- The paper presents RoParQ, a novel benchmark with the XParaCon metric that quantifies LLM robustness by evaluating cross-paraphrase consistency.
- It employs paraphrase-aware supervised fine-tuning using multiple paraphrasing engines to enforce invariant reasoning across different question formulations.
- Experimental results show that even lightweight models achieve competitive paraphrase alignment, underpinning cost-effective improvements in model robustness.
RoParQ: Paraphrase-Aware Alignment of LLMs for Robustness to Paraphrased Questions
Motivation and Problem Definition
LLMs continue to display pronounced sensitivity to superficial variations in input queries, evident in scenarios where semantically equivalent but syntactically distinct paraphrases elicit inconsistent responses, undermining their reliability in open-domain QA and downstream safety-critical deployments. This behavior suggests a reliance on surface-level cues rather than grounded semantic comprehension, raising critical doubts about their deployment in real-world settings with substantial linguistic variability.
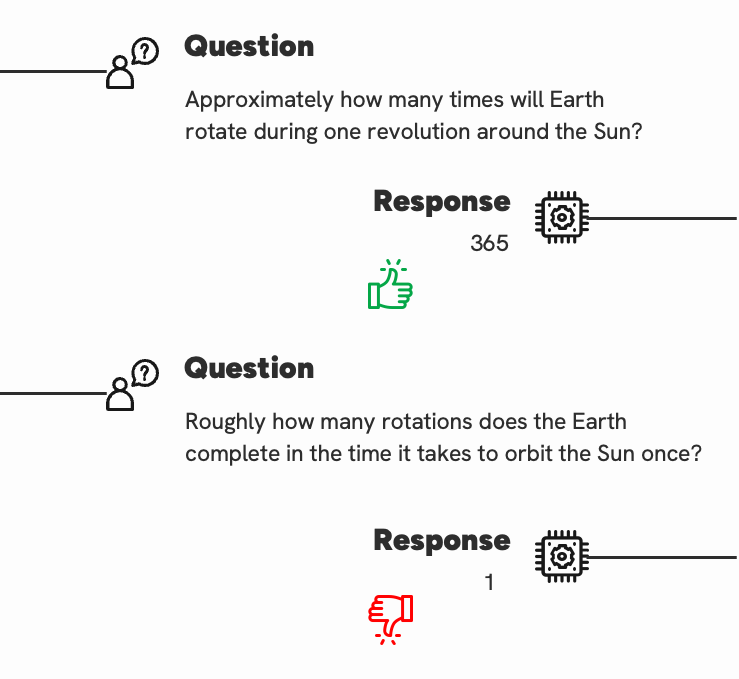
Figure 1: An example of the LLM generating an incorrect response when given a paraphrased question.
To address this deficiency, the paper introduces RoParQ—the first benchmark deliberately constructed to systematically assess and enforce cross-paraphrase consistency within closed-book multiple-choice QA. The central contribution is the RoParQ dataset, complemented by the XParaCon metric, and an alignment approach leveraging paraphrase-aware, reasoning-based SFT (Supervised Fine-Tuning).
RoParQ Benchmark Construction
Questions are sourced from major QA datasets—MMLU, ARC, CommonsenseQA, and MathQA—ensuring comprehensive coverage of both general knowledge and math reasoning domains. The construction pipeline performs several data hygiene steps: passage-containing, underspecified, multi-sentence, and masked-word questions are excluded, focusing exclusively on closed-book, short, well-formed items.
To generate high-quality paraphrased variants, Gemini 2.5 Flash Lite and Claude 3.5 Sonnet (proprietary models) are used as paraphrasing engines under strict instructions to preserve semantics and the multiple-choice QA format. Each item thus consists of three variants: the original question, a Gemini paraphrase, and a Claude paraphrase.
A critical methodological innovation lies in selecting only examples that empirically elicit cross-paraphrase inconsistency. An open-source judge LLM (Llama-3.1-8B-Instruct) analyzes response confidence across 24 permutations per item (3 variants × 8 choice orderings). Items answered consistently correctly or incorrectly are excluded; only those displaying inconsistent confidence across paraphrases are retained, yielding a testbed targeting the precise robustness failures of contemporary LLMs.
