Beam search decoder for quantum LDPC codes
Abstract: We propose a decoder for quantum low density parity check (LDPC) codes based on a beam search heuristic guided by belief propagation (BP). Our beam search decoder applies to all quantum LDPC codes and achieves different speed-accuracy tradeoffs by tuning its parameters such as the beam width. We perform numerical simulations under circuit level noise for the $[[144, 12, 12]]$ bivariate bicycle (BB) code at noise rate $p=10{-3}$ to estimate the logical error rate and the 99.9 percentile runtime and we compare with the BP-OSD decoder which has been the default quantum LDPC decoder for the past six years. A variant of our beam search decoder with a beam width of 64 achieves a $17\times$ reduction in logical error rate. With a beam width of 8, we reach the same logical error rate as BP-OSD with a $26.2\times$ reduction in the 99.9 percentile runtime. We identify the beam search decoder with beam width of 32 as a promising candidate for trapped ion architectures because it achieves a $5.6\times$ reduction in logical error rate with a 99.9 percentile runtime per syndrome extraction round below 1ms at $p=5 \times10{-4}$. Remarkably, this is achieved in software on a single core, without any parallelization or specialized hardware (FPGA, ASIC), suggesting one might only need three 32-core CPUs to decode a trapped ion quantum computer with 1000 logical qubits.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a new way to fix errors in quantum computers that use a special kind of error-correcting code called a quantum LDPC code. The new method is a decoder (a program that figures out what went wrong and how to fix it) that combines two ideas:
- belief propagation (BP), a fast but sometimes unreliable technique, and
- beam search, a smart way to explore only the most promising guesses.
The result is a decoder that’s both fast and accurate, and it can be tuned to trade speed for accuracy (or vice versa) depending on what the hardware needs.
The main questions the paper asks
- Can we build a decoder for quantum LDPC codes that is as accurate as the best existing method (BP-OSD) but much faster?
- Can it avoid slow “worst-case” scenarios so that even the rare, hard cases finish quickly?
- Will it still work well on different kinds of quantum LDPC codes and more realistic noise models?
How the method works (in simple terms)
Think of decoding like trying to repair a corrupted message using alarms raised by “checks” in the code. In quantum LDPC codes:
- The checks are like smoke detectors that tell you “something’s wrong” but not exactly where.
- The decoder guesses where the errors are and tries to find a fix that matches the alarms (the “syndrome”).
Belief propagation (BP) is like passing rumors on a social network: each node (possible error) updates what it “believes” based on its neighbors (the checks). BP is fast, but in quantum LDPC codes the network has lots of small loops. That makes the rumors go in circles, causing confusion (oscillations), so BP can get stuck or give unreliable answers.
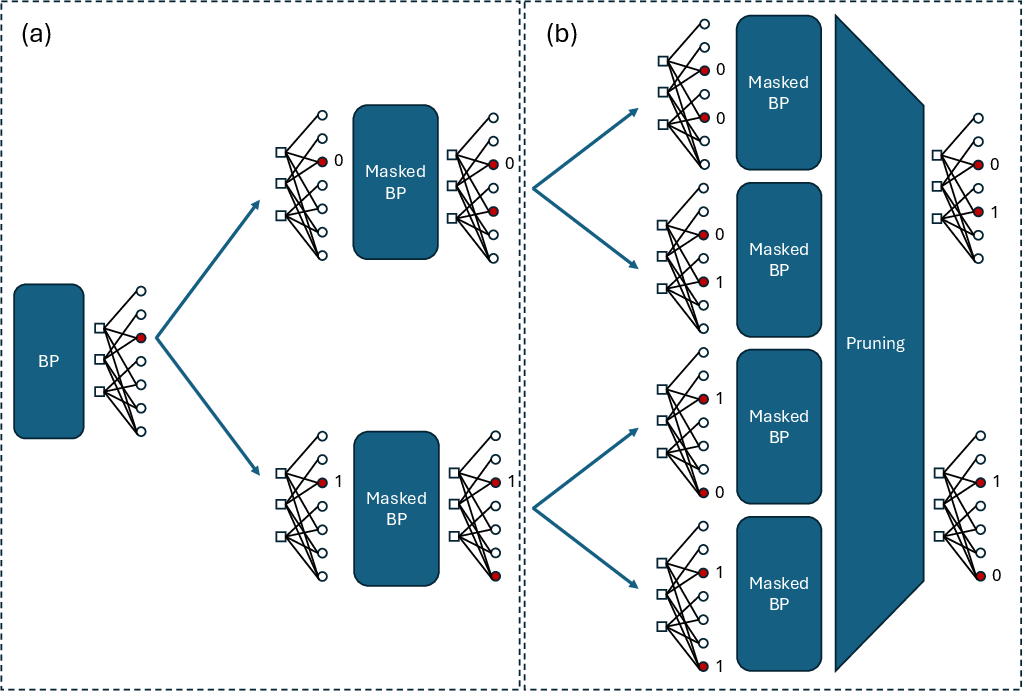
This paper’s decoder keeps the speed of BP but adds beam search, which works like this:
- Start with a short BP run to get a rough idea of which parts look confusing.
