Seeing without Pixels: Perception from Camera Trajectories
Abstract: Can one perceive a video's content without seeing its pixels, just from the camera trajectory-the path it carves through space? This paper is the first to systematically investigate this seemingly implausible question. Towards this end, we propose a contrastive learning framework to train CamFormer, a dedicated encoder that projects camera pose trajectories into a joint embedding space, aligning them with natural language. We find that, contrary to its apparent simplicity, the camera trajectory is a remarkably informative signal to uncover video content. In other words, "how you move" can indeed reveal "what you are doing" (egocentric) or "observing" (exocentric). We demonstrate the versatility of our learned CamFormer embeddings on a diverse suite of downstream tasks, ranging from cross-modal alignment to classification and temporal analysis. Importantly, our representations are robust across diverse camera pose estimation methods, including both high-fidelity multi-sensored and standard RGB-only estimators. Our findings establish camera trajectory as a lightweight, robust, and versatile modality for perceiving video content.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Seeing without Pixels: Perception from Camera Trajectories
Overview
This paper asks a surprising question: can we tell what’s happening in a video without looking at the video’s pixels at all—just by analyzing how the camera moved while filming? The authors show that the path a camera takes over time (its “trajectory”) carries a lot of clues about the activity being recorded. They build a small AI model called CamFormer that learns to understand these camera movements and connect them to simple text descriptions, like “walking” or “shooting a basketball.”
What questions does the paper try to answer?
The research focuses on three easy-to-grasp questions:
- Can camera movement alone reveal the content of a video?
- Does this work for both first-person videos (from a wearable camera) and third-person videos (someone filming others)?
- Is this camera-movement signal strong enough to help with real tasks, like finding the right caption, recognizing actions, or figuring out when an action happens?
How does the method work?
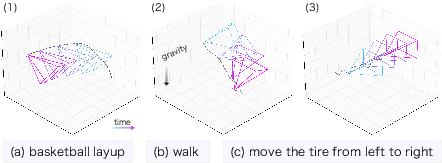
Think of the camera trajectory like drawing a line in the air showing where the camera moved—tilting up, panning left, stepping forward, turning around, and so on. Different activities leave different “motion fingerprints.” For example, filming a basketball layup often tilts upward; walking has a gentle back-and-forth bounce; circling around a sculpture makes a round motion pattern.
CamFormer learns these patterns using a few ideas:
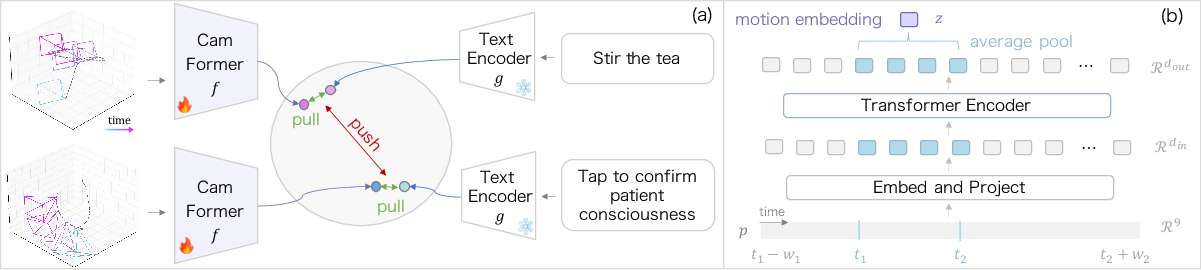
- Contrastive learning: Imagine you have pairs of things that match (a movement pattern and its correct caption) and lots of mismatched pairs. The model is trained to pull matching pairs closer together and push mismatches apart. This helps it learn which movement goes with which description.
- Embedding space: This is like a map where similar things end up near each other. CamFormer places camera movements and text descriptions on the same map so matching pairs sit close.
- Context helps: Instead of looking at only a tiny moment, the model also looks a bit before and after. This extra “context” makes it easier to understand what’s really happening.
- A lightweight encoder: CamFormer is a small transformer (a type of neural network that’s good at processing sequences, like time-series data). It reads the sequence of camera positions and angles over time and produces a compact “movement signature.”
They trained CamFormer using large datasets where videos had:
- The camera’s pose over time (estimated either from special glasses or just from the video itself).
- Text narrations or captions describing what’s in the clip.
What did they find, and why does it matter?
