- The paper introduces a novel end-to-end transformer-based diffusion model in pixel space that eliminates autoencoder compression artifacts and enhances fidelity.
- It employs pixel-wise AdaLN modulation and pixel token compaction to effectively balance global semantic reasoning with localized detail refinement.
- Empirical results on ImageNet and text-to-image tasks demonstrate competitive FID, high recall, and superior editability compared to latent diffusion models.
Motivation and Problem Statement
Conventional DiT-based diffusion models perform denoising in a learned latent space, typically with compression via VAEs. While this enables significant compute and memory savings for high-resolution synthesis, the semantic and reconstruction mismatch between the autoencoder and the generative backbone introduces limitations: lossy reconstruction from the autoencoder erases high-frequency details, leading to irrecoverable artifacts and suboptimal editability, and the decoupled optimization between encoder and generator caps fidelity due to an optimization dilemma. Pixel-space generative modeling conceptually avoids this bottleneck, but standard Transformer architectures suffer from infeasible compute scaling and inefficient locality modeling at high resolution. The central challenge is the efficient and accurate modeling of fine-grained per-pixel dependencies at scale.
PixelDiT Architecture
PixelDiT is a single-stage, fully transformer-based diffusion model trained end-to-end in pixel space, eschewing pre-trained autoencoders and latent representations. Its architecture uses a dual-level design:
- Patch-level DiT: Utilizes large non-overlapping patches, enabling efficient global semantic reasoning with significantly reduced sequence lengths.
- Pixel-level DiT (PiT block): Processes pixel tokens with local detail refinement and explicit per-pixel conditioning through dedicated submodules.
The core innovations enabling computational and representational efficiency are pixel-wise AdaLN modulation and pixel token compaction. The former allows per-pixel adaptive normalization and semantic alignment by mapping semantic patch tokens to unique affine parameters for every pixel. The latter compresses each p2 pixel group within a patch into a compact token prior to self-attention and decompresses afterwards, reducing the quadratic scaling of self-attention while ensuring the preservation of high-frequency detail.
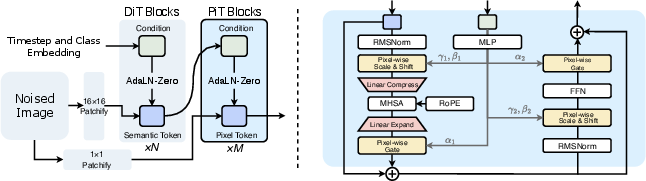
Figure 1: Overview of PixelDiT: a dual-level, fully transformer-based diffusion architecture that operates directly in pixel space.
Pixel-wise AdaLN Modulation
Distinct from standard global or patch-wise AdaLN, PixelDiT employs a linear expansion from semantic tokens to produce per-pixel normalization parameters, enabling highly localized, context-aware updates at each spatial location.
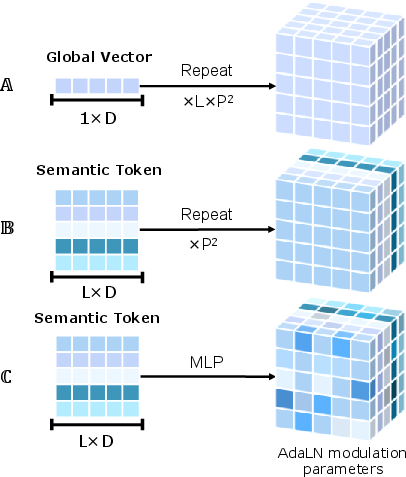
Figure 2: AdaLN modulation strategies—contrast global, patch-wise, and pixel-wise AdaLN, with the latter realizing per-pixel context alignment.
Pixel Token Compaction
Pixel token compaction substitutes the expensive global attention over all pixel tokens with localized compaction—first, compress p2 spatial locations into a token per patch, then apply self-attention, and finally decompress. This allows scaling to megapixel resolutions while avoiding sequence lengths that quickly exhaust resources in naïve pixel-level transformers.
Empirical Results
ImageNet Generation
PixelDiT-XL achieves FID 1.61 on ImageNet 256×256, outperforming prior pixel-space models (e.g., PixelFlow gFID 1.98, PixNerd gFID 1.93, EPG gFID 2.04) and significantly narrowing the gap with leading latent diffusion models. PixelDiT delivers high recall (0.64) and competitive IS (292.7), attesting to balanced diversity–faithfulness generation performance. Qualitative examination reveals sharp textures, coherent object boundaries, and globally consistent structure.












