- The paper demonstrates that realistic, repeated JPEG augmentations significantly improve deepfake detector generalization.
- It quantifies how extended training and optimized input processing, such as full-image resizing and multi-crop strategies, benefit various model architectures.
- The study shows that replay-based continual learning effectively mitigates catastrophic forgetting while adapting detectors to emerging synthetic methods.
Generalized Design Choices for Deepfake Detectors
Introduction and Motivation
The increasing sophistication of generative models has precipitated a growing challenge for deepfake detection systems. With rapid advances in text-to-image models and diffusion-based architectures, distinguishing authentic images from AI-generated content demands robust detectors resilient to diverse post-processing and unseen synthetic methods. This paper performs a systematic, architecture-agnostic evaluation of design choices—specifically those surrounding data augmentation, training duration, input processing, multiclass supervision, and continual/incremental learning—establishing evidence-driven practices for optimal deepfake detector generalization on temporally evolving benchmarks, notably AI-GenBench.
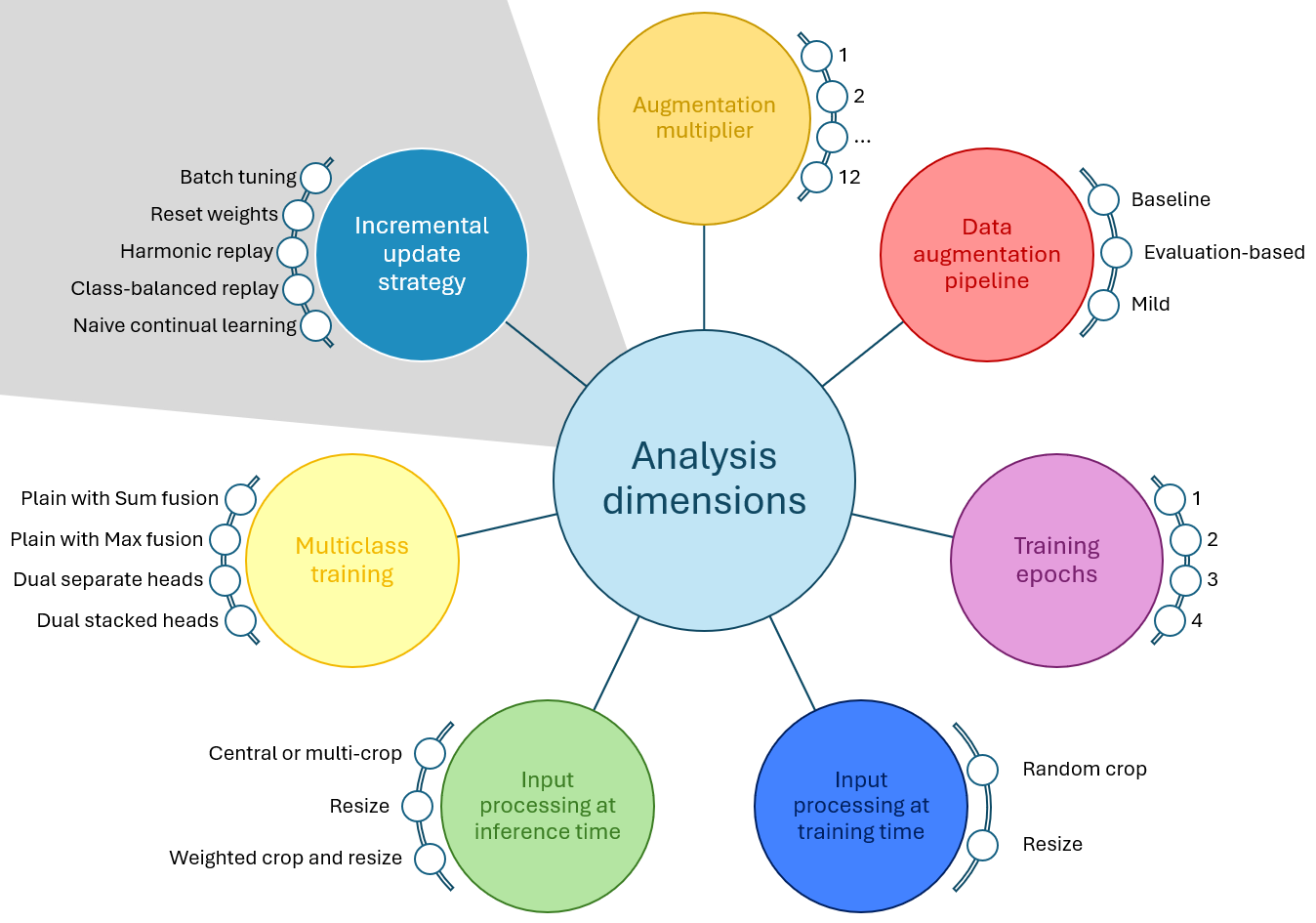
Figure 1: The dimensions evaluated in this work encompass training, inference, and incremental update design choices for deepfake detectors.