Here are the main findings, explained simply:
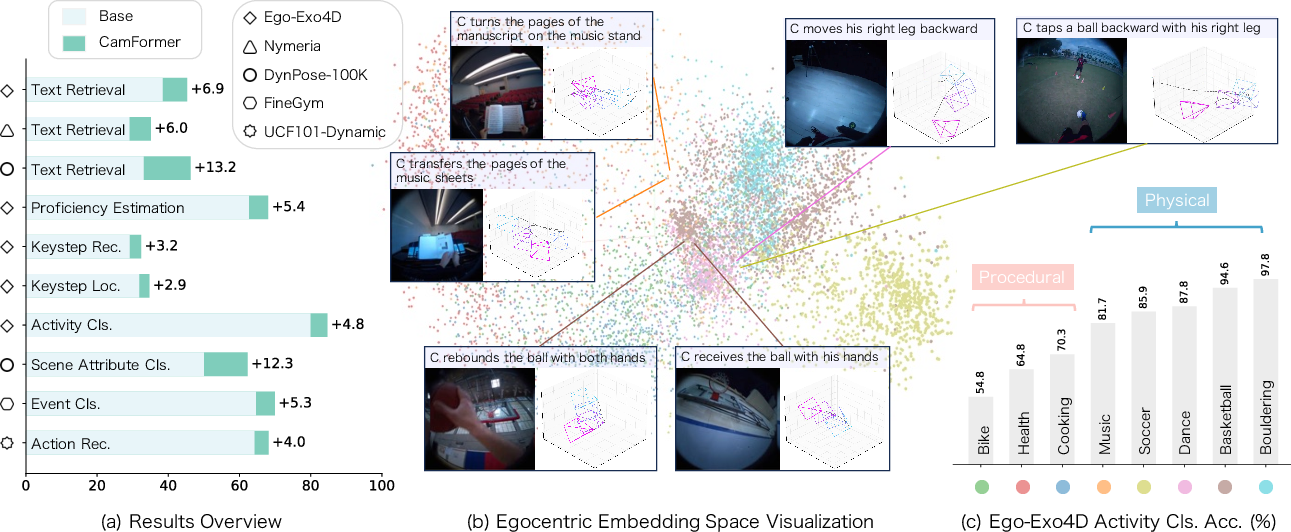
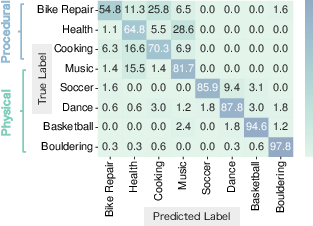
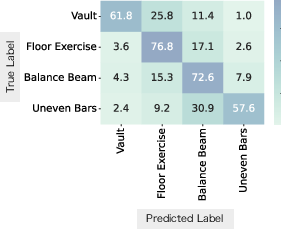
- Camera movement alone is often enough to understand physical actions: For energetic activities like basketball, bouldering, or walking, CamFormer sometimes beats heavy video models (which process pixels) while being much faster and smaller.
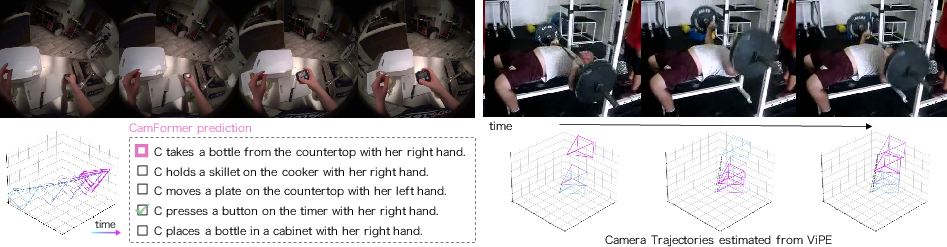
- It helps even when the action isn’t visible: In first-person videos, your hands or feet might be out of view. Movement patterns still let the model guess correctly (for example, a sudden downward motion matches “landing on the mat” in climbing).
- It works for third-person videos too: When someone films an event, how they move reflects what they’re focusing on (like fast pans in soccer or a slow circle around a statue). The model can use this to match captions and recognize scene attributes.
- It pairs well with normal video: For subtle, step-by-step tasks (like cooking or bike repair) where movements are small, combining camera movement with pixels improves results. The two signals complement each other.
- It’s robust across different pose estimators: Whether the camera path comes from fancy sensors or estimated from regular video, CamFormer stays useful. Better pose estimates help, but the model generalizes well.
