- The paper introduces a test-time training approach for interactive 3D Gaussian refinement, achieving rapid and non-destructive edits.
- It employs a two-stage pipeline with voxel-based compression and transformer-driven fast-weight updates to integrate sparse 2D inputs.
- Empirical evaluations show superior detail preservation and efficient global relighting performance compared to baseline methods.
SplatPainter: Interactive Test-Time Training-Based Editing of 3D Gaussian Assets
Motivation and Context
The proliferation of 3D Gaussian Splatting (3DGS) as a photorealistic, efficient 3D representation has accelerated content creation pipelines. While conventional pipelines leverage diffusion models or optimization for generation and editing, these approaches suffer from destructive, slow, or imprecise operations, which limit practical, artist-friendly workflows. SplatPainter (2512.05354) addresses the critical deficit in direct, interactive refinement of 3DGS assets by enabling continuous, high-fidelity edits from sparse 2D views, without losing the original asset's structural and appearance identity.
Technical Framework
SplatPainter implements a state-aware feedforward architecture, distinguished by its ability to directly update compact Gaussian representations conditioned on new 2D image inputs. The system is structured as a two-stage pipeline:
- Feature-Rich Compression: Given an input 3DGS asset, multiple views are rendered and processed using a Gaussian Large Reconstruction Model (LRM), producing a dense, feature-rich point cloud. This output is then regularized and compressed into a voxel-based grid via a local transformer, aggregating and distilling context for each Gaussian (Figure 1).

Figure 1: The SplatPainter pipeline—preprocessing via LRM and transformer-based Gaussian compression; followed by interactive loop for TTT-driven refinement.
- Interactive Editing via Test-Time Training (TTT): The compressed scene is iteratively updated through user-supplied 2D edits. Dedicated TTT layers within the transformer blocks adapt "fast weights" at inference, enabling quick specialization to each new input (Figure 2). This ensures edits are localized and non-destructive, preserving unedited regions and propagating pixel-level changes coherently in 3D.
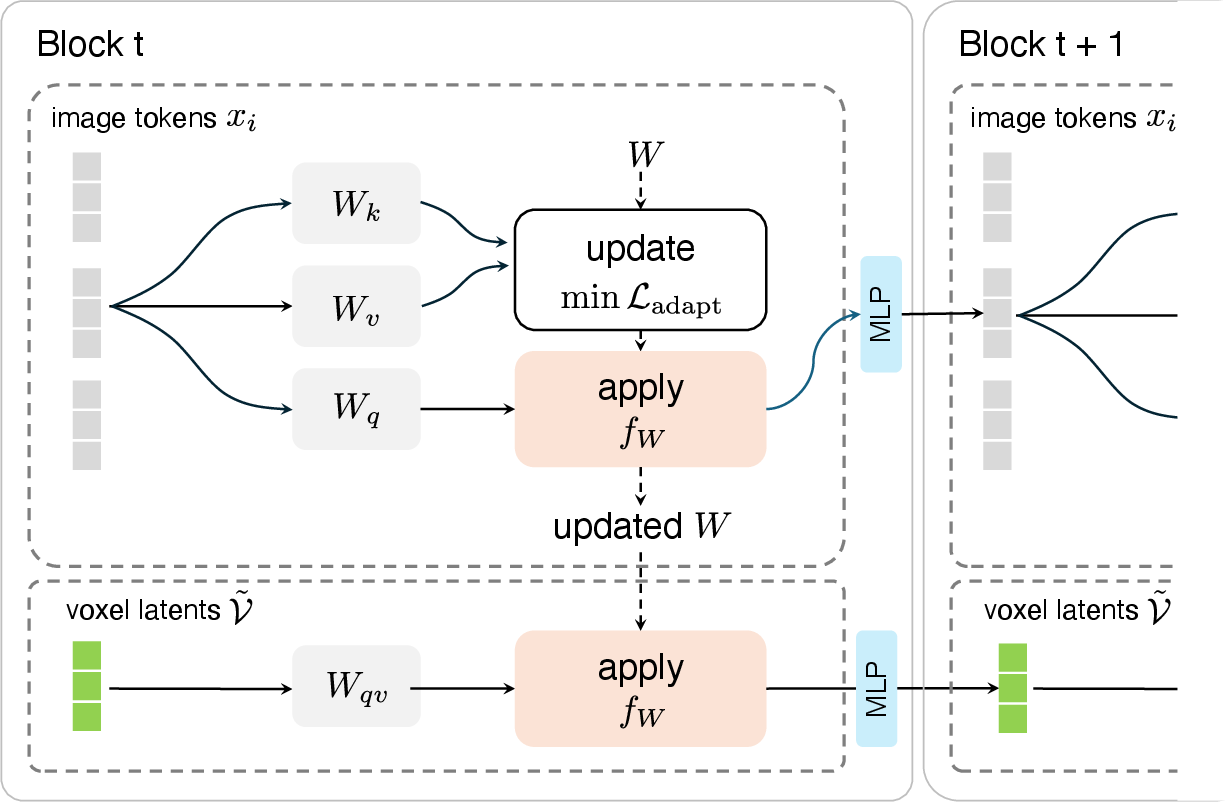
Figure 2: SplatPainter's TTT mechanism for updating fast weights on new input views, then applying them to affected voxel latents.
A distinguishing aspect is the architecture's unified handling of divergent editing tasks—fine local refinement (e.g., super-resolution of small regions) and global appearance transformation (e.g., scene-wide relighting)—all at interactive rates.
Empirical Evaluation
Local Detail Refinement
The authors benchmarked SplatPainter against strong direct reconstruction (GS-LRM), feedforward upsampling (GenDen), and optimization-based methods (3DGS, SRGS), using zoomed-in high-res views from TexVerse. SplatPainter demonstrated consistent superiority in preserving high-frequency detail and sharpness, with minimal latency per edit (Figure 3). Quantitatively, it matched or exceeded optimization-based approaches (PSNR 21.07, SSIM 0.578) but operated orders of magnitude faster (1.54–2.18 s vs. 323–495 s per edit).