- Pick the “least reliable” spot—the place BP is most unsure about (you can think of this like the node whose opinion flips back and forth the most).
- Branch into two possibilities: “no error here” (0) and “error here” (1).
- For each possibility, run BP again but ignore (mask) that spot so its value is fixed and can’t flip anymore.
- Keep only the best few partial guesses (this number is called the beam width), based on a “reliability score.”
- Repeat: branch on the next most confusing spot, run BP, and prune again.
- Stop when you find a correction that fits the alarms, or after a limited number of rounds.
Key ideas explained:
- Beam width: how many top candidate paths you keep at each step. Bigger beam width = more thorough search = usually more accurate but slower.
- Reliability score: a simple way to estimate which partial guesses are worth keeping. The score looks at how strongly each node leans toward “error” or “no error” over all BP iterations. If a node keeps changing its mind (oscillates), it gets marked as unreliable. This helps the search focus on the tough spots first.
- Masked BP: after you fix some nodes to 0 or 1, you run BP while keeping those choices locked, which calms the oscillations and speeds convergence.
Why this helps:
- BP alone struggles with short loops.
- BP-OSD (the old “gold standard”) is accurate but slow because it does heavy linear algebra (matrix inversion).
- This method steers BP using beam search, avoids the heavy math, and focuses compute on the most promising options.
What did they test and find?
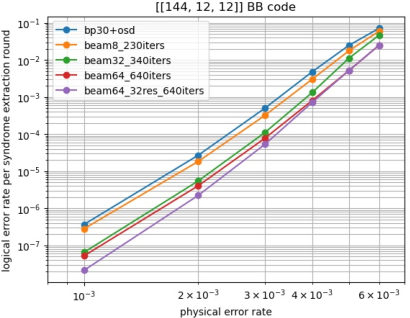
They ran large-scale simulations with realistic “circuit-level noise” (meaning errors can happen during gates, idling, and measurements) on several quantum LDPC codes, especially the bivariate bicycle (BB) code with parameters [[144, 12, 12]].
Highlights:
- With beam width 64: about 17× lower logical error rate than BP-OSD on the [[144, 12, 12]] BB code at noise rate p = 10-3.
- With beam width 8: the same logical error rate as BP-OSD but the “99.9th percentile” runtime (the slowest 0.1% of cases) is 26.2× faster. This matters because rare slow cases can bottleneck a quantum computer.
- With beam width 32: 5.6× lower logical error rate than BP-OSD, and at a lower noise rate p = 5×10-4 the 99.9th-percentile runtime per syndrome round is under 1 millisecond—fast enough for trapped-ion systems—while still running on a single CPU core.
They also showed:
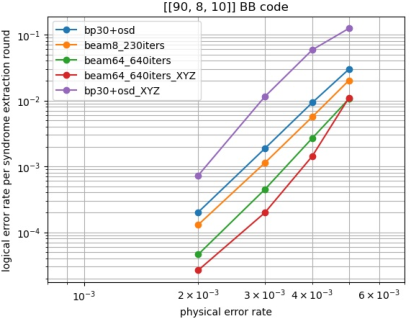
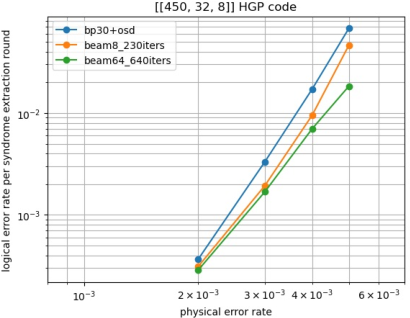
- The method works well on other codes (another BB code and a hypergraph product code).
