Cross Domain Evaluation of Multimodal Chain-of-Thought Reasoning of different datasets into the Amazon CoT Framework
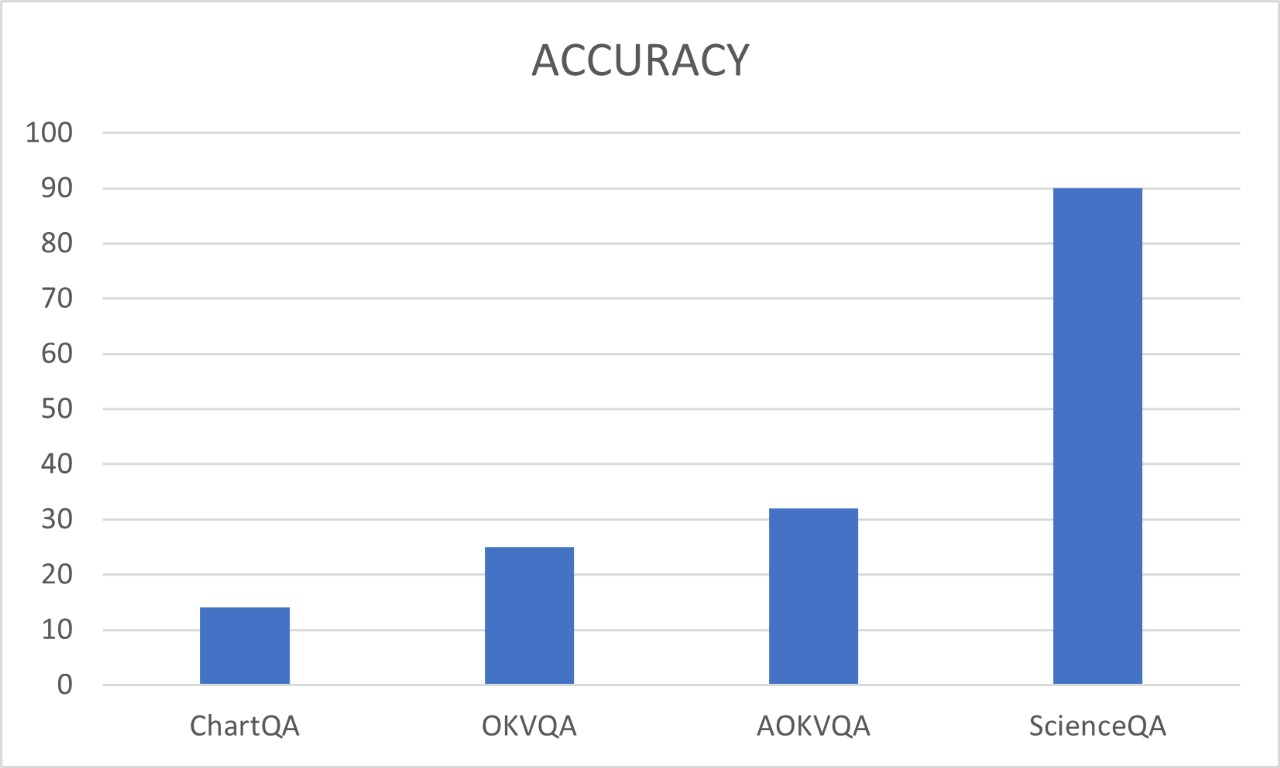
Abstract: While recent work has extended CoT to multimodal settings, achieving state-of-the-art results on science question answering benchmarks like ScienceQA, the generalizability of these approaches across diverse domains remains underexplored. This work presents a comprehensive analysis of Multimodal Chain-of-Thought (Multimodal-CoT) reasoning, evaluating its effectiveness on the A-OKVQA, OKVQA and ChartQA datasets, which requires broad commonsense and world knowledge beyond scientific reasoning. We implement the two-stage framework proposed by Zhang et al. [3], which separates rationale generation from answer inference and integrates vision features through a gated fusion mechanism with T5-based LLMs. Through systematic ablation studies, we analyze the contributions of vision features, rationale quality, and architectural choices. Our findings reveal that while vision integration significantly reduces hallucination in rationale generation, the effectiveness of CoT reasoning varies substantially across question types, with commonsense reasoning presenting particular challenges. This work provides practical insights for researchers implementing multimodal reasoning systems and identifies key areas for future improvement in cross-domain generalization.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Glossary
- AdamW: An optimization algorithm that decouples weight decay from the gradient update to improve generalization in transformer training. "Optimization is performed using AdamW with a linear learning-rate warmup schedule."
