Visual Sync: Multi-Camera Synchronization via Cross-View Object Motion
Abstract: Today, people can easily record memorable moments, ranging from concerts, sports events, lectures, family gatherings, and birthday parties with multiple consumer cameras. However, synchronizing these cross-camera streams remains challenging. Existing methods assume controlled settings, specific targets, manual correction, or costly hardware. We present VisualSync, an optimization framework based on multi-view dynamics that aligns unposed, unsynchronized videos at millisecond accuracy. Our key insight is that any moving 3D point, when co-visible in two cameras, obeys epipolar constraints once properly synchronized. To exploit this, VisualSync leverages off-the-shelf 3D reconstruction, feature matching, and dense tracking to extract tracklets, relative poses, and cross-view correspondences. It then jointly minimizes the epipolar error to estimate each camera's time offset. Experiments on four diverse, challenging datasets show that VisualSync outperforms baseline methods, achieving an median synchronization error below 50 ms.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
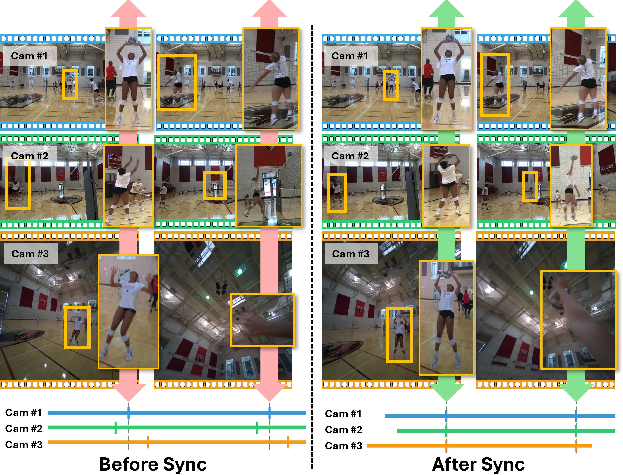
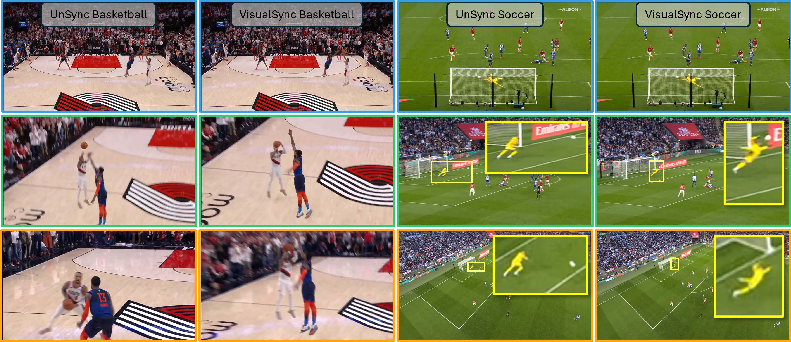
The paper introduces VisualSync, a method that makes separate videos of the same event line up in time, even if they were recorded on different cameras that didn’t talk to each other. Think of friends filming a volleyball game from different angles on their phones: the videos won’t start at the exact same moment. VisualSync figures out the tiny time shifts needed so that “the same moment” matches across all cameras.
The big questions the authors ask
- Can we sync multiple videos of the same moving scene without special equipment, loud claps, or manual adjustments?
- Can we do it accurately (within tiny fractions of a second) even when cameras are moving, scenes are messy, and the views look very different?
- Can we build a general tool that works on many types of scenes (sports, people, animals), not just one special case?