- It can use extra information (called XYZ-decoding, which uses both X- and Z-type check outcomes at once). This extra info usually creates more short loops that hurt BP-OSD—but the new decoder handles it well and gets even better accuracy.
A few numbers to give you a feel:
- On [[144, 12, 12]] at p = 10-3 over 12 rounds:
- Average time per code block: BP-OSD ≈ 10.6 ms; beam-8 ≈ 2.3 ms; beam-32 ≈ 3.8 ms.
- 99.9th-percentile time: BP-OSD ≈ 289 ms; beam-8 ≈ 11.0 ms; beam-32 ≈ 14.2 ms.
- At p = 5×10-4, beam-32 averages about 270 microseconds per round and stays under 1 ms at the 99.9th percentile—on a single CPU core.
Why this is important
- Practical speed and reliability: The decoder is both fast and accurate, and you can tune it by adjusting the beam width. It outperforms the long-standing BP-OSD decoder, sometimes by large margins, while also taming the worst-case runtimes.
- Real hardware fit: For trapped-ion or neutral-atom quantum computers—where each round of error checks takes about 1 ms—this decoder can run in time on ordinary CPUs, without custom chips (no FPGA/ASIC needed). The paper estimates you might need only a few multi-core CPUs to decode around 1000 logical qubits in real time.
- Flexible and parallel-friendly: The approach is simple, easy to parallelize, and works across different code families and decoding styles (including XYZ-decoding).
Big-picture impact
This decoder makes quantum LDPC codes more practical by solving a core problem: getting high accuracy without blowing the runtime budget. That means:
- Lower overhead: fewer physical qubits are needed to reach the same reliability, saving hardware.
- Smoother scaling: keeping the “tail” of the runtime short helps large quantum systems run steadily without waiting on rare slow decodes.
- Future-friendly: Because the method is simple and general, it’s a good foundation for more theory, more optimization, and eventually, real-time control in large quantum machines.
In short: The paper delivers a decoder that is fast, accurate, and practical, bringing quantum LDPC codes closer to real-world use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list enumerates what remains missing, uncertain, or unexplored in the paper, focusing on concrete items future researchers could investigate or address.
- Lack of theoretical guarantees: no proofs of correctness, convergence, or optimality relative to maximum-likelihood (or maximum a posteriori) decoding; no bounds on logical error rate relative to the optimal decoder.
- No formal runtime analysis: absence of worst-case complexity bounds (per round and overall), tail guarantees, or principled explanations for the observed 99.9 percentile improvements; masked BP cost per path/round is not analyzed.
- Parameter selection methodology is ad hoc: no guidance or auto-tuning strategy for beam_width, max_rounds, initial_iters, iters_per_round, and num_results; sensitivity analyses across codes and noise regimes are missing.
- Reliability metric design is heuristic: the absolute sum of posterior LLRs is motivated empirically but lacks justification or comparison against alternatives (e.g., LLR variance, damping, check-node reliabilities, cycle-centrality scores, or learned scoring).
- Path scoring and final solution selection are under-specified: “minimum-weight” among found solutions is chosen, but weight definition and its relationship to posterior probability and degeneracy in quantum codes are not formalized; tie-breaking and multi-solution ranking require design and evaluation.
- Pruning risks are not quantified: the probability that pruning eliminates the correct path (and its impact on logical failures) is not measured or bounded; no restart or recovery policies are proposed when pruning misleads the search.
- Node selection strategy is narrow: only the “least reliable” node is used for branching; alternative strategies (e.g., conflict-driven, cycle-aware, check-reliability-driven, or hybrid policies) are not explored or benchmarked.
- No study of adaptive beam search: dynamic adjustment of beam width or rounds based on syndrome difficulty, runtime budgets, or online reliability signals is not investigated.
- Limited code families and sizes: results cover small-to-moderate instances (BB [[90,8,10]], [[144,12,12]]; HGP [[450,32,8]]); scalability to larger blocklengths/distances and asymptotically good qLDPC families (e.g., quantum Tanner, PK codes) is not demonstrated.
- