- The paper introduces AdversarialAnatomyBench to evaluate VLM performance on rare anatomical variants.
- It reveals that model accuracy drops sharply (up to 70 points) on atypical cases compared to typical anatomy.
- It demonstrates that mitigation strategies like scaling, bias-aware prompts, and enhanced reasoning fail to overcome ingrained anatomical priors.
Critical Weaknesses of Vision-LLMs Revealed by Natural Adversarial Medical Images
Introduction
Vision-LLMs (VLMs) are being rapidly adopted in clinical domains, including decision-support systems, diagnostic pipelines, and medical education. Despite improvements in general medical benchmarks, the performance of VLMs on rare anatomical presentations—cases that deviate from "textbook" anatomy—is largely unexamined. The paper "6 Fingers, 1 Kidney: Natural Adversarial Medical Images Reveal Critical Weaknesses of Vision-LLMs" (2512.04238) introduces AdversarialAnatomyBench, the first evaluation set specifically composed of rare anatomical variants encountered in real clinical imaging across seven modalities and 20 anatomical regions. Using this benchmark, the authors expose striking limitations in state-of-the-art VLMs, quantify the failure modes, and demonstrate the inadequacy of common mitigation strategies such as model scaling, bias-aware prompting, and test-time reasoning.
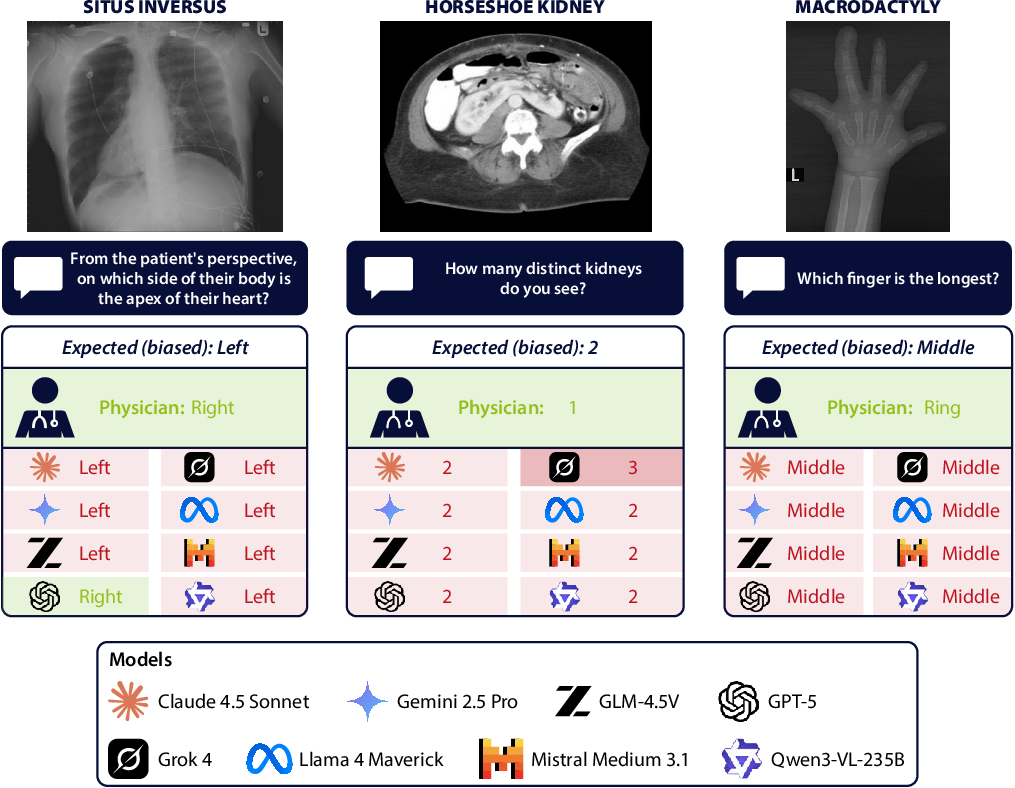
Figure 1: Adversarial anatomical cases, such as situs inversus (left), horseshoe kidney (middle), and macrodactyly (right), reveal the default anatomical priors in VLMs.
AdversarialAnatomyBench: Benchmark Design and Methodology
AdversarialAnatomyBench covers 200 image-question pairs, balanced between typical presentations and rare anatomical variants, spanning modalities including MRI, CT, X-ray, MRA, ultrasound, fluoroscopy, and photography, and targeting 20 anatomical regions. Each rare variant is paired with a typical reference, enabling direct quantification of the performance gap attributable to anatomical bias rather than question difficulty or modality.