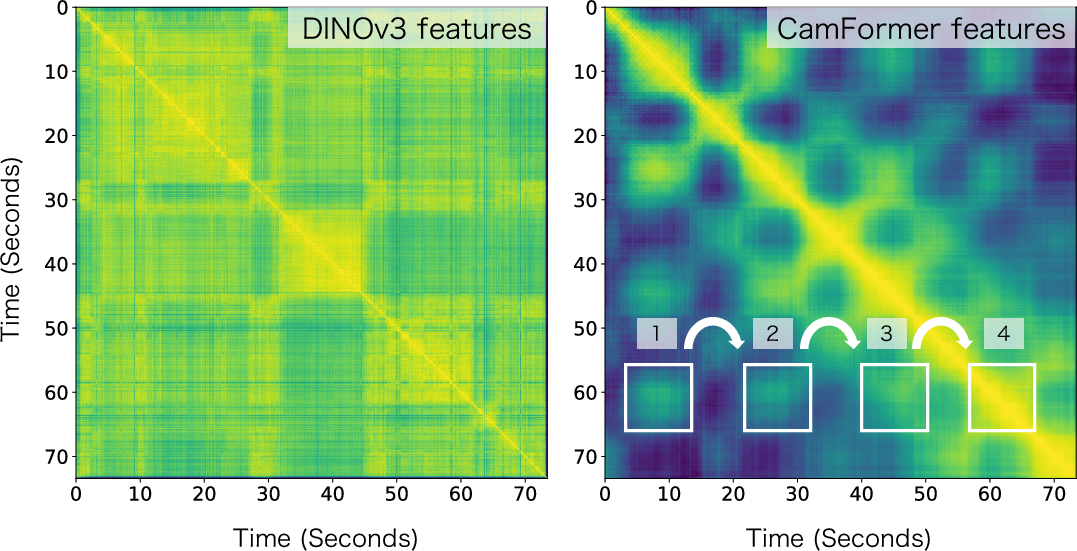
- It can reveal timing and repetition: Because it understands motion over time, CamFormer can help count repeated actions (like slicing onions) and locate when certain steps happen.
These results matter because camera trajectory is:
- Lightweight: It uses much less compute than processing every pixel.
- Privacy-friendly: You can analyze movement without seeing the actual scene.
- Widely available: You can estimate camera motion from regular videos—no special hardware required.
What’s the bigger impact?
This work suggests a new way to understand videos: don’t just look at what’s in the frames—also read how the camera moved. That could help:
- Video search and summarization: Quickly find clips by movement patterns or match them to descriptions.
- Sports and skill analysis: Recognize expertise from smooth, controlled motion vs. shaky, chaotic movement.
- Robotics and AR: Use motion signatures to understand tasks when visuals are messy or partly hidden.
- Privacy-aware applications: Learn from motion without exposing sensitive visual details.
Overall, the paper shows that “how you move” can reveal “what you’re doing” or “what you’re observing,” making camera trajectory a powerful, practical signal for understanding video content—often without seeing a single pixel.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that future work could address to strengthen, generalize, and better understand camera-trajectory-based perception.
- Lack of formal theory: No principled characterization of which trajectory signals (e.g., rotation vs. translation, temporal patterns) encode which semantics; develop controlled, synthetic experiments and an information-theoretic analysis (e.g., mutual information between trajectory features and labels).
- Scale and coordinate-frame ambiguity: The method uses relative translation and 6D rotation w.r.t. the sequence midpoint, but does not quantify sensitivity to absolute scale, gravity alignment, or world-vs-camera frames; compare normalizations (e.g., gravity-aligned frames, unit-scale reparameterization) and their impact on downstream tasks.
- Sensitivity to pose errors: Robustness results aggregate across estimators without a fine-grained error analysis; systematically test the effect of noise, drift, bias, and rotational/translation error components on performance via controlled perturbations.
- Pose estimator semantic benchmark: The proposed “semantic utility” idea is promising but not formalized; define protocols, datasets, metrics, and error taxonomies to benchmark pose estimators on downstream semantic tasks (not just geometric metrics).
- Sampling rate and sequence duration: No ablations on temporal sampling (5–30 Hz) or window lengths beyond qualitative plots; quantify performance vs. sampling frequency, window size, and multi-scale temporal modeling.
- Contextualized encoding constraints: The method uses future context to disambiguate actions; evaluate causal, streaming variants that only use past context, and characterize trade-offs between disambiguation and latency.
- Representation choices: Only 9D pose is used; assess the impact of including velocities/accelerations, angular rates, jerk, camera intrinsics, and zoom/focus dynamics on semantic decoding.
- Stabilization and zoom effects: Real-world videos often have electronic/optical stabilization and zoom changes; quantify how stabilization filters and zoom behavior alter trajectories and downstream performance.
