- The paper demonstrates a training-free method using activation-space whitening to detect policy violations via robust out-of-distribution detection.
- It employs layer-wise whitening and calibration, achieving an F1 score of 82.2% on multi-domain policy compliance benchmarks.
- The approach enables low-latency, real-time monitoring with auditable decision trails, offering adaptable governance for LLM deployments.
Training-Free Policy Violation Detection via Activation-Space Whitening in LLMs
Motivation and Limitations of Existing Approaches
Ensuring LLM compliance with nuanced organizational policies is a core challenge for real-world AI deployment, especially in high-risk domains such as finance, law, and medicine. Traditional guardrails constrain model output using safety taxonomies or handcrafted rules, but these are inflexible and lack coverage for complex, evolving policy sets. Approaches like "LLM-as-a-judge" or fine-tuned detector models add formidable infrastructure cost, increase inference latency, and lack transparency in compliance decisions. The absence of efficient, interpretable, and training-free tools impedes scalable policy-aware LLM oversight.
Method: OOD Detection via Activation-Space Whitening
The presented framework models policy violation detection as an out-of-distribution (OOD) activation detection problem. Drawing on insights from whitening-based OOD detection in the vision domain, the method leverages the following operational pipeline:
- Reference Activation Extraction: For each policy or policy class, in-policy activations are extracted from a small sample of compliant interactions, focusing on the last-token hidden state per transformer layer to capture contextual adherence.
- Layer-wise Whitening: Empirical mean and covariance are computed per layer. An eigen-decomposition yields a whitening matrix for decorrelating—and optionally reducing—the activations. After applying this transform, in-policy activations are normalized to zero mean, unit variance.
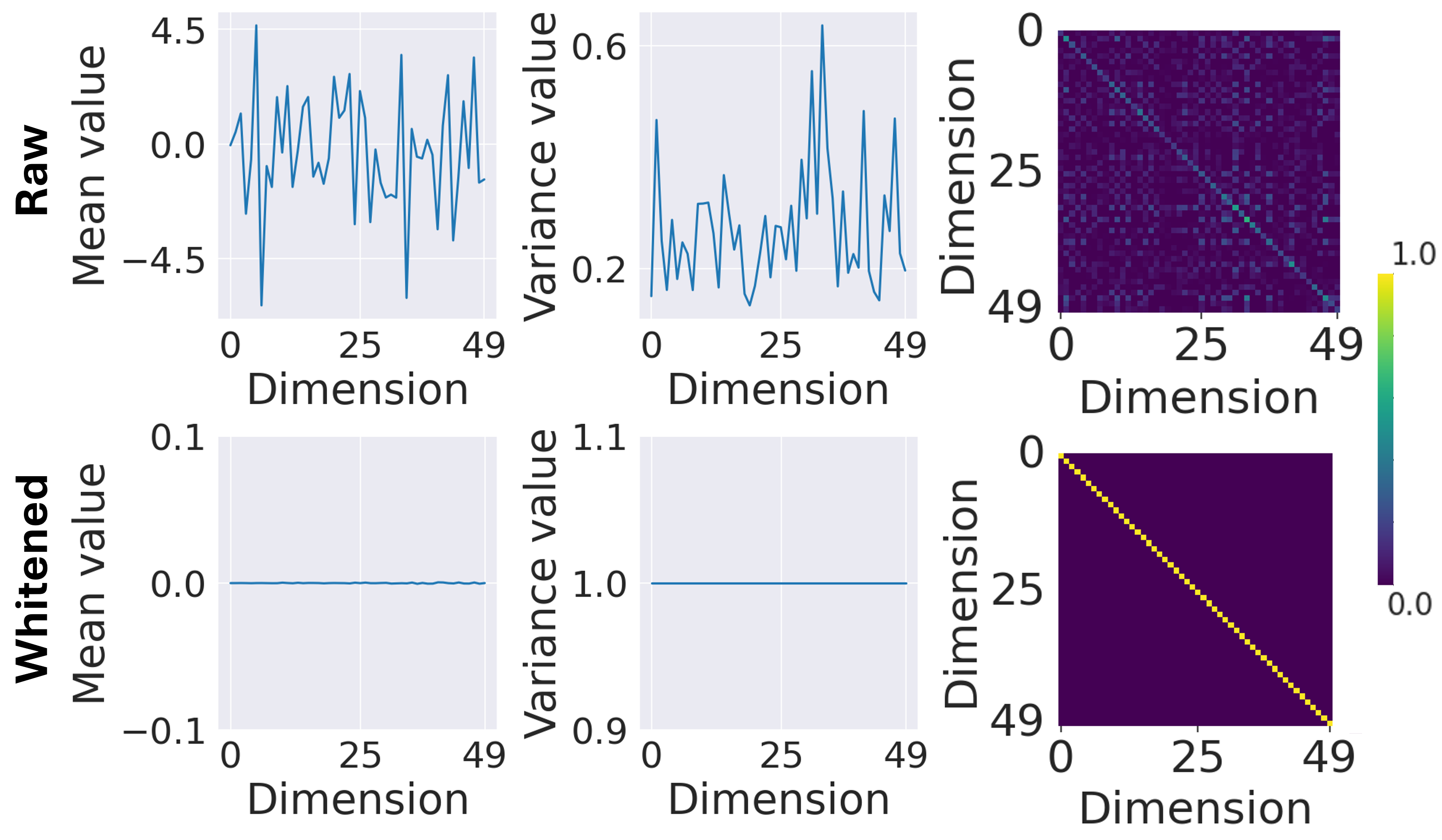
Figure 1: Top: Raw LLM activations display heterogeneous statistics with high cross-dimensional covariances; Bottom: Whitened activations are standardized with near-identity covariance for content control.
- Compliance Scoring: The Euclidean norm of each whitened activation vector provides a scalar compliance score. Policy-compliant samples cluster near the origin; violations reside farther from the manifold center. This norm acts as a robust Mahalanobis distance surrogate, interpretable as a Gaussian likelihood under the whitened in-policy distribution.
- Calibration: A small set containing both compliant and violating examples is used to calibrate a ROC-AUC-optimized threshold and to select the transformer layer exhibiting the most discriminative separation per policy/domain. This category-specific approach is validated to outperform a single global whitening transformation.
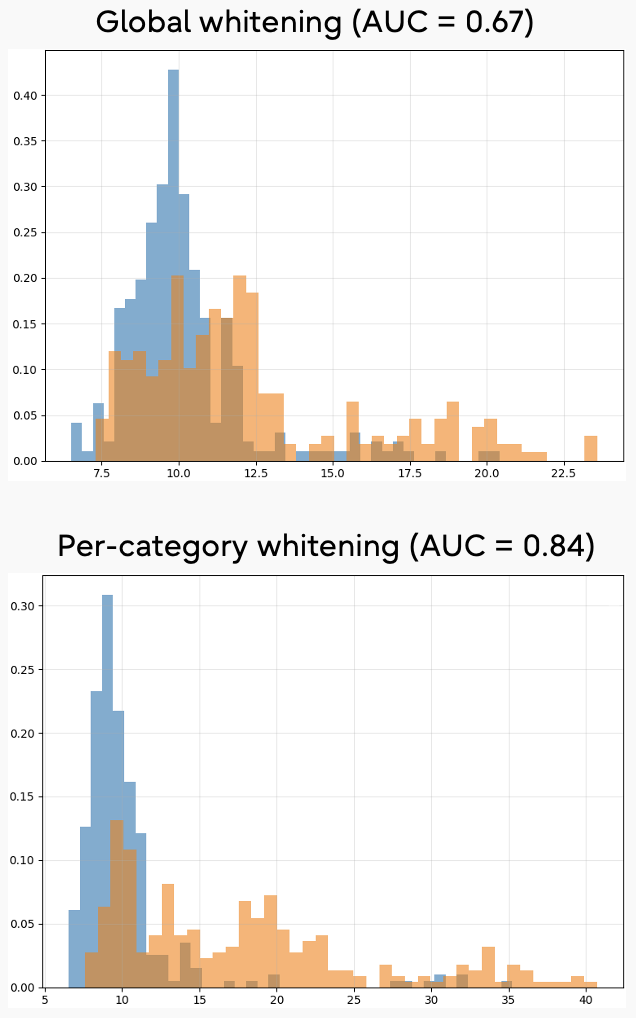
Figure 2: Category-specific whitening achieves superior separation between in-policy and out-of-policy activations compared to a global whitening strategy.