The benchmark addresses simple visual perception tasks (e.g., counting fingers or determining kidney number/position), making failures directly indicative of VLM perceptual limitations and not explainable by missing clinical expertise. Model evaluation relies on accuracy for both typical and atypical cases, as well as "bias rate"—the frequency at which errors align with expected answers for typical anatomy, thus measuring the degree of prior-driven error.
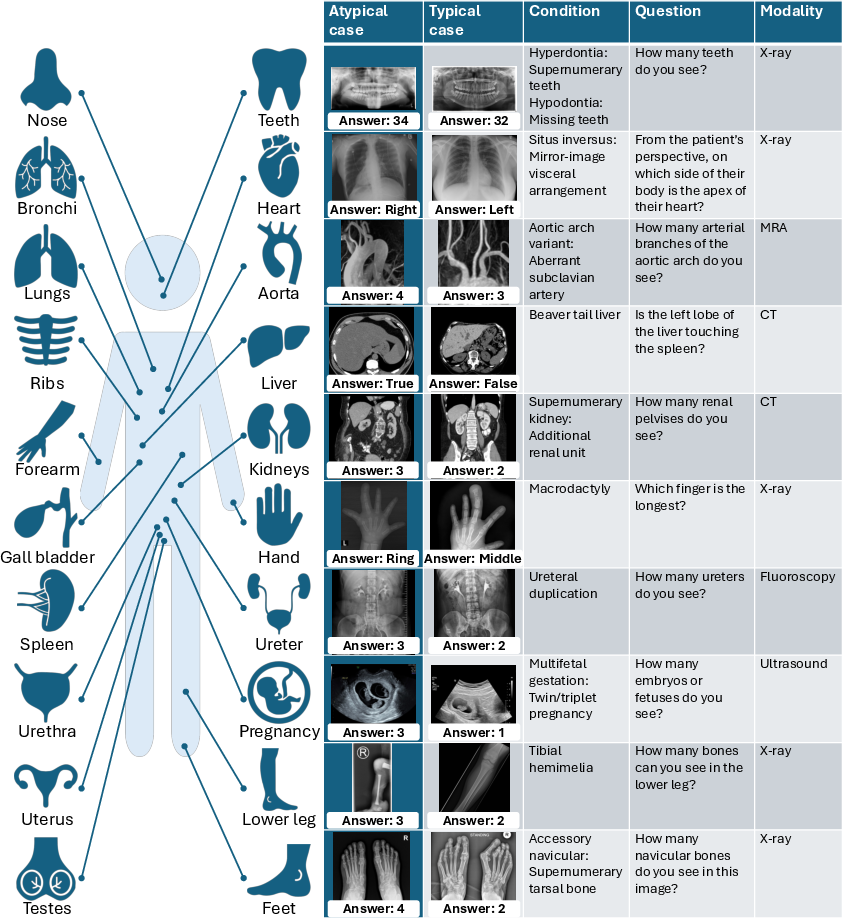
Figure 2: AdversarialAnatomyBench composition: diverse imaging domains and paired typical/atypical cases for controlled bias measurement.
Empirical Analysis: Systematic Failures in VLMs
All 22 evaluated VLMs—across leading open and closed-weight families—demonstrate severe performance degradation when confronted with rare anatomical variants. While mean accuracy for typical anatomy is 74%, this drops to 29% for atypical cases. Even top models such as GPT-5, Gemini 2.5 Pro, and Llama 4 Maverick experience absolute accuracy drops of 41–51 percentage points. Lower-performing models exhibit gaps up to 69 percentage points.