Data Augmentation: Realism and Compression
A principal factor for detector robustness is the augmentation pipeline. The study contrasts aggressive perturbation strategies with more realistic augmentations simulating social media re-encodings. The evaluation-based pipeline, incorporating up to three probabilistic JPEG compressions, outperforms the baseline of strong transformations and single compression across all backbone architectures. The implication is clear: augmentations closely imitating real-world transmission artifacts drive better generalization to future synthetic generators.
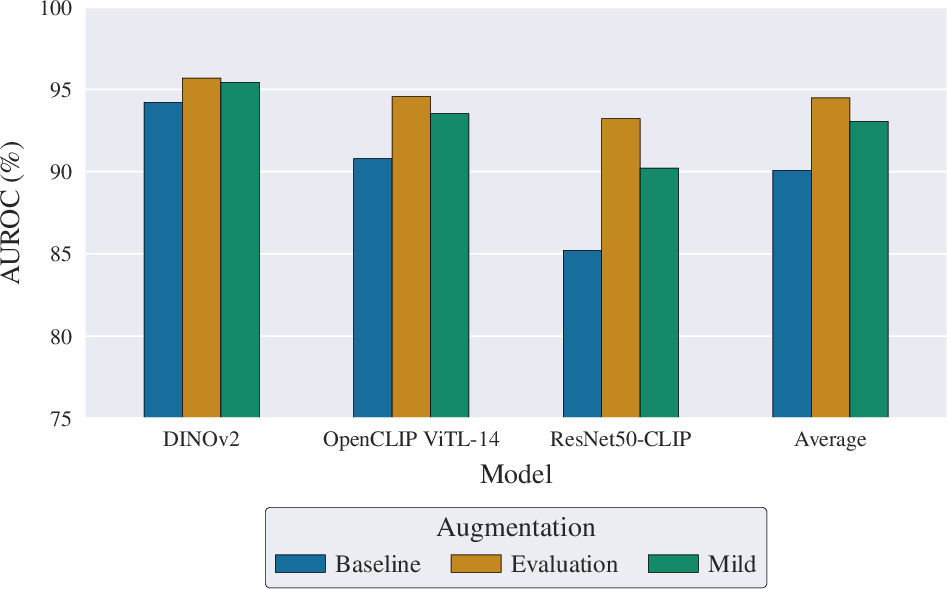
Figure 2: AUROC impact of training-time augmentation pipelines across detector architectures.
Repeated JPEG compression is further isolated and demonstrated to meaningfully enhance detection performance, suggesting its critical role in exposure to real-world degradations.
Augmentation Multiplier and Training Duration
Systematic variation of the augmentation multiplier (am) and epoch count reveals that increased dataset "expansion" through augmentation or additional training epochs yields equivalent generalization improvements—particularly for larger models like DINOv2 and ViT-L CLIP, which quickly plateau at optimal performance. For smaller backbones, such as ResNet-50 CLIP, training longer continues to confer benefits. Nevertheless, in AI-GenBench-constrained scenarios (am=4), four training epochs provide an effective performance-efficiency compromise.
