Your Latent Mask is Wrong: Pixel-Equivalent Latent Compositing for Diffusion Models
Abstract: Latent inpainting in diffusion models still relies almost universally on linearly interpolating VAE latents under a downsampled mask. We propose a key principle for compositing image latents: Pixel-Equivalent Latent Compositing (PELC). An equivalent latent compositor should be the same as compositing in pixel space. This principle enables full-resolution mask control and true soft-edge alpha compositing, even though VAEs compress images 8x spatially. Modern VAEs capture global context beyond patch-aligned local structure, so linear latent blending cannot be pixel-equivalent: it produces large artifacts at mask seams and global degradation and color shifts. We introduce DecFormer, a 7.7M-parameter transformer that predicts per-channel blend weights and an off-manifold residual correction to realize mask-consistent latent fusion. DecFormer is trained so that decoding after fusion matches pixel-space alpha compositing, is plug-compatible with existing diffusion pipelines, requires no backbone finetuning and adds only 0.07% of FLUX.1-Dev's parameters and 3.5% FLOP overhead. On the FLUX.1 family, DecFormer restores global color consistency, soft-mask support, sharp boundaries, and high-fidelity masking, reducing error metrics around edges by up to 53% over standard mask interpolation. Used as an inpainting prior, a lightweight LoRA on FLUX.1-Dev with DecFormer achieves fidelity comparable to FLUX.1-Fill, a fully finetuned inpainting model. While we focus on inpainting, PELC is a general recipe for pixel-equivalent latent editing, as we demonstrate on a complex color-correction task.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Your Latent Mask is Wrong: Pixel-Equivalent Latent Compositing for Diffusion Models”
What is this paper about (big picture)?
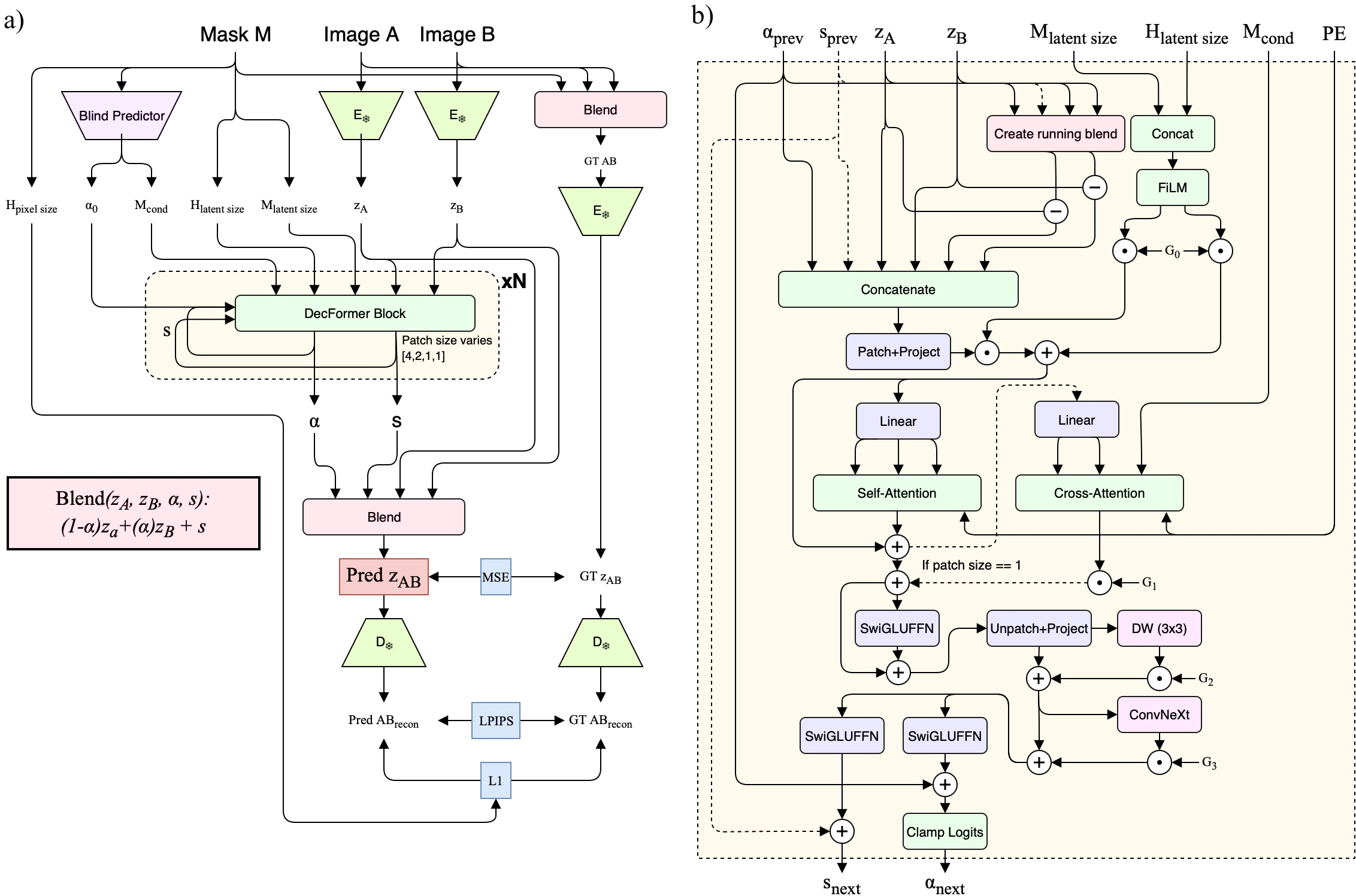
This paper is about making image editing with AI look cleaner and more accurate—especially when you replace or fix parts of a picture using a “mask” (think of a stencil that tells the AI where to edit). Today’s popular image generators work on a compressed version of the image (called “latents”), and most tools mix these latents in a simple way that often causes blurry edges, weird halos, and color shifts. The authors propose a better way called Pixel-Equivalent Latent Compositing (PELC) and a tiny helper model named DecFormer that makes the results match what you’d get if you mixed images directly, pixel by pixel.
What questions does the paper ask?
- Why do current methods for mixing image parts in the AI’s compressed space (latent space) cause visible problems?
- Can we design a method in latent space that behaves exactly like mixing images in pixel space (the actual picture), even when the AI compresses images by 8×?
- Can this be done with a small, fast model that plugs into existing image generators without retraining the big model?
- Will this improve inpainting (filling in or replacing parts of an image), especially around edges and soft transparency?
- Can the same idea work for other edits (like color changes), not just masking?
How did the researchers approach the problem?
Think of a modern image generator as using two steps:
- An encoder squashes the image into a compact code (latent).
- A decoder turns that code back into an image.
Most tools mix two latent codes using a resized, lower-resolution mask—like mixing two recipes by averaging the ingredients. But the decoder is complex and non-linear, so “averaging recipes” doesn’t reliably give you “averaged pictures.” That mismatch creates artifacts.
The authors set one clear goal: if you mix in latent space, the final decoded picture should look the same as if you had mixed the original images directly in pixel space. They call this pixel-equivalence.
To do that, they:
- Keep the encoder and decoder frozen (unchanged).
- Train a small model called DecFormer (about 7.7 million parameters—tiny compared to the big generator) to learn how to blend two latents using:
- Per-channel blend weights (like different mixing amounts for different “ingredients” of the latent).
- A small “residual correction” (a smart nudge to fix what simple blending can’t).
- Supervise it with ground truth from pixel-space mixing (alpha compositing), so the model learns: “When I blend these latents, the decoded image must match the true pixel mixture.”
They also adjust the diffusion process slightly so DecFormer’s blend happens at the “cleanest” stage (the fully denoised latent, often called z0) and then continue the normal generation steps. This makes it plug-and-play.
In everyday terms: instead of pretending the compressed codes behave like images, they teach a small “mixing assistant” to blend codes in a way that produces the same picture you’d get if you mixed actual images.
What did they find, and why does it matter?
The authors tested their method on the FLUX.1 family of diffusion models and found:
- Cleaner seams and edges: DecFormer cuts edge errors by up to about 53% compared to the usual simple blend. Halos and jagged edges are much reduced.
- True soft masks: It handles soft transparency (like feathered edges) much better, avoiding smears and gray halos.
- Better global color consistency: No odd color shifts across the image—a common problem when latents are blended poorly.
- High-resolution control: Masks don’t have to be squashed down to 1/8 size, so fine details are preserved.
- Almost no speed or size penalty: It adds only about 3.5% extra computation and 0.07% extra parameters compared to a large FLUX.1 model.
- Inpainting improves: Even without retraining the big model, inpainting looks better. With a tiny extra training module (a small LoRA), quality becomes comparable to a fully retrained, dedicated inpainting model (FLUX.1-Fill).
- Works beyond masking: The same idea (PELC) also works for other pixel-style edits—like brightness/contrast/gamma changes—done correctly in latent space.
In short: the method makes edited images look more natural where parts are stitched together, without slowing things down much.
What does this mean for the future?
- Better tools, fewer artifacts: Photo edits—like object replacement or background cleanup—should look cleaner, especially around edges and soft transitions.
- Less retraining: Instead of building and maintaining separate giant inpainting models, teams can plug in a small compositor and get strong results.
- A general recipe for “latent edits”: PELC is a principle, not just one trick. It can be used to build other “pixel-equivalent” tools in latent space (like color, exposure, or even future video edits) without constantly converting back and forth between latent and pixel images.
- Limits: This fixes how parts are blended, not what content gets generated inside the mask. Big, complex edits still need smart generative models. And testing on more autoencoders is needed.
Overall, this paper points out a simple but powerful idea: if you mix things in the AI’s compressed world, make sure the final picture looks exactly like mixing them in the real image. Doing that yields sharp, clean, and faithful edits—without making everything slower or more complicated.
Collections
Sign up for free to add this paper to one or more collections.