TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows
Abstract: Recent advances in large multi-modal generative models have demonstrated impressive capabilities in multi-modal generation, including image and video generation. These models are typically built upon multi-step frameworks like diffusion and flow matching, which inherently limits their inference efficiency (requiring 40-100 Number of Function Evaluations (NFEs)). While various few-step methods aim to accelerate the inference, existing solutions have clear limitations. Prominent distillation-based methods, such as progressive and consistency distillation, either require an iterative distillation procedure or show significant degradation at very few steps (< 4-NFE). Meanwhile, integrating adversarial training into distillation (e.g., DMD/DMD2 and SANA-Sprint) to enhance performance introduces training instability, added complexity, and high GPU memory overhead due to the auxiliary trained models. To this end, we propose TwinFlow, a simple yet effective framework for training 1-step generative models that bypasses the need of fixed pretrained teacher models and avoids standard adversarial networks during training, making it ideal for building large-scale, efficient models. On text-to-image tasks, our method achieves a GenEval score of 0.83 in 1-NFE, outperforming strong baselines like SANA-Sprint (a GAN loss-based framework) and RCGM (a consistency-based framework). Notably, we demonstrate the scalability of TwinFlow by full-parameter training on Qwen-Image-20B and transform it into an efficient few-step generator. With just 1-NFE, our approach matches the performance of the original 100-NFE model on both the GenEval and DPG-Bench benchmarks, reducing computational cost by $100\times$ with minor quality degradation. Project page is available at https://zhenglin-cheng.com/twinflow.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces TwinFlow, a new way to make image-generating AI models create pictures in just one step instead of dozens or even a hundred steps. It’s designed to be simple, fast, and to work well even on very large models, like those with 20 billion parameters.
Why does this matter?
Many top image and video generators (like diffusion or flow-based models) need 40–100 tiny steps to produce a single image. That makes them slow and expensive to run. TwinFlow aims to cut that down to 1–2 steps while keeping quality high, which can make creative tools faster, cheaper, and easier to use at scale.
What questions were the researchers trying to answer?
- Can we train a model to generate high-quality images in just one step?
- Can we do this without using extra “helper” networks (like GAN discriminators) or a frozen “teacher” model (distillation), which make training unstable or memory-hungry?
- Can this approach work on very large models and keep up with the quality of the original many-step versions?
How does TwinFlow work? (Explained with simple ideas)
Think of turning random noise into a picture like guiding a ball down a path from “noise land” to “picture land.”
- In traditional systems, the ball takes many tiny steps, carefully guided each time.
- TwinFlow tries to “straighten the path,” so the ball can jump directly to the picture in one big step.
Here’s the key idea, using an everyday analogy:
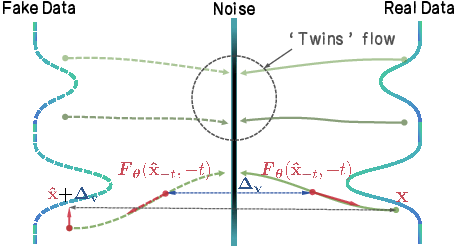
- Two paths from the same start: TwinFlow creates two “twin” paths from noise:
- The “real” path (moving forward in time) goes from noise to real images.
- The “fake” path (moving backward in time) goes from noise to images the model itself produced.
- Match the directions, not just the destination: At many points along these paths, TwinFlow looks at the “direction arrows” (think of them as GPS arrows showing where to move next—this is what the paper calls the “velocity field”). It teaches the model to make the arrows on the fake path match the arrows on the real path.
- Self-adversarial learning: Usually, models rely on a separate “critic” network (like in GANs) to tell them what’s good or bad. TwinFlow avoids that. Instead, the model compares its own fake path to the real one and learns to correct itself—like practicing against your own past mistakes.
Put simply: TwinFlow trains the model to make the straightest, most direct route from noise to a good image by aligning the “directions” of two mirror-image paths. That’s why it can jump in one big step.
What about the technical terms?
- “Velocity field” = the direction and speed the model thinks it should move to turn noise into an image.
- “Twin trajectories” = the two mirror-image paths (forward to real data, backward to the model’s own samples).
- “Self-adversarial” = the model challenges and corrects itself without using an extra critic network.
- “1-NFE” (Number of Function Evaluations) = one step to generate an image.
What did they find?
The team tested TwinFlow on both dedicated text-to-image models and very large, general image models. Highlights:
- On standard text-to-image tests, TwinFlow achieved a GenEval score of about 0.83 in just 1 step, beating strong baselines like SANA-Sprint (which uses a GAN-style loss) and RCGM (a consistency-style method).
- On a huge 20-billion-parameter model (Qwen-Image-20B), TwinFlow reached almost the same quality with 1–2 steps as the original model did with 100 steps:
- 1 step: GenEval ≈ 0.86 and DPG-Bench ≈ 86.5%
- Original 100 steps: GenEval ≈ 0.87 and DPG-Bench ≈ 88.3%
- That means up to about 100× faster image generation with only a small quality drop.
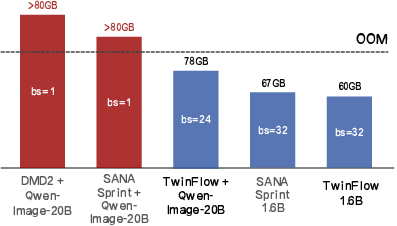
- Training is simpler and more stable: TwinFlow doesn’t need extra networks or a frozen teacher model, so it uses less GPU memory and avoids common training headaches.
Why is this important?
- Faster and cheaper: One-step generation cuts compute costs dramatically. That makes big models more practical for real-world use.
- Scales to very large models: TwinFlow’s simple design fits massive models without running out of memory.
- Stable training: No extra discriminators or teacher models needed, reducing complexity and instability.
- Better user experience: Faster image generation can enable real-time creative tools, mobile deployment, and lower-energy systems.
Key terms in plain language
- Diffusion/flow models: Methods that create images by gradually turning noise into a picture through many small steps.
- NFE (Number of Function Evaluations): How many steps it takes to generate an image; fewer is faster.
- Distillation: Teaching a small or fast model to copy a bigger, slower model (often needs a frozen teacher).
- Adversarial training (GANs): A generator makes images while a discriminator tries to spot fakes; powerful but can be unstable and memory-heavy.
- Velocity field: The model’s idea of which direction to move next to go from noise toward a real image.
Bottom line
TwinFlow shows a way to get high-quality images in one step, without extra helper networks or teachers, and it works even on very large models. This could make advanced image generation much faster, cheaper, and easier to deploy—bringing high-quality creative AI closer to everyday use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces TwinFlow for one-step/few-step generation without auxiliary networks or frozen teachers. While results are promising, several aspects remain uncertain or unexplored:
- Theoretical guarantees
- Lack of convergence analysis: no proof that minimizing the velocity-field difference guarantees convergence to the real data distribution, especially when the “fake” trajectory is derived from the model’s own predictions.
- Unclear conditions under which the velocity-matching objective avoids degenerate solutions (e.g., trivial equal-but-wrong velocities) without external supervision.
- The score–velocity relationship and KL-gradient derivation are shown for linear transport; it is not established whether the claims extend to other transports or noise schedules, including the use of negative time inputs.
- Numerical stability and weighting
- Potential numerical instability near t→0 (derivations include 1/t terms) is not addressed; no reweighting, clipping, or curriculum described to mitigate singularities around t=0.
- The role and optimal setting of the balancing hyperparameter
λ(batch partition between base and TwinFlow losses) is not systematically characterized; no guidance on adaptive scheduling or robustness across datasets and scales. - No ablation on the metric function
d(·,·)(e.g., L2 vs. Huber vs. cosine) used in both adversarial and rectification losses; its impact on stability and one-step quality is unknown.
- Twin trajectory design choices
- The implications of using independent
zandz_fakeversus correlated or shared noise for the twin trajectories are not explored; potential benefits of coupling are unknown. - It is unclear whether sharing a single head for positive/negative time conditioning is optimal; no comparison to split heads, separate parameterizations, or architectural decoupling of the two flows.
- The implications of using independent
- Training dynamics and failure modes
- Risk of self-reinforcement: using the model’s own outputs to supervise the negative branch may amplify biases or errors; safeguards against drift or collapse are not discussed.
- No empirical analysis of training stability (variance across seeds, hyperparameter sensitivity, gradient norms) compared to adversarial or distillation baselines.
- Interaction between the base any-step objective (multi-step fidelity) and rectification (few-step straightening) may create conflicting gradients; no diagnostics or mitigation (e.g., gradient surgery) are presented.
- Generalization and scope
- Applicability beyond text-to-image (e.g., video generation, audio, 3D, multilingual or multimodal tasks such as image-to-text, editing, or cross-modal translation) is not demonstrated despite claims of generality.
- For unified multimodal models (e.g., Qwen-Image), the impact of TwinFlow on non-generation tasks or other modalities (e.g., captioning, text generation) is not evaluated; potential capability trade-offs are unknown.
- Evaluation breadth and rigor
- Limited diversity assessment: no quantitative diversity metrics (e.g., intra-FID, recall, coverage, precision–recall curves) or human A/B studies; mode collapse risks are not measured for TwinFlow.
- Benchmarks focus on GenEval, DPG-Bench, and WISE; classical metrics (FID/CLIP-FID/IS), robustness to OOD prompts, safety/toxicity, and fairness/bias are not reported.
- Comparisons to baselines are not uniformly controlled for total compute, wall-clock training time, or data usage; fairness of comparisons (e.g., prompt rewrites, guidance settings, decoding pipelines) is not fully clarified.
- Efficiency and scaling
- Training-time cost is not quantified (throughput, step time, accumulated GPU-hours) for TwinFlow versus distillation or GAN-based methods; only memory usage is emphasized.
- No analysis of scaling laws: how performance and stability evolve with model size, dataset size, or resolution; whether gains persist for >20B models or at ultra-high resolutions.
- Few-step quality beyond 1–2 NFEs is underexplored; it is unclear how performance scales with 3–8 steps and whether multi-step performance matches strong diffusion/flow baselines.
- Conditional generation specifics
- The interplay with classifier-free guidance (CFG) or alternative conditioning strategies is not detailed; sensitivity to guidance scale or conditioning dropout is not studied.
- Effects on compositionality and long/intricate prompts are only partially probed (WISE); no targeted stress tests on rare entities or complex spatial/attribute constraints.
- Design and implementation details
- The choice of
N=2in the any-step objective for “stability” is not justified with ablations; benefits over N in {0,1,3+} are unknown. - The negative-time schedule reuses the same transport as positive time; no exploration of asymmetric schedules, noise magnitudes, or curriculum from positive to negative times.
- Lack of analysis on latent vs. pixel-space training (SANA vs. Qwen-Image): when and where TwinFlow is most effective, and whether VAEs or normalizing flows interact differently with the twin objectives.
- The choice of
- Robustness and safety
- No experiments on robustness to distribution shift (domain transfer), adversarial or corrupted inputs, or prompt perturbations.
- No safety evaluation (e.g., harmful content generation rates) or discussion of how twin training influences moderation or controllability.
- Reproducibility and deployment
- Missing details on datasets, preprocessing, training schedules, and hyperparameter ranges in the main text (appendix referenced); end-to-end reproducibility for full-parameter 20B training remains uncertain.
- Inference latency is only inferred via NFEs; real wall-clock latency and throughput on commodity hardware vs. data-center accelerators are not measured.
- Extensions and combinations
- It is unknown whether TwinFlow is complementary to distillation or GAN losses (e.g., can a small adversarial head further improve fidelity without instability?).
- Potential integration with improved ODE solvers, learned schedulers, or noise-conditioned priors is not studied.
- No investigation into multi-branch or multi-twin generalizations (more than two trajectories) and whether they bring further gains.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that leverage the paper’s findings and methods to improve existing products and workflows today.
- Cloud-scale text-to-image APIs: cut inference cost and latency
- Sector: software/cloud, media/advertising
- What emerges: a “1-NFE” inference path for existing diffusion/flow-matching models; drop-in schedulers and serving templates that replace 40–100-step pipelines
- Workflow: fine-tune a production model (e.g., Qwen-Image-20B) with TwinFlow; deploy a 1–2 step sampler to increase throughput per GPU and reduce latency for user-facing endpoints
- Assumptions/dependencies: base model supports the any-step (flow-matching) interface with time conditioning; content safety filters remain in place; quality parity depends on domain (paper shows parity on text-to-image)
- Real-time creative tooling (instant previews, iteration-in-the-loop)
- Sector: media/design/marketing
- What emerges: “instant preview” mode in design tools (e.g., Figma/Adobe plugins) where 1-step renders provide fast iteration; full-fidelity multi-step fallback optional
- Workflow: integrate TwinFlow-trained models into desktop plugins/web apps for storyboard generation, prompt-tuning, layout exploration
- Assumptions/dependencies: acceptable small quality delta vs. 100-NFE; prompt safety/compliance; GPU or high-end CPU/edge accelerator access
- On-prem and enterprise deployments under tight compute budgets
- Sector: enterprise IT
- What emerges: private text-to-image services that meet SLAs without large GPU fleets
- Workflow: TwinFlow fine-tuning of existing internal models; deploy with 1-step inference for batch creative requests or internal tooling
- Assumptions/dependencies: internal datasets/policies for model fine-tuning; any-step-compatible model backbone
- Data augmentation at scale for computer vision training
- Sector: software/AI, robotics
- What emerges: synthetic dataset generation pipelines that achieve 10–100× more samples per dollar/time
- Workflow: use TwinFlow-trained models to generate labeled synthetic images for detection/classification/segmentation pretraining
- Assumptions/dependencies: label quality strategies (prompting, LLM-based captioning, human QA); domain validity and legal/licensing safeguards
- Edge and mobile experiences with lower latency
- Sector: mobile/AR, e-commerce
- What emerges: near-real-time product mockups, AR filters, catalog image variations
- Workflow: deploy a small model variant trained with TwinFlow to on-device NPUs or lightweight edge servers; 1–2 NFE enables interactive use
- Assumptions/dependencies: model size still matters—20B is too large for phones; use smaller backbones (e.g., 0.6B–1.6B) or quantization
- Multimodal platform throughput increase without architectural complexity
- Sector: general AI platforms
- What emerges: higher throughput for unified multimodal stacks (e.g., Qwen-Image family) without discriminators/teacher models
- Workflow: apply TwinFlow to existing large models (LoRA or full-parameter training); swap inference scheduler to 1–2 steps
- Assumptions/dependencies: training stability validated (paper shows viability up to 20B); robust MLOps for versioning and A/B testing
- ESG and cost reporting improvements via inference efficiency
- Sector: energy/ESG, corporate sustainability
- What emerges: measurable reductions in GPU-hours and energy per generated asset; reporting artifacts for sustainability dashboards
- Workflow: quantify NFE reduction (e.g., 100× vs. baseline) and include in ESG metrics; use for procurement and internal policy
- Assumptions/dependencies: accurate carbon accounting; equivalence of output quality for business use
- Academic and R&D acceleration
- Sector: academia/research
- What emerges: simpler few-step training without discriminators/teachers; lower memory footprint to avoid OOM on large models
- Workflow: replicate TwinFlow on open architectures (SANA, Qwen-Image, OpenUni); iterate rapidly on ablations and new objectives
- Assumptions/dependencies: any-step framework familiarity; training datasets and compute access
- Adaptation kits for existing pipelines
- Sector: software tooling
- What emerges: “TwinFlow Trainer” (training loop extension), “TwinFlow Scheduler” (1–2 step inference), “TwinFlow LoRA pack” (low-rank fine-tuning recipes)
- Workflow: integrate into popular libraries (e.g., Diffusers-like) with negative-time conditioning and velocity rectification losses
- Assumptions/dependencies: open-source stack adoption; adherence to training hyperparameters (e.g., λ balancing)
- Content operations with predictable output latency
- Sector: digital media ops
- What emerges: SLAs for content generation pipelines (social, e-commerce listings) with consistent sub-second renders
- Workflow: use 1-NFE models to guarantee turnaround times; batch scheduling and auto-retry logic simplified
- Assumptions/dependencies: similar or acceptable content quality; guardrails remain for safety and brand policy
Long-Term Applications
These use cases are plausible extensions that require further research, scaling, validation, or domain-specific development.
- Real-time video generation and editing with few steps
- Sector: media/entertainment, software
- Potential tools: streamable composers where each frame or segment is produced in 1–2 steps; live prompt-controlled previews for post-production
- Dependencies: demonstrate TwinFlow efficacy on video backbones; temporal consistency objectives; robust evaluation beyond images
- On-device AR glasses and spatial computing
- Sector: consumer hardware, XR
- Potential products: instant scene/object generation and personalization directly on wearable devices
- Dependencies: extreme model compression/quantization; energy-aware schedulers; privacy-preserving local prompts
- Robotics simulation and synthetic environments
- Sector: robotics, autonomy
- Potential workflows: fast generation of varied photorealistic scenes for sim-to-real transfer and rare-event training
- Dependencies: domain fidelity validation; coupling with physics engines and scene graphs; controls for distribution shift
- Healthcare: privacy-preserving synthetic data
- Sector: healthcare
- Potential tools: accelerated pipelines to create de-identified synthetic medical images for pretraining and augmentation
- Dependencies: rigorous clinical validation; bias and safety assessments; regulatory compliance (HIPAA/GDPR), provenance tracking
- Education: personalized learning content at scale
- Sector: education/edtech
- Potential products: per-learner instant visualizations with explainable prompts (e.g., STEM diagrams)
- Dependencies: smaller models for school devices; content accuracy checks; accessibility and cultural sensitivity policies
- Policy and governance: low-inference-intensity standards
- Sector: public policy, ESG
- Potential frameworks: procurement guidelines and benchmarks that favor low-NFE generative systems; standardized reporting on inference energy
- Dependencies: industry consensus on metrics; oversight for content safety and watermarking; independent audits
- Cross-modal extensions (audio, 3D, molecular design)
- Sector: creative tech, materials science
- Potential tools: one-step audio synthesis/editing; rapid text-to-3D asset pipelines; accelerated generative chemistry for candidate screening
- Dependencies: adapting TwinFlow to modality-specific transports and objectives; domain evaluations; IP and safety concerns
- Personalized generative models with few-shot adaptation
- Sector: consumer apps, marketing
- Potential products: “instant personalization” via lightweight TwinFlow fine-tunes; brand/style-locked generators
- Dependencies: data collection policies; catastrophic forgetting safeguards; content moderation
- Secure and compliant generation at scale
- Sector: software/security/compliance
- Potential workflows: coupling 1-step generation with robust watermarking, traceability, and content filtering without slowing inference
- Dependencies: watermark robustness research; integration with safety classifiers; policy-aligned defaults
Notes on Assumptions and Dependencies
- Generalization: The paper demonstrates strong results on text-to-image (e.g., 0.86 GenEval at 1-NFE for Qwen-Image-20B) and smaller SANA models; performance in other modalities (video, audio, 3D) remains to be proven.
- Model size and hardware: 1-step reduces compute per sample but not parameter count; on-device deployment requires smaller backbones, pruning/quantization, or distillation.
- Safety and compliance: All deployments should retain content filtering, watermarking, and governance processes; one-step efficiency does not replace safety controls.
- Training prerequisites: TwinFlow depends on any-step/flow-matching-compatible architectures and negative-time conditioning; hyperparameter balancing (e.g., λ) impacts quality and stability.
- Quality trade-offs: Minor degradation vs. 100-NFE can be acceptable in interactive settings; mission-critical domains (healthcare, policy) require stricter validation.
Glossary
- Adversarial training: A training paradigm that pits models against adversarial objectives (often via discriminators) to improve generation quality, which can introduce instability and complexity. "integrating adversarial training into distillation (e.g., DMD/DMD2 and SANA-Sprint) to enhance performance introduces training instability"
- Any-step generative model framework: A unified formulation that encompasses both multi-step and few-step generative paradigms under a single training objective. "A recent framework, RCGM~\citep{sun2025anystep}, introduces a unified formulation for the any-step generation framework"
- Conditional distribution: The probability distribution of data given a specific conditioning variable. "let $p(\xx)$ represent its data distribution and $p(\xx|\cc)$ the conditional distribution given a condition $\cc$."
- Consistency models: Generative models designed to produce high-quality samples in very few steps by enforcing consistency across predictions. "a powerful new paradigm of consistency models~\citep{song2023consistency}"
- Distribution matching distillation (DMD/DMD2): Distillation techniques that align the model’s output distribution with the real data distribution, often with adversarial components. "distribution matching distillation (e.g., DMD variants~\citep{yin2024one,yin2024improved})"
- FSDP-v2: Fully Sharded Data Parallel (version 2), a large-scale model training strategy that shards parameters and states across devices. "instantiated as separate models using FSDP-v2; this configuration leads to OOM."
- Flow matching: A generative modeling approach that trains neural networks to match velocity fields of flows transforming noise into data. "Under flow matching objective and linear transport"
- GAN discriminator: The adversarial component in GANs that distinguishes real data from generated data during training. "GAN requires a trained discriminator"
- GAN loss: An adversarial loss function used in GAN training to encourage the generator to fool the discriminator. "without resorting to a GAN loss"
- Generative Adversarial Networks (GANs): Generative models composed of a generator and discriminator trained adversarially to synthesize realistic data. "Generative Adversarial Networks (GANs)~\citep{goodfellow2014generative}"
- GenEval: An automated benchmark for evaluating text-to-image generation quality and faithfulness. "achieves a GenEval score of 0.83 in 1-NFE"
- Jacobian term: The derivative of a transformed variable with respect to model parameters, appearing in gradient derivations. "the Jacobian term in~\eqref{eq:kl_gradient_full} is instantiated as"
- Jacobian-Vector Product (JVP): An efficient operation to compute the product of a Jacobian and a vector, often used in implicit differentiation or finite differences. "the Jacobian-Vector Product (JVP) is approximated via finite differences."
- KL divergence: A measure of dissimilarity between two probability distributions, often minimized to match model and target distributions. "we aim to minimize the KL divergence"
- Linear transport: A flow setting where the mixture of noise and data varies linearly with time. "under linear transport ()"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning method for large models. "Qwen-Image-20B (LoRA tuning)"
- Mode collapse: A failure mode in generative models where diversity drops and outputs become nearly identical. "severe diversity degradation (mode collapse)"
- Number of Function Evaluations (NFE): The count of model evaluations during sampling; fewer NFEs indicate faster inference. "requiring 40-100 Number of Function Evaluations (NFEs)"
- Out-of-memory (OOM): A runtime failure due to insufficient GPU memory for model training or inference. "suffers from OOM when applying to ultra-large models."
- PF-ODE: Probability Flow Ordinary Differential Equation, the continuous-time formulation used to sample by integrating velocity fields. "along a specific PF-ODE trajectory"
- Rectification loss: A training term that encourages aligning twin trajectories by matching their velocity fields to enable few-step generation. "This motivates the following rectification loss:"
- RCGM: A unified any-step generative framework that encompasses multi-step and few-step methods. "RCGM~\citep{sun2025anystep}"
- Score function: The gradient of the log-density of a distribution with respect to data, used to relate densities and velocity fields. "where is the score of the respective distribution."
- Self-adversarial flows: A training approach that induces adversarial signals internally by constructing twin trajectories, avoiding external discriminators. "Self-adversarial Flows"
- Stop-gradient operator: A mechanism that prevents gradients from flowing through a term during backpropagation. "we employ the stop-gradient operator, ."
- Twin trajectories: Symmetric trajectories around zero time that map shared noise to real and fake data for self-adversarial training. "the introduction of twin trajectories"
- TwinFlow: The proposed framework that achieves one-step generation via self-adversarial twin trajectories and velocity rectification. "we propose TwinFlow, a simple yet effective framework for training 1-step generative models"
- Velocity field: The vector field defining the instantaneous direction of change in the data space along the generative flow. "difference between the velocity fields ($\Delta_{\vv}$)"
- WISE: A benchmark for evaluating image generation capabilities and reasoning quality. "WISE~\citep{niu2025wise}"
Collections
Sign up for free to add this paper to one or more collections.