SpriteHand: Real-Time Versatile Hand-Object Interaction with Autoregressive Video Generation
Abstract: Modeling and synthesizing complex hand-object interactions remains a significant challenge, even for state-of-the-art physics engines. Conventional simulation-based approaches rely on explicitly defined rigid object models and pre-scripted hand gestures, making them inadequate for capturing dynamic interactions with non-rigid or articulated entities such as deformable fabrics, elastic materials, hinge-based structures, furry surfaces, or even living creatures. In this paper, we present SpriteHand, an autoregressive video generation framework for real-time synthesis of versatile hand-object interaction videos across a wide range of object types and motion patterns. SpriteHand takes as input a static object image and a video stream in which the hands are imagined to interact with the virtual object embedded in a real-world scene, and generates corresponding hand-object interaction effects in real time. Our model employs a causal inference architecture for autoregressive generation and leverages a hybrid post-training approach to enhance visual realism and temporal coherence. Our 1.3B model supports real-time streaming generation at around 18 FPS and 640x368 resolution, with an approximate 150 ms latency on a single NVIDIA RTX 5090 GPU, and more than a minute of continuous output. Experiments demonstrate superior visual quality, physical plausibility, and interaction fidelity compared to both generative and engine-based baselines.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “SpriteHand: Real-Time Versatile Hand-Object Interaction with Autoregressive Video Generation”
1. What is this paper about?
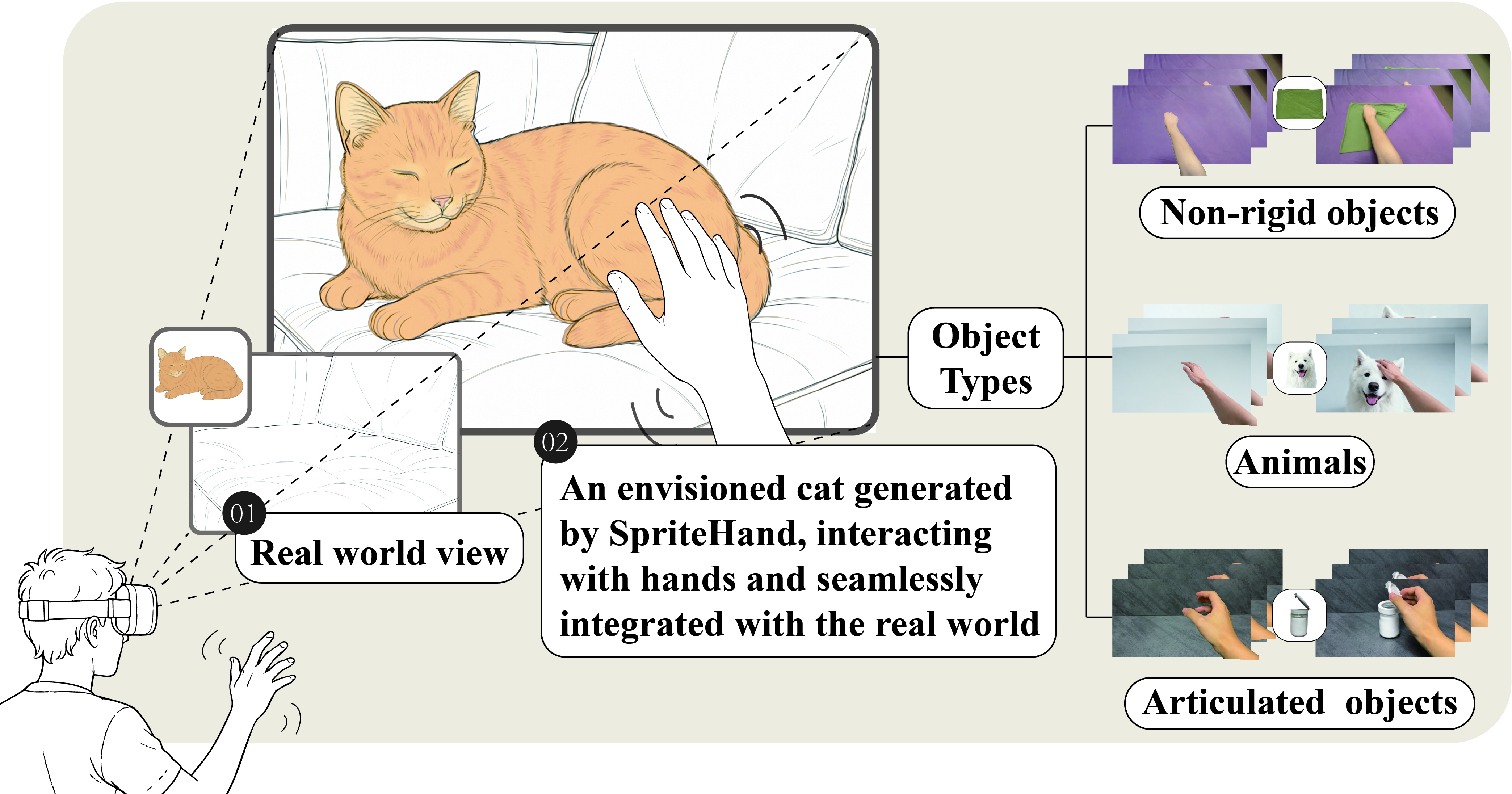
This paper introduces SpriteHand, a computer system that can create videos—live and in real time—showing a person’s hands interacting with a virtual object as if it were actually there. Imagine pointing your phone at your hands and seeing a virtual cat, toy, or door reacting naturally to your touch. SpriteHand makes those hand–object interactions look realistic, even for squishy things like fabric or flexible toys, and does it fast enough to feel immediate.