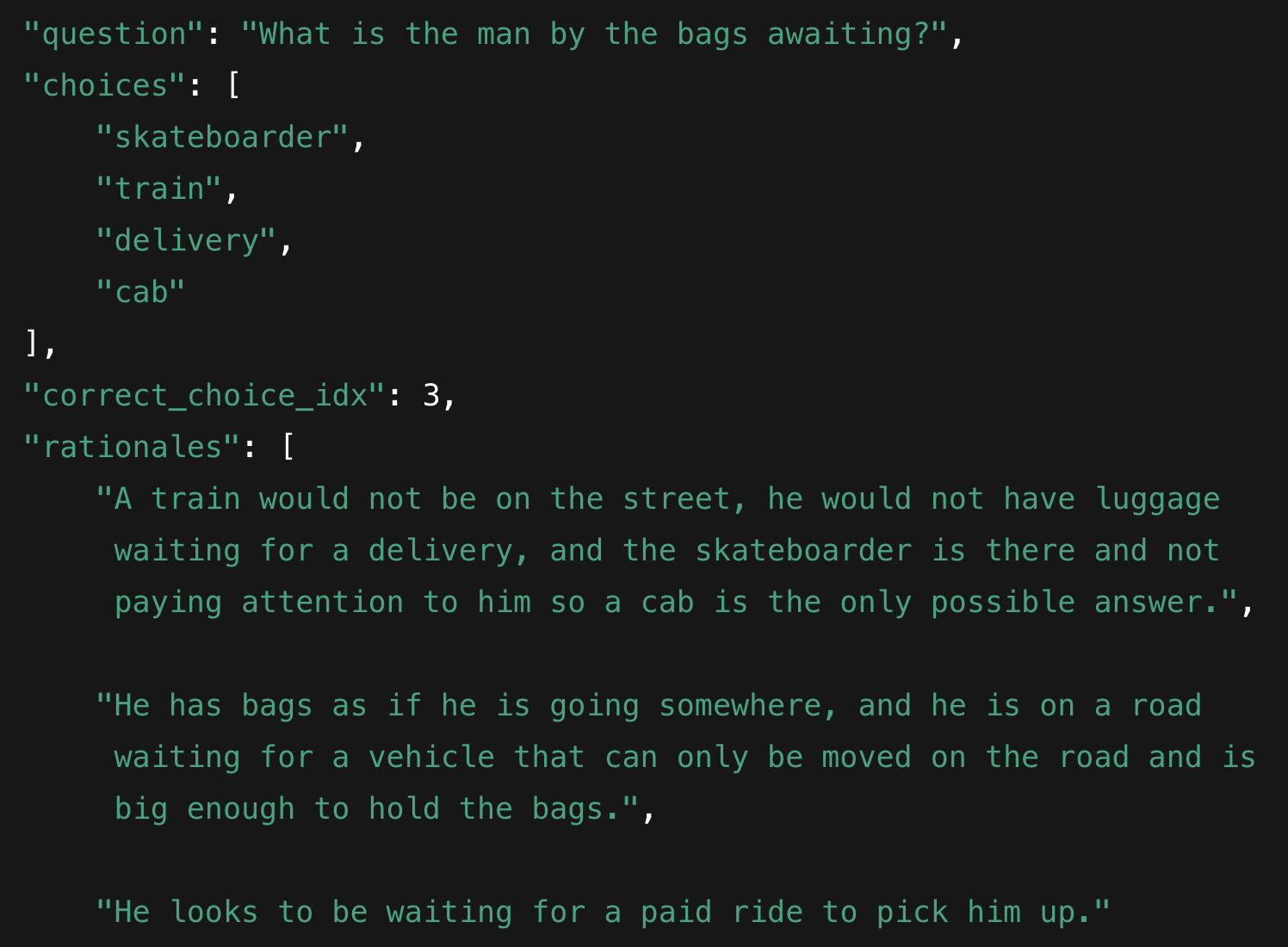
- A-OKVQA: A benchmark for open-ended VQA that requires world knowledge and includes richer annotations and rationales. "A-OKVQA~\cite{schwenk2022okvqa} extends OK-VQA by providing richer annotations and multiple valid rationales."
- ablation studies: Systematic removal or modification of model components to analyze their individual contributions. "Through systematic ablation studies, we analyze the contributions of vision features, rationale quality, and architectural choices."