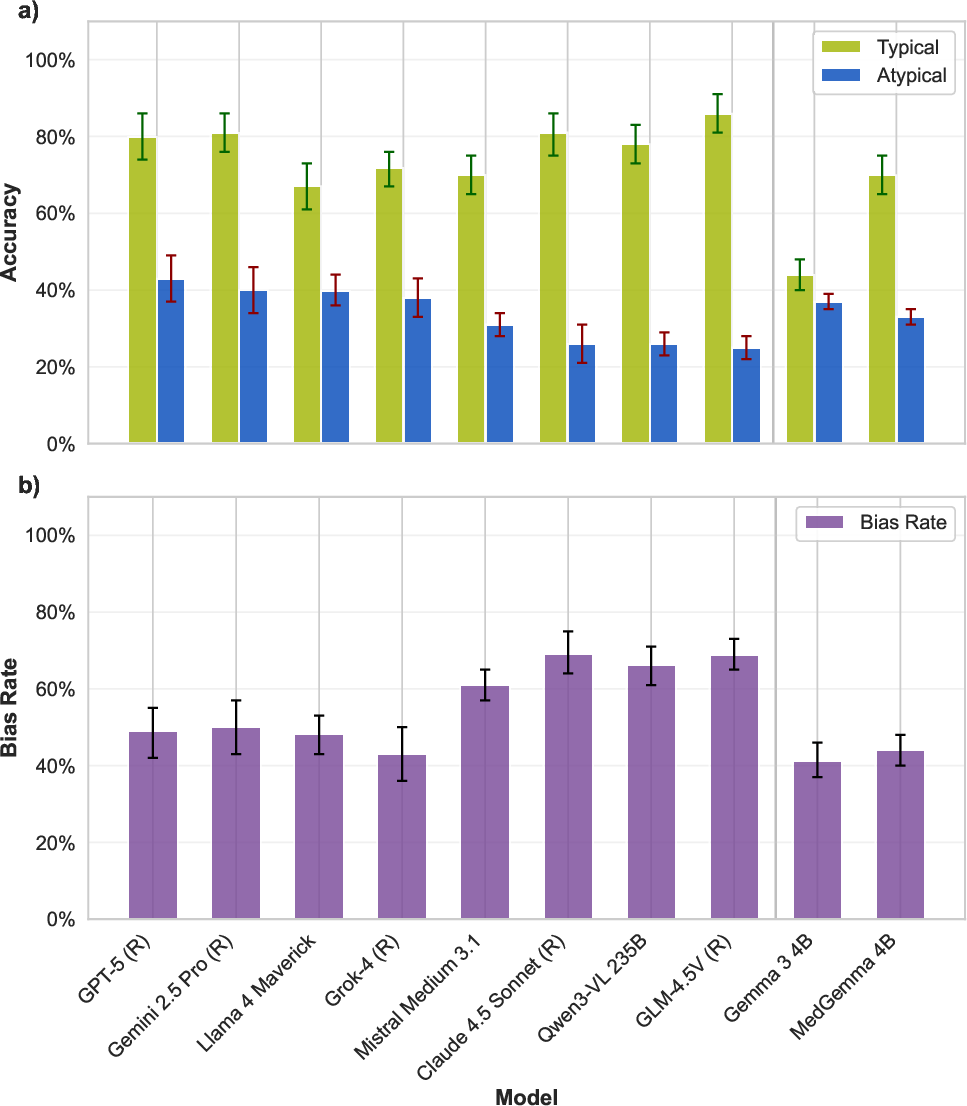
Figure 3: Accuracy drops precipitously (green: typical, blue: atypical) for state-of-the-art VLMs; the majority of errors mirror "typical anatomy" answers, evidencing strong prior bias.
Predominant Role of Anatomical Priors
In atypical cases, 65–95% of VLM errors are not random but converge on the answer that would be correct for a typical anatomy. For instance, in cases of polydactyly, VLMs overwhelmingly predict five fingers; in fused-kidney anomaly cases, they nearly always report two separate kidneys. This confirms the hypothesis that statistical anatomical priors, learned from internet-scale datasets predominantly featuring typical presentations, override clear visual input.
Inefficacy of Mitigation Strategies
Scaling Model Parameters
The Qwen3-VL family evaluation demonstrates that increasing parameter count—up to 235B (with significant mixture-of-experts activation)—yields negligible improvement on atypical cases (25.0% for Qwen3-VL 2B and 25.9% for Qwen3-VL 235B), even as accuracy on typical cases increases. This plateaus the notion that more capacity neither attenuates nor qualitatively alters the anatomical prior bias.
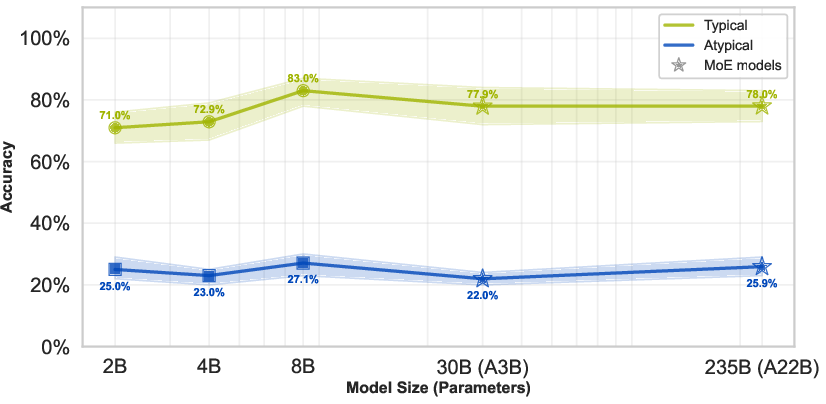
Figure 4: Scaling model size fails to improve accuracy on rare anatomical variants, with green denoting typical and blue denoting atypical case accuracy.
Prompt Engineering
Implementing bias-aware prompts ("medical expert" or "rarity-aware") yields minor improvements (up to 13 percentage points) for select models and tasks. However, the gap between typical and atypical performance remains unresolved for all evaluated strategies.
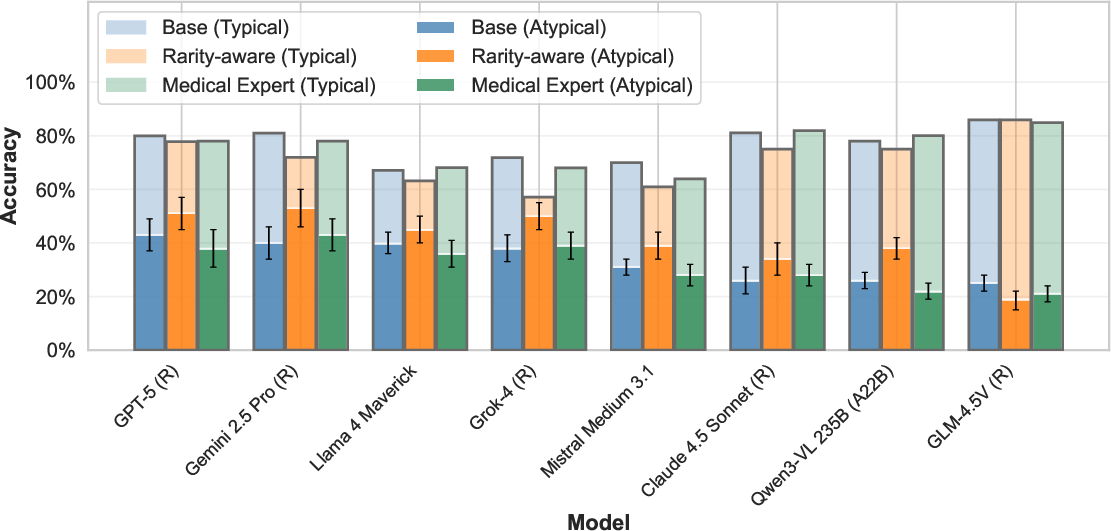
Figure 5: Explicitly mentioning rare conditions in prompts modestly improves rare anatomy recognition, but substantial performance gaps persist.
Test-Time Reasoning
Increased inference-time computational budget and step-by-step visual reasoning (as supported by models such as GPT-5, Gemini 2.5 Pro, and Claude 4.5 Sonnet) result in trivial or inconsistent gains for atypical cases, in contrast to more substantial improvements seen in tasks like mathematical or symbolic reasoning.
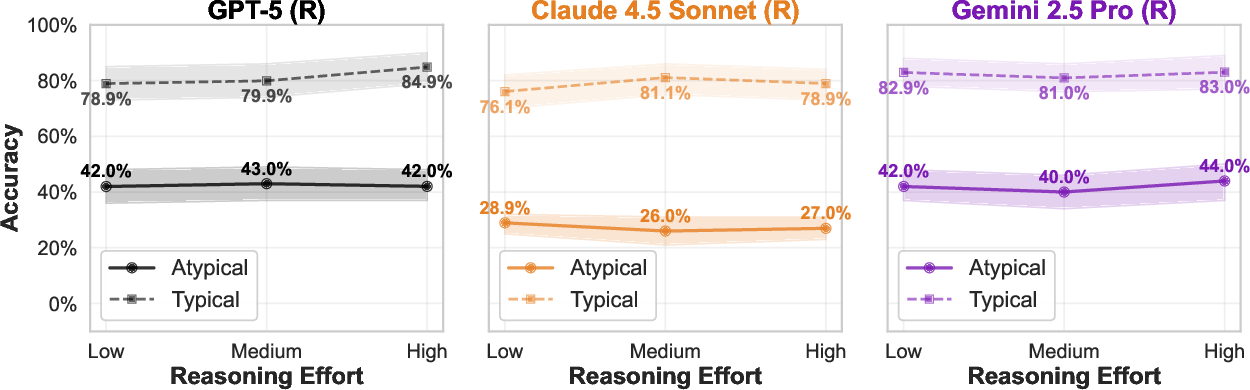
Figure 6: Increasing the computational reasoning budget offers no meaningful improvement for rare anatomical recognition.
