- The paper demonstrates that traditional add/remove adjacency in differential privacy fails to adequately protect sensitive attributes in ML models.
- It introduces substitute adjacency, which allows record substitution to better capture empirical privacy leakage against attribute inference attacks.
- Novel auditing techniques using gradient-space and input-space canaries empirically reveal privacy vulnerabilities that surpass add/remove DP guarantees.
Beyond Membership: Limitations of Add/Remove Adjacency in Differential Privacy
Introduction
The research paper "Beyond Membership: Limitations of Add/Remove Adjacency in Differential Privacy" (2511.21804) challenges the adequacy of traditional differential privacy (DP) methods that utilize add/remove adjacency for protecting sensitive information in ML models. The standard approach to implementing DP in ML primarily focuses on safeguarding against membership inference attacks using add/remove adjacency. This method considers two datasets adjacent if one can be derived from the other by adding or removing a single record. However, the paper brings to light the limitations of this approach in ensuring attribute privacy, which is often more relevant in contexts where protecting sensitive attributes or labels is crucial.
Empirical Evaluation of Substitute Adjacency
The paper introduces the concept of substitute adjacency, which permits the substitution of one record in the dataset to form its neighbor rather than mere addition or removal. This concept is critical for protecting attribute-level privacy but is often overlooked in conventional DP practices. The authors empirically demonstrate that privacy guarantees reported under add/remove adjacency significantly overestimate the protection provided against attribute inference attacks when substitute adjacency is more appropriate.
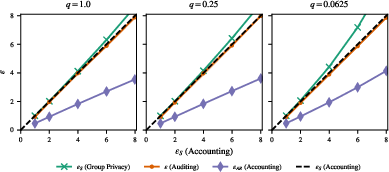
Figure 1: Auditing DP using worst-case dataset canaries based on substitute adjacency surpasses the privacy upper bound for add/remove DP.
By deploying novel auditing techniques, the authors evaluate DP under substitute adjacency, indicating that empirical privacy leakage often exceeds the theoretical bounds of add/remove DP, yet aligns with the limits set by substitute DP.
Auditing Techniques and Results
The paper advances algorithms for crafting "canaries" — synthetic records used to probe the privacy leakage in DP models. These canaries help audit DP models to expose privacy vulnerabilities that traditional add/remove approaches might miss.
- Gradient-Space Canaries: Crafted canaries demonstrated superior effectiveness in the audit of models trained on natural datasets. The empirical leakage often contravened add/remove DP guarantees (Figure 2).
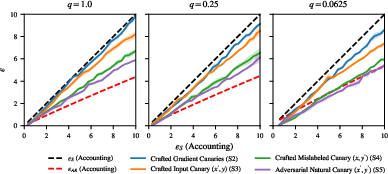
Figure 2: Auditing models trained with DP using natural datasets reveals privacy leakage surpassing add/remove DP upper bounds.
- Input-Space Canaries: Although less effective than gradient-space canaries, input-space canaries still exposed significant privacy risks. They underscored the importance of substituting sample data over merely employing add/remove strategies.
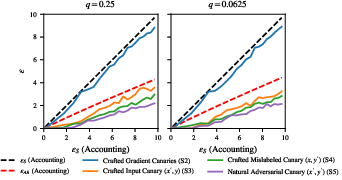
Figure 3: Auditing MLP model trained from scratch using input-space canaries results in weaker audits compared to theoretical add/remove DP bounds.
Theoretical and Practical Implications
The research unveils a crucial gap between theoretical privacy guarantees and practical vulnerabilities, especially when attribute or label privacy is of concern. This has substantial implications for practitioners using DP in ML, especially those relying on libraries and tools that default to add/remove adjacency without considering the appropriate context.
Future Directions
The findings point toward a need for the community to adopt privacy accounting frameworks that consider substitute adjacency when the focus shifts from proving mere membership privacy to ensuring attribute confidentiality. Future research could focus on developing more robust canary creation techniques sensitive to real-world training hyperparameters and offering tighter audits that generalize well across different models.
Conclusion
The paper presents a compelling case for revisiting and potentially revising the standard practices in differential privacy as applied to machine learning. By highlighting the shortcomings of add/remove adjacency in specific contexts, it encourages a paradigm shift toward more nuanced methods that adhere better to the privacy needs dictated by the data and the intended protections.
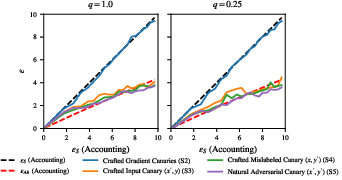
Figure 4: Auditing Models Trained For Text Classification shows privacy leakage that aligns with substitute DP guarantees rather than add/remove DP.
This research underscores the importance of selecting appropriate privacy models aligned with both the nature of the data and the specific threat models applicable to practical applications.