- Domain coverage: Pretraining/evaluation focus on Aria egocentric and DynPose-100K exocentric data; test transfer to cinematic content, sports broadcast, surveillance, vehicle-mounted, drone footage, and smartphone videos with varied filming styles.
- Minimal-motion scenarios: Performance collapses for static attributes (e.g., day/night); define thresholds for “insufficient motion,” and explore hybrid signals (e.g., low-res vision, audio, scene priors) to recover semantics when trajectory signal is weak.
- Procedural activity limitation: Trajectories underperform on procedural tasks; investigate complementary cues (e.g., hand pose, object state, audio) and learned fusion (cross-attention, gating) beyond feature averaging to improve fine-grained semantics.
- Fusion strategy: Fusion with video is done by simple feature averaging; compare learned joint models (e.g., co-attentional transformers, late fusion with calibration) and study when/why trajectory adds non-redundant information.
- Text space dependence: The text encoder is frozen CLIP; evaluate jointly trained or domain-adapted text encoders, multilingual text, and alignment under noisy narrations/captions (e.g., Panda70M) to reduce semantic mismatch.
- Contrastive training details: Negative mining, batch size, and curriculum are not analyzed; test hard-negative mining, memory-bank strategies, and positive/negative sampling schemes to strengthen cross-modal alignment.
- Open-vocabulary retrieval: MCQ (5-way) retrieval is limited; benchmark open-vocabulary, large-corpus retrieval (top-k) and long-form grounding to assess real-world utility beyond multiple choice.
- Quantitative counting: Repetitive action counting is shown qualitatively via self-similarity maps; establish quantitative counting benchmarks, metrics (e.g., MAE, F1), and evaluate across diverse repetitive actions.
- Temporal localization rigor: [email protected] is briefly reported; provide full tIoU curves, per-class error breakdowns (over-/under-segmentation), and sensitivity to boundary noise for localization tasks.
- Cross-domain generalization: Egocentric→Nymeria zero-shot is promising; test exocentric→other exocentric datasets (e.g., Kinetics, HMDB51), and egocentric↔exocentric transfer to assess modality/domain gaps.
- Identity and privacy: Camera trajectories may fingerprint individuals (e.g., head/hand motion styles); evaluate re-identification risk, privacy leakage, and design privacy-preserving transformations (e.g., motion style anonymization).
- Bias and confounding: Motion patterns may correlate with venue, device, or demographics; conduct fairness audits, cross-subject splits, and domain adversarial training to reduce spurious correlations.
- Resource and scaling laws: Inference is lightweight, but training compute, data scaling, and parameter scaling laws are not studied; quantify performance vs. data size, model size, and compute for trajectory-only vs. fused models.
- Streaming/edge deployment: Latency, memory footprint, and on-device feasibility (wearables, phones) are not reported; measure real-time performance and propose causal variants for deployment.
- Multi-actor/attention disentanglement: Exocentric trajectories reflect the filmer’s attention, which may not align with the primary actor(s); explore modeling multiple attention modes, scene graphs, or attention disentanglement.
- Integration with IMU and other sensors: Comparisons to IMU exist (PRIMUS), but fusion of video trajectory with IMU or audio is not studied; quantify gains from multi-sensor trajectory signals and robustness under sensor failure.
- Self-supervised pretraining: Beyond text contrastive learning, test self-supervised objectives on trajectories (e.g., masked modeling, forecasting, invariance/equivariance constraints) to reduce dependence on captions/narrations.
- Causal analysis: Distinguish causal factors (content causing camera motion) from correlations; design interventions (e.g., scripted filming protocols) and causal modeling to avoid spurious semantics.
- Coordinate/frame normalization across estimators: Cross-source alignment (Aria vs. monocular estimators) may differ in scale and axes; formalize normalization pipelines and quantify their impact on downstream tasks.
- Evaluation baselines in exocentric retrieval: Camera description baselines are two-stage LMMs; include direct video-text baselines (e.g., CLIP/InternVideo) for fair comparison on exocentric retrieval tasks.
- Robustness to missing/irregular trajectories: Handle dropped frames, variable sampling, and trajectory gaps; design imputation and irregular-time modeling (e.g., continuous-time transformers).
- Ethical and societal impacts: Assess potential misuse (e.g., surveillance enhancement, behavior profiling) and establish guidelines for responsible use of trajectory-based perception.