How the method works (everyday explanation)
The method uses a geometry rule from cameras called “epipolar geometry.” Here’s a kid-friendly picture of the idea:
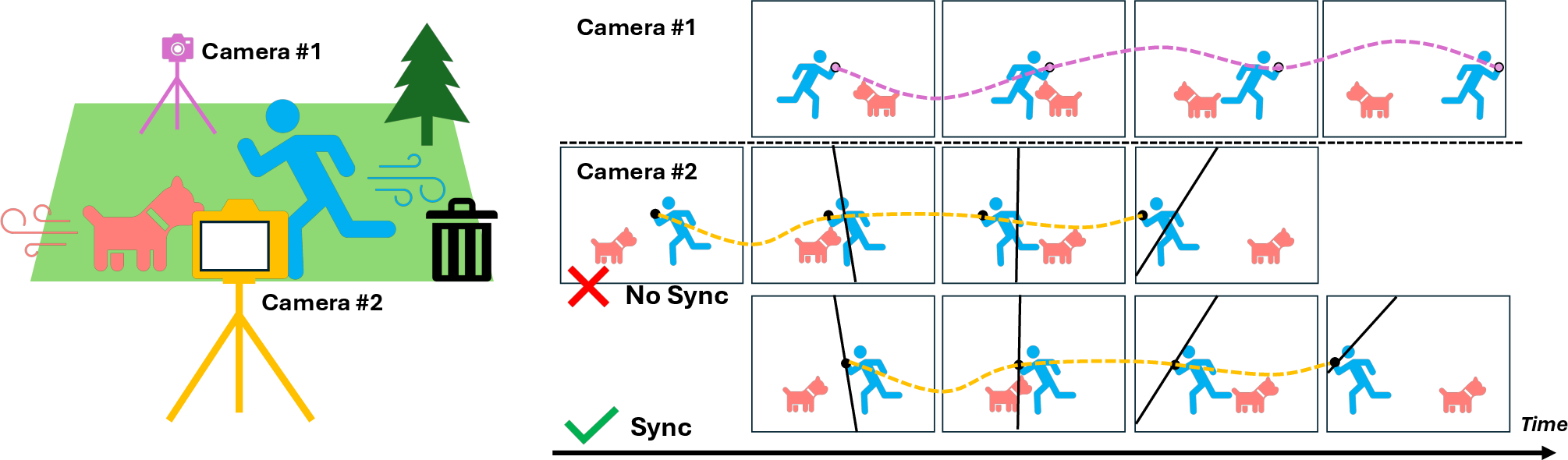
- Imagine you have two cameras filming a moving person. If both cameras are looking at the same exact moment, then a point on the person (like their hand) must appear in each camera in a very specific place that matches a line rule between the two cameras. You can think of it like “rails” (epipolar lines): when timing is correct, the point sits exactly on its rail in both camera views.
- If the videos are not time-aligned, that point won’t sit on the rail at the same time. It will look “off-track.”
VisualSync uses this idea to find the best time shift for each camera so that lots of tracked points across the videos sit on their rails at the same time.
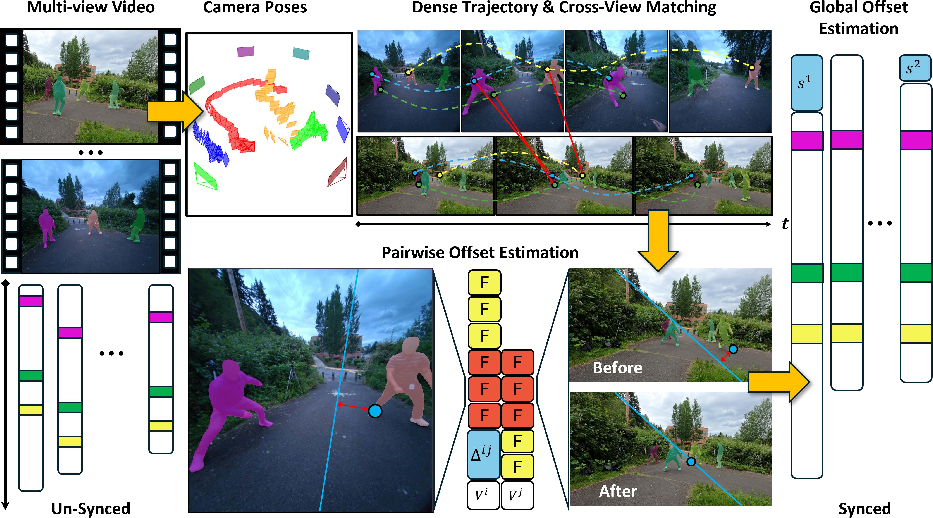
To make this practical on real videos, the system follows three main stages:
- Stage 0: Gather visual clues automatically
- It estimates where each camera is and how it’s pointing (camera geometry).