2. What questions did the researchers ask?
To make virtual objects feel “real” in live video, the team set out to answer:
- Can we generate believable hand–object interaction videos in real time, not just offline?
- Can we handle tricky objects (like soft cloth, hinged lids, or animals) that are hard to simulate with traditional physics engines?
- Can we keep the video stable and consistent for a long time without the quality slowly falling apart?
3. How did they do it? (Methods in simple terms)
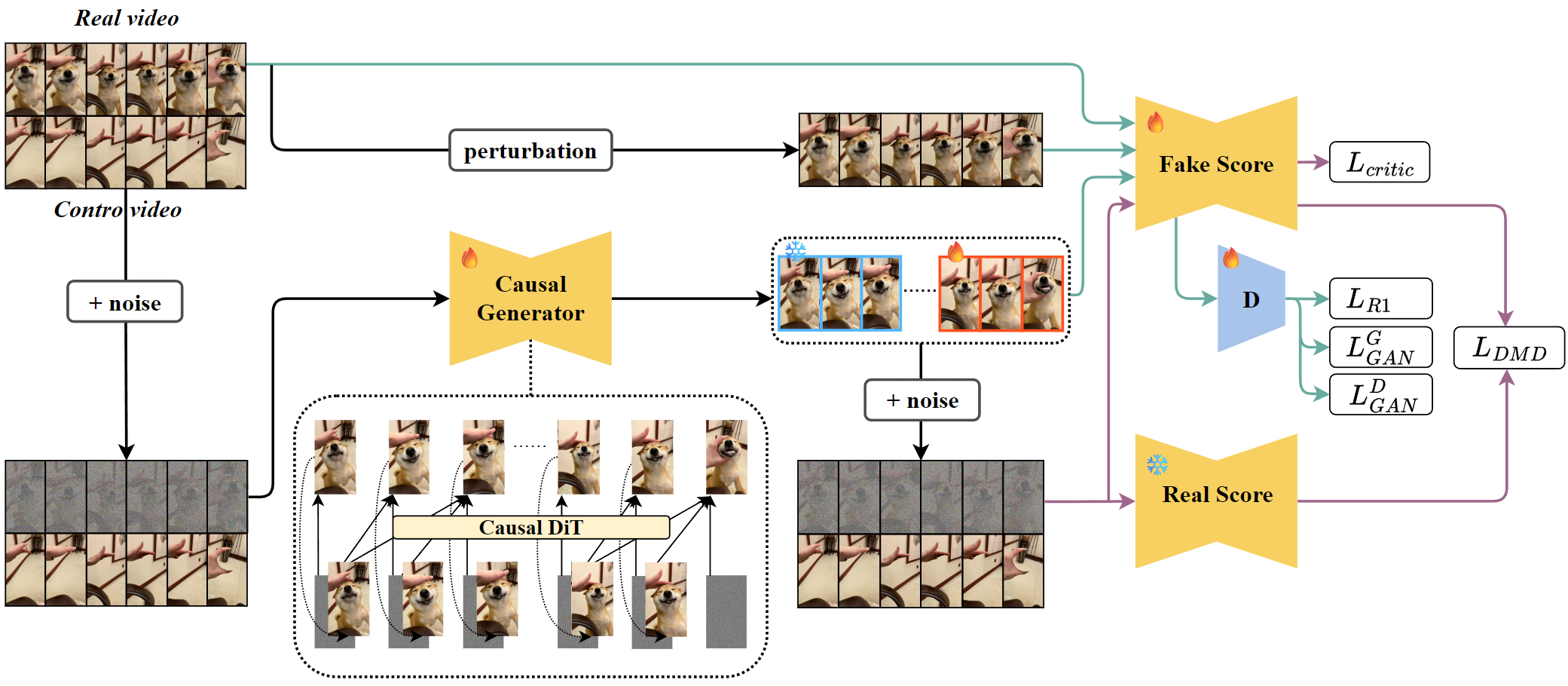
Think of SpriteHand like a smart video “puppeteer” with two main stages: a high-quality teacher and a fast, real-time student.