Practical Applications
Immediate Applications
The following applications can be deployed today by leveraging CamFormer’s trajectory-to-text embeddings, contextualized trajectory encoding, and demonstrated robustness across pose sources (hardware SLAM and video-only estimators). Each item includes sectors, potential tools/workflows, and key assumptions or dependencies.
- Privacy-preserving video indexing and retrieval for body-worn, mobile, and drone cameras
- Sectors: security/public safety, enterprise IT, media asset management, cloud storage
- Tools/workflows: “TrajectorySearch” pipeline that estimates poses (Aria, MegaSaM/ViPE/π³), computes CamFormer embeddings, and aligns them to text for retrieval; index pose-only metadata to comply with privacy standards
- Assumptions/dependencies: pose estimation quality (especially in challenging environments), motion-rich content for best results, text retrieval performance strongest for physical activities and “out-of-view” scenarios
- Occlusion-/blur-robust tagging in egocentric footage
- Sectors: sports coaching, industrial how-to/maintenance, first-person tutorials
- Tools/workflows: event tags driven by camera motion signatures (e.g., disambiguating “land on mat” vs. “rise to wall” in climbing); integrate as a fallback when vision is noisy or the action is out of frame
- Assumptions/dependencies: reliable pose extraction; gains largest when visual cues are subtle or absent
- Proficiency assessment from camera motion in physical tasks
- Sectors: sports training, skill certification, coaching platforms
- Tools/workflows: “MotionSkill Score” uses CamFormer to classify expert vs. novice (fine-tuned per domain), surface insights in athlete dashboards
- Assumptions/dependencies: domain calibration and validation to avoid bias; performance strongest for dynamic, physical activities
- Repetitive action counting from temporal self-similarity in motion embeddings
- Sectors: physiotherapy, fitness apps, industrial assembly/QA
- Tools/workflows: “RepCounter” uses CamFormer’s token-level temporal maps to detect repetitions (e.g., exercise reps, cutting strokes), runs on wearables or edge devices
- Assumptions/dependencies: consistent worn-camera placement and regular motion cadence; counting reliability may degrade for irregular or subtle motions
- Fusion-based improvements in video understanding pipelines
- Sectors: video analytics vendors, MLOps for vision
- Tools/workflows: add a fusion stage (feature averaging or learned fusion) between CamFormer embeddings and video models (e.g., EgoVLPv2) to boost fine-grained procedural recognition and temporal localization
- Assumptions/dependencies: integration effort, optimal temporal context window tuning, benefits are task-dependent (strongest for procedural tasks when vision is good)
- Shot classification and scene attribute tagging from exocentric motion
- Sectors: media production analytics, broadcast ops, cinematography tooling
- Tools/workflows: “MotionTagger” classifies shot patterns (e.g., circling overview, slow pan) and motion-driven scene attributes (e.g., presence of walking people)
- Assumptions/dependencies: limited utility for static attributes (e.g., day/night); requires reliable pose per shot
- Semantic benchmarking of camera pose estimators
- Sectors: 3D vision tooling, SLAM vendors, research QA
- Tools/workflows: “Trajectory-SEM Bench” evaluates pose methods by downstream semantic performance (classification, retrieval), complementing geometric metrics
- Assumptions/dependencies: standardized datasets and tasks; agreement on metrics across academic/industry stakeholders
- Lightweight edge analytics for constrained devices
- Sectors: IoT, wearables, mobile robotics
- Tools/workflows: embed CamFormer (0.3M params, ~0.02G MACs) to run motion-based tagging and retrieval locally; stream only minimal metadata
- Assumptions/dependencies: on-device pose estimation (IMU+video or video-only estimators) and power budget; motion-rich tasks favored
- Privacy and compliance-ready analytics pipelines
- Sectors: public safety, regulated industries
- Tools/workflows: “Pose-only analytics” stores trajectories and embeddings instead of pixels; offers privacy-preserving summaries and retrieval
- Assumptions/dependencies: legal/regulatory acceptance of trajectory metadata; risk assessment for potential re-identification via motion patterns
- Metadata enrichment and auto-captioning from motion-text alignment
- Sectors: content platforms, DAM/archival systems
- Tools/workflows: “AutoCamCaption” generates/aligns high-level descriptions from motion; improves searchability and summarization
- Assumptions/dependencies: caption templates and domain-specific language tuning; text alignment benefits strongest for motion-salient scenes
- Drone mission summarization and monitoring via motion semantics
- Sectors: infrastructure inspection, SAR (search and rescue), cinematography
- Tools/workflows: “FlightMotion Summaries” labels mission phases (e.g., circling overview, approach, pass-by), flags unusual operator motion
- Assumptions/dependencies: stable pose estimation under wind/vibration; careful interpretation of operator intent vs. environmental constraints
Long-Term Applications
These applications require further research, scaling, or development (e.g., broader pretraining data, improved monocular pose estimation, task-specific validation, and integration with other modalities or products).