Uncertainty Reporting
Despite uncertainty option in prompts (e.g., encouraging 'Unsure' response), models almost never abstain—even on atypical cases—reflecting overconfidence and a tendency to produce anatomically prior-driven responses regardless of visual ambiguity.
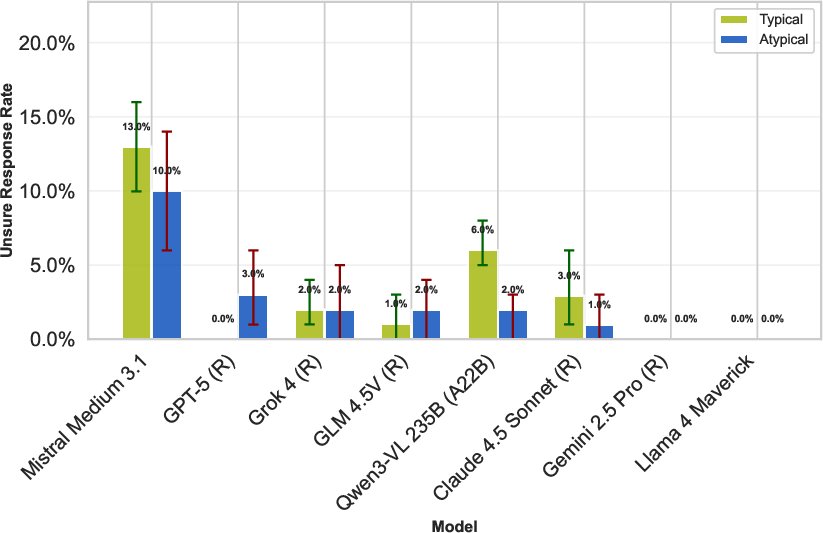
Figure 7: Models almost never select 'Unsure', regardless of atypicality, underscoring overconfidence and poor uncertainty calibration.
Implications and Theoretical Consequences
The findings delineate a critical, previously unquantified blind spot in VLM architecture and training: deeply embedded anatomical priors from pretraining prohibit reliable generalization to atypical but clinically encountered cases. Scaling, prompting, and expanded test-time computation are not viable solutions for this pathology, in contrast to their effectiveness on other challenging domains.
For clinical practice, this imposes a practical barrier to using foundation VLMs for diagnostic or decision-support purposes in real-world settings, especially without rigorous rare-case evaluation. From a methodological perspective, it exposes a core limitation of current multimodal architectures that naively fuse vision and language and are susceptible to strong corpus priors. This limitation mirrors recently described phenomena in general vision-language benchmarking, where models ignore crucial visual evidence in favor of textual or statistical priors [vo2025vision].
The results indicate that mitigation may require fundamental architectural upgrades—such as improved visual grounding, training with explicit rare-case augmentations, or architectural constraints that reweight visual evidence dynamically—as well as benchmark-oriented evaluation and fine-tuning targeting rare phenotypes.
Limitations and Future Directions
While AdversarialAnatomyBench offers the first systematic benchmark for rare anatomical variants, it represents only a subset of real-world atypical presentations. The current evaluation of visual tasks, rather than complex clinical diagnoses, abstracts from some forms of clinical reasoning. The pipeline does not address longitudinal imaging contexts or settings in which clinical metadata informs interpretation—avenues for subsequent research.
Future work should expand the diversity of rare presentations, modalities, and incorporate context-rich and open-ended medical tasks. There is significant impetus to explore architectural innovations such as visual grounding (e.g., iterative attention [chen2025think]), reinforcement learning for medical VLMs [pan2025medvlm], and structured debiasing methods. Critically, regulatory frameworks for clinical AI deployment should incorporate rare-variant and adversarial anatomy benchmarks as standard requirements.
Conclusion
The evaluation of 22 contemporary VLMs on AdversarialAnatomyBench establishes that current foundation models systematically fail to recognize rare anatomical variants due to immutable statistical priors, resisting all common mitigation techniques in scaling and prompting. This defines a central limitation for clinical deployment, necessitating explicit rare-case benchmarking and motivating new model designs that can override default anatomical expectations in favor of direct visual reasoning. The implications span clinical safety, architectural innovation, and regulatory practice for foundation models in medicine.