- The paper presents a novel graph-based framework (Match-and-Fuse) that achieves consistency in generated image sets by fusing pairwise image correspondences.
- It leverages Multiview Feature Fusion combined with feature guidance to refine fine-grained structural details without manual masks.
- Experimental results demonstrate state-of-the-art consistency using the DINO-MatchSim metric and robust scalability across diverse image collections.
Match-and-Fuse: Consistent Generation from Unstructured Image Sets
Introduction
The paper "Match-and-Fuse: Consistent Generation from Unstructured Image Sets" (2511.22287) addresses the problem of generating consistent, controlled sets of images from unstructured collections. Rather than handling single images or densely sampled videos, this approach focuses on collections of images sharing common content but demonstrating variation in context, viewpoint, and background—such as product albums, storyboards, or object-centric datasets. Achieving semantic and appearance consistency across such sets is challenging due to non-temporal structure, deformable content, and ambiguity in correspondences.
Methodology
Given an input set of N images featuring shared visual elements (e.g., an object or subject appearing across views) and user-provided prompts Pshared and Ptheme (specifying target content and overall style), the goal is to synthesize a new set preserving the source layout and ensuring cross-image consistency for shared regions.
Pairwise Consistency Graph and Grid Prior
The method leverages the emergent "grid prior" in text-to-image diffusion models, where joint generation of image grids partially enforces consistency but suffers from scalability and fidelity issues when extended to larger sets. To overcome this, Match-and-Fuse models the collection as a Pairwise Consistency Graph: nodes represent the N images, and each edge corresponds to jointly generating a two-image grid. All pairwise grids are processed in coordination, fusing information and enforcing alignment through dense correspondences.

Figure 1: Comparison between naive image grid generation and the proposed Match-and-Fuse method. While grid priors enforce partial consistency, Match-and-Fuse scales consistency across larger sets and arbitrary layouts.
Multiview Feature Fusion and Guidance
