- The paper introduces a hybrid point descriptor network (HPNet) that merges semantic and spectral features to improve point cloud segmentation accuracy.
- It proposes an Implicit AutoEncoder that leverages implicit surfaces to mitigate sampling variation, enhancing self-supervised representation learning.
- The approach adapts masked autoencoder pretraining and 2D-to-3D transfer techniques to enable robust 3D feature learning for varied applications.
Representation Learning for Point Cloud Understanding
The paper focuses on advancements in representation learning for point cloud data, a critical aspect of 3D data processing widely applicable in computer vision, robotics, and geospatial analysis. It addresses the challenge of effectively utilizing point clouds for tasks such as classification, segmentation, and object detection, leveraging both supervised and self-supervised learning methods.
Introduction
With the proliferation of technologies like LiDAR, 3D scanners, and RGB-D cameras, acquiring 3D data has become more accessible, allowing for a richer understanding of environments across various applications. Point clouds, as a representation format, capture the spatial and geometric properties of objects and scenes. This paper explores the two main approaches to learning representations from point clouds: supervised learning, which depends heavily on annotated datasets, and self-supervised learning, which seeks to create representations from unlabeled data using pretext tasks.
HPNet: Hybrid Point Descriptor Network
HPNet introduces a method for primitive segmentation of point clouds, combining traditional geometric heuristics with deep learning. This approach utilizes a hybrid point descriptor that merges learned semantic and spectral descriptors to improve segmentation accuracy.
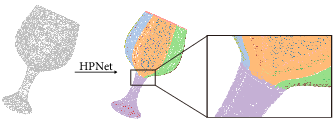
Figure 1: HPNet takes a point cloud as input and outputs detected primitive patches. It can handle diverse primitives at different scales. The detected primitives have smooth boundaries.
HPNet's architecture consists of multiple modules: a dense descriptor module producing semantic and shape descriptors, a spectral embedding module calculating geometric consistency and smoothness features, and a clustering module that applies learned adaptive weights for segmentation. By integrating both standard and novel spectral descriptors, HPNet significantly outperforms baseline approaches in segmentation tasks.
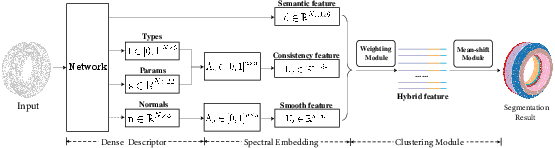
Figure 2: Overview of our approach pipeline. HPNet consists of three modules: a Dense Descriptor, Spectral Embedding Module, and Clustering Module.
Implicit AutoEncoder for Self-Supervised Learning
The paper proposes an Implicit AutoEncoder (IAE), addressing the challenges inherent in point-cloud representation learning, notably the sampling variation problem. IAE shifts from explicit point cloud reconstructions to implicit surface representations, which help decouple true 3D geometry representation from sampling noise.
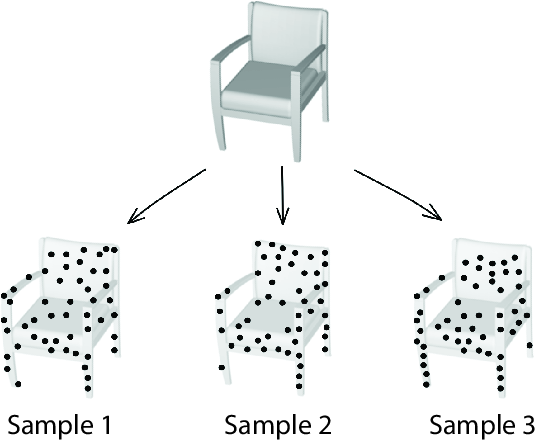
Figure 3: The Sampling Variation Problem. Given a continuous 3D shape, there are infinitely many ways to sample a point cloud. The proposed IAE improves existing point-cloud self-supervised representation learning methods.
IAE enhances the capturing of generalizable 3D features by using implicit functions as its output format during the reconstruction phase, providing a more stable and efficient representation learning process that surpasses traditional autoencoders.
Masked Autoencoder-Based Point Cloud Pretraining
Building upon the masked autoencoder paradigm success in NLP and computer vision, the paper adapts it for 3D point cloud pretraining. The novel approach emphasizes recovering high-order features like surface normals and variations on masked points, rather than simply reconstructing point locations.
This technique uses attention-based decoders that leverage masked points as inputs to predict their feature representations, significantly improving the quality of learned features applicable to various downstream tasks.
2D-to-3D Transfer Learning
Addressing the scarcity of extensive labeled 3D datasets, the paper introduces multi-view representation strategies leveraging pre-trained 2D models to assist 3D representation learning. The approach involves projecting 3D feature volumes into multiple 2D views and aligning these with pre-trained 2D hierarchies, thus retaining essential 3D characteristics.
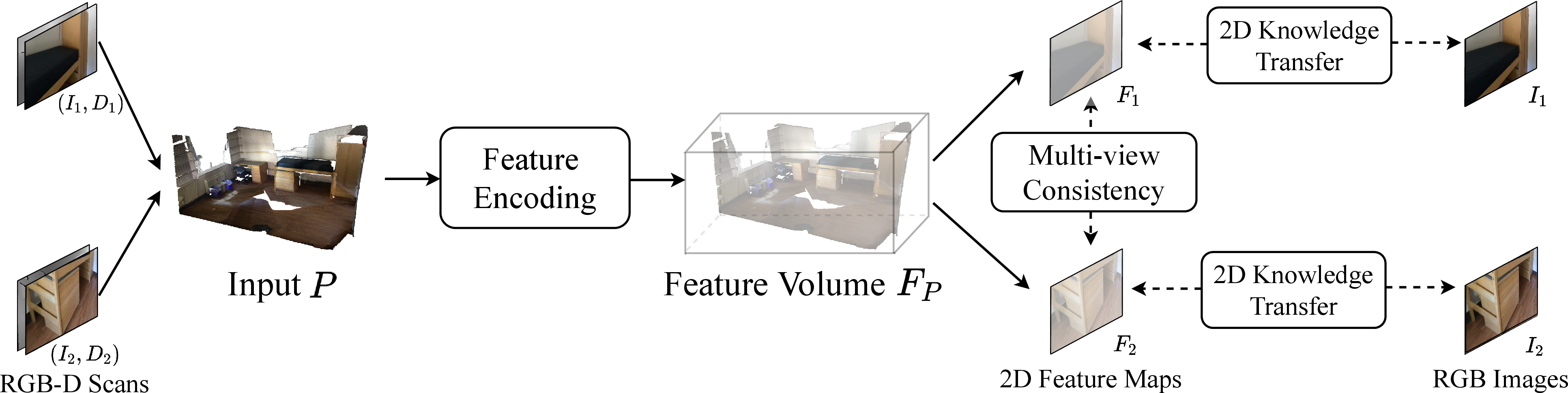
Figure 4: Approach overview. We used complete and semi-transparent point clouds to represent the input P and the feature volume FP for better visualization.
The multi-view consistency module focuses on preserving geometrical cues by encouraging consistency across projections, ensuring the integrity of 3D-specific features while benefiting from 2D pre-trained model insights.
Conclusion
This paper not only advances techniques in point cloud representation learning but also shows promising results across supervised, self-supervised, and transfer learning domains. The methodologies proposed effectively enhance point cloud data processing capabilities, paving the way for more robust applications in various fields. Future work should explore expanding the data sources and integrating transfer learning techniques further to improve the scalability and adaptability of such models in real-world applications.