- Trajectory modality as a first-class citizen in multimodal foundation models
- Sectors: AI research, platform ML
- Tools/workflows: integrate CamFormer-like encoders into general-purpose multimodal LLMs for motion-aware reasoning and retrieval
- Assumptions/dependencies: large-scale cross-domain trajectory–text pairs; robust generalization across egocentric/exocentric, indoor/outdoor
- Privacy-first policy frameworks for “pose-only” analytics
- Sectors: policy/regulation, compliance, civil liberties
- Tools/workflows: standards defining acceptable use of trajectory metadata (retention, consent, auditing), independent evaluation of re-identification risks
- Assumptions/dependencies: stakeholder buy-in; empirical studies on privacy guarantees vs. utility
- Real-time AR assistants that infer intent from head/camera motion
- Sectors: consumer AR, education/training, enterprise fieldwork
- Tools/workflows: on-device motion understanding to trigger contextual help (e.g., procedure steps, safety prompts) without full video analysis
- Assumptions/dependencies: low-latency pose estimation, ergonomic wearables, task-specific validation for procedural contexts
- Robot learning from human camera motion (implicit demonstrations)
- Sectors: robotics, teleoperation, human–robot interaction
- Tools/workflows: use camera trajectories from human demonstrations to inform robot policies (attention cues, task phase segmentation)
- Assumptions/dependencies: mapping motion semantics to robot states/actions; combining trajectory with other signals (e.g., hand/eye tracking, object state)
- Camera-trajectory conditioning for video generation and editing
- Sectors: media production, virtual cinematography
- Tools/workflows: “camera control” in generative video—condition shot style by motion embeddings; post-edit continuity checks via trajectory alignment
- Assumptions/dependencies: integration with video generative models; datasets pairing trajectories with desired cinematic outcomes
- Smart classrooms and retail analytics via motion-aware summaries
- Sectors: education, retail operations
- Tools/workflows: infer engagement or navigation patterns from teacher/shopper camera motion; optimize layout or pedagogy
- Assumptions/dependencies: rigorous ethics and privacy safeguards; domain generalization across settings and populations
- Clinical applications: vestibular/gait assessment from head-mounted motion
- Sectors: healthcare, digital diagnostics
- Tools/workflows: quantify motion patterns indicative of vestibular dysfunction or gait anomalies from egocentric trajectories
- Assumptions/dependencies: clinical trials and regulatory approval; standardized protocols and sensors
- Driver attention and situational awareness from dashcam motion
- Sectors: automotive, fleet safety
- Tools/workflows: infer attention shifts or hazard responses from camera movement (or rig motion) in vehicles; incident analysis
- Assumptions/dependencies: consistent mounting; disentangling vehicle dynamics from camera operator intent
- Multi-agent coordination via trajectory embeddings
- Sectors: robotics (swarm UAVs), defense, environmental monitoring
- Tools/workflows: shared motion embeddings to understand and coordinate group behavior (coverage, pursuit/evasion patterns)
- Assumptions/dependencies: reliable inter-agent localization; robust embeddings in diverse outdoor conditions
- Large-scale video curation and compression through motion metadata
- Sectors: cloud storage, content platforms
- Tools/workflows: store trajectories and motion embeddings to enable search/summarization while minimizing raw video retention
- Assumptions/dependencies: acceptance of motion-only archives; measurable retrieval quality vs. full-video baselines
- Motion-first search UX (“describe with movement” queries)
- Sectors: search providers, creative tooling
- Tools/workflows: enable queries like “find circling overview shots,” “find fast reactive pans” across large catalogs
- Assumptions/dependencies: standardized motion vocabularies; user education and intent mapping
Cross-cutting assumptions and dependencies
- Pose estimation quality and sampling rate are critical; hardware SLAM (e.g., Aria) currently outperforms video-only estimators, though CamFormer generalizes across sources.
- Motion semantics are strongest for dynamic physical activities; procedural and static contexts benefit from fusion with visual cues and well-tuned temporal context windows.
- Domain transfer requires diverse trajectory–text pretraining; task-specific fine-tuning can further improve reliability.
- Ethical, legal, and bias considerations must be addressed, especially in public safety, healthcare, and education deployments.