- Step 1: Train a “teacher” model for quality
- The team starts with a powerful video generator (a diffusion transformer) that’s great at making smooth, realistic videos but needs to see the whole video at once. It learns from many examples how hands and objects interact.
- Input: one picture of the object + a video of a hand moving (without the object).
- Output: a video where the hand appears to touch and control the object in a natural way.
- Step 2: Build a “student” model for speed
- The teacher is too slow for live use, so they create a faster model that generates the video one frame at a time, like a livestreamer (this is called autoregressive generation).
- It remembers past frames (like a “memory cache”) so each new frame is quick to produce and stays consistent with what came before.
- Step 3: Polish the student so it doesn’t drift or degrade over time
- Self-forcing: The student practices using its own previous outputs, not just perfect examples. This is like rehearsing under real show conditions, so it won’t panic when it has to rely on itself.
- Distribution Matching (student–teacher tutoring): The student compares its “style” to the teacher’s high-quality style and adjusts to match it.
- Adversarial training (the “art critic”): A separate critic network tries to tell real from generated frames, pushing the student to make results that look more real.
- Smart caching and an optional tiny autoencoder speed up processing so the system can keep up with live video.
In short: a high-quality teacher teaches a fast student; then the student rehearses in realistic conditions with coaching and a critic to keep results sharp and stable.
4. What did they find, and why is it important?
Here are the key results:
- Real-time performance: The system runs at about 18 frames per second with roughly 150 milliseconds of delay on a powerful graphics card, which feels responsive for live use (like AR on a headset or phone).
- Long, stable videos: It can keep generating for over a minute without the picture getting worse or the motion drifting off target.
- Big quality jump after refinement: The “raw” fast model looks noticeably worse than the teacher at first, but after the polishing steps (self-forcing + teacher matching + critic), quality improves a lot—much closer to the teacher.
- Works across tough cases: It handles three hard categories—non-rigid (like cloth), articulated (like doors and lids), and animals. Non-rigid is easiest; animals are the toughest because they move unpredictably.
- Competitive realism: While some offline methods can look slightly cleaner, they aren’t live. SpriteHand comes close in visual quality and wins on responsiveness, which is crucial for interactive experiences.
Why this matters: Most traditional physics-based systems struggle with soft or complicated objects and can’t run fast enough with high realism for live video. SpriteHand shows that a learned, data-driven approach can deliver both realism and speed, opening the door to new kinds of AR/VR and interactive media.
5. What could this change in the real world?
- Augmented and Virtual Reality: You could pet virtual animals, open virtual boxes, or fold virtual cloth that reacts to your actual hand movements in your real environment.
- Games and creative tools: Players and creators can mix real hands with virtual items on the fly—no heavy 3D modeling or complex physics setup needed.
- Robotics and training: Simulating believable hand–object interactions quickly could help teach robots or prototype tasks for factories and services.
- Digital twins and education: It becomes easier to create convincing demos and lessons where virtual objects behave naturally around real people.
Overall, SpriteHand suggests a new way to make virtual things feel part of the real world: instead of trying to perfectly simulate physics for every object, we can learn from real videos and generate realistic interactions live, right in your camera view.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Input inconsistency and requirements: the paper alternately describes “a static object image” and an “initial frame I0 containing the object”; clarify and evaluate both regimes (image-only vs. image+I0), including how object pose, scale, and depth are initialized and updated in real time.
- Absence of explicit 3D reasoning: the system infers plausible interactions from 2D inputs without estimating object/hand 3D pose, depth, or contact geometry; investigate integrating monocular depth, 3D hand/object pose estimators, or neural fields to improve contact accuracy and physical plausibility.
- No quantitative physical plausibility metrics: beyond FID/FVD and VBench, there are no HOI-specific measures (e.g., contact persistence, penetration depth, slip vs. stick ratio, deformation compliance); develop and report physics-aware metrics using 3D reconstruction, contact maps, and force proxies.
- Dataset realism and artifact bias: training pairs are constructed via segmentation and inpainting (SAM2, EgoHOS, VACE), which can introduce artifacts; quantify segmentation/inpainting error rates, measure their impact on model learning, and provide artifact-aware data splits/ablation.
