- The paper introduces Stable Signer, a hierarchical end-to-end model that unifies text-to-gloss mapping, MoE-based pose generation, and diffusion-based video rendering for sign language production.
- It leverages the SLUL module with SAGM loss and dynamic SLP-MoE for robust semantic alignment and pose stability, reducing error propagation in traditional pipelines.
- Experimental results show a 48.6% improvement in BLEU-4 and 41.4% in ROUGE, evidencing significant performance gains over conventional SLP methods.
Stable Signer: A Hierarchical End-to-End Sign Language Generative Model
Motivation and Context
Existing Sign Language Production (SLP) pipelines decompose the generation problem into several sequential, independently trained stages: Text-to-Gloss, Gloss-to-Pose, and Pose-to-Video. While this modularization facilitated early progress, it introduces substantial error accumulation, temporal alignment problems between representations, and burdensome redundancies in intermediate steps. As shown in (Figure 1), correspondences between glosses and pose frames become increasingly misaligned, driving suboptimal averaging and instability in downstream video synthesis.

Figure 1: Sign Language Production pipelines typically rely on complex intermediate representations, which increase error accumulation and disrupt the semantic alignment between input text and rendered video.
Model Architecture Overview
To address these inefficiencies, Stable Signer proposes a hierarchical, end-to-end framework consisting of three main innovations:
- Sign Language Understanding Linker (SLUL): A unified T5-based Transformer module performing robust Prompt/Text-to-Gloss mapping, trained with Semantic-Aware Gloss Masking (SAGM) and contrastive objectives for increased semantic fidelity across disparate input forms.
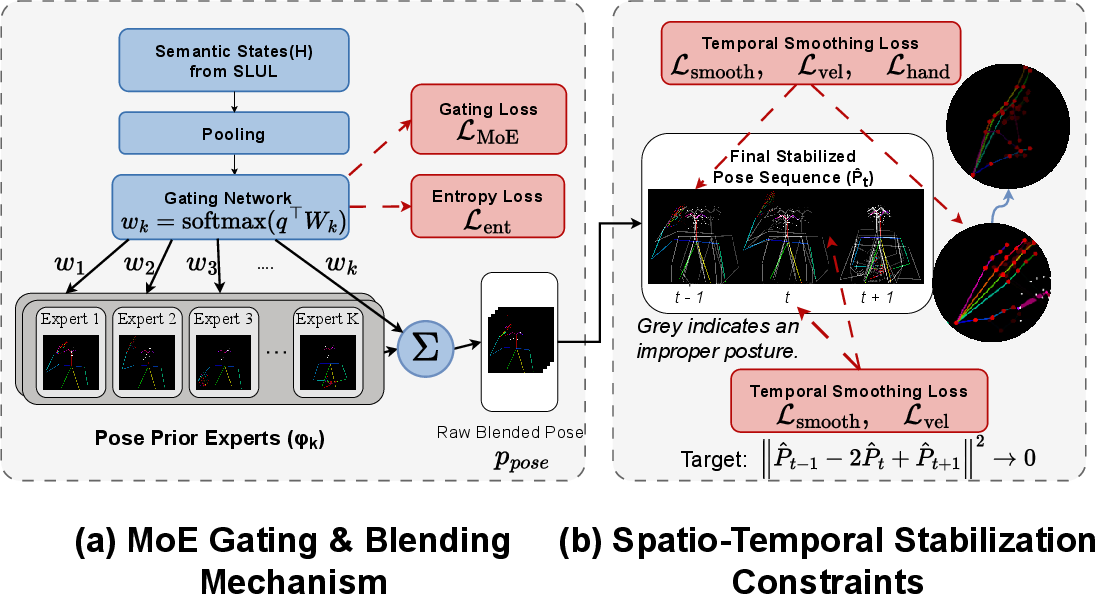
- Sign Language Production Mixture-of-Experts (SLP-MoE): A gated MoE architecture integrating rule-based pose priors, dynamically selected based on semantic features derived from SLUL, to generate temporally stable, spatially precise pose sequences from glosses.
- Pose-to-Video Diffusion Synthesis: A diffusion-based video renderer conditioned jointly on pose sequences and semantic features from SLUL, enabling style control and robustness to pose ambiguities.
The architecture eliminates intermediate gloss-pose misalignments, merges language understanding with video rendering in a tightly-coupled manner, and enforces stability and semantic integrity throughout the generative process.
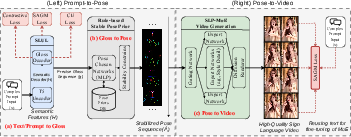
Figure 2: Pipeline overview: input text or prompt is mapped to glosses by SLUL, glosses are converted to stabilized pose sequences via SLP-MoE, and a diffusion model renders the full sign language video with style conditioning.
Semantic Understanding: SLUL and SAGM Loss
The SLUL module formulates Prompt/Text-to-Gloss as a sequence transduction problem, utilizing a T5 encoder-decoder backbone with language identifier prepending and cross-lingual semantic pooling. SAGM Loss is central: a random masking schedule on the gloss sequence forces the decoder to reconstruct gloss tokens from underdetermined semantic signals, while a KL divergence loss aligns masked and unmasked posterior distributions, explicitly regularizing the model to resist local gloss form noise and rare variations.