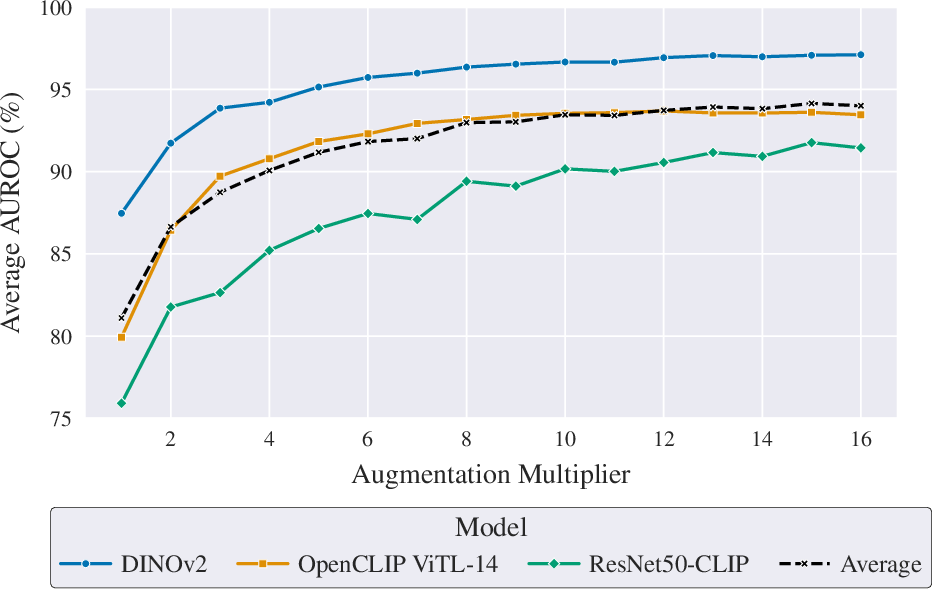
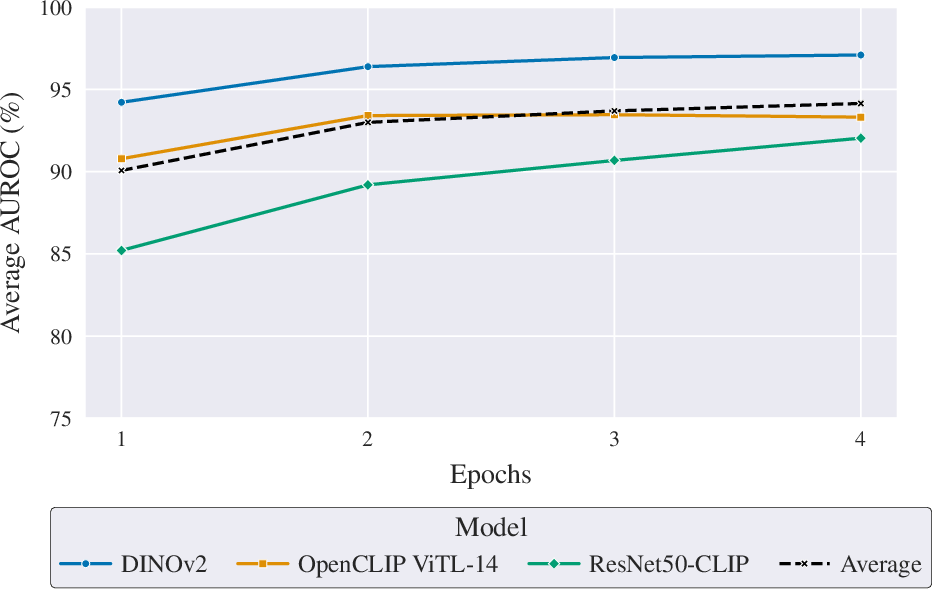
Figure 3: The effect of augmentation multiplier and training epochs on generalization (AUROC) performance.
Detector performance is sensitive to preprocessing of input images. The standard approach—resizing the entire image to model resolution for both training and evaluation—is generally optimal, although larger transformer backbones (DINOv2, ViT-L CLIP) benefit noticeably from hybrid strategies that combine full-image and multi-crop inference via score fusion. This suggests that scale and semantic context, in addition to fine-grained forensic cues captured by cropping, may enhance discrimination for models with sufficient representational capacity.
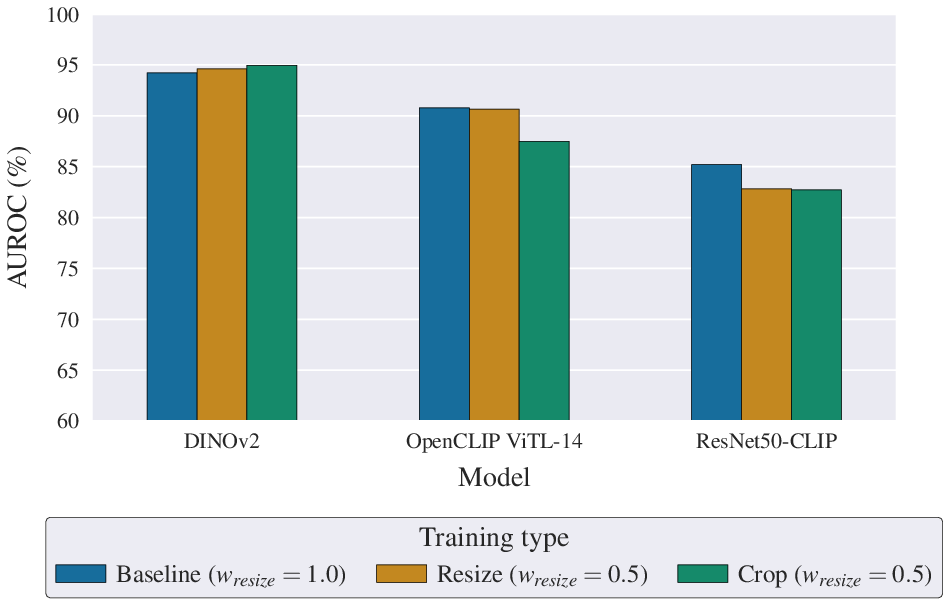
Figure 4: AUROC comparison of training/evaluation input strategies for different detector backbones.