- Limited domain breadth and imbalance: only three domains with uneven sample counts (animals are underrepresented); expand categories (tools, liquids, granular materials, rigid multi-part machinery) and balance sample sizes to reduce domain bias.
- Lack of fine-grained annotations: the dataset has no labels for material properties (elasticity, friction), kinematic constraints, or contact states; add per-sample HOI attributes and material/structure metadata to enable controllable generation and targeted evaluation.
- Articulated object priors: failures on complex mechanisms suggest the need for structural priors; explore conditioning on kinematic graphs or part segmentation to preserve hinge/link constraints during generation.
- Animals and living entities: rare/fast animal motions cause collapses; curate more diverse animal sequences, add species/pose labels, and test specialized motion priors to handle high-frequency, non-rigid morphologies safely and realistically.
- Occlusion and clutter robustness: heavy occlusions and stacked objects lead to topological merging; incorporate occlusion-aware training, layered compositing, and hand/object instance tracking to prevent topology errors.
- Multi-object and bimanual interactions: the paper does not evaluate interacting with multiple objects or both hands simultaneously under causal streaming; benchmark and extend to multi-object, bimanual, and tool-mediated interactions with explicit coordination constraints.
- Camera motion and illumination variation: robustness to egocentric motion blur, rapid viewpoint changes, and lighting shifts is unquantified; design stress tests with HMD/phone footage and report performance under strong photometric/geometric perturbations.
- Real-time performance generalization: latency/FPS are reported for an NVIDIA RTX 5090 at 640×368; profile across commodity GPUs, mobile SoCs, and AR devices, and quantify the trade-offs between resolution, frame rate, power, and thermal limits.
- Long-horizon guarantees: while minute-long generation is shown, formal analysis of drift over indefinite horizons and under non-repeating inputs is missing; develop reset/re-anchoring strategies and detect/drift-correct mechanisms for open-ended sessions.
- Failure mode detection and recovery: the system lacks online detectors for interaction violations (penetration, collapse, misalignment); implement real-time monitors and corrective controllers (e.g., recondition frames, adjust conditioning, or invoke priors).
- Controllability of physical properties: object material/behavior (softness, friction, stiffness) cannot be explicitly controlled; add control knobs or prompts for physical attributes and evaluate their consistency and range.
- Conditioning modalities: current control is limited to a hand-motion video; explore multi-modal control (text prompts, voice, IMU/glove signals, skeletal hand tracking) and study how each influences fidelity and responsiveness.
- Comparative baselines: no streaming HOI-specific generative baselines are included (e.g., adapted CausVid/SlowMo variants); implement and compare against state-of-the-art causal video generators under identical tasks and hardware.
- Evaluation fairness and statistical rigor: the human study lacks details (participant count, recruitment, statistical tests, inter-rater reliability); report sample sizes, significance tests, confidence intervals, and preregistered protocols to substantiate claims.
- Task alignment with “oracle” baseline: VACE uses privileged masks and offline processing, which differs from SpriteHand’s streaming constraints; add non-privileged offline baselines and streaming baselines to isolate causal vs. oracle advantages.
- Resolution and visual quality trade-offs: accelerated Tiny Autoencoder (TAE) variant degrades temporal metrics on some categories; systematically map quality–latency–resolution trade-offs and propose adaptive strategies (dynamic resolution, model scaling).
- Reproducibility gaps: key training details (exact hyperparameters, schedule lengths, dataset splits, augmentation recipes, optimizer settings) and code/data availability are unclear; release code, pre-trained weights, data processing scripts, and a standardized benchmark.
- Safety, ethics, and user studies in MR: implications of synthesizing interactions with animals and deceptive realism are not addressed; add ethics guidelines (content filters, consent, disclaimers), and evaluate user comfort, trust, and motion sickness in AR/VR scenarios.
- Personalization and domain adaptation: the system does not adapt to individual hand shapes, skin tones, or idiosyncratic motion; explore lightweight online personalization, few-shot adaptation, and robustness across demographics.
- Scene integration fidelity: background relighting, cast shadows, and mutual illumination between hands and objects are not modeled; add differentiable relighting and shadow synthesis for tighter scene-object integration.
- Robust hand tracking and calibration: reliance on inferred hand motion without explicit calibration can misalign control and generation; integrate robust hand pose detectors, temporal calibration, and per-device alignment procedures.
- Memory and compute profiling: streaming KV caches and VAE buffering are described but not quantified; provide memory footprints, cache eviction strategies, and latency breakdowns to guide deployment engineering.