Figure 3: Qualitative ImageNet 256×256 results using PixelDiT-XL at high guidance scale, demonstrating fine-grained texture and semantic coherence.
Text-to-Image Generation (T2I)
Via MM-DiT conditioning on the patch pathway and maintaining the pixel-level design, PixelDiT scales to T2I tasks at 1024² resolution. Achieving a GenEval score of 0.74 and DPG-bench score of 83.5 at 1K resolution, PixelDiT approaches or matches state-of-the-art latent models, outperforming all prior pixel-space approaches at this scale.
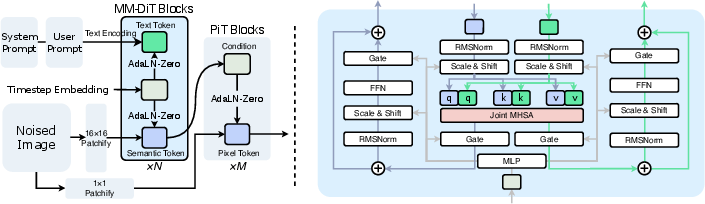
Figure 4: T2I variant architecture: MM-DiT blocks in the patch-level pathway enable multi-modal fusion while pixel-level blocks handle per-pixel detail.
The model achieves 0.33 samples/s throughput at 1024² with 1.3B parameters—an efficiency competitive with latent methods.
Effectiveness in Image Editing
In image editing scenarios, PixelDiT avoids VAE-induced artifacts common in latent models, resulting in superior content and detail preservation, especially for fine-grained structures (e.g., small text or texture in localized edits).
Critical Ablations
The ablations demonstrate that both pixel token compaction and pixel-wise AdaLN are indispensable. Removing compaction triggers intractable memory costs and degraded results (9.84 gFID to out-of-memory), while removing pixel-wise AdaLN yields a notable performance drop (from 2.36 gFID to 3.50 at 80 epochs). Sequence length and compaction rates are also found to strongly affect convergence and final quality, with aggressive compaction yielding both faster training and optimal FID.
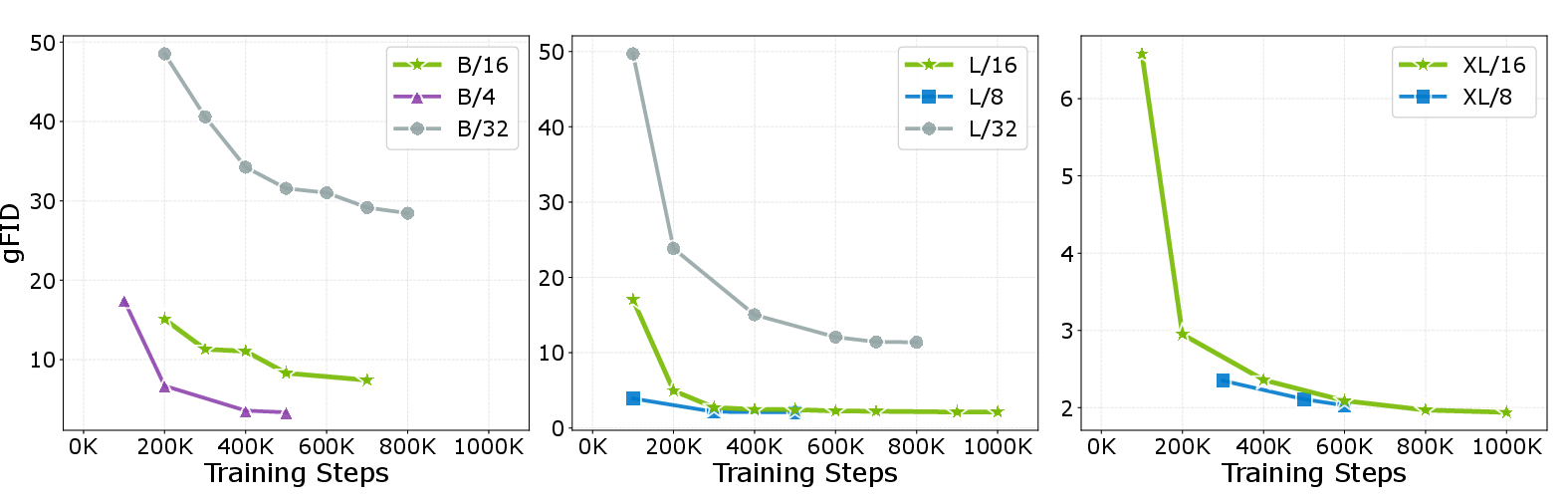
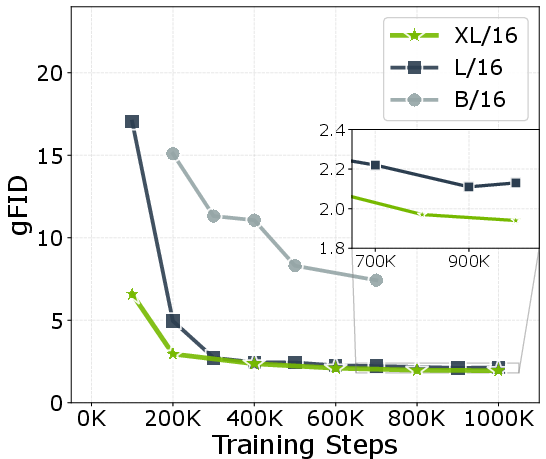
Figure 5: Patch size and model scaling ablations. Diminishing returns with extremely small patches at scale; optimal compute-quality tradeoff at moderate patch size.
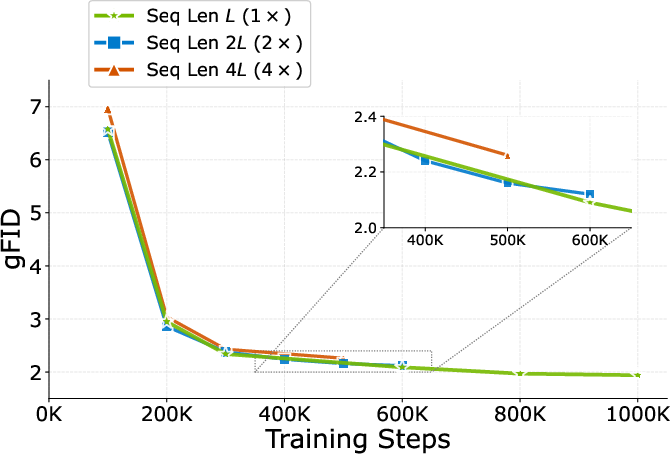
Figure 6: Ablation of Pixel Token Compaction rates; the 1× (default) compaction yields best practical trade-off in compute and quality.
Architectural and Practical Implications