Multiclass Supervision and Fusion
The role of generator-conditional supervision is dissected through multiclass, dual-head, and centroid-based scoring approaches. Pure multiclass training, followed by sum or max fusion, is consistently inferior to direct binary optimization. However, integrating generator labels in a dual-head setup with an auxiliary multiclass loss elevates performance for large transformers, achieving competitive results and providing generator attribution without degrading binary detection.
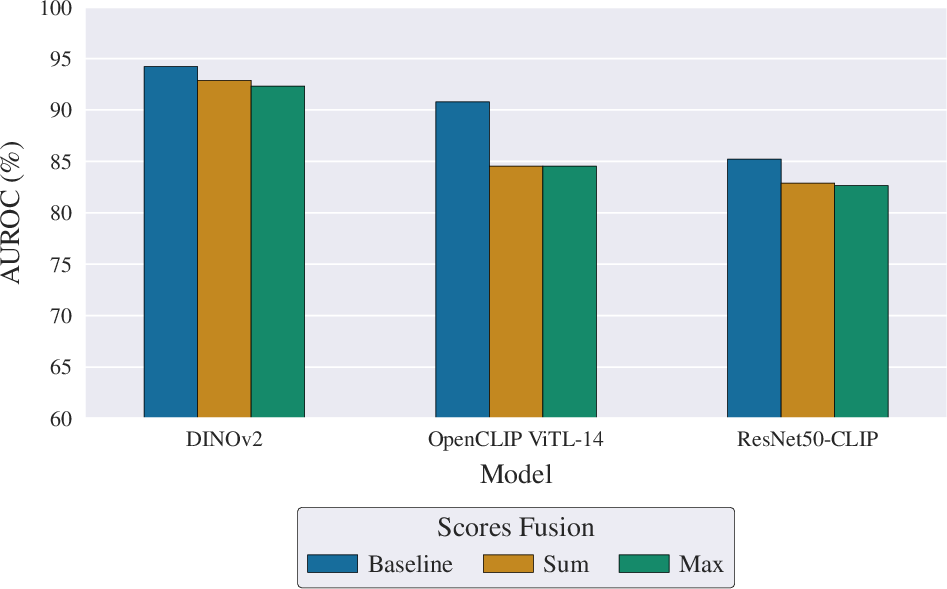
Figure 5: Comparison of fusion strategies for multiclass training against direct binary optimization.
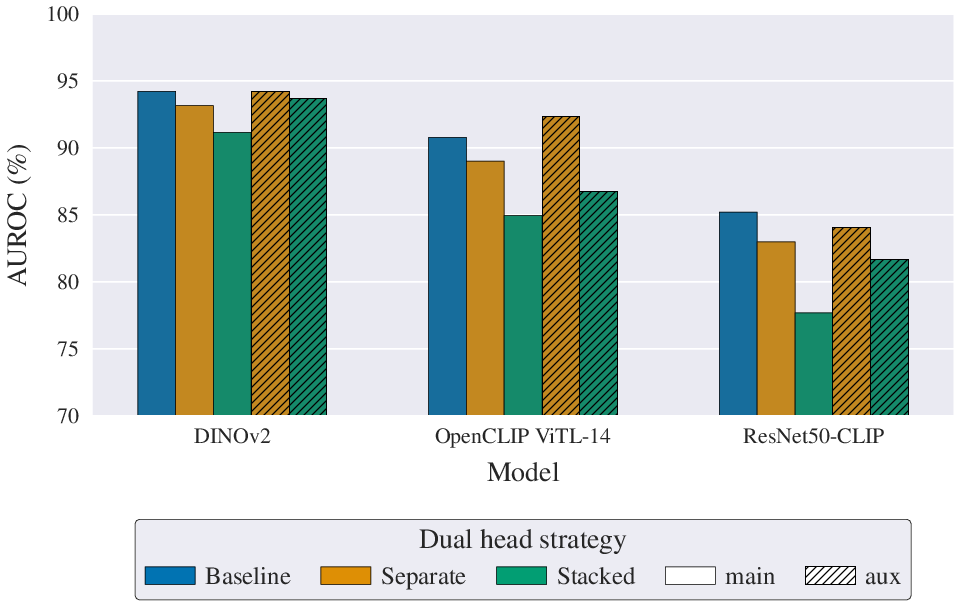
Figure 6: Dual-head architectures and loss weightings: separate heads with auxiliary multiclass loss yield the most gains for high-capacity backbones.