XParaCon: Robustness Metric
The XParaCon metric formalizes robustness by computing the negative logarithm (base 2) of the mean per-example standard deviation in accuracies across the three paraphrased variants. This approach quantifies not just accuracy loss but the consistency of correct answers irrespective of formulation—yielding a direct, interpretable robustness score.
Model Evaluation Protocol
Pre-trained baselines span the Llama 3.1, Qwen 3, Mistral families (with sizes from under 10B to over 400B parameters), and comparisons include top proprietary models (Gemini 2.5 Flash Lite, Claude 3.5 Sonnet). Both general knowledge and math reasoning splits are assessed to investigate robustness across semantic and procedural regimes.
Prompts are tailored for domain: for general knowledge, standard multiple-choice QA formatting is used; for math reasoning, models are instructed to "think step by step" prior to answering, enforcing explicit reasoning and reducing spurious answer artifacts.

Figure 2: Prompt used for multiple choice question answering in the general knowledge subset.

Figure 3: Prompt used for multiple choice question answering in the math reasoning subset, eliciting explicit intermediate reasoning steps.
Paraphrase-aware SFT is implemented by presenting the model with an original and paraphrase pair and supervising the model to both restate (paraphrase) and guarantee answer equivalence, embedding paraphrase consistency into the model’s reasoning trace.

Figure 4: Prompt used for question paraphrasing to generate high-quality, meaning-preserving variants.

Figure 5: Prompt for paraphrase-aware multiple choice QA in the general knowledge domain, enforcing answer invariance under paraphrase during fine-tuning.

