AnyTalker: Scaling Multi-Person Talking Video Generation with Interactivity Refinement
Abstract: Recently, multi-person video generation has started to gain prominence. While a few preliminary works have explored audio-driven multi-person talking video generation, they often face challenges due to the high costs of diverse multi-person data collection and the difficulty of driving multiple identities with coherent interactivity. To address these challenges, we propose AnyTalker, a multi-person generation framework that features an extensible multi-stream processing architecture. Specifically, we extend Diffusion Transformer's attention block with a novel identity-aware attention mechanism that iteratively processes identity-audio pairs, allowing arbitrary scaling of drivable identities. Besides, training multi-person generative models demands massive multi-person data. Our proposed training pipeline depends solely on single-person videos to learn multi-person speaking patterns and refines interactivity with only a few real multi-person clips. Furthermore, we contribute a targeted metric and dataset designed to evaluate the naturalness and interactivity of the generated multi-person videos. Extensive experiments demonstrate that AnyTalker achieves remarkable lip synchronization, visual quality, and natural interactivity, striking a favorable balance between data costs and identity scalability.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces AnyTalker, a computer system that can make realistic videos of several people talking to each other—at the same time—based on audio. The videos look natural: lips match the speech, faces and bodies move, and the people react to each other with eye contact and gestures. A big goal is to do this without needing huge amounts of specially recorded multi-person training data.
What questions did the researchers ask?
The paper focuses on three main questions:
- How can we generate talking videos with many different people at once, not just one, and let them interact naturally?
- Can we train such a system mostly using cheaper, easier-to-find single-person videos instead of massive multi-person recordings?
- How do we measure “interactivity” in multi-person videos (like eye contact and head movements), so we can objectively tell if the results feel natural?
How did they do it?
The team designed a new method that combines smart architecture and a careful training process. Here’s the approach in simple terms:
Building on existing video models
They start from a powerful video generator (a “diffusion transformer”). Think of this model like a skilled filmmaker that can turn instructions (like text and audio) into a high-quality video. It already knows how to make realistic motion and visuals.
- “Diffusion” models create images or video by starting from random noise and gradually “cleaning” it up.
- A “transformer” helps the model pay attention to the right bits of information—like listening closely to the audio when drawing lip movements.
Audio‑Face Cross Attention (AFCA): matching voices to faces
Their key idea is a new attention mechanism called AFCA. Think of attention like spotlights on a stage:
- Each person’s voice is one spotlight.
- Each person’s face is another spotlight. AFCA links a voice spotlight to the correct face spotlight, so the model knows which part of the video should react to which audio.
How it works in everyday terms:
- The model takes in pairs: one person’s audio and that person’s face.
- It processes all the pairs in a loop, one after another, and adds up the results.
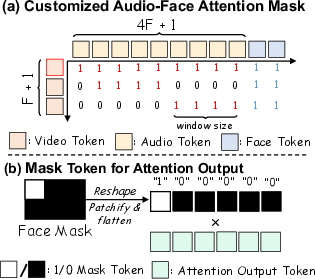
- A “face mask” acts like painters’ tape, making sure changes (like mouth movement) happen only inside the right person’s face area.
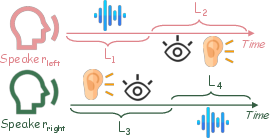
- A “temporal mask” is a timing rulebook that helps the model align the right chunks of audio with the right video frames, so lip movements match the speech rhythm.
Because AFCA handles pairs one-by-one and shares the same logic for each pair, it can scale to any number of people—2, 3, 4, or more—without redesigning the system.
Two‑stage training: learning from single‑person videos, then refining interactivity
Recording multi-person conversations is costly. So they split training into two stages:
- Stage 1: Learn from single-person videos
- They “fake” multi-person scenes by horizontally sticking two single-person videos side-by-side, and pairing each half with the right audio.
- This teaches the model basic multi-person speaking patterns (like lip-sync and localizing movements to the right person) using mostly single-person data.
- Stage 2: Refine with a small amount of real multi-person data
- With about 12 hours of carefully filtered two-person clips, they fine-tune the system to improve natural reactions: eye gaze, head turns, listening behavior, and turn-taking.