Glossary
- 6D continuous rotation representation: A continuous parameterization of 3D rotation using six values to avoid discontinuities and ambiguities in rotation representations. "Each pose is represented as a 9D relative vector (3D translation and 6D continuous rotation representation~\cite{zhou2019continuity}), computed with respect to the sequence midpoint."
- attention heads: Parallel attention mechanisms in a multi-head attention module that allow the model to focus on different representation subspaces. "The transformer encoder consists of 4 layers, each with 4 attention heads, a 256-dimensional feed-forward network, and a dropout rate of 0.1."
- CamFormer: A dedicated transformer-based encoder that maps camera pose trajectories into a semantic embedding space aligned with text. "we propose a contrastive learning framework to train CamFormer, a dedicated encoder that projects camera pose trajectories into a joint embedding space, aligning them with natural language."
- camera pose estimation: The process of determining a camera’s position and orientation in space from sensor data or images. "Camera pose estimation is a fundamental task of 3D vision."
- camera pose trajectory: A time-ordered sequence of estimated camera poses (translations and rotations) across a video segment. "This work addresses the untapped problem of how to unlock the semantic information within camera pose trajectories."
- camera trajectory: The path a camera follows through space over time, often represented as a sequence of poses. "the camera trajectory is a remarkably informative signal to uncover video content."
- conditional prior: A conditioning signal supplied to a generative model to guide its outputs based on context. "or serving as a conditional prior to guide video generation~\cite{he2024cameractrl,li2024can,li2025egom2p,geng2025motion}."
- contrastive learning: A representation learning approach that pulls aligned pairs (e.g., trajectory-text) together and pushes mismatched pairs apart in an embedding space. "The dominant paradigm learns high-level semantics by training visual encoders on massive-scale video-text data via contrastive learning~\cite{wang2022internvideo,wang2024internvideo2,lin2022egocentric,pramanick2023egovlpv2,zhao2023learning,ashutosh2023hiervl}."
- contextualized trajectory encoding: An encoding strategy that augments a target window of trajectory with surrounding temporal context to disambiguate actions. "We address this challenge with a contextualized trajectory encoding, which extends the sequence length beyond the immediate temporal window to capture broader temporal context, thereby disambiguating the central action."
- cross-modal alignment: Learning to align representations across different data modalities (e.g., trajectories and text) so related items are nearby in a shared space. "ranging from cross-modal alignment to classification and temporal analysis."
- egocentric: First-person camera perspective captured from the recorder’s viewpoint (e.g., head-mounted). "We first analyze the egocentric (first-person) setting, where a wearable camera's trajectory offers a direct correlation with the recorder's action."
- egocentric motion: Motion signals derived from a first-person wearable camera that reflect the camera-wearer’s movements. "Beyond action recognition, egocentric motion has also been shown to correlate with other semantic properties, such as physical forces~\cite{park2016force} and camera-wearer identity~\cite{yonetani2017ego}."
- embedding space: A learned vector space where semantically related inputs (e.g., trajectories and texts) are mapped to nearby points. "a dedicated encoder that projects camera pose trajectories into a joint embedding space, aligning them with natural language."
- exocentric: Third-person camera perspective captured by an observer not attached to the actor. "We then analyze exocentric (third-person) videos, where the trajectory is decoupled from the actor, and reflects the recorder's attention as an observer."
- feed-forward network: The position-wise multilayer perceptron within transformer blocks that processes token representations. "The transformer encoder consists of 4 layers, each with 4 attention heads, a 256-dimensional feed-forward network, and a dropout rate of 0.1."
- fine-tuning: Further training of a pre-trained model on a downstream task, often with task-specific labels. "via end-to-end fine-tuning, where CamFormer is trained jointly with a linear head."
- IMU: Inertial Measurement Unit; a sensor device that measures acceleration and rotational rates. "The same principle has been applied to a broader set of modalities, seeking to connect audio~\cite{guzhov2022audioclip}, IMU~\cite{moon2023imu2clip,das2025primus,moon2024anymal}, thermal, depth images~\cite{girdhar2023imagebind} and touch~\cite{yang2024binding} to a shared semantic space."
- keystep recognition: Identifying fine-grained action steps within a broader activity. "keystep recognition on the 278 fine-grained keystep labels, which are specific to the 3 procedural activities (bike repair, health, cooking);"
- large multimodal models (LMMs): High-capacity models that process and integrate multiple modalities (e.g., video, text) for tasks like captioning or description. "Recent work~\cite{fang2025camerabench,liu2025shotbench,wang2025cinetechbench} trains large multimodal models (LMMs) to generate textual descriptions of camera cinematography from video input (\eg,
zoom,pan'')." - linear probing: Evaluating representations by training a simple linear classifier on top of frozen features. "as a frozen feature extractor (\eg, linear probing);"
- mean-pooling: Aggregating a sequence of feature vectors by averaging them to obtain a single representation. "the final embedding is produced by mean-pooling only the output features corresponding to the original window ."