Glossary
- Ablation study: A systematic removal or alteration of components to assess their impact on performance. "Ablation study (Fig.~\ref{fig:r1_compare}) further indicates that long-horizon stability is strongly supported by the inclusion of the R1 loss"
- Adversarial post-training: A refinement stage where a generator is improved using a discriminator to enhance perceptual realism. "Following the adversarial post-training paradigm~\cite{lin2025diffusionadversarialposttrainingonestep}, we further refine the causal generator through discriminator-guided perceptual learning."
- Adversarial training: Training regime where a generator and discriminator compete to improve realism. "combining distribution matching \cite{yin2024onestep,yin2024improved} and adversarial training \cite{lin2025autoregressiveadversarialposttrainingrealtime}."
- Articulated objects: Objects composed of parts connected by joints (e.g., hinges) allowing movement. "The articulated object dataset comprises 618 samples of hinge- and link-based structures (doors, lids, foldables) curated from Arctic"
- Autoregressive video generation: Generating the next video frame conditioned on past frames in sequence. "an autoregressive video generation framework for real-time synthesis of versatile hand-object interaction videos"
- Bidirectional diffusion transformer (DiT): A diffusion-based transformer that attends across past and future tokens for generation. "we first train a bidirectional diffusion transformer (DiT) for hand–object interaction synthesis"
- Block-causal mask: An attention mask that restricts tokens to attend only to past frames. "a block-causal mask so that tokens from the current frame can only attend to tokens from frames ."
- Block-causal transformer design: Transformer architecture with bidirectional intra-frame attention and causal cross-frame attention. "a causal variant of the model that follows the block-causal transformer design introduced in CausVid~\cite{yin2025causvid}."
- Bootstrap frame: The initial frame used to start a streaming generation process. "The control video is divided into a bootstrap frame and successive 4-frame blocks;"
- Causal inference architecture: Model design enforcing temporal causality for online generation. "Our model employs a causal inference architecture for autoregressive generation"
- Causal self-attention: Attention mechanism that only considers current and past tokens. "Formally, the causal self-attention is defined as"
- CausVid: A framework introducing block-causal transformers for streaming video generation. "block-causal transformer design introduced in CausVid~\cite{yin2025causvid}."
- Critic loss: A regularization objective that guides the score network to behave like a valid diffusion model. "we apply a critic loss that constrains the fake score to behave as a valid diffusion model on the generator-induced distribution."
- Discriminator: A neural network that distinguishes real from generated samples to guide adversarial training. "The discriminator takes intermediate layer features of the fake score network $f_{\text{fake}$ as input"
- Diffusion Forcing (DF): Training technique introducing stochastic temporal perturbations to reduce exposure bias. "Diffusion Forcing (DF) \cite{chen2024df} alleviates this gap by introducing stochastic temporal perturbations to stabilize long rollouts."
- Distribution Matching Distillation (DMD): A distillation method aligning a trainable model’s score with a reference diffusion model. "we employ distribution matching distillation (DMD)~\cite{yin2024onestep,yin2024improved}, which aligns two bidirectional diffusion networks"
- Distributional gap: The statistical difference between generated and real data distributions. "FID evaluates the distributional gap between generated videos and real videos"
- EgoHOS: A method for egocentric hand-object segmentation. "Hand masks are extracted via SAM2 \cite{ravi2024sam2} and EgoHOS \cite{zhang2022egohos}"
- Egocentric camera view: First-person viewpoint captured from the user’s perspective. "The user perceives the world through an egocentric camera view"
- Exposure bias: Training-inference mismatch caused by conditioning on ground truth during training but model outputs at inference. "Teacher Forcing (TF) \cite{gao2024tf} trains next-frame prediction on ground-truth contexts, leading to exposure bias during inference"
- Fréchet Inception Distance (FID): Metric assessing similarity between generated and real images via feature distributions. "We report Fréchet Inception Distance (FID) \cite{Seitzer2020FID}"
- Fréchet Video Distance (FVD): Metric evaluating temporal and spatial consistency between real and generated videos. "Fréchet Video Distance (FVD) \cite{unterthiner2019accurategenerativemodelsvideo}"
- Hierarchical KV Cache: Multi-level storage of key-value tensors to accelerate causal attention in streaming. "A hierarchical KV Cache \cite{yin2025causvid} is maintained across all causal attention layers"
- Keyâvalue caching: Reusing stored attention keys and values from previous frames to speed generation. "cached keyâvalue pairs from past frames are reused across attention computations"
- Kinematic constraints: Restrictions on motion dictated by a model’s joints and linkages. "manually defined object models, kinematic constraints, and pre-scripted hand gestures"
- KullbackâLeibler divergence: A measure of how one probability distribution diverges from another. "conditional KullbackâLeibler divergence"
- Latent Diffusion Models (LDM): Diffusion models operating in a compressed latent space rather than pixel space. "Video Latent Diffusion Models (LDM) \cite{Rombach2021HighResolutionIS}"
- Latent space: Compressed representation space used for efficient modeling and generation. "encode both and into the latent space"
- MANO hand model: A parametric 3D hand model used for reconstruction and manipulation tasks. "MANO hand model\cite{Romero2017EmbodiedH}"
- Mode collapse: Failure in generative models where outputs lack diversity, collapsing to few modes. "preventing mode collapse and ensuring reliable gradients"
- Non-rigid objects: Deformable entities that change shape under interaction. "(1) Non-rigid objects."