- Even though training uses mostly two-person scenes, the AFCA design generalizes to more than two people.
Measuring interactivity: a new dataset and metric
To test “interactivity,” they built:
- InteractiveEyes: a set of two-person conversation clips with clear speaking and listening segments.
- An interactivity metric focused on eye-region motion during listening periods.
- Why eyes? In conversations, listeners naturally move their eyes and eyebrows, look at the speaker, and show subtle reactions.
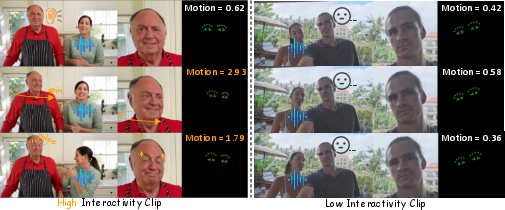
- The metric calculates how much the eye keypoints move frame-to-frame, especially while the person is listening. More natural, responsive motion means higher interactivity.
What did they find?
The researchers report strong results across several aspects. In short:
- Better interactivity: Compared to other multi-person methods, AnyTalker’s characters show more natural listening behaviors, eye movements, and head turns.
- Accurate lip-sync: Lips match the audio well, even when multiple people speak at different times.
- Scales to many identities: Thanks to AFCA, it can handle an arbitrary number of people and even non-human characters, without hard-coding labels.
- High visual quality: The videos look clean and lifelike, not glitchy or blurry.
- Lower data cost: It learns most multi-person behavior from single-person videos and needs only a small amount of real multi-person data (around 12 hours) to refine interactivity, unlike other methods that require hundreds or thousands of hours.
Their larger model version performs best across interactivity and quality metrics, while the smaller one still achieves strong results.
Why it matters
AnyTalker makes it much easier to create convincing multi-person conversation videos:
- Content creators could generate podcasts, interviews, talk shows, or multi-host livestreams without recording all participants together.
- Education and entertainment could use interactive avatars that respond naturally in group settings.
- Games and virtual worlds could include lifelike group conversations with AI-controlled characters.
It also sets a standard for measuring interactivity, which can help future research improve realism. As with any powerful generative tool, it’s important to use it responsibly—respecting people’s identities, getting consent for voice and face data, and being transparent about AI-generated content.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or left unexplored in the paper, formulated to guide concrete follow-up research.
- Generalization beyond two-person interactions: the model is fine-tuned only on ~12 hours of dual-person data; its behavior with 3+ speakers (e.g., panel discussions, group meetings) is not quantitatively evaluated or benchmarked.
- Overlapping speech handling: the pipeline assumes diarized, separated audio streams; performance and binding accuracy under overlapping speech or diarization errors remain untested.
- Turn-taking and dialogue dynamics: there is no explicit modeling or evaluation of turn-taking latency, interruption management, backchannels (e.g., nods, “uh-huh”), or response timing consistency.
- Automatic audio–face binding: AFCA expects paired face–audio inputs; it is unclear how robustly the system can auto-bind audio streams to faces in the presence of noisy diarization or uncertain active speaker detection.
- Interactivity metric validity: the proposed eye-keypoint Motion metric lacks formal validation (e.g., user studies, psychometric analysis) of its correlation with human judgments across diverse demographics and contexts.
- Metric scope and completeness: interactivity evaluation is restricted to eye-region motion during listening; it ignores gaze direction toward the current speaker, head nods, facial mimicry, micro-expressions, hand/body gestures, and timing alignment with speech.
- Metric robustness: the Motion score may be gamed by exaggerated or jittery movements; thresholds, normalization, and anti-cheating safeguards need formalization and cross-method stress tests.
- Gaze-direction assessment: no metric captures whether listeners look at the active speaker at appropriate times (mutual gaze events, gaze shifts toward speaker onset), an important conversational cue.
- Listener mouth motion: undesired mouth movements or lip-sync during listening periods are not measured; Sync-C* ignores listening phases and may conceal listener artifacts.
- Head/body interactivity: while the method claims whole-body support, evaluations prioritize faces; there is no quantitative assessment of hand gestures, posture shifts, or full-body synchrony with speech.