Figure 6: Paraphrase-aware, step-by-step math MCQA prompt, applied in fine-tuning and inference.
Results and Analysis
Robustness trends strongly correlate with parameter count, both in general knowledge and math reasoning. Claude 3.5 Sonnet and Llama-3.1-405B establish best-in-class baselines on XParaCon, with proprietary models consistently showing superior paraphrase alignment in math-heavy domains.
Fine-tuning small/medium open-source models under the paraphrase-aware SFT regime closes the robustness gap: for instance, Llama-3.1-8B-Instruct’s XParaCon increases from 2.186 to 2.629 (general knowledge) and 1.924 to 2.316 (math reasoning). The most notable outcome is that fine-tuned lightweight models often match or exceed the consistency of far larger pre-trained models while maintaining competitive accuracy—for example, Qwen3-4B-Instruct-2507 achieves XParaCon 4.856 post-alignment, rivaling much larger architectures.
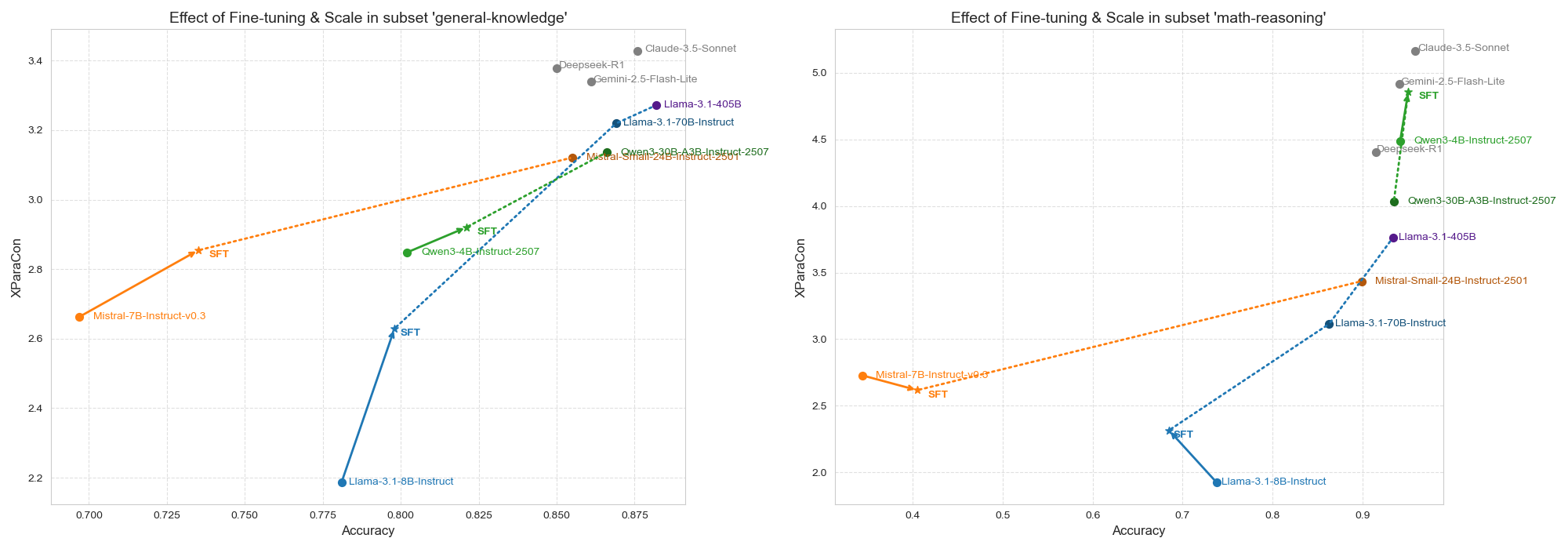
Figure 7: Movements of accuracies and XParaCon scores within model families, capturing the effect of scale and fine-tuning interventions.
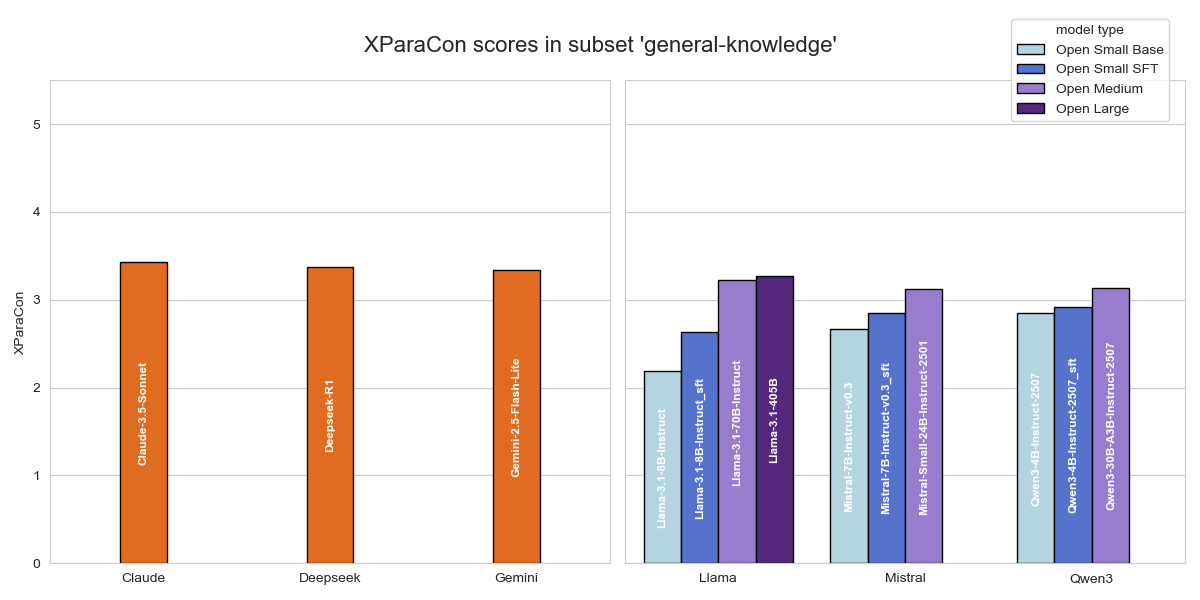
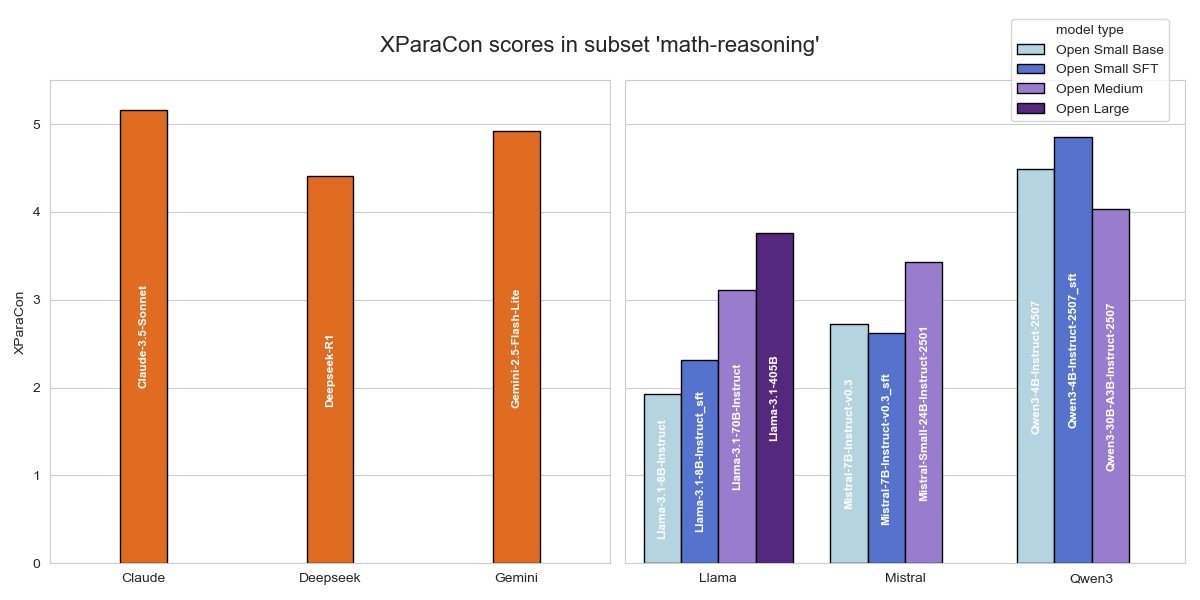
Figure 8: XParaCon scores for each model on the general knowledge subset, illustrating improvements from fine-tuned alignment.
A further observation is the marginal, but non-negligible, accuracy-robustness trade-off in some cases—especially in math reasoning for the most constrained models, suggesting a ceiling effect where enforced invariance can slightly suppress the capacity to answer idiosyncratic formulations.
Practical and Theoretical Implications