A core component is Multiview Feature Fusion (MFF), which operates in the feature space of a frozen, depth-conditioned diffusion model. For each pair, dense 2D visual correspondences from the source set identify shared regions. Features at matched locations are averaged across pairs, promoting consistency in fine-grained details. This is formalized in the pairwise and N-node graph setting, ensuring global consistency via iterative aggregation.
Additionally, a lightweight Feature Guidance step defines an explicit loss over feature matches (using L2 distance), updating latent variables with gradient information to further refine alignment of small structures. Notably, these operations are training-free and do not require manual mask annotation.
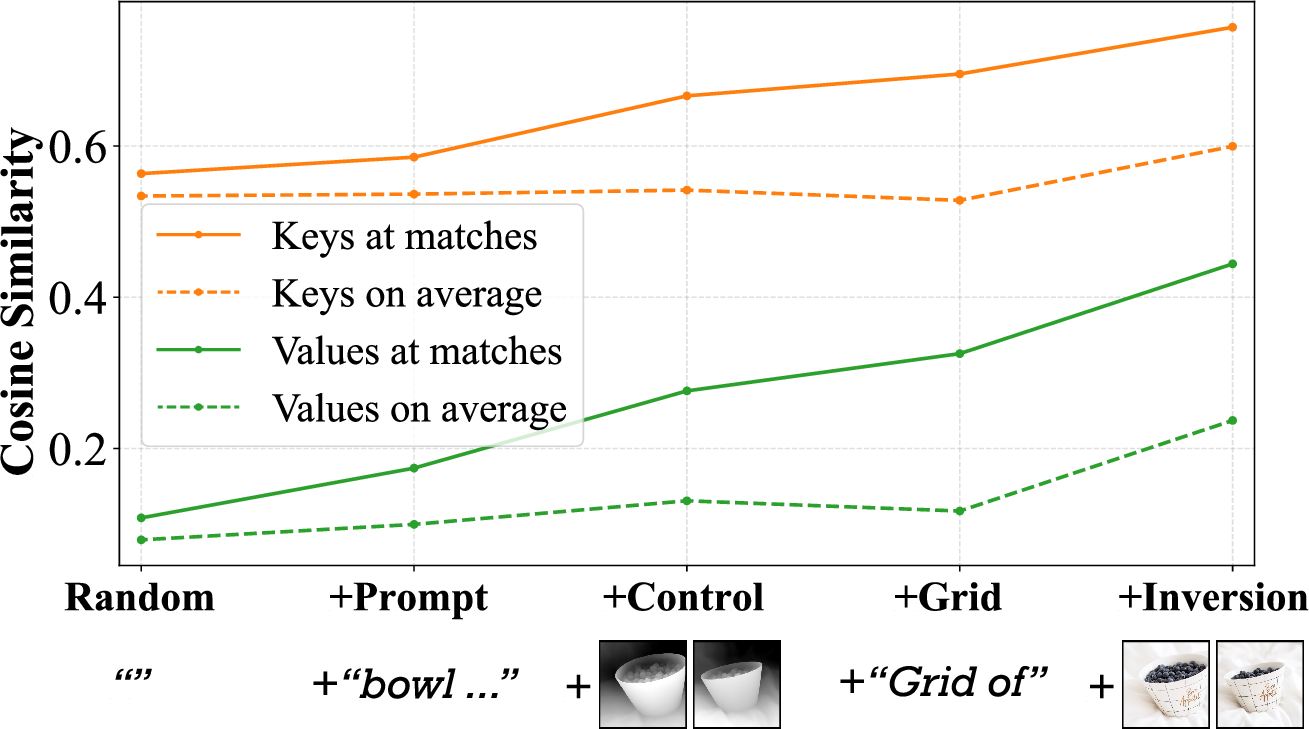
Figure 3: Cosine similarity of matched internal features correlates strongly with visual consistency across increasing levels of control and joint generation.
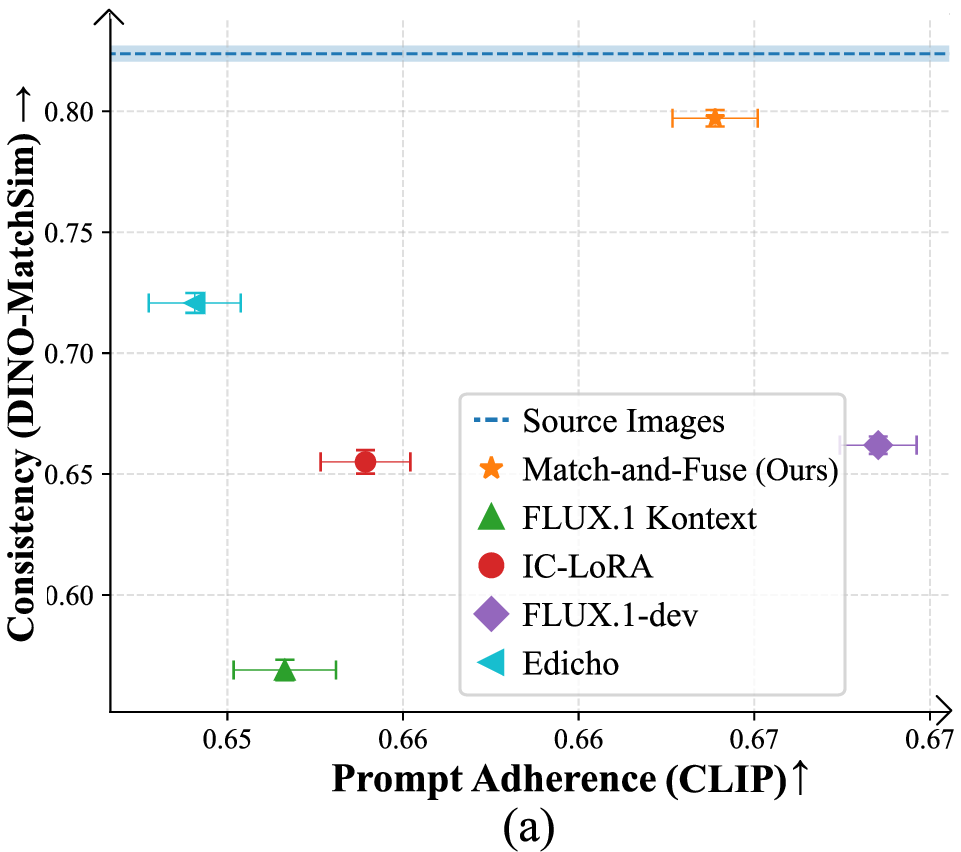
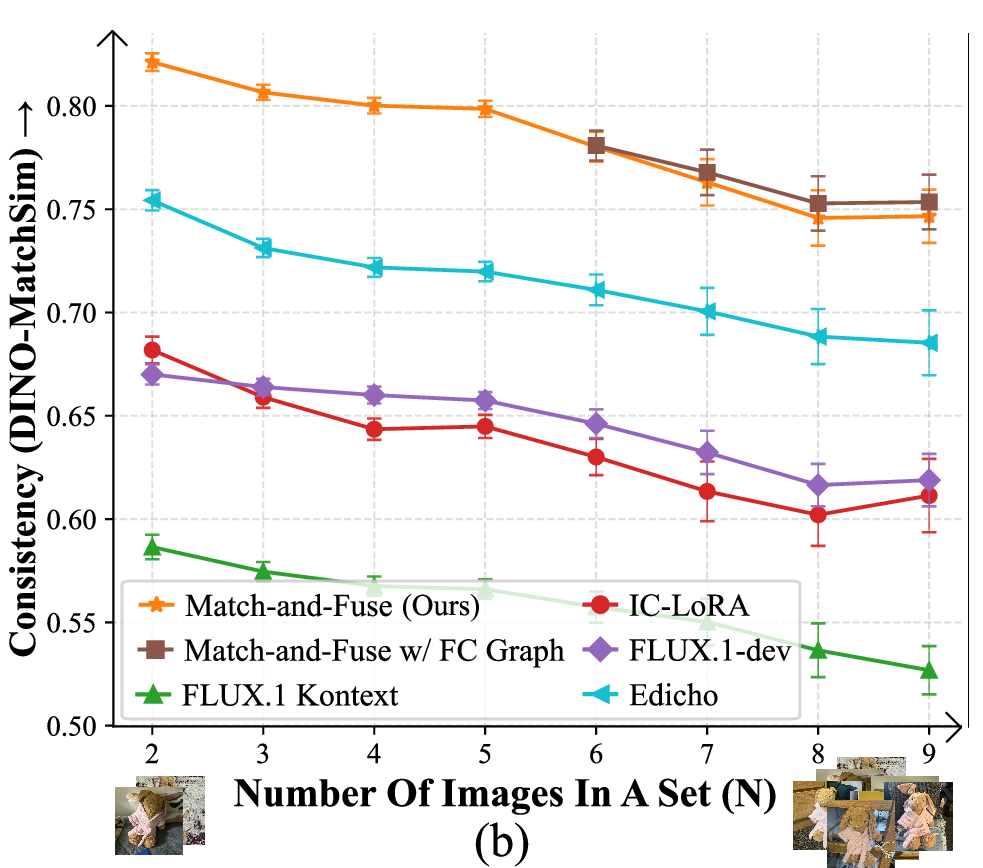
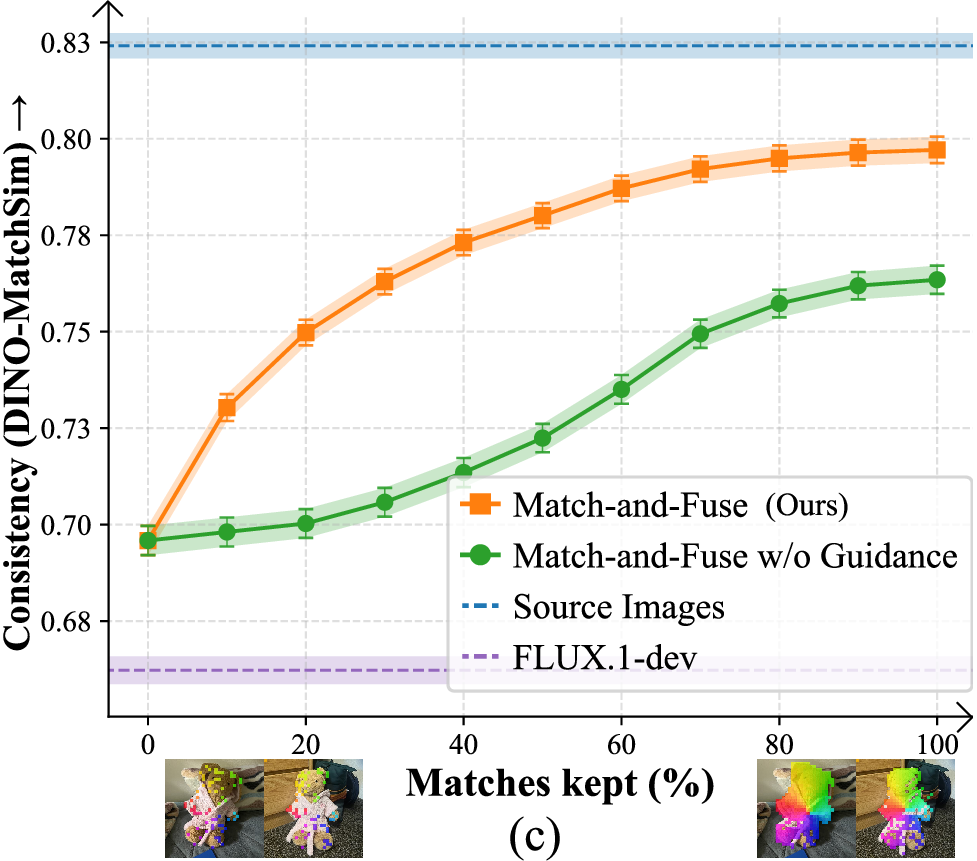
Figure 5: Quantitative performance as a function of prompt adherence, image set size, and match sparsity. Match-and-Fuse achieves state-of-the-art consistency (DINO-MatchSim metric) and robust scalability.