- Long-range audio context: the temporal attention mask restricts non-initial frames to local audio windows (4 tokens), with no ablation/justification showing the impact on coarticulation or anticipatory lip motions.
- AFCA scalability cost: computational and memory scaling of AFCA with the number of identities is not reported; maximum feasible IDs, latency, and throughput for real-time scenarios remain unclear.
- Interference across identities: AFCA uses shared parameters and sums per-ID outputs; potential cross-identity leakage (e.g., motions bleeding between faces) and mitigation strategies are not analyzed.
- Face mask design limitations: a global face bounding box mask may suppress natural out-of-plane movements or large pose changes; failure modes under occlusions, extreme head turns, or profile views are not studied.
- Robustness to realistic conditions: sensitivity to audio noise, reverberation, accents, multilingual speech, emotional prosody, variable speaking rates, and room acoustics is not evaluated.
- Non-human generalization: claims of generalizing to non-human cases lack quantitative evaluation, non-human-specific encoders, or failure analyses (e.g., when face detection fails or CLIP features are not semantically aligned).
- Scene consistency and multi-person composition: stage-1 concatenation generates side-by-side scenes from independent videos; generalization to shared physical spaces, camera motion, and cross-person occlusions is not assessed.
- Binding under visual ambiguity: the system’s behavior when faces are partially occluded, appear similar (twins), or rapidly enter/exit the frame is not characterized.
- Long-video coherence: interactivity and identity consistency for longer conversations (>1 minute) are untested; drift, fatigue of motions, or cumulative artifacts over time remain unknown.
- Ethical safeguards: data consent, identity protection, misuse risks (deepfakes), watermarking, and detectability of synthetic content are not addressed.
- Fairness and comparability: comparisons involve models trained on different base architectures and data scales; controlled experiments normalizing backbone and data size are missing.
- Text prompt influence: the role of text prompts in controlling multi-person interactions and their sensitivity or failure cases are not ablated or quantified.
- Emotion modeling: “lively emotions” are claimed without an emotion metric or controlled evaluation (e.g., valence/arousal, expressive prosody alignment).
- Active speaker detection at inference: a fully automated pipeline to infer who is speaking from vision/audio (without pre-paired streams) is not demonstrated.
- Multi-modal control extensions: integration of higher-level controllers (e.g., scripted dialogue, policy models for turn-taking, gesture planners) is not explored.
- Dataset scale and diversity: InteractiveEyes is small (short ~10s clips, only two persons), with limited diversity (cultures, languages, camera setups, motion types); broader benchmarks (3–5 speaker interactions, varied settings) are needed.
- Ablations on AFCA design: no direct comparison to label-based RoPE/L-RoPE, per-ID adapters, or other multi-stream binding strategies under identical conditions.
- Training strategy sensitivity: the effect of freezing vs fine-tuning audio/text/image encoders on interactivity, lip sync, and generalization is not explored.
- Input synchronization edge cases: mismatch in audio lengths across streams, variable start times, or dropped frames are not tested; temporal alignment robustness remains an open issue.
Practical Applications
Immediate Applications
The following items describe concrete ways AnyTalker’s findings and components can be deployed now, organized by sector and accompanied by key dependencies or assumptions.
- Multi-speaker podcast and talk-show avatar production — Media & Entertainment
- Create multi-person talking videos (hosts, guests) from separate audio tracks with natural lip-sync and responsive eye/head movements.
- Tools/workflow: “Avatar panel generator” using AFCA; voice diarization pipeline; CLIP-based face binding; template prompts; batch rendering with AnyTalker’s open-source code.
- Assumptions/dependencies: Clean, separated audio per speaker; consent and rights to reference faces; GPU inference capacity.
- Live-commerce avatar co-hosts — E-commerce/Marketing
- Deploy interactive digital sales assistants that can react (gaze shifts, nods) to the main host’s speech and alternate turns.
- Tools/workflow: Dual-audio ingestion; scheduler for turn-taking; text prompt templates for product segments; real-time or near-real-time pipeline.
- Assumptions/dependencies: Low-latency audio processing; diarization quality; moderation/compliance for claims.
- Multi-language dubbing of group scenes — Media localization
- Replace or supplement original actors with avatars while preserving conversational timing and interactivity; maintain separate audio-to-face bindings per character.