Distance-to-centroid scoring provides no substantial gains over the baseline MLP head, and is less reliable, reaffirming the robustness of binary-optimized end-to-end classification for this domain.
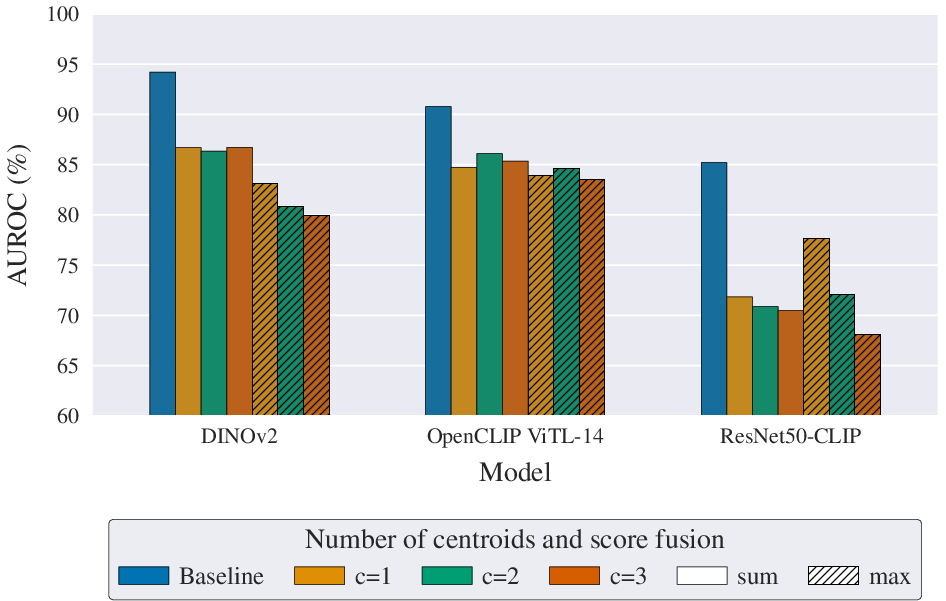
Figure 7: AUROC effects of centroid count and fusion strategy for distance-based scoring across backbones.
Incremental Update and Continual Learning
A realistic deployment scenario is detectors incrementally adapting to new synthetic generators. Standard batch retraining yields high performance but is computationally expensive. Naive incremental training suffers from catastrophic forgetting. Replay-based continual learning approaches (both class-balanced and harmonic scheduling) effectively preserve knowledge of prior generators and maintain adaptability to emerging generative methods, with the harmonic schedule offering a practical reduction in memory growth and computational overhead. The forgetting effect is more pronounced in lower-capacity models—larger models are more robust in both retention and adaptation.