- attention mask: A binary or weighted mask that controls which tokens the model’s attention mechanism can focus on. "A corresponding extension of the attention mask ensures that the decoder attends to both visual and textual tokens."
- beam search: A heuristic decoding algorithm that explores multiple candidate sequences to select high-probability outputs. "captions are generated using beam search, and stored in a mapping question_id â caption."
- Bilinear Attention Networks (BAN): A VQA model architecture that uses bilinear pooling to capture interactions between visual and textual features. "Methods like Bottom-Up Top-Down attention~\cite{anderson2018bottom}, Bilinear Attention Networks (BAN)~\cite{kim2018bilinear}, and Multi-modal Compact Bilinear pooling (MCB)~\cite{fukui2016multimodal} demonstrated the importance of fine-grained vision-language interaction."
- BLIP: A vision-language pretraining and captioning model used to generate image captions for multimodal tasks. "we generate them using the BLIP image captioning model:"
- Bottom-Up Top-Down attention: An attention mechanism combining region-level visual features (bottom-up) with task-driven signals (top-down). "Methods like Bottom-Up Top-Down attention~\cite{anderson2018bottom}, Bilinear Attention Networks (BAN)~\cite{kim2018bilinear}, and Multi-modal Compact Bilinear pooling (MCB)~\cite{fukui2016multimodal} demonstrated the importance of fine-grained vision-language interaction."
- Chain-of-Thought (CoT) prompting: A prompting strategy that elicits intermediate reasoning steps to improve problem solving. "Chain-of-Thought (CoT) prompting emerged as a breakthrough technique for eliciting complex reasoning from LLMs."
- ChartQA: A dataset for question answering over charts requiring numerical and visual reasoning over plots. "ChartQA~\cite{chartqa} consists of bar charts, pie charts, and line plots paired with natural-language questions requiring numerical comparisons, trend understanding, and reasoning over visualized data."
- CLIP: A vision-LLM trained with contrastive objectives to align images and text. "Models like CLIP~\cite{radford2021learning}, ALIGN~\cite{jia2021scaling}, and BLIP~\cite{li2022blip} learn aligned vision-language representations through contrastive learning or image-text matching objectives."
- compositional reasoning: Solving complex problems by decomposing them into simpler subproblems and composing solutions. "This hierarchical approach proves particularly effective for compositional reasoning tasks."
- Consensus scoring: An evaluation method that awards partial credit based on agreement with multiple human annotations. "Consensus scoring: Uses OK-VQA's fractional VQA-style voting."
- contrastive learning: A training paradigm that pulls aligned pairs (image-text) together and pushes non-matching pairs apart. "Models like CLIP~\cite{radford2021learning}, ALIGN~\cite{jia2021scaling}, and BLIP~\cite{li2022blip} learn aligned vision-language representations through contrastive learning or image-text matching objectives."
- cosine decay: A learning rate schedule that decreases the rate following a cosine curve after a warmup period. "Cosine decay after warmup."
- Exact Match (EM): A metric that checks if the normalized predicted answer exactly matches the normalized ground truth. "Exact Match (EM): String-normalized strict match."
- F1-score: A harmonic mean of precision and recall computed over token-level overlaps between prediction and ground truth. "F1-score: Token-level overlap via precision/recall."
- FLAN-T5-Base: A variant of the T5 model instruction-tuned to follow prompts, used as the backbone for reasoning. "We use the FLAN-T5-Base model as the backbone, consistent with the original paper."
- gated attention mechanism: A fusion technique that modulates the contribution of image and text features via a learned gate during attention. "Image embeddings are fused with textual representations through the gated attention mechanism:"
- gated fusion mechanism: A model component that integrates visual features with LLM representations using gates to control information flow. "integrates vision features through a gated fusion mechanism with T5-based LLMs."
- gradient accumulation: A training technique that simulates larger batch sizes by summing gradients over multiple steps before updating weights. "Due to GPU memory constraints, we use a small batch size with gradient accumulation."
- GPT-4V: A multimodal extension of GPT-4 that accepts visual inputs for integrated reasoning. "GPT-4V extends GPT-4's capabilities to visual inputs, while Gemini~\cite{reid2024gemini} provides native multimodal understanding."
- Image-text matching objectives: Training losses that encourage correct pairing between images and their corresponding textual descriptions. "Models like CLIP~\cite{radford2021learning}, ALIGN~\cite{jia2021scaling}, and BLIP~\cite{li2022blip} learn aligned vision-language representations through contrastive learning or image-text matching objectives."