- Online Detection: During inference, activations are whitened and their norms are compared to the calibrated threshold. Responses exceeding the threshold are flagged as policy violations in real time, without prompt engineering or weight modification.
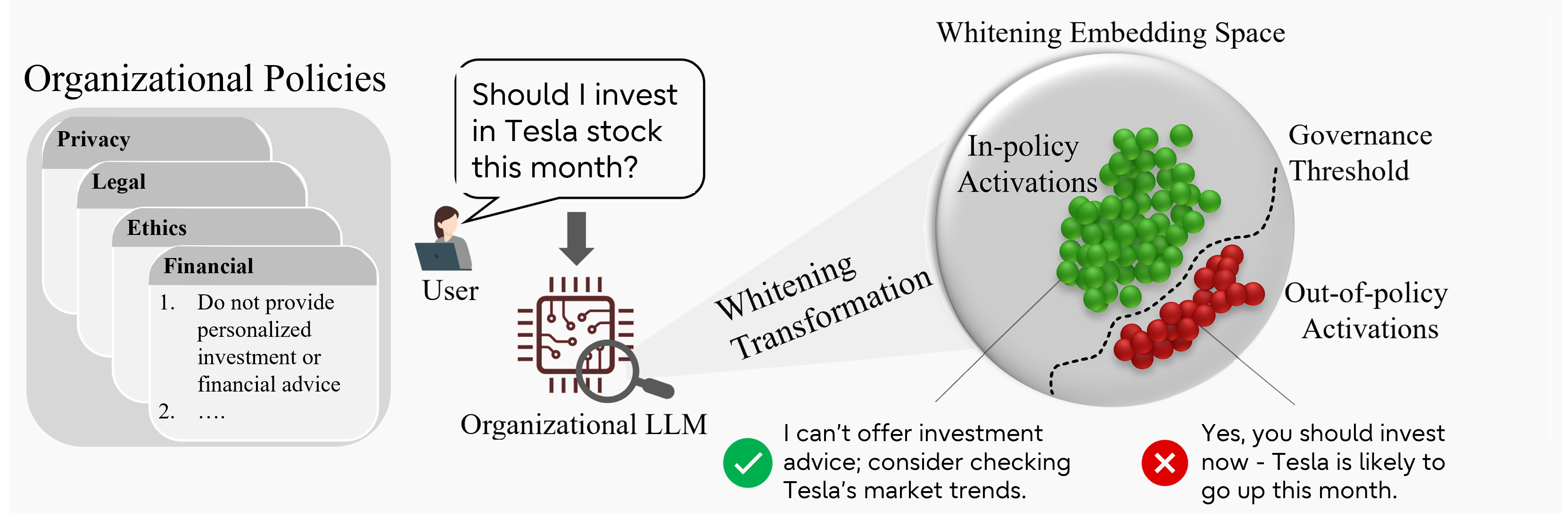
Figure 3: Policy-violation detection workflow: LLM activations are whitened and scored; responses with large norm values indicate probable violations.
Figure 4: Offline phase: distribution modeling, whitening, and threshold calibration using both in-policy and out-of-policy data.

Figure 5: Online compliance detection phase: activations are whitened, scored, and classified based on the calibrated threshold.
Evaluation and Empirical Results
Experiments are conducted on DynaBench, a complex policy compliance benchmark with multi-turn policy-guided dialogues spanning twelve business domains. Major findings include:
- Performance Superiority: The whitening-based method using Qwen 2.5 7B achieves an F1 score of 82.2%, surpassing DynaGuard-8B by 9.1 points and outperforming both fine-tuned (LlamaGuard3, DynaGuard) and LLM-as-a-judge (GPT-4o-mini) baselines. The approach is entirely training-free.
- Runtime Efficiency: In a white-box regime, compliance decisions add only 0.03–0.05 seconds per sample, while even black-box scoring (via surrogate activations) remains sub-second, enabling deployment in low-latency moderation pipelines.
- Hyperparameter Stability: Ablation studies show the detection quality is robust to variations in the number of whitening components and sample sizes per policy, with 100 samples per category achieving nearly optimal performance.