- Tools/workflow: TTS per character; AFCA for multi-stream binding; timeline editing for speaking/listening intervals; Sync-C* scoring for quality control.
- Assumptions/dependencies: High-quality TTS; voice casting; rights management; accurate diarization of source dialogue.
- Virtual panel discussions for webinars and corporate communications — Enterprise/EdTech
- Generate multi-speaker internal presentations with representative avatars; synthesize Q&A segments using turn-taking and listener interactivity.
- Tools/workflow: Script + multiple audio tracks; avatar template library (human and non-human); meeting branding overlays.
- Assumptions/dependencies: Organizational policies on synthetic media; user consent; consistent audio capture.
- Privacy-preserving video conferencing avatars — Productivity/Communications
- Replace live camera feeds with faithful avatars that reflect lip-sync and eye motions, reducing on-camera anxiety and protecting identity.
- Tools/workflow: Client plug-in for conferencing tools; per-participant audio feed; AFCA-based mapping; optional watermarking.
- Assumptions/dependencies: Latency constraints; platform integration; user acceptance; clear synthetic labeling.
- Social media content co-hosts and duet creators — Creator economy
- Two or more avatars co-present tutorials, commentary, and entertainment; eye-gaze and subtle listener motions avoid “mannequin” look.
- Tools/workflow: Creator-friendly “multi-host avatar studio” with templates; batch generation; built-in Interactivity metric QA.
- Assumptions/dependencies: Mobile-friendly inference or cloud rendering; IP rights for faces/voices.
- Interactive customer support demos and role-plays — Customer Experience/Training
- Produce multi-agent support simulations (agent + customer) for training; measure listener responsiveness via eye-keypoint Interactivity score.
- Tools/workflow: Scenario scripts; dual audio tracks; QA gate using Interactivity metric; LMS integration.
- Assumptions/dependencies: Scenario realism; diarization accuracy; data privacy for synthetic transcripts.
- NPC conversation clips for games and modding — Gaming
- Quickly generate multi-character dialogue previews, trailers, or in-game cinematics using stylized or non-human avatars.
- Tools/workflow: Game engine plug-ins; character face references; AFCA for multi-character binding; animation pass hand-offs.
- Assumptions/dependencies: Artistic alignment with game style; timing and lip-sync pass checks.
- Advertising creatives with multi-character variants — Marketing
- A/B test multi-character ad concepts (e.g., brand ambassador + customer) with controlled interactivity and lip-sync quality.
- Tools/workflow: Creative brief -> TTS -> AnyTalker batch; Interactivity metric to filter stilted takes; rights workflow for talent avatars.
- Assumptions/dependencies: Legal review; disclosure requirements for synthetic personas; voice brand guidelines.
- Academic benchmarking and model QA — Research
- Use InteractiveEyes dataset and the eye-motion Interactivity metric to evaluate multi-person generative models and reduce “listener mannequin” artifacts.
- Tools/workflow: Integrate Interactivity metric into CI; shared benchmark scripts; reproducible comparisons.
- Assumptions/dependencies: Public availability and licensing of the dataset; robustness of eye landmark extraction.
- Low-cost multi-person training via data augmentation — Startups/Labs
- Adopt the concatenation-based Stage-1 pipeline to learn multi-speaker patterns on single-person datasets; apply light multi-person fine-tuning.
- Tools/workflow: Horizontal concatenation messengers; generic “dual speaker” prompts; small multi-person refinement set (≈12 hours).
- Assumptions/dependencies: Good single-person dataset diversity; reliable face detection (InsightFace); compute for fine-tuning.
- Open-source AFCA layer for multi-stream conditioning — Software
- Drop AFCA into DiT-based generators to bind multiple conditional streams (audio + face) with scalable identities and masked attention.
- Tools/workflow: Plug-in architecture; parameter sharing across identities; face mask token handling; MHCA integration.
- Assumptions/dependencies: Compatibility with underlying video diffusion backbone; quality of face masks and feature encoders (CLIP, Wav2Vec2).
Long-Term Applications
These opportunities are feasible with additional research, scaling, or engineering (e.g., real-time constraints, broader validation with >2 speakers, domain adaptation).