PixelDiT demonstrates that highly efficient and high-fidelity pixel-space diffusion is achievable given appropriately structured transformers. The model decouples global and local learning, optimally amortizing compute while ensuring locality and semantic context. Practically, PixelDiT alleviates the two-stage autoencoder bottleneck and associated artifacts (such as texture smoothing and distributional shift), and unlocks precise local editing—critical for downstream tasks needing artifact-free outputs.
The results indicate that pixel-space diffusion, when empowered by architectural innovations in transformer computation and per-pixel conditioning, can close the historical quality gap with latent diffusion and scale to previously unattainable resolutions.
Outlook
The PixelDiT design reframes pixel-space diffusion as a primary, not auxiliary, path for generative visual modeling. The tractability and demonstrated quality at megapixel scales point toward future work in (a) architecture scaling, (b) integration with retrieval and large-scale multi-modal pretraining, and (c) further reduction of compute requirements through hardware-tailored attention kernels and sparse computation.
This work positions pixel-level transformers—previously dismissed as impractical for high-resolution generative modeling—as competitive, practical, and in several aspects superior for image fidelity, editability, and fine detail preservation.
Conclusion
PixelDiT addresses longstanding pitfalls of latent diffusion by unifying semantics and local detail modeling in a dual-pathway, fully transformer-based diffusion framework directly in pixel space. Through pixel-wise AdaLN and aggressive pixel token compaction, it maintains the fidelity advantages of pixel modeling while achieving compute profiles comparable to latent baselines. Results on both class- and text-conditional tasks at high resolution demonstrate that efficient pixel modeling, rather than latent representation, is the main barrier to high-fidelity pixel-space diffusion. PixelDiT sets a new standard for end-to-end diffusion-based generative modeling (2511.20645).