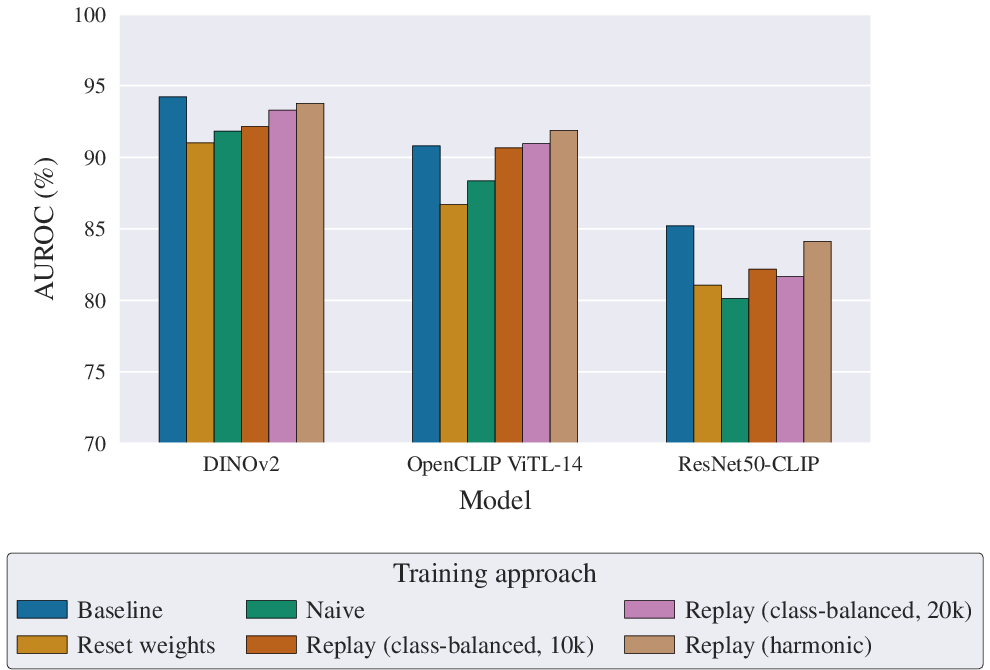
Figure 8: Next Period AUROC for batch, naive, and replay-based incremental learning strategies.
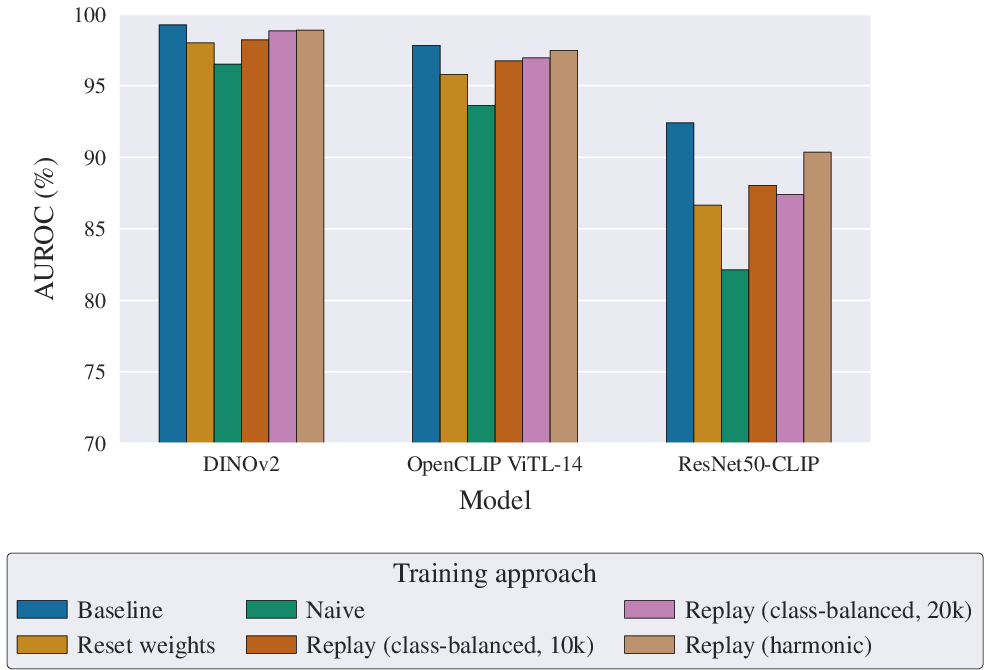
Figure 9: Past Period AUROC for incremental learning strategies, showing superior retention of older generator detection capability with replay buffers.
Synthesis of Optimal Design Choices
Integrating the most effective strategies—extended training (4 epochs), evaluation-style augmentation with repeated JPEG compression, full-image resizing for input, and auxiliary multiclass supervision (dual-head architecture)—the DINOv2 backbone achieves a mean Next Period AUROC of 97.36%, establishing a new state-of-the-art on AI-GenBench. These practices are robust across model architectures and practical for scalable, real-world deployments.
Conclusion
This study provides a rigorous, systematic decomposition of deepfake detector design across crucial dimensions. Strong empirical evidence demonstrates the value of realistic, repeated compression-based augmentation, balanced training duration, semantic-aware input processing, and judicious use of generator labels. Replay-based continual learning is shown to be effective for temporal adaptation under resource constraints. The established best-practices are broadly transferable, setting a technical foundation for robust, future-proof deepfake detectors. Anticipated extensions include systematic evaluation in settings with localized or inpainted manipulations, and dynamic adaptation to adversarial synthetic media generation.