- It finds moving stuff in the scene (like people, balls, birds).
- It tracks many small points over time in each video (like tiny dots on clothes or objects).
- It matches which points in one camera correspond to the same real-world points in another camera.
- The authors use strong, ready-made AI tools for these steps (for example, trackers and matchers) so they don’t have to reinvent everything.
- Stage 1: Find the best time shift for each pair of cameras
- For each camera pair, try sliding one video forward/backward by small amounts (like testing many tiny delays).
- For each tested delay, measure how well the tracked points sit on their rails (the “rail fit” score). A special metric called the Sampson error tells how far a dot is from its matching line; smaller is better.
- Pick the delay with the lowest error for that pair.
- Stage 2: Make all cameras agree globally
- Now there are many pairwise time shifts (A vs. B, A vs. C, B vs. C, etc.).
- The system solves a “best overall” fit so each camera gets one final time offset that works consistently across all pairs, while ignoring noisy pair results. You can think of this as a careful “vote and adjust” process.
In short: VisualSync looks for time shifts that make moving points line up with the camera-geometry rules across all views.
What they found and why it matters
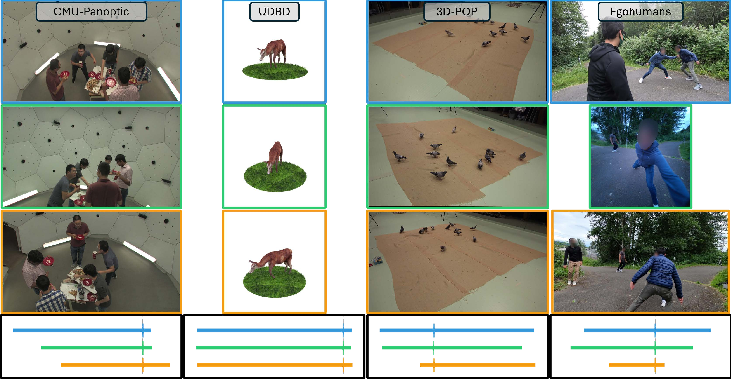
The authors tested VisualSync on several kinds of datasets:
- Human activities indoors with many cameras (CMU Panoptic).
- Sports scenes with head‑mounted and regular cameras (EgoHumans).
- Birds moving around (3D-POP).
- A synthetic (computer-made) set (UDBD).
Main results:
- VisualSync achieves very accurate timing—often better than 50 milliseconds (that’s 0.05 seconds). That’s good enough that fast motions (like a ball hit) look aligned across cameras.
- It works across tough situations: different camera angles, moving cameras, small moving objects, motion blur, and varying frame rates.
- It outperforms other recent methods that rely on different ideas (like only learning-based tricks or only depth/brightness matching).
Why this is important:
- Once videos are properly synced, you can do cool things:
- Make smooth “bullet-time” effects (jumping between camera views at the exact same moment).
- Build better 3D/4D reconstructions of dynamic scenes.
- Improve new-view video rendering (the paper shows that unsynced input looks blurry, but synced input looks sharp).
- Help sports analysis, film editing, and multi-camera security footage.
What this research could lead to
- Easier multi-camera editing: Fans, creators, and filmmakers can combine phone videos without claps or expensive gear.
- Better 3D/4D scene understanding: Syncing is a key step for building accurate moving 3D models from casual videos.
- Stronger vision tools: Other computer vision systems (like those that create new camera angles) work better when their input videos are aligned in time.
A simple way to remember it:
- VisualSync watches where moving points should be in each camera at the same moment.
- It slides videos until those points line up with the camera-geometry “rails.”
- When the rails line up for lots of points, the videos are synchronized.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future research.
- Identifiability conditions: What sufficient conditions (viewpoint overlap, number/distribution of dynamic points, camera motion types) guarantee that minimizing epipolar violations recovers the true offsets? Analyze degeneracies (planar scenes, pure rotations, points moving along epipolar lines, identical periodic motions) and design detectors or remedies.