- Non-saturating logistic formulation: GAN loss variant improving training stability and gradient flow. "The critic is trained using a non-saturating logistic formulation"
- R1 regularization: Gradient penalty applied to the discriminator to stabilize GAN training. "we adopt the approximated R1 regularization"
- SAM2: A segmentation model for images and videos used to obtain masks. "SAM2 \cite{ravi2024sam2}"
- Self Forcing (SF): Training approach where the model conditions on its own generated outputs to reduce train-inference gap. "Self Forcing (SF) \cite{huang2025sf} further aligns training with inference"
- Spatio-temporal correspondences: Learned mappings linking spatial structures with temporal dynamics. "to learn spatio-temporal correspondences between the control motion and object interaction dynamics."
- Streaming inference: Online generation approach producing outputs incrementally with low latency. "fully streaming inference \cite{yin2025causvid}"
- Teacher Forcing (TF): Training method using ground-truth previous outputs as inputs for next-step prediction. "Teacher Forcing (TF) \cite{gao2024tf} trains next-frame prediction on ground-truth contexts"
- Temporal coherence: Consistency of appearance and motion across time in generated sequences. "enhance visual realism and temporal coherence."
- Tiny Autoencoder (TAE): A compact autoencoder variant used to accelerate decoding while maintaining consistency. "Tiny Autoencoder \cite{BoerBohan2025TAEHV}"
- Variational Autoencoder (VAE): Generative model that learns a latent representation via probabilistic encoding/decoding. "pretrained 3D variational autoencoder (VAE)"
- VBench-I2V: A benchmark providing perceptual metrics for image-to-video generation. "from VBench-I2V \cite{huang2023vbench}"
- Video Diffusion Models (VDM): Diffusion-based generative models extended to handle video sequences. "Video Diffusion Models (VDM)\cite{Ho2022VideoDM}"
- Wan 2.1: A bidirectional video diffusion transformer backbone used as the base model. "Wan 2.1~\cite{wan2025wanopenadvancedlargescale}"
Practical Applications
Overview
SpriteHand is a real-time autoregressive video generation framework that embeds a static virtual object into a live egocentric scene and synthesizes plausible hand–object interactions in response to a user’s hand motions. It runs at ~18 FPS and 640×368 with ~150 ms latency on a single NVIDIA RTX 5090, and supports minute-long streaming via causal attention, KV caching, and a hybrid post-training regimen (self-forcing rollout + distribution matching + adversarial refinement). It is particularly strong for non-rigid, articulated, and animal-like interactions where traditional physics engines struggle.
Below are practical applications organized by deployment horizon. Each item includes sectors, candidate tools/products/workflows that could be built, and assumptions/dependencies affecting feasibility.
Immediate Applications
These can be piloted or deployed now with a workstation GPU or cloud inference, leveraging the SpriteHand causal-refined model as described.
- Interactive AR/MR overlays for content creators and streamers
- Sectors: software, media/entertainment, education
- Tools/products/workflows: OBS/Twitch plugins that add “hand-reactive” virtual objects (toys, tools, pets) to live streams; mobile MR filters for TikTok/Reels; Unity/Unreal plugins for rapid prototyping of hand-reactive overlays without 3D assets.
- Assumptions/dependencies: GPU or cloud inference to meet sub-200 ms latency; adequate hand capture from a phone or webcam; results are visually plausible but not physically accurate for all cases.
- Video editing without manual keyframing for hand-object effects
- Sectors: software, media production, advertising
- Tools/products/workflows: Adobe After Effects/Premiere or CapCut plugin to insert and animate products (hinge lids, flexible packaging) that respond to recorded hand motions; batch processing for social creatives.
- Assumptions/dependencies: 640×368 baseline output may require super-resolution; tricky occlusions or fast motions may need manual review.
