; analyze why channel concatenation outperforms additive fusion or adapters, and explore principled controllers (learned gating, cross-condition routers, conditional normalization).
- Risk of hallucinated objects and non-physical interactions is unquantified; add physics-aware constraints or differentiable simulation priors to reduce implausible HOI generations.
- Data, code, and benchmark availability are unclear; clarify licensing, release plans, and reproducibility artifacts (training scripts, configs, seeds, pre/post-processing).
- Ethical and safety considerations are not discussed: address identity manipulation risks, consent/privacy for training videos, watermarking/traceability of generated content, and potential bias amplification from domain-specific datasets.
- Generalization to other backbones is untested: verify whether the approach transfers to non-Wan I2V models (e.g., CogVideoX, SVD) and smaller DiTs; report sensitivity to teacher quality in distillation.
- Impact of LoRA rank and injection locations is unstudied; perform targeted ablations to balance motion controllability vs preservation of pre-trained priors and avoid over-adaptation.
- Quantitative measurement of “80% discontinuity resolution” is unspecified; define a clear metric for start-gap mitigation (e.g., temporal motion smoothness score, acceleration continuity) and provide statistical analysis across diverse cases.
- Safety against noisy or adversarial pose inputs is not assessed; implement confidence-aware filtering, outlier rejection, or uncertainty modeling to prevent catastrophic artifacts under poor pose detection.
Practical Applications
Immediate Applications
The following applications can be deployed now using SteadyDancer’s first-frame preserving I2V paradigm, Condition-Reconciliation Mechanism, Synergistic Pose Modulation Modules, and efficient LoRA-based training pipeline. Each item includes sector alignment, potential tools/workflows, and feasibility notes.
- Human photo animation for consumer apps (social media, creator tools)
- Sector: software, media/entertainment
- What: Animate selfies or portraits with dance, gestures, or scripted motions while preserving identity and avoiding abrupt “start-gap” jumps. Useful for TikTok-style content, memes, digital postcards, and avatar videos.
- Tools/workflows: mobile SDK/API with “first-frame preserving animation”; pose ingestion from pre-recorded clips or in-app motion capture; lightweight LoRA packs for theme styles.
- Assumptions/dependencies: availability of pose sequences (from camera capture or pose estimators like OpenPose/MediaPipe/SMPL); user consent and content labeling (C2PA/watermarking); device or cloud GPU for inference.
- Brand mascot and spokesperson animation (advertising and marketing)
- Sector: advertising, media/entertainment
- What: Transform static brand images into coherent video ads; maintain identity across motion, reduce artifacts compared with R2V methods, and create A/B variants rapidly.
- Tools/workflows: “First-frame preserving animator” plugin in Adobe/DaVinci; LoRA fine-tuning on brand identities; batch generation pipelines with VBench-I2V QA and the X-Dance stress test suite.
- Assumptions/dependencies: brand approvals; clean high-res reference image; motion clips aligned with campaign tone; GPU capacity for batch rendering.
- Virtual production and post-production VFX shot repair
- Sector: film/TV, media/entertainment
- What: Extend shots from keyframes, repair motion discontinuities, and synthesize smooth transitions using Pose Simulation to mitigate start-gap artifacts; maintain costume and face fidelity across retargeted motions.
- Tools/workflows: Blender/Unreal integration; pose clean-up with Temporal Motion Coherence Module; shot extension from hero frames; automated “misalignment stress test” before ingest.
- Assumptions/dependencies: clear reference stills; high-quality pose capture; version-controlled LoRA tuning to adhere to show continuity; studio GPU farm.
- Game content prototyping and modding from concept art
- Sector: gaming, software
- What: Convert character sheets or key art into short animated cutscenes or emotes; maintain the art style and character while applying pose sequences.
- Tools/workflows: Unity/Unreal plugin; batch animation tool with Frame-wise Attention Alignment Unit to avoid identity drift; quick LoRA style locks for specific IP.
- Assumptions/dependencies: pose libraries; rights to character/IP; limited extreme motion in early builds.