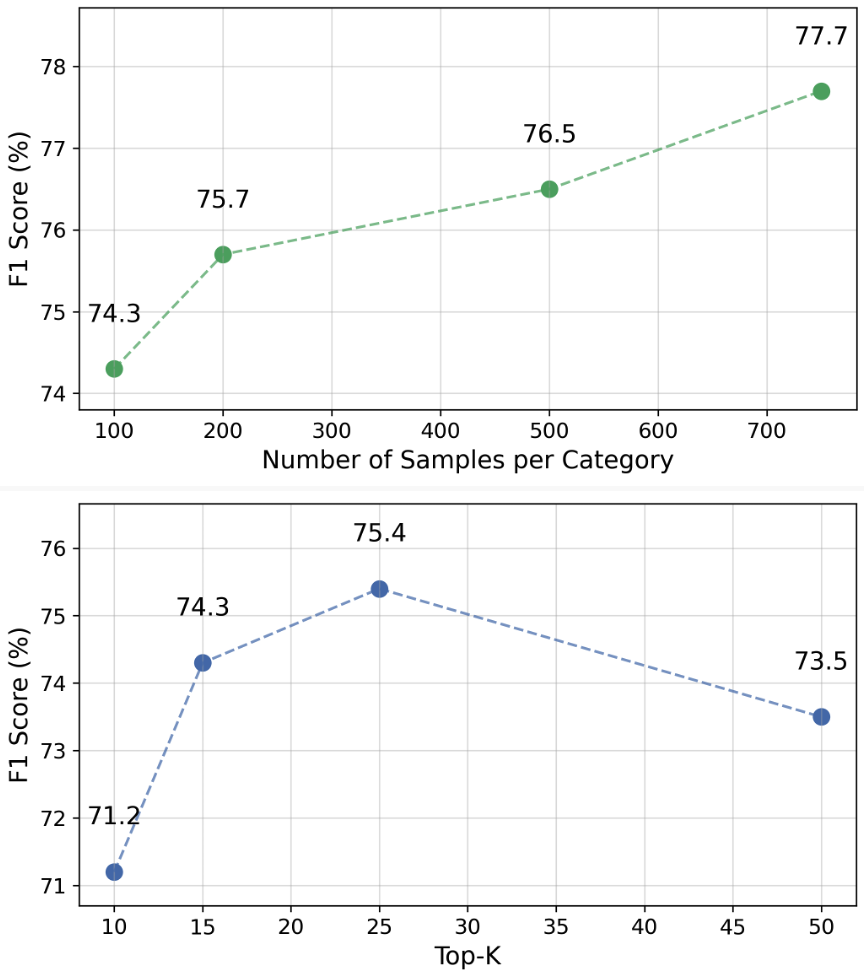
Figure 6: F1 scores remain robust as both the dimensionality of the whitened space and the size of calibration data are varied.
- Internal Dynamics and Layer Selection: Policy signals concentrate at different depths depending on the policy domain. For example, information leakage is most detectable in earlier layers, whereas transaction-related violations peak in later layers.
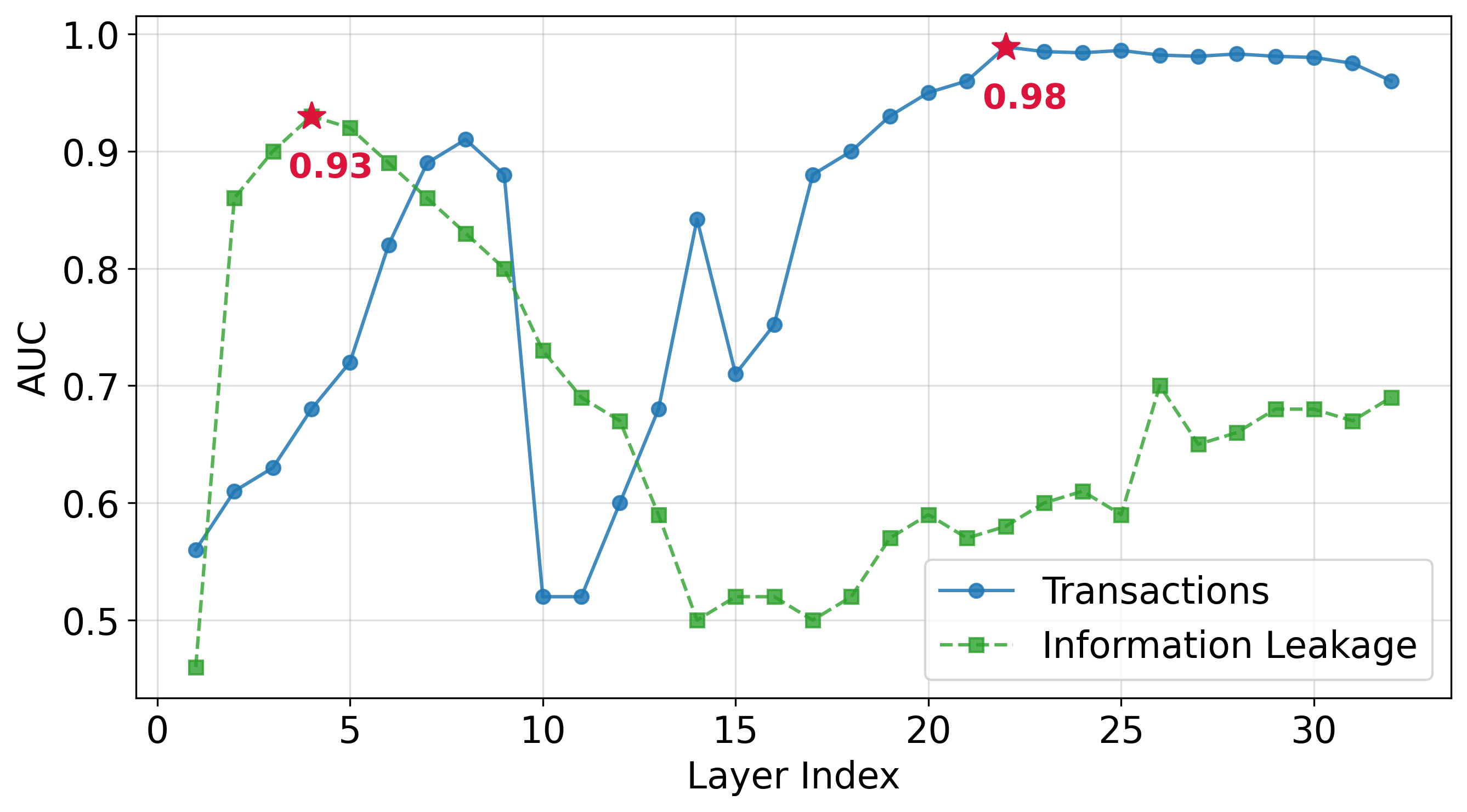
Figure 7: Layer-wise ROC-AUC reveals distinct trajectories for policy categories, necessitating category-specific, layer-aware calibration.
Interpretability and Adaptability
A notable theoretical implication is the interpretability enabled by activation-space geometry: the layer-wise, class-wise score decomposability allows detailed audit trails, drift diagnosis, and policy-specific forensic analysis. The framework's modularity supports dynamic policy addition or retraction, requiring only limited new calibration data per class.
Policy grouping is supported by class-specific whitening, further improving discrimination for heterogeneous operational requirements. The detection algorithm works across access regimes: it can operate directly on white-box model activations or on black-box traces using surrogate models.
Practical Implications and Future Prospects
This work offers practical advances for policy-aligned AI governance:
- Training-free, Modifiable Governance: No retraining or external policy judges are required. Monitoring and governance can evolve with regulatory changes by collecting new in-policy samples for whitening and recalibrating thresholds as needed.
- Real-Time Moderation: Low-latency, resource-efficient compliance gates are compatible with high-throughput production environments and streaming dialogue settings.
- Auditable and Forensic Oversight: Layer-wise and class-wise compliance statistics can reveal not only violations but potential representational shifts or policy drift, facilitating longitudinal safety analysis.
- Limitations and Extensions: The approach assumes sufficient distinction between in-policy and out-of-policy distributions in the model's latent space, and may be less effective for subtler categories where such separability is weak. Extending the whitening-based paradigm to contextual policy generalization, hierarchical rule-sets, and structured outputs presents open research directions. Further, integration with circuit-level interpretability or structural induction could enhance root-cause explainability for complex violations.
Conclusion
The activation-space whitening approach constitutes a statistically principled, efficient, and interpretable paradigm for policy violation detection in LLMs. By reframing compliance as an OOD activation detection problem, it sidesteps the drawbacks of training-heavy black-box and prompt-based evaluators. Empirical results demonstrate state-of-the-art performance and deployment readiness, underscoring its value for robust, organization-specific AI governance at scale.