- Rapid previsualization for AR interaction design
- Sectors: software, XR, HCI research
- Tools/products/workflows: Design teams mock up hand interactions with non-rigid/hinged props using only object images and sample hand videos; iterate on affordances and timings before committing to engine-based implementations.
- Assumptions/dependencies: previews guide design but do not provide exact physics; complex mechanisms may still require traditional prototyping.
- E-commerce product demos with hand-reactive behavior
- Sectors: retail/e-commerce, marketing
- Tools/products/workflows: Web/mobile “try-it-in-your-hands” demos for hinges (lids, cases) and flexible goods (garments, towels) that respond to customer hand gestures in-camera; interactive ads.
- Assumptions/dependencies: cloud inference for scale; legal/disclosure that visuals are approximations; domain bias if product category differs from training data.
- Training data augmentation for HOI research
- Sectors: academia, robotics, computer vision
- Tools/products/workflows: Generate diverse hand-object clips for non-rigid/articulated cases to pretrain recognition or pose-estimation models; synthetic-to-real domain adaptation studies.
- Assumptions/dependencies: Labeling pipelines for generated data; avoid learning model biases from failure modes (e.g., rare poses).
- Mixed-reality museum/exhibit interactions
- Sectors: culture/education, entertainment
- Tools/products/workflows: On-site kiosks or guided tours where visitors manipulate virtual artifacts or wildlife safely via hand gestures; deploy with an HMD or tablet.
- Assumptions/dependencies: Reliable lighting/hand visibility; on-site GPU or edge server.
- Remote assistance and customer support demonstrations
- Sectors: industrial services, consumer electronics
- Tools/products/workflows: Technicians or agents show customers how a latch, lid, or connector behaves by live-embedding a virtual surrogate into the user’s scene, synced to hand motions.
- Assumptions/dependencies: Clear camera positioning; disclaimers about approximate behavior for safety-critical tasks.
- HCI user studies of hand-object interaction without full 3D pipelines
- Sectors: academia (HCI, CV)
- Tools/products/workflows: Conduct perception and latency studies using SpriteHand’s streaming pipeline to test realism, plausibility, and responsiveness; annotate user behavior without building assets.
- Assumptions/dependencies: Standardized lab setups; maintaining consistent camera viewpoints across participants.
- Educational micro-simulations for K–12 and informal learning
- Sectors: education
- Tools/products/workflows: Classroom or home apps where students handle virtual materials (cloth, sponges, flaps) to learn about material properties or mechanisms qualitatively.
- Assumptions/dependencies: Clear messaging that this is a visual approximation; cloud/offline capability depending on school infrastructure.
- VTubing and virtual pet interactions
- Sectors: media/entertainment, consumer apps
- Tools/products/workflows: Real-time virtual pets that respond to streamer hand gestures without rigging; extensions for avatar props that “behave” when touched.
- Assumptions/dependencies: Stable hand capture; managing failure cases with rare poses.
- Content moderation and benchmarking tools for generative MR
- Sectors: policy/tech governance, platform trust & safety
- Tools/products/workflows: Internal review tooling that flags potential failure cases (e.g., topological merging, misalignment) and adds content provenance/watermark metadata for SpriteHand-generated segments.
- Assumptions/dependencies: Integration with C2PA-like provenance; platform policies for synthetic content disclosures.
Long-Term Applications
These require further research, scaling, improved physical grounding, or hardware maturation (e.g., on-device inference for AR glasses).
- On-device MR for AR glasses and mobile without cloud
- Sectors: XR hardware/software, consumer electronics
- Tools/products/workflows: Lightweight SpriteHand variants (pruned/quantized, tiny autoencoders) running on mobile NPUs; real-time hand–object interactions for heads-up experiences.
- Assumptions/dependencies: More efficient models, hardware acceleration, improved battery/thermal budgets.
- Physics-aware action authoring and prototyping tools
- Sectors: software, game development, XR
- Tools/products/workflows: Hybrid pipelines where SpriteHand generates interaction previews and then automatically extracts constraints/rigs for game engines; semi-automatic conversion to physically simulatable assets.
- Assumptions/dependencies: Learning structural priors from data; reliable extraction of kinematics/topology from generated sequences.
- Robot learning from generative HOI “world models”
- Sectors: robotics, academia
- Tools/products/workflows: Use SpriteHand-like models to propose plausible non-rigid/articulated interactions for imitation learning, policy initialization, and domain randomization; closed-loop training with real-world validation.
- Assumptions/dependencies: Bridging sim-to-real gap; ensuring safety—visual plausibility ≠ correct dynamics.