Prompt Composition
Automated, per-image prompts Pinon−shared are constructed via VLMs, combining user guidance with pose, appearance, and thematic details extracted directly from the input set. This enables structured, flexible manipulation without extensive manual engineering.

Figure 2: Example VLM-generated captions expanding on both shared and image-specific semantics for set-level prompting.
Experimental Evaluation
Benchmark and Metrics
A curated benchmark of 149 diverse sets (400 edits, 3–15 images per set) incorporates real photographs, object-centric image collections, video frames, and hand-drawn storyboard sketches. A novel metric—DINO-MatchSim—is introduced for fine-grained, correspondence-aware evaluation of object consistency across set members, complementing CLIP and DreamSim scores for prompt adherence and holistic similarity.
Results and Analysis
Qualitative and quantitative experiments show that Match-and-Fuse consistently outperforms baselines including FLUX, FLUX Kontext, IC-LoRA, and Edicho [flux2024, labs2025flux1kontextflowmatching, lhhuang2024iclora, bai2024edicho]. The method preserves detailed structural, appearance, and textural consistency even under non-rigid deformations, diverse backgrounds, and large set sizes (N>10). Fine-grained ablation shows contributions from each component—graph-level pairing, feature fusion, and feature guidance—are all essential.

Figure 4: Qualitative results demonstrate preservation of shared semantic content and fine-grained detail across rigid/non-rigid subjects and variant backgrounds.
Figure 9: Comparative outputs highlight superior structural and semantic consistency relative to established baselines.
User studies and VLM-based evaluation support the strength of cross-image consistency and perceptual adherence, with Match-and-Fuse preferred in the majority of comparisons.
An analysis of runtime and memory requirements confirms scalability is maintained through graph sparsification (random neighbor selection), resulting in effectively linear time and space costs per image.

Figure 7: Consistency trends as set size increases; fine-scale consistency becomes challenging with larger N, reflecting fundamental limits of feature fusion and alignment.
Extended Applications and Limitations
The architecture generalizes to varied modalities, such as consistent storyboard (sketch) generation and localized semantic editing when paired with techniques like FlowEdit. Key limitations include reliance on dense, reliable 2D matches (performance degrades in unmatched or ambiguous regions), and dependence on the underlying diffusion model's capacity to respect layout constraints.

Figure 8: Extended applications including consistent story generation from sketches and composable localized editing.

Figure 11: Limitations arise in regions with sparse correspondences or ambiguous structure, such as disocclusions and symmetries.
Implications and Future Directions
Match-and-Fuse enables practical workflows for content creation, multi-view design, consistent editing of product catalogs, and creative set manipulation, without fine-tuning or labeled data. Theoretically, it establishes a bridge between image collection analysis and diffusion-based set-to-set synthesis by leveraging graph-based feature fusion and automated correspondence. Extending the methodology to support higher-level reasoning (e.g., 3D structure, more abstract semantic hierarchies), larger set sizes, or cross-modal set generation (video, text, 3D) presents an avenue for future research. Integration with foundation models and improved matching under low-overlap scenarios are likely directions for further improvement.
Conclusion
Match-and-Fuse (2511.22287) provides a robust, training-free pipeline for consistent generation across unstructured image sets, overcoming limitations of prior pairwise or scene-constrained approaches. Its Pairwise Consistency Graph and Multiview Feature Fusion techniques elevate both visual and semantic consistency, demonstrating strong empirical results and enabling new possibilities for set-aware image synthesis and editing.