- [email protected]: Mean Intersection-over-Union measured at an IoU threshold of 0.3, commonly used for evaluating detection/localization. "yields a +3.2\% accuracy gain in recognition and a +2.9 [email protected] gain in localization."
- monocular videos: Videos captured with a single camera (as opposed to stereo or multi-camera setups). "learning-based models~\cite{li2025megasam,huang2025vipe,wang2025pi,wang2025vggt,xiao2025spatialtrackerv2,kuang2024collaborative} that infer pose from monocular videos."
- multiple-choice question (MCQ): A task format where a model selects the correct answer from several alternatives. "we adapt the 5-way multiple-choice question (MCQ) format from~\cite{lin2022egocentric}, where the model must select the correct textual description from five candidates."
- novel view synthesis: Generating new images of a scene from unseen viewpoints, given structure and/or pose information. "On the application side, camera pose has powered tasks such as novel view synthesis~\cite{li2025cameras}, 3D reconstruction and mapping~\cite{keetha2025mapanything}, or serving as a conditional prior to guide video generation~\cite{he2024cameractrl,li2024can,li2025egom2p,geng2025motion}."
- optical flow: A per-pixel motion field describing apparent motion between consecutive frames. "A few works~\cite{ryoo2015pooled,singh2017trajectory,abebe2016robust,narayan2014action} have shown that egocentric motion representations, such as optical flow~\cite{kitani2011fast,kitani2012ego,wang2013action,li2015delving,singh2015generic}, can aid action recognition."
- PCA: Principal Component Analysis; a dimensionality reduction technique used for visualization or compression. "A PCA visualization of CamFormer embeddings on unseen Ego-Exo4D trajectories, colored by the dataset's 8 activity labels."
- pre-training: Initial large-scale training phase used to learn general representations before downstream fine-tuning. "we propose to pre-train a dedicated trajectory encoder, which we term {\em CamFormer}, to project camera trajectories into a joint embedding space with text"
- relative vector: A vector representing pose relative to a chosen reference (e.g., sequence midpoint) rather than in absolute coordinates. "Each pose is represented as a 9D relative vector (3D translation and 6D continuous rotation representation~\cite{zhou2019continuity}), computed with respect to the sequence midpoint."
- self-similarity map: A matrix showing pairwise similarity between temporal feature vectors, useful for detecting periodicity. "we compute the self-similarity map of CamFormer's temporal features (\ie, the output token sequence before the final average pooling)."
- SLAM: Simultaneous Localization and Mapping; algorithms that estimate a device’s trajectory while building a map of the environment. "we adopt the large-scale Ego-Exo4D~\cite{grauman2024ego}, which provides time-stamped narrations and high-quality dense camera trajectories from Meta Aria glasses~\cite{engel2023project} (specifically, visual-inertial pose estimates from the device's SLAM cameras)."
- temporal action localization: Detecting and localizing the start and end times of actions within a video. "We examine tasks that require precise temporal information, including temporal action localization and the recognition of periodic patterns for repetitive action counting."
- temperature hyperparameter: A scaling factor in softmax-based contrastive objectives that controls distribution sharpness. "where is the symmetric text-to-trajectory loss, and is the temperature hyperparameter."
- Transformer: A neural network architecture based on self-attention mechanisms, effective for sequence modeling. "Our camera trajectory encoder (CamFormer), is a light-weight Transformer~\cite{vaswani2017attention}."
- visual encoders: Neural networks that process images or video to produce vector representations. "The dominant paradigm learns high-level semantics by training visual encoders on massive-scale video-text data via contrastive learning~\cite{wang2022internvideo,wang2024internvideo2,lin2022egocentric,pramanick2023egovlpv2,zhao2023learning,ashutosh2023hiervl}."
- visual-inertial: Combining visual and inertial sensor data for robust pose estimation. "visual-inertial pose estimates from the device's SLAM cameras"
- zero-shot: Applying a model to a new task or dataset without any task-specific training on that dataset. "we test this model by directly applying it on Nymeria~\cite{ma2024nymeria} dataset in a zero-shot manner."
Collections
Sign up for free to add this paper to one or more collections.