- Rolling-shutter and timing models: How to extend the method to cameras with rolling shutter, line-by-line exposure, shutter skew, or per-frame timing jitter, where a single fundamental matrix per frame is inadequate?
- Time-varying intrinsics: The pipeline assumes fixed intrinsics; how to robustly handle zoom, focus changes, and lens distortion that vary within a clip, and propagate intrinsics uncertainty into synchronization?
- Non-constant offsets and clock drift: Cameras often exhibit drift, dropped frames, or variable frame pacing; develop models and solvers for piecewise or smoothly varying offsets si(t) rather than a single global Δ.
- Sub-frame accuracy: The pairwise search is discrete in frame units; specify and validate interpolation/refinement strategies (e.g., motion-model-based interpolation, continuous-time optical flow) that achieve true millisecond-level precision beyond the frame interval.
- Uncertainty-aware epipolar optimization: Incorporate uncertainty in pose, intrinsics, and tracklets into the Sampson error (e.g., covariance-weighted residuals, heteroscedastic noise models) rather than treating fundamental matrices and matches as deterministic.
- Principled spurious-pair filtering: Replace heuristic thresholds (energy-ratio, local minima count) with statistically grounded tests or learned reliability predictors (calibrated confidences from CoTracker/MASt3R) for selecting trustworthy pairs.
- Scalable pair selection: The O(N2) cost limits large-scale setups; devise active or geometry-aware strategies to select an informative sparse set of pairs (e.g., based on predicted overlap from rough poses) while maintaining global identifiability.
- Joint pose–time optimization: The method fixes camera geometry during synchronization; investigate alternating or joint optimization (e.g., EM-like procedures) to reduce coupling errors when pose estimates are imperfect or time-varying.
- Sparse or ambiguous dynamics: How to detect segments where dynamic cues are insufficient (heavy occlusion, tiny moving objects, repetitive textures) and adapt (e.g., defer to audio/IMU cues or static background constraints) to avoid misleading energy landscapes?
- Robust cross-view association: Cross-view tracklet matching in wide baselines and heavy motion blur remains brittle; develop multi-object, identity-consistent association that uses geometry, appearance, and temporal priors jointly.
- Cycle consistency and graph diagnostics: Beyond IRLS on pairwise offsets, enforce cycle-consistency constraints and use cycle residuals to identify inconsistent edges and diagnose graph connectivity issues.
- Automatic hyperparameter tuning: Provide methods to self-tune search ranges, step sizes, Huber δ, and filtering thresholds across scenes with different FPS, motion scales, and noise levels.
- Benchmarking on truly unsynchronized captures: Current evaluation uses synthetic offsets from cropped sequences; curate a benchmark with real, hardware-timestamped multi-camera videos, including clock drift and variable frame rates, to measure absolute accuracy and robustness.
- Robustness to minimal static background: Pose estimation relies on static regions; assess and improve performance in scenes with highly dynamic backgrounds (crowds, moving platforms) or low-feature environments.
- Multi-modal fusion: Explore principled integration of audio transients, IMU/gyro data, and device metadata to resolve ambiguities and accelerate synchronization when visual cues are weak or misleading.
- Efficiency improvements: Replace brute-force pairwise search with coarse-to-fine strategies (e.g., cross-correlation of epipolar residuals, learned offset predictors) and parallelized pipelines for practical large-N deployments.
- Degeneracy-aware regularization: Address cases where periodic motions induce multiple local minima; design regularizers or priors (e.g., temporal smoothness, event anchors) to break symmetry and stabilize optimization.
- Downstream impact quantification: Beyond qualitative K-Planes results, systematically measure how synchronization quality affects 4D reconstruction, novel-view metrics (PSNR/SSIM/LPIPS), and multi-view tracking accuracy.
- Reproducibility and dependence on foundation models: The pipeline leans on multiple large pretrained models (VGGT, DEVA, MASt3R, CoTracker, GPT/SAM); analyze sensitivity to model versions/domains and propose lighter, open alternatives or failsafes for broader reproducibility.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with the current VisualSync pipeline (Stage 0–2, offline), leveraging pretrained modules (VGGT, MASt3R, CoTracker3, DEVA) and robust global offset estimation (IRLS). Each bullet includes sectors, potential tools/workflows, and key assumptions/dependencies that affect feasibility.