- Real-time multi-user avatar conferencing at scale — Communications
- Live multi-party calls with low-latency avatars reflecting turn-taking, gaze, and subtle listener behaviors.
- Tools/workflow: GPU/ASIC acceleration; streaming-ready AFCA; robust online diarization; network jitter handling.
- Assumptions/dependencies: Sub-200 ms pipeline latency; scalable edge inference; platform standards for synthetic labeling.
- Virtual production pipelines for film/TV — Media & Entertainment
- Previsualization and even final shots of multi-character dialogue scenes using stylized or non-human avatars, with director control over interactivity.
- Tools/workflow: DCC integration; timeline/gaze editors; script-based turn-taking controls; approval workflows.
- Assumptions/dependencies: Artistic fidelity and direction; union and talent contracts; large-scale render farms.
- Metaverse events and social worlds with expressive group avatars — XR/Metaverse
- Host panels, classes, and performances with many avatars interacting naturally, including brand mascots and non-human forms.
- Tools/workflow: AFCA extended to dozens of identities; crowd interaction models; server orchestration for multi-stream inputs.
- Assumptions/dependencies: Performance with large N; moderation tools; content authenticity verification.
- Synthetic datasets for training social perception (gaze, turn-taking) — AI/Robotics
- Generate controlled multi-person scenes to train models in nonverbal cues for conversational AI and social robots.
- Tools/workflow: Scenario generators with labeled speaking/listening segments; parameterized eye/head motion; curriculum learning.
- Assumptions/dependencies: Transferability from synthetic to real; diverse cultural expressions; ethical data use.
- Multi-party multilingual dubbing with cross-cultural expressivity — Media localization
- Adapt eye/gaze and micro-expressions to cultural norms while preserving conversational structure across languages.
- Tools/workflow: Culture-aware motion priors; expressivity mapping; editor tools for listener responsiveness.
- Assumptions/dependencies: Cultural datasets; localization expertise; audience testing.
- Group-therapy and clinical training simulations — Healthcare
- Role-play group sessions with synthetic patients and therapists, emphasizing realistic listening and turn-taking behaviors.
- Tools/workflow: Domain-specific prompts and audio; quality gates using Interactivity; privacy-preserving avatarization of real cases.
- Assumptions/dependencies: Clinical validation; ethical safeguards; HIPAA/GDPR compliance.
- Education: multi-agent tutors, debates, and classroom simulations — EdTech
- Create interactive multi-avatar lessons (teacher + student panel), debate formats, and peer instruction scenes.
- Tools/workflow: LMS integration; script-to-multi-avatar pipelines; assessment using Interactivity for engagement.
- Assumptions/dependencies: Pedagogical effectiveness studies; accessibility accommodations; institutional policies.
- Policy tooling: benchmarks and metrics for synthetic multi-person media — Governance
- Standardize interactivity and authenticity checks; watermarking audits; disclosure frameworks for multicharacter synthetic content.
- Tools/workflow: Interactivity metric as QA; dataset-driven compliance tests; platform APIs for labeling.
- Assumptions/dependencies: Regulatory consensus; industry adoption; robust detection of mislabeled content.
- Multi-modal controllers (beyond audio): gestures, sensor fusion for avatars — Software/Robotics
- Extend AFCA to handle heterogeneous inputs (text, gaze trackers, gestures) for fine-grained multi-avatar control.
- Tools/workflow: Multi-stream in-context attention; adapter modules; real-time sensor ingestion.
- Assumptions/dependencies: Stable fusion strategies; standardized input formats; user devices.
- Automated A/B testing of conversational layouts and interactivity — Marketing UX
- Optimize group scene timing, gaze behavior, and turn-taking patterns to increase viewer engagement and comprehension.
- Tools/workflow: Experiment manager; metrics suite (Interactivity + Sync-C* + retention); generator feedback loop.
- Assumptions/dependencies: Reliable engagement data; consent; privacy-compliant analytics.
Cross-cutting assumptions and dependencies
- Audio quality and diarization: Clear separation of speakers is critical; errors degrade lip-sync and interactivity.
- Identity assets and rights: Use of faces/voices requires consent and proper licensing; comply with local laws and platform policies.
