- The paper introduces a training-free method that recalibrates early, middle, and last global attention layers to achieve up to 8-10x inference speedup.
- It employs a two-step approach by converting early layers into frame attention and applying a grid-based subsampling strategy in middle layers for computational efficiency.
- Experimental evaluations and ablation studies demonstrate that the approach maintains or improves accuracy in multi-view 3D vision tasks while significantly reducing computational cost.
AVGGT: Rethinking Global Attention for Accelerating VGGT
Introduction
The paper "AVGGT: Rethinking Global Attention for Accelerating VGGT" (2512.02541) addresses the computational inefficiencies inherent in global self-attention models such as VGGT and π3, which perform notably in multi-view 3D vision tasks. Recognizing the computational burden posed by global attention, this paper proposes an acceleration strategy that relies on a nuanced understanding of how global attention layers contribute to multi-view reasoning. Through layer-wise analysis, the authors identify distinct roles for early, middle, and last global attention layers and introduce a training-free acceleration method that achieves substantial speedups without degrading performance.
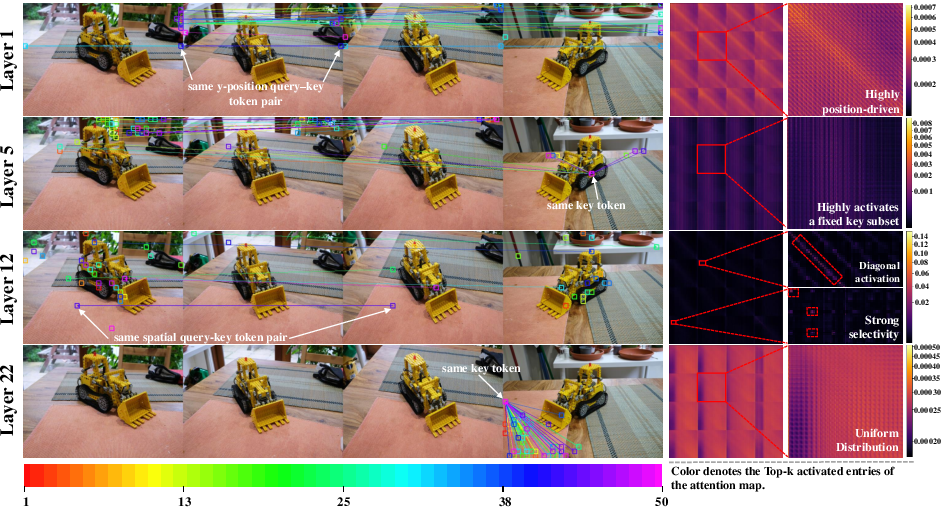
Figure 1: Camera pose estimation results highlight the efficacy of subsampling strategies in mitigating computational loads.
Analyzing Global Attention Dynamics
The analysis reveals three key findings regarding the roles of global attention layers:
- Early Layers: These do not significantly contribute to multi-view correlations, as features at this stage lack adequate 3D information necessary for forming meaningful correspondences. Attention at these layers tends to be uniformly distributed without distinct spatial patterns.
- Middle Layers: They perform substantial cross-view alignment by linking spatially corresponding tokens across different views. This phase is critical for establishing multi-view correlations.
- Last Layers: These offer only minor refinements to already aligned representations, indicating their reduced impact on further enhancing multi-view consistency.
These insights underpin the development of an acceleration mechanism that adapts the function of each layer to improve computational efficiency.
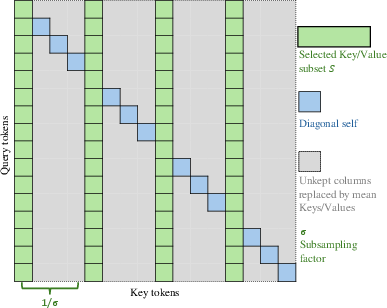
Figure 2: Subsampling strategy illustration, demonstrating the grid-based approach for token selection.
Methodology
Leveraging the layer-wise insights, the paper introduces a two-step acceleration scheme that requires no retraining:
- Global-to-Frame Conversion: Early global layers are converted into frame attention layers, reducing computational complexity by adapting the layout to process within frames independently.
- Subsampling Strategy: For middle layers, a subsampling approach is employed where selected key/value tokens are used based on a uniform grid, allowing the retention of correlating anchors necessary for alignment. This reduces unnecessary dense computations, achieving significant speedups.
Moreover, the strategy enhances subsampling by preserving diagonal interactions and approximating dropped tokens with a mean component.
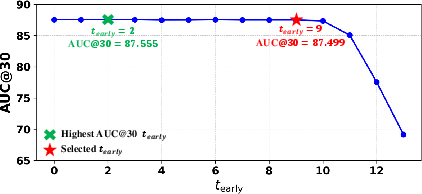
Figure 3: Impact of subsampling factor on performance.
Experimental Evaluation
Comprehensive experiments validate the proposed method across different datasets, demonstrating up to $8$-10× speedup in inference time while retaining, and in some cases improving, accuracy across pose estimation and point map benchmarks.
The experiments show:
- Consistent improvements over sparse-attention baselines, particularly in highly dense multi-view settings where computational costs historically surge.
- Robust performance validated through ablation studies, reinforcing the importance of middle layer alignment in maintaining accuracy while optimizing speed.
This efficiency emphasizes the practical impact of AVGGT in real-world applications requiring rapid multi-view processing.
Conclusion
The paper successfully elaborates on a training-free acceleration method informed by an analytical breakdown of VGGT global attention roles. By selectively recalibrating layer functions and employing intelligent subsampling, the method achieves impressive computational efficiency without compromising model efficacy. The evidenced practical acceleration holds promise for scalable deployment in resource-intensive 3D vision applications.
These findings not only challenge traditional model architectures but also drive future explorations into optimizing global attention mechanisms in transformer models tailored for advanced 3D perception tasks.