Contrastive pooling objectives further ensure that prompt and gloss embeddings from the encoder and decoder remain closely aligned in a shared vector space. The result is a mapping that robustly handles naturalistic, ambiguous, or noisy prompts far beyond the simplified settings of prior Text2Gloss models.
Gated Pose Generation: SLP-MoE
Given gloss and semantic state representations, SLP-MoE computes query vectors over a set of K pose experts, each corresponding to a rule-based pose sequence prior. The MoE gating mechanism enables:
Diffusion-Based Pose-to-Video Rendering
The resulting stabilized pose keypoints drive a video diffusion renderer (based on ControlNeXt/Wan), with semantic features from SLUL injected into the rendering pipeline. This enables both preservation of sign-specific motions and flexible stylistic adaptation. Conditioning at multiple abstraction levels allows for photorealistic synthesis with accurate manual and non-manual sign components, overcoming domain gaps and pose ambiguities found in multi-signer datasets.
Experimental Analysis
Numerical Results: Stable Signer yields 48.6% improvement in BLEU-4 and 41.4% in ROUGE over prior SLP systems on challenging datasets (e.g., How2Sign, WLASL). The system surpasses strong baselines, including transformer-based and diffusion SLP models, demonstrating not only superior overall scores but also consistent test-generalization, not merely overfitting to development data.
Ablation Studies reveal individual contributions: SLUL with SAGM loss alone realizes large performance gains in semantic mapping. SLP-MoE provides a further substantial improvement in video synthesis, with ablations confirming that gains are not merely due to better backbone architectures but emerge directly from the joint end-to-end structure.
Efficiency: Dynamic Time Warping (DTW) analyses show that SLUL and SLP-MoE accelerate convergence and reach lower minimal alignment errors compared to prior approaches. MoE-based training delivers more stable sequence outputs with fewer training epochs.
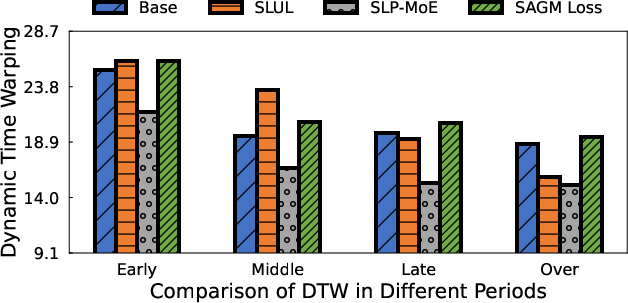
Figure 4: DTW-based efficiency comparisons demonstrate consistently faster convergence and better final sequence alignment for systems equipped with SLUL and SLP-MoE.
Qualitative results corroborate these outcomes. As visualized in (Figure 5), the model automatically learns clean, semantically-aligned pose targets absent from traditional pose extractors, realizes smooth temporal transitions, and generates final sign language videos exhibiting high fidelity and robust style transfer. Notably, Stable Signer eliminates the common pathologies of jitter, temporal misalignment, and gesture uncertainty prevalent in non-hierarchical approaches.

Figure 5: Visual evaluation of the full pipeline: (a) learned simplified poses, (b) intermediate pose video, (c) final photorealistic rendering, with ground-truth frames for reference.
Implications, Theoretical and Practical
Stable Signer challenges the conventional SLP modularization paradigm. By subsuming the entire pipeline into a hierarchical end-to-end objective, it partially resolves both error propagation and alignment pathologies, reconciling language understanding with pose stability at a fundamental level. This design enables direct optimization for both semantic accuracy (via cross-modal and contrastive objectives) and human perceptual metrics (via frame-level smoothness and hand precision losses).
Practically, this holistic approach expands the range of deployable SLP solutions, yielding outputs robust to gloss ambiguities, signer variability, and naturalistic prompts produced by Deaf and Hard-of-Hearing users. It substantially advances the feasibility of customizable, real-time, and stylistically controllable SLP video generation for assistive accessibility, education, and mediated communication contexts.
Theoretically, the adoption of hierarchical end-to-end training, dynamic pose prior selection, and semantic denoising losses provides a blueprint for tackling similar sequence-to-sequence multimodal generation problems where intermediate representations are both unstable and semantically ambiguous.
Future Directions
The joint optimization strategy and MoE conditioned rendering create avenues for expansion:
- Multilingual Generalization: Extending SAGM-based gloss conditioning and cross-lingual pooling for sign languages with varying grammar.
- Non-Manual Marker Integration: Incorporation of richer facial and body cues via multi-modal diffusion controls.
- Personalized/Supervised Adaptation: Style adaptation for individual signers and responsive, interactive SLP in streaming settings.
- Cross-Modal Retrieval and Evaluation: Leveraging the SLUL–MoE framework for sign video captioning and recognition via shared semantic representations.
Moreover, the foundation laid by Stable Signer in integrating rule-based priors, contrastive embedding alignment, and dynamic expert selection could generalize beyond SLP, particularly in complex human motion synthesis domains.
Conclusion
Stable Signer constitutes a significant step toward robust, accurate, and semantically coherent end-to-end sign language generation. By unifying language understanding and pose-conditioned video synthesis within a hierarchical generative model, and enforcing stability both in outcome and optimization, it sets a new benchmark for both quality and efficiency in the SLP field. Strong numerical results, corroborated by extensive qualitative and ablation evidence, highlight the system's capabilities and establish a template for multimodal hierarchical generation architectures in AI (2512.04048).