- Compute and latency: Large backbones (e.g., 14B) need substantial GPUs; real-time scenarios require acceleration and optimization.
- Generalization to >2 speakers: While AFCA scales arbitrarily and shows promise, broad validation for larger groups will require more multi-person training data and stress testing.
- Ethical and safety considerations: Watermarking, disclosure, and misuse prevention (e.g., deepfake multi-person scenes) need policy and technical safeguards.
- Integration with existing stacks: Compatibility with diffusion backbones, TTS engines, CLIP/Wav2Vec2, and face detection (InsightFace) influences feasibility.
Glossary
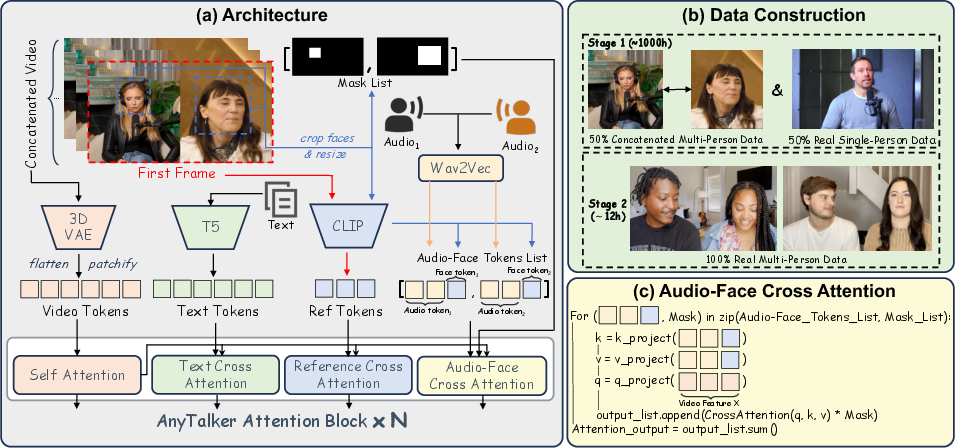
- 3D VAE: A variational autoencoder that encodes video into spatiotemporal latent features for diffusion-based generation. "AnyTalker tokenizes the 3D VAE features through patchifying and flattening"
- AdamW: An optimizer that decouples weight decay from the gradient update, commonly used in training deep networks. "All models are optimized with AdamW~\cite{loshchilov2017decoupled} on 32 NVIDIA H200 GPUs."
- AFCA (Audio-Face Cross Attention): A multi-stream cross-attention mechanism that binds audio tokens to corresponding face regions to drive multiple identities. "we introduce a specialized multi-stream processing structure, termed as the Audio-Face Cross Attention~(AFCA)"
- Audio diarization: The process of segmenting an audio track into speaker-homogeneous regions to determine who spoke when. "audio diarization~\cite{Plaquet23} to separate audio and ensure there is only one or two speakers"
- CLIP image encoder: A visual encoder from the CLIP model used to extract identity features from reference images. "leverages the CLIP image encoder~\cite{radford2021learning}"
- Classifier-free guidance: A sampling technique that improves conditional generation by interpolating between conditional and unconditional model outputs. "uses token-level masking within a classifier-free guidance framework to realize similar binding"
- Diffusion Transformer (DiT): A diffusion model architecture that uses Transformer blocks for generative modeling. "we extend Diffusion Transformer's attention block with a novel identity-aware attention mechanism"
- Embedding Router: A module that associates identity embeddings with corresponding content (e.g., spoken audio) to control specific avatars. "Bind-your-Avatar~\cite{huang2025bind} introduces a fine-grained Embedding Router that binds
whoâ withwhat they speakâ." - Eye keypoints: Specific landmark points around the eyes used to quantify motion and interactivity. "we propose a quantitative evaluation of the interaction by tracking the motion amplitude of eye keypoints."
- Eye landmarks: Detected sparse points on the eye region used to analyze gaze and micro-movements. "right shows cropped face and eye landmarks."
- Face-Aware Audio Adapter: A controller that modulates attention to different characters based on face information for multi-person audio-driven generation. "HunyuanVideo-Avatar~\cite{chen2025hunyuanvideo} leverages a Face-Aware Audio Adapter to activate attention across different characters selectively"
- FFN layer: The feed-forward network following attention layers in Transformer blocks, producing the final outputs. "Consistent with the Wan model, all attention layers are connected to the final output FFN layer"
- Fréchet Inception Distance (FID): A metric comparing feature distributions of generated and real images to assess visual quality. "the Fréchet Inception Distance (FID)~\cite{heusel2017gans}"
- Fréchet Video Distance (FVD): A metric that evaluates the realism of generated videos by comparing video feature distributions. "the Fréchet Video Distance (FVD)~\cite{unterthiner2019fvd}"
- Hand Keypoint Variance (HKV): A metric measuring variability of hand landmarks over time, used as inspiration for the eye-based interactivity metric. "Drawing inspiration from the Hand Keypoint Variance (HKV) metric employed in CyberHost~\cite{lin2025cyberhost}"
- I2V (Image-to-Video): A setting/model that converts a single image into a video sequence using generative methods. "AnyTalker inherits certain architectural components from the Wan I2V model~\cite{wan2025wan}."
- ID similarity: A measure of identity consistency across frames, often computed with a face-recognition model. "ID similarity~\cite{deng2019arcface} calculated between the first frame and the remaining frames."
- InsightFace: A face analysis toolkit used for detection, cropping, and identity verification in data processing. "using InsightFace~\cite{deng2019arcface} to ensure two faces in most frames"
- Interactivity (metric): A quantitative measure of listener responsiveness based on eye motion during non-speaking periods. "we introduce a novel metric, the eye-focused Interactivity, designed to assess the natural interaction between speakers and listeners."
- Label Rotary Position Embedding (L-RoPE): A positional embedding variant that incorporates labels to bind inputs (e.g., audio) to specific entities. "MultiTalk~\cite{kong2025let} proposes Label Rotary Position Embedding~\cite{su2024roformer} to address audioâperson binding."
- Mask token: A token that gates attention outputs to a predefined face region, preventing activation outside the face area. "Mask token used for output masking in Audio-Face Cross Attention."
- MHCA (Multi-Head Cross Attention): An attention mechanism where queries attend to keys/values from another modality or source across multiple heads. "Here, MHCA denotes Multi-Head Cross Attention"
- Optical flow: A method that estimates pixel-wise motion between frames, used for filtering excessive movement in training data. "optical flow~\cite{karaev2024cotracker} to filter excessive motion"
- Patchifying and flattening: Operations that convert spatial feature maps into sequences of tokens for Transformer processing. "AnyTalker tokenizes the 3D VAE features through patchifying and flattening"
- Reference Attention Layer: A cross-attention mechanism that injects identity features from a reference image into the generation process. "AnyTalker incorporates Reference Attention Layer, a cross-attention mechanism that leverages the CLIP image encoder"
- ReferenceNet: A module for identity conditioning in portrait animation, providing reference-based control signals. "identity control via ReferenceNet~\cite{zhu2023tryondiffusion, hu2024animate, kong2025profashion, zhang2025learning}"
- Sync-C: A metric that quantifies lip-audio synchronization quality in talking-head generation. "Sync-C~\cite{chung2016out} to measure the synchronization between audio and lip movements"
- Sync-C*: A refined synchronization metric computed only during speaking intervals in multi-person scenarios. "we refine its calculation as Sync-C to focus only on the lip synchronization during each character's speaking periods"
- Temporal attention: An attention mechanism across the time dimension to model temporal dependencies in video. "They typically integrate modules for temporal attention~\cite{guoanimatediff}"
- Temporal Attention Mask: A mask that restricts attention to a local temporal window aligning video and audio tokens. "This structured alignment between video and audio streams is achieved by applying a Temporal Attention Mask $M_{\text{temporal}$"
- T5 encoder: A text encoder from the T5 model used to produce textual conditioning features. "the text features are generated by the T5 encoder~\cite{raffel2020exploring}."
- Wav2Vec2: A self-supervised audio representation model used to extract features for conditioning lip movements. "Wav2Vec2~\cite{baevski2020wav2vec} is also applied to extract the audio feature ."
Collections
Sign up for free to add this paper to one or more collections.