- E-commerce and fashion dynamic product previews
- Sector: e-commerce, fashion/retail
- What: Animate catalog images to show fabric drape and motion on the original model; generate try-on videos from a single photo to increase engagement.
- Tools/workflows: pipeline for motion retargeting with Spatial Structure Adaptive Refiner to adapt pose to body type; brand-specific LoRA; quality gates using FVD/VBench-I2V.
- Assumptions/dependencies: disclosure that physics is approximate; model consent; motion sequences aligned to garment category; policy compliance (avoid misleading claims).
- Education content generation (PE, dance, sign basics)
- Sector: education
- What: Create personalized instructor videos from a single instructor photo and curated motion sequences; maintain clear identity and smooth transitions for step-by-step lessons.
- Tools/workflows: lesson authoring tool with pose libraries; temporal smoothing via TMCM; caption/overlay integration.
- Assumptions/dependencies: curated, safe motion sequences; accessibility considerations; rights/consent for educator images.
- Physical therapy and wellness exercise demos (non-diagnostic)
- Sector: healthcare (consumer wellness)
- What: Personalized exercise demonstrations animated from patient or trainer images with prescribed pose sequences; preserve identity for better adherence.
- Tools/workflows: clinic or app workflow with therapist-provided pose sets; condition reconciliation to avoid body-type distortions; disclaimer tooling.
- Assumptions/dependencies: not a medical device; consent; validated pose sequences; bias checks on body types.
- Synthetic spokespersons and corporate communications
- Sector: enterprise software, media/communications
- What: Generate internal announcements or training clips from a single corporate avatar image; maintain identity across motion for consistency.
- Tools/workflows: internal content platform API; LoRA for attire/brand; governance hooks for watermarking and provenance logs.
- Assumptions/dependencies: security and privacy; approved identity assets; policy-aligned labeling.
- Developer SDKs and content QA tooling
- Sector: software
- What: Provide a low-resource I2V SDK supporting condition fusion/injection (channel concat + LoRA), pose modulation modules, and staged training; ship QA tools like misalignment stress tests (X-Dance) and metric gates (FVD, VBench-I2V).
- Tools/workflows: Python API, CLI, and CI integration; recipe notebooks for 10–20-hour internal datasets; automatic Pose Simulation for start-gap robustness.
- Assumptions/dependencies: base model license (e.g., Wan-2.1 I2V or similar); GPU access; acceptable latency targets.
- Trust and safety labeling of synthetic media
- Sector: policy, platform governance
- What: Enforce provenance embedding and disclosure for first-frame preserving outputs; compute “pose-to-image alignment scores” to audit identity drift and motion faithfulness.
- Tools/workflows: watermark insertion; C2PA manifests; alignment scoring service; moderation hooks.
- Assumptions/dependencies: platform adoption; standardized metadata; legal compliance and consent management.
Long-Term Applications
These applications are plausible but require further research (multi-person, real-time, physics, 3D awareness), scaling, or integration with adjacent modalities and systems.
- Real-time telepresence avatars from a single photo
- Sector: communications, AR/VR
- What: Stream live body-tracked poses to animate a photo-based avatar with stable identity and coherent motion in video calls and virtual events.
- Tools/workflows: edge-optimized I2V models; latency-aware condition injection; camera motion control; audio-driven facial animation.
- Assumptions/dependencies: model compression/pruning for mobile/AR glasses; robust multi-camera pose tracking; very low-latency inference.
- Cinematic AI pipelines from storyboards to finished scenes
- Sector: film/TV, media/entertainment
- What: Convert storyboard frames into multi-shot sequences with consistent actors, camera motion, and HOI; maintain first-frame identity across scene transitions.
- Tools/workflows: scene graph + motion script; multi-character alignment; object interaction synthesis beyond pose only; camera parameter controls.
- Assumptions/dependencies: multi-agent control; stronger 3D geometry and physics; advanced editing UIs; substantial compute.
- Personalized digital humans for customer service and education
- Sector: enterprise software, education
- What: Always-on assistants animated from approved images; integrate speech, gestures, and context-aware motion while preserving identity.
- Tools/workflows: multimodal fusion (speech-to-gesture); long-horizon temporal coherence modules; domain LoRA packs per brand/role.
- Assumptions/dependencies: lip-sync and gaze control; ethics and compliance (deepfake, impersonation); robust deployment on edge devices.
- Accessibility: high-fidelity sign language generation
- Sector: healthcare, public services, education
- What: Create accurate, coherent sign-language videos from a single signer photo and linguistic pose specifications.
- Tools/workflows: sign-language motion libraries; precision temporal alignment; QA with expert annotators.
- Assumptions/dependencies: domain-specific datasets; cultural/language variants; certification and validation.
- Sports and broadcast: personalized replays and highlight synthesis
- Sector: sports media
- What: Generate “what-if” replays or personalized highlights by animating player photos with recorded motion; maintain identity fidelity.
- Tools/workflows: pose capture from tracking systems; camera parameter control; physics-aware object interactions (ball, equipment).
- Assumptions/dependencies: licensing and rights management; physics realism; multi-player interactions.
- Large-scale dynamic retail catalogs with motion previews
- Sector: e-commerce, fashion/retail
- What: Programmatically produce motion previews for millions of SKUs from static images; consistent identity retention per model across motions.
- Tools/workflows: batch pipelines; per-brand LoRA; garment-aware motion sets; automated QA and compliance labeling.
- Assumptions/dependencies: scalable GPU infrastructure; garment/body-type adaptation; legal guidance to avoid misleading depictions.
- Multi-person and crowd animation from single group photos
- Sector: media/entertainment, events
- What: Animate entire group shots coherently with individual identity preservation and coordinated motion.
- Tools/workflows: per-person pose alignment; collision and occlusion handling; inter-person temporal consistency modules.
- Assumptions/dependencies: multi-agent control and scheduling; increased data requirements; complex edge cases.
- Robotics/HRI synthetic dataset generation
- Sector: robotics, academia
- What: Produce human motion videos with consistent identity and object interactions to train perception and HRI policies.
- Tools/workflows: controllable pose libraries; HOI synthesis; scenario diversification; domain adaptation.
- Assumptions/dependencies: bridging sim-to-real; 3D scene understanding; labeled interaction data.
- Academic benchmarks for misalignment and continuity
- Sector: academia
- What: Standardize different-source benchmarks (e.g., X-Dance) and metrics assessing spatio-temporal misalignment, start-gap robustness, and identity preservation.
- Tools/workflows: open datasets; evaluation servers; ablation suites for condition fusion/injection and decoupled distillation.
- Assumptions/dependencies: community adoption; dataset licensing; reproducible evaluation protocols.
- Policy frameworks for identity-preserving generative media
- Sector: policy/regulation
- What: Guidelines and standards for consent, watermarking, provenance, age gating, and permissible uses of identity-preserving animation.
- Tools/workflows: C2PA extensions for pose provenance; regulatory compliance checklists; audit APIs.
- Assumptions/dependencies: cross-platform agreement; legal harmonization across jurisdictions; stakeholder buy-in.
Notes on Feasibility and Dependencies
- Base model availability and licensing: The approach assumes access to a strong I2V backbone (e.g., Wan-2.1 I2V 14B, CogVideoX). Licensing constraints affect commercial use.
- Pose quality and modality: Performance depends on accurate, smooth pose input. Temporal smoothing (TMCM) mitigates noise, but extreme or contradictory poses may require curation.
- Compute and latency: Immediate applications are viable with cloud GPUs; real-time/edge uses require model compression and inference optimizations.
- Identity and IP rights: Use cases involving real people or brand characters require explicit consent and rights management; provenance labeling is recommended.
- Physics and HOI: While SteadyDancer can infer plausible object interactions from pose-only signals, robust physical accuracy is not guaranteed without dedicated physics/3D modules.
- Safety and bias: Datasets should be diverse; outputs must include watermarks/provenance; platforms should implement moderation for misuse (e.g., impersonation).
Glossary
- 3D VAEs: Variational autoencoders that compress data across spatial and temporal dimensions for video. "adopt 3D VAEs over standard 2D VAEs"
- Ablation study: An analysis that removes or varies components to assess their individual contributions. "Ablation of Condition-Reconciliation Mechanism."
- Adapter-based injection: Adding extra modules to inject conditions into a model, often increasing parameters and complexity. "adapter-based injection (Row 2)"
- CLIP feature: A semantic embedding extracted by CLIP used to provide global context or guidance. "concatenating it with the CLIP feature of the first pose frame"
- Condition-Decoupled Distillation: A training strategy that distills unconditional generative priors separately from conditional objectives to avoid conflicts. "Condition-Decoupled Distillation"
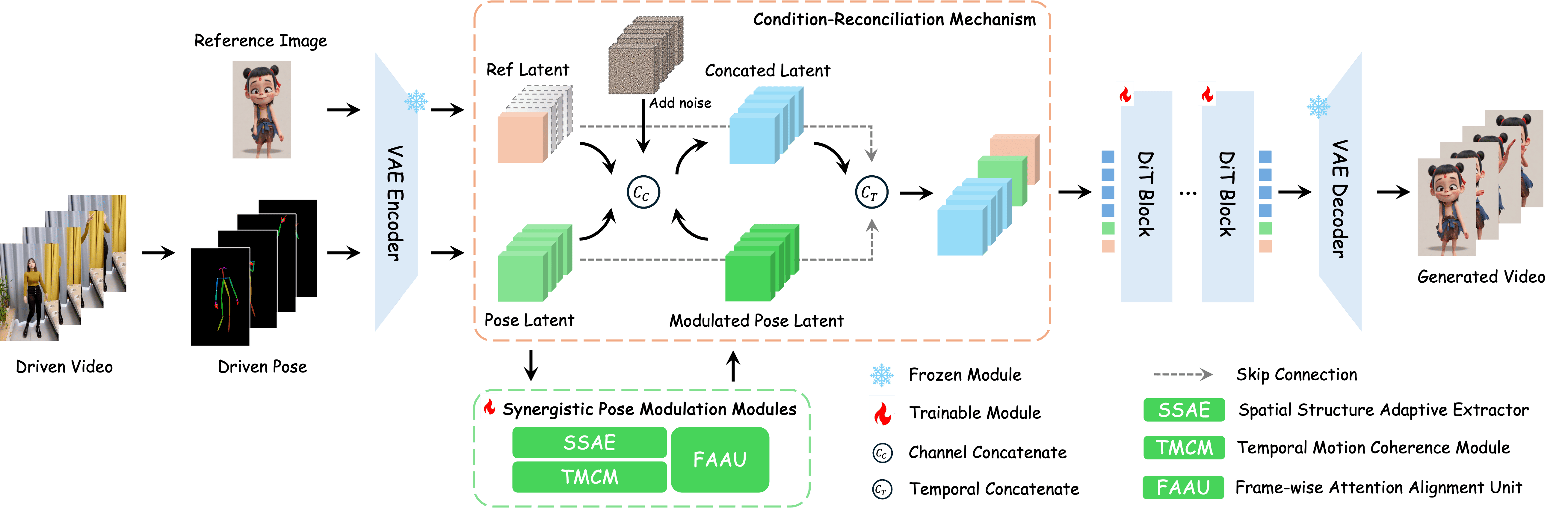
- Condition-Reconciliation Mechanism: A method to harmonize appearance and motion conditions to preserve the first frame while maintaining control. "we propose Condition-Reconciliation Mechanism"
- ControlNet: A diffusion model extension that conditions generation on external guidance like pose or edges. "leveraged ControlNet for pose guidance"
- Cross-attention: An attention mechanism where one set of features attends to another, enabling alignment of different modalities. "decoupled cross-attention layers of DiT"
- DensePose: A representation mapping 2D images to 3D human surface coordinates for detailed pose guidance. "DensePose"
- Depthwise spatial convolutions: Convolutions applied per channel to capture intra-frame structures efficiently. "including depthwise spatial convolutions to capture intra-frame structures"
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion models, enabling large-scale generative modeling. "Diffusion Transformer (DiT)"
- Dynamic convolution: Convolution whose kernels are generated adaptively from the input, tailoring filters to each sample. "It employs dynamic convolution"
- FID: Fréchet Inception Distance; a metric that measures image distribution similarity between generated and real data. "FID"
- First-frame preservation: Ensuring the generated video’s initial frame matches the reference image identity and appearance. "first-frame preservation"
- Frame-wise Attention Alignment Unit: A module that aligns pose and appearance per frame via cross-attention. "Frame-wise Attention Alignment Unit"
- FVD: Fréchet Video Distance; a metric evaluating video-level fidelity and temporal consistency. "FVD"
- Human-Object Interactions (HOI): Scenarios where humans interact with objects, testing motion control and physical plausibility. "Human-Object Interactions (HOI)"
- Image-to-Video (I2V) paradigm: Generating video starting from a single image, inherently preserving the first frame. "Image-to-Video (I2V) paradigm"
- Identity drift: Deviation of the generated subject’s identity from the reference image over time. "leading to failures such as identity drift"
- LoRA-based fine-tuning: Low-Rank Adaptation; parameter-efficient fine-tuning that adds low-rank updates to pre-trained weights. "LoRA-based fine-tuning"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric comparing visual similarity as judged by deep features. "LPIPS"
- Motion Discontinuity Mitigation: A training stage to reduce abrupt transitions in motion, improving smoothness. "Motion Discontinuity Mitigation"
- Motion-to-Image Alignment: Aligning motion signals (pose) with image appearance to avoid artifacts and preserve identity. "with Motion-to-Image Alignment"
- Pointwise temporal convolutions: 1x1 convolutions across time used to model inter-frame dynamics efficiently. "and pointwise temporal convolutions to model inter-frame dynamics"
- Pose Simulation: A training technique that introduces synthetic pose mismatches to teach smooth transitions. "We therefore propose Pose Simulation"
- ReferenceNet: A UNet-based network that injects appearance features from a reference image to preserve identity. "UNet-based ReferenceNet"
- Reference-to-Video (R2V) paradigm: Binding a reference image onto a driven pose sequence, often relaxing alignment constraints. "Reference-to-Video (R2V) paradigm"
- SMPL: A parametric 3D human body model used for geometric guidance in animation. "SMPL"
- Spatial Structure Adaptive Refiner: A module that refines pose features via dynamic convolution to better match image structure. "Spatial Structure Adaptive Refiner"
- Start-gap misalignment: The abrupt difference between the static reference and the first driving pose, causing jump artifacts. "start-gap misalignment"
- Staged Decoupled-Objective Training Pipeline: A three-stage training framework optimizing motion control, quality, and continuity separately. "Staged Decoupled-Objective Training Pipeline"
- Synergistic Pose Modulation Modules: A set of modules that jointly resolve spatial and temporal pose-image misalignments. "Synergistic Pose Modulation Modules"
- Temporal coherence: Consistency of appearance and motion across video frames. "temporal coherence"
- Temporal Motion Coherence Module: A module that models smooth motion dynamics from discrete pose sequences. "Temporal Motion Coherence Module"
- TemporalConcat: A concatenation operation along the temporal axis to provide explicit first-frame references. "TemporalConcat"
- VAE encoder: The encoder part of a Variational Autoencoder that maps inputs to latent representations. "encoded by a VAE encoder"
- Vbench-I2V: A benchmark with multidimensional metrics for evaluating image-to-video generation quality. "Vbench-I2V"
- Velocity prediction: In diffusion, predicting the velocity field used to guide denoising towards target distributions. "We decompose its velocity prediction into an unconditional component and a conditional component"
- Zero-filled frames: Empty temporal frames appended to the reference image for conditioning in I2V models. "temporally concatenated with zero-filled frames"
Collections
Sign up for free to add this paper to one or more collections.