- InstructBLIP: An instruction-tuned vision-LLM enabling controlled multimodal reasoning. "Instruction-Tuned Multimodal Models: LLaVA~\cite{liu2023visual}, InstructBLIP~\cite{dai2023instructblip}, and LLaMA-Adapter~\cite{zhang2023llama} fine-tune large vision-LLMs on instruction-following data, enabling more flexible and controllable multimodal reasoning."
- instruction-tuned multimodal models: Models fine-tuned with instruction-following data to improve controllability and task alignment across modalities. "Instruction-Tuned Multimodal Models: LLaVA~\cite{liu2023visual}, InstructBLIP~\cite{dai2023instructblip}, and LLaMA-Adapter~\cite{zhang2023llama} fine-tune large vision-LLMs on instruction-following data, enabling more flexible and controllable multimodal reasoning."
- learning-rate warmup schedule: A strategy that starts training with a low learning rate and gradually increases it to stabilize optimization. "Optimization is performed using AdamW with a linear learning-rate warmup schedule."
- Least-to-Most Prompting: A prompting method that decomposes a problem into ordered subproblems solved sequentially. "Least-to-Most Prompting: Zhou et al.~\cite{zhou2022least} proposed decomposing complex problems into simpler sub-problems solved sequentially, with each solution building on previous results."
- majority voting: A technique that selects the most frequent answer from multiple annotations or sampled predictions. "Algorithm: Majority Voting"
- Multimodal Chain-of-Thought (Multimodal-CoT): A framework that generates explicit reasoning steps across both text and images. "Zhang et al.~\cite{zhang2023multimodal} introduced Multimodal-CoT, a framework that incorporates both language and vision modalities into a two-stage reasoning process."
- Numeric Accuracy: A tolerance-based metric that checks if a predicted number is within a small margin of the ground truth. "Numeric Accuracy: A tolerance-based numeric comparison:"
- OK-VQA: A VQA dataset requiring external commonsense and world knowledge beyond what is visible in the image. "OK-VQA~\cite{marino2019ok} requires answering open-ended questions about natural images where the answer is not present in the image alone."
- ScienceQA: A structured, multiple-choice multimodal QA benchmark focused on scientific reasoning. "Their approach achieved state-of-the-art performance on the ScienceQA benchmark~\cite{lu2022learn}"
- self-consistency decoding: A decoding strategy that samples multiple reasoning paths and aggregates answers to improve reliability. "Wang et al.~\cite{wang2022self} introduced self-consistency decoding, which samples multiple reasoning paths and selects the most consistent answer through majority voting."
- Semantic Similarity: An evaluation measure that compares meaning similarity between prediction and ground truth, often using embeddings. "Semantic Similarity: Using SentenceTransformer embeddings:"
- SentenceTransformer embeddings: Vector representations produced by SentenceTransformer models for computing semantic similarity. "Using SentenceTransformer embeddings:"
- ViT-L/32: A Vision Transformer variant that processes images by splitting them into 32×32 patches and using a large model configuration. "Following the MM-CoT architecture, vision features extracted from a ViT-L/32 encoder are first projected into the T5 embedding dimension (768) using a trainable linear projection layer."
- vision-language pretraining: Joint pretraining of models on paired image-text data to learn aligned multimodal representations. "Vision-Language Pretraining: Models like CLIP~\cite{radford2021learning}, ALIGN~\cite{jia2021scaling}, and BLIP~\cite{li2022blip} learn aligned vision-language representations through contrastive learning or image-text matching objectives."
- visual entailment: A task that treats image-question answering as determining whether visual evidence supports or contradicts textual statements. "Visual Entailment~\cite{xie2019visual} frames VQA as a reasoning task."
- Visual Question Answering (VQA): A task where models answer questions about images combining computer vision and natural language understanding. "Visual Question Answering (VQA) requires models to answer natural language questions about images."
- Vision–Language Fusion: Architectural mechanisms for integrating visual features with textual representations for joint reasoning. "VisionâLanguage Fusion"
- zero-shot CoT reasoning: Eliciting chain-of-thought explanations without task-specific examples by using simple prompting cues. "Zero-Shot CoT: Kojima et al.~\cite{kojima2022large} showed that simply appending phrases like \"Let's think step by step\" to questions enables zero-shot CoT reasoning"
Collections
Sign up for free to add this paper to one or more collections.