Figure 3: SplatPainter's refined result exhibits sharper, better-resolved features compared to baselines when viewed from novel perspectives.
Global Relighting and Appearance Transfer
For global edits, SplatPainter was compared to the generative relighting model ReLitLRM. By exploiting a few sparse relit views, SplatPainter achieved consistent propagation of new lighting conditions throughout the asset, capturing accurate shadows and color transfer (Figure 4). Quantitative gains were pronounced: SplatPainter improved PSNR by >2.5 dB and SSIM by >0.02 relative to the baseline, scaling robustly with the number of input views, while maintaining near real-time performance (0.06–0.2 s per update).

Figure 4: SplatPainter propagates user-specified lighting edits throughout the scene, achieving photometrically accurate global appearance transfer.
Ablations and Generalization
Voxel compression ablations established that opacity-weighted, local attention-based queries maximized visual fidelity, nearly matching uncompressed GS-LRM outputs while drastically reducing memory and compute (Figure 5). TTT-based refinement consistently outperformed frozen cross-attention baselines for conditionally propagating features, validating its adaptability. Tests on assets generated by Trellis confirmed that the method generalizes to arbitrary, non-reconstructed asset sources, maintaining high-quality refinements for both photometry and local texture edits (Figure 6).

Figure 5: The two-stage pipeline retains visual fidelity after compression, and enables quality improvements via interactive refinement.

Figure 6: Demonstration of SplatPainter's refinement on generated 3DGS from Trellis—enhanced local detail and robust handling of diverse edits.
Implications and Future Directions
From a practical standpoint, SplatPainter yields an unprecedented workflow for 3DGS asset refinement: sub-second, view-consistent edits enabling both precision graffiti-style changes and physically accurate relighting from sparse 2D cues. This facilitates a granular, responsive editing paradigm unattainable by diffusion or optimization pipelines. The asset identity and structural details are preserved, supporting high-frequency content critical for industrial and entertainment applications.
Theoretically, introducing TTT-based stateful adaptation into 3D representation editing bridges spatial memory models from SLAM with modern deep generative schemes. By leveraging fast-weight programmable layers, SplatPainter hints at broader applications where continual inference-time model updates interactively reshape scene representations without retraining. Generalizations may include multiresolution voxelization, geometric manipulation, and further integration with text/image-conditioned generative models.
Conclusion
SplatPainter establishes a versatile, efficient architecture for interactive, image-driven 3D Gaussian Splatting asset refinement. Through novel integration of compact voxel-based representations and TTT-driven iterative adaptation, the method supports a rich spectrum of editing tasks—local enhancement, global appearance transfer, and direct asset manipulation—with state-of-the-art quality and responsiveness. The framework paves the way for finer-grained, artist-controlled 3D editing pipelines and suggests compelling intersections between online learning, spatial memory, and feedforward generative 3D content authoring.