This evidence suggests that robust, paraphrase-invariant reasoning is not simply an emergent function of scale; rather, it is tractable to targeted alignment interventions even in smaller models. The RoParQ benchmark and XParaCon offer precise instruments for quantifying and driving further research into compositional generalization, semantic invariance, and real-world readiness of LLMs under adversarial or natural data shift scenarios.
From a theoretical perspective, the results indicate that semantic regularization—forcing consistency across nominally semantically equivalent but syntactically diverse inputs—effectively encourages abstraction from pattern-matching to more global representations. This property is essential for bridging the gap between parametric “look-up” and genuine language understanding.
Future Directions
Subsequent work should expand RoParQ to open-ended QA, cross-lingual, and multi-hop reasoning, and explore more advanced forms of alignment such as RLHF or meta-learning for paraphrase robustness. Investigating the intersection between consistency enforcement and model interpretability, as well as robustness under adversarial or compositional perturbations, presents further foundational directions.
Conclusion
RoParQ and XParaCon establish rigorous, domain-agnostic testbeds and metrics for evaluating and aligning LLMs for paraphrase-invariant QA. The demonstrated efficacy of paraphrase-aware fine-tuning in elevating small models to parity with, or above, much larger LLMs has significant implications for cost-effective deployment and democratization of robust, reliable AI. The proposed framework sets the agenda for future research on training and evaluating models not just on correctness, but on genuine, semantically coherent understanding across linguistic variability.