- Media and entertainment (post‑production, VFX, broadcasting)
- Tools/products/workflows: NLE plugin for auto‑sync in Adobe Premiere/DaVinci Resolve; VFX bullet‑time assembly from phones; broadcast control‑room utility to align unsynchronized sideline and aerial feeds; cloud API for crowdsourced concert multi‑angle alignment.
- Assumptions/dependencies: Some temporal/viewpoint overlap and co‑visible dynamic motion; reasonable texture for matching; offline compute (hours for multi‑camera sequences); accuracy may degrade with extreme motion blur or minimal movement.
- Sports analytics and officiating
- Tools/products/workflows: Team analysis pipelines to align fan‑cams, coaching cameras, and broadcast feeds; officiating replay systems that unify angles for event timing (e.g., ball release/impact); highlight generation from user‑generated content.
- Assumptions/dependencies: Co‑visible player/ball motion across views; adequate frame rate; consistent playback speed; legal rights to ingest UGC.
- Surveillance, security, and forensics
- Tools/products/workflows: CCTV multi‑camera time alignment for incident reconstruction; forensic toolkits to synchronize citizen videos without audio claps/timecode; insurance claim video alignment (dashcams, storefront cameras).
- Assumptions/dependencies: Overlapping fields of view; at least some moving objects; chain‑of‑custody and privacy controls; static/dynamic camera pose estimation reasonably reliable.
- Education and training (lecture capture, lab demos)
- Tools/products/workflows: Multi‑angle lecture stitching without dedicated timecode; synchronizing lab apparatus recordings for experiment analysis; MOOC video creation from mixed devices.
- Assumptions/dependencies: Co‑visible dynamic cues (e.g., instructor gestures, moving objects); moderate viewpoint overlap; offline processing.
- Healthcare (operating rooms, procedural training, quality assurance)
- Tools/products/workflows: OR multi‑camera alignment for retrospective review; skills training modules with synchronized endoscope/room views; audit trail creation without hardware sync.
- Assumptions/dependencies: Privacy/compliance (HIPAA, GDPR); sufficient dynamic cues (staff movement, instrument motion); stable camera geometry; offline processing preferred.
- Robotics and drones (multi‑camera rigs lacking hardware sync)
- Tools/products/workflows: Align streams for SLAM/visual odometry when timecode fails; drone multi‑camera synchronization for inspection tasks; dataset curation for multi‑view model training (e.g., NeRF, K‑Planes).
- Assumptions/dependencies: Some moving features and static background for pose; moderate FPS; current pipeline is offline and O(N²) in camera count.
- Smart cities, transportation, and automotive
- Tools/products/workflows: Accident reconstruction via aligning traffic cameras and dashcams; public safety incident timeline creation; fleet camera datasets synchronized for analysis.
- Assumptions/dependencies: Legal data access; co‑visible vehicle/person motion; sufficient overlap; privacy considerations.
- Research/dataset curation (academia and R&D)
- Tools/products/workflows: Standard synchronization preprocessing for multi‑view dynamic datasets; improved inputs for novel‑view synthesis pipelines (e.g., K‑Planes), 4D modeling (NeRF variants), and multi‑view tracking; benchmark creation for synchronization evaluation.
- Assumptions/dependencies: Multi‑view coverage and motion; availability of pretrained models; reproducible pipelines and documented metrics.
- Consumer/social apps (daily life, events)
- Tools/products/workflows: Mobile app that invites friends to upload clips, auto‑synchronizes, and outputs multi‑angle remixes or “bullet‑time” effects for parties, birthdays, concerts.
- Assumptions/dependencies: Co‑visible subject; sufficient overlap; device permissions; feasible cloud/offline compute.
Long‑Term Applications
Below are use cases that become practical with further research, scaling, or development—e.g., real‑time constraints, reducing O(N²) cost, handling variable playback speeds, and broader systems integration.