- Digital twins of non-rigid assets for training and ops
- Sectors: manufacturing, logistics, energy/utilities (training), facilities
- Tools/products/workflows: Operator training modules with hand-reactive virtual surrogates for flexible components, gaskets, and covers; “what-if” rehearsals when accurate FEM models are unavailable.
- Assumptions/dependencies: Validation against ground truth; governance to avoid misuse for critical procedures.
- Tele-rehabilitation and at-home therapy gamification
- Sectors: healthcare (rehab, OT/PT)
- Tools/products/workflows: Exercises using virtual elastic/cloth objects that respond to patient hand motion; remote progress tracking via perceptual metrics.
- Assumptions/dependencies: Clinical validation; clear limits of biomechanical accuracy; privacy controls for egocentric video.
- Synthetic dataset generation for non-rigid and animal HOI benchmarks
- Sectors: academia, AI benchmarking
- Tools/products/workflows: Large-scale, diverse datasets to train/test models for hand pose, contact, and affordance understanding in complex materials and animal interactions; standardized benchmarks.
- Assumptions/dependencies: Bias management; curation and annotation tooling; agreement on evaluation protocols.
- Interactive product configurators with tactile proxies
- Sectors: retail/e-commerce, industrial design
- Tools/products/workflows: Let users “feel” how lids flip or fabrics drape via visual cues; future coupling to haptics for richer feedback in AR showrooms.
- Assumptions/dependencies: Enhanced material modeling; optional haptic hardware.
- Safety training for field technicians (utilities, manufacturing)
- Sectors: energy, industrial training
- Tools/products/workflows: Scenario rehearsals manipulating virtual covers, guards, or levers in live scenes, before touching live equipment; mixed-reality SOP walkthroughs.
- Assumptions/dependencies: Integration with enterprise safety platforms; strict disclaimers and validation; secure on-prem deployment.
- Human–animal interaction education and therapy aids
- Sectors: education, healthcare (mental health), entertainment
- Tools/products/workflows: Safe MR interactions with virtual animals (pet therapy simulations; classroom biology modules) that respond to gentle hand cues.
- Assumptions/dependencies: Content safeguards; addressing failure cases with rare poses; ethically sourced training data.
- Tooling for policy compliance: provenance, watermarking, and disclosure UX
- Sectors: policy/regulation, platform governance
- Tools/products/workflows: System-level controls that embed robust watermarks and C2PA provenance into streaming outputs; UI patterns for clear disclosure; audit logs for enterprise deployments.
- Assumptions/dependencies: Standardized provenance adoption; resilience against adversarial removal; cross-platform support.
- Multimodal extensions with haptics and audio
- Sectors: XR, gaming, accessibility
- Tools/products/workflows: Integrate tactile and audio feedback synchronized with generative hand-object events for richer MR; accessibility modes for users with low vision (audio-tactile cues).
- Assumptions/dependencies: Low-latency multimodal sync; hardware availability; extended model conditioning.
- Procedural content generation for games with dynamic props
- Sectors: gaming, XR
- Tools/products/workflows: Authoring tools where designers sketch hand gestures and the system proposes responsive prop behaviors (cloth banners, folding gadgets), then exports to engine-ready assets.
- Assumptions/dependencies: Better controllability and consistency; pipelines for converting generated behaviors into rigged assets.
- Privacy-preserving egocentric processing
- Sectors: policy/compliance, enterprise IT
- Tools/products/workflows: On-device hand masking, background anonymization, and strict data lifecycles for egocentric streams used by SpriteHand; differential privacy options for logs/metrics.
- Assumptions/dependencies: Efficient on-device segmentation; compliance with regional regulations (GDPR/CCPA/HIPAA as applicable).
Cross-cutting Assumptions and Dependencies
- Compute and latency: Reported real-time performance (~18 FPS, ~150 ms) requires an RTX 5090-class GPU; mobile/on-glasses deployment will need significant optimization or edge/cloud offload.
- Visual vs physical fidelity: Outputs are “physically plausible” but not guaranteed physically correct—especially for complex mechanisms, heavy occlusions, stacked objects, or rare animal poses (noted by authors).
- Input quality: Robustness depends on consistent hand visibility, reasonable lighting, and stable egocentric framing; hand segmentation/control video quality is a bottleneck.
- Data and bias: Performance is best on domains represented in training (non-rigid materials, articulated objects, common animal behaviors); out-of-distribution cases may degrade.
- IP and licensing: Use of static object images must respect rights; generated content should include provenance/watermarking where policies require disclosure.
- Safety and ethics: Do not use generative interactions as ground truth for safety-critical decisions or to control robots without additional validation and safeguards.
Collections
Sign up for free to add this paper to one or more collections.