- Real‑time/near‑real‑time synchronization for live broadcast and streaming
- Sector: Media, sports, live events
- Tools/products/workflows: Edge/on‑prem services that estimate offsets on the fly; integration into vision mixers; firmware‑level camera sync assist using cross‑view motion.
- Assumptions/dependencies: Reduced latency tracking/matching; efficient graph optimization (sub‑quadratic in cameras); robust to motion blur and rapid zoom; GPU/ASIC acceleration.
- Multi‑user AR/VR telepresence and shared 4D capture
- Sector: AR/VR, collaboration, education
- Tools/products/workflows: Align heterogeneous mobile streams to build real‑time shared 4D scenes; synchronized multi‑observer experiences in classrooms, sports, or concerts.
- Assumptions/dependencies: Low‑latency synchronization; privacy‑preserving cross‑view matching; strong network and compute; standardized uncertainty reporting.
- City‑scale camera networks and public safety platforms
- Sector: Smart cities, policy, public safety
- Tools/products/workflows: Platforms that synchronize dozens/hundreds of cameras during incidents; standardized evidence timelines combining citizen and municipal feeds.
- Assumptions/dependencies: Governance, privacy, legal frameworks; scalable, fault‑tolerant synchronization; robust in sparse motion and severe viewpoint differences.
- Cross‑modal sensor synchronization (video + IMU/LiDAR/radar)
- Sector: Robotics, autonomous vehicles, industrial inspection
- Tools/products/workflows: VisualSync extended to multi‑modal cues for full sensor alignment when hardware timecode is unreliable; improved data fusion quality.
- Assumptions/dependencies: New cross‑modal optimization terms; sensor calibration; consistent motion cues across modalities.
- Camera hardware and platform integration (“VisualSync inside”)
- Sector: Consumer/pro camera ecosystems
- Tools/products/workflows: Cameras/phones that opportunistically self‑synchronize across devices via visual motion cues; SDKs for OEMs.
- Assumptions/dependencies: On‑device tracking/matching; privacy‑preserving peer discovery; standards for inter‑device sync metadata.
- Large‑scale UGC aggregation for automatic 4D content creation
- Sector: Media platforms, creator tools
- Tools/products/workflows: Concert/sports platforms that ingest crowdsourced videos, auto‑sync, reconstruct dynamic scenes, and publish multi‑angle experiences or volumetric replays.
- Assumptions/dependencies: Rights management; heterogeneous camera quality; resilient sync under sparse overlap and occlusion.
- Medical devices and OR systems with built‑in visual synchronization
- Sector: Healthcare devices, regulatory
- Tools/products/workflows: Certified systems that continuously align endoscopic, overhead, and wearable cameras; standardized audit logs.
- Assumptions/dependencies: Regulatory approvals; verification against ground truth; deterministic performance guarantees.
- Policy and standards for synchronized multi‑source evidence
- Sector: Law, public policy, standards bodies
- Tools/products/workflows: Protocols to document synchronization uncertainty, provenance, and reproducibility; admissibility guidelines for courts and oversight agencies.
- Assumptions/dependencies: Transparent error metrics (e.g., median ms offsets, confidence); chain‑of‑custody practices; privacy and consent frameworks.
Cross‑cutting assumptions and dependencies
To maximize feasibility across the above applications:
- Co‑visible dynamic motion and some spatiotemporal overlap are required; performance degrades with minimal motion or extreme blur.
- Reliable camera pose estimation for at least a subset of views; extreme viewpoint differences and textureless scenes can hinder matching.
- Current pipeline is offline and O(N²) in camera pairs; scaling to real‑time or city‑scale requires algorithmic and systems engineering (e.g., graph sparsification, incremental sync).
- Not robust to variable playback speeds (e.g., slow‑motion segments interleaved with normal speed) without dedicated handling.
- Availability of pretrained visual foundation models (VGGT, MASt3R, CoTracker3, DEVA) and sufficient compute; privacy/legal constraints must be addressed for surveillance/UGC use.
Glossary
- AUC: Area Under the Curve; a summary metric over error thresholds. "We report the AUC for error thresholds at 100ms (A@100) and 500ms (A@500) respectively."
- Algebraic epipolar residual: The raw scalar residual from the epipolar constraint before geometric normalization. "Intuitively, the numerator is the squared algebraic epipolar residual, and the denominator sums the squared lengths of the two epipolarâline normals."
- Camera extrinsics: External camera parameters (pose: rotation and translation) describing the camera’s position and orientation in the world. "and the corresponding extrinsic trajectories."
- Camera intrinsics: Internal camera parameters (e.g., focal length, principal point) defining projection from 3D to 2D image coordinates. "Let denote the known (or estimated) intrinsics,"
- Chamfer distance: A symmetric distance between two point sets, often used to compare shapes or correspondences. "compute Chamfer distances between projected dynamic pixels."
- Covisible: Simultaneously visible in multiple camera views. "measures the misalignment error under this candidate offset in terms of the Sampson geometric error between associated tracklet pairs that are covisible between camera and ."
- Epipolar constraint: The relation that corresponding points in two images must satisfy under the correct geometry. "then the epipolar constraint holds:"
- Epipolar geometry: The two-view geometric relationships (epipolar lines, fundamental matrix) between cameras and scene points. "estimate temporal offsets using epipolar geometry,"
- Epipolar line: In one image, the line on which the correspondence of a point in the other image must lie. "When cameras are time-aligned, keypoint tracks align with epipolar lines (bottom);"
- Fundamental matrix: A 3×3 matrix encoding the epipolar geometry between two cameras. "where is the fundamental matrix between camera at time and camera at time ,"
- Homogeneous coordinates: Projective coordinates for points (with an extra scale dimension) used in multi-view geometry. "be a pair of matched 2D tracklets in homogeneous coordinates between cameras and ,"
- Huber loss: A robust loss that is quadratic near zero and linear for large residuals to reduce sensitivity to outliers. "where is the Huber loss."
- Iteratively Reweighted Least Squares (IRLS): A robust optimization method that solves weighted least squares with weights updated iteratively. "We solve this with an iteratively reweighted least squares (IRLS) procedure~\cite{daubechies2010iteratively}, yielding the final global synchronization offsets ."
- Neural Radiance Field (NeRF): A neural representation of scenes used for novel view synthesis via radiance field modeling. "Sync-NeRF incorporates temporal offsets into photometric optimization."
- RANSAC: A robust model fitting algorithm that iteratively samples data to estimate parameters while rejecting outliers. "which relies solely on dynamic tracklets and uses RANSAC to compute inlier matches as the pairwise energy metric."
- Reprojection error: The distance between observed image points and their projections from the estimated 3D model and camera parameters. "closely matching the true reprojection error, while remaining a fast and closedâform computation."
- Sampson error: A normalized first-order approximation of geometric point-to-epipolar-line distance used for efficient optimization. "Among various epipolarâerror measures, we adopt the Sampson error~\cite{hartley2003multiple, luong1996fundamental, sampson1982fitting, rydell2024revisiting},"
- Structure-from-Motion (SfM): Techniques that recover camera poses and 3D structure from multiple overlapping images or videos. "Structure-from-Motion (SfM) techniques~\cite{agarwal2011building, wang2024dust3r, schonberger2016structure, sweeney2015optimizing, oliensis2000critique, pollefeys2008detailed, snavely2006photo, wu2013towards}, such as COLMAP~\cite{schonberger2016structure}, have significantly advanced 3D reconstruction pipelines"
- Symmetric epipolar distance: A geometric error measuring point-to-epipolar-line distances in both images symmetrically. "We also evaluate three geometric energy termsâcosine error, algebraic error~\cite{lee2020geometric}, and symmetric epipolar distanceâwhich are detailed in \cref{para:other_energy}."
- Tracklet: A short temporal trajectory of a tracked point across consecutive frames. "to extract tracklets, relative poses, and crossâview correspondences."
- Triangulation: Recovering 3D point positions from their 2D projections across multiple views using known camera geometry. "Ground-truth camera poses are used to triangulate scene points and resolve per-image scale ambiguity."
Collections
Sign up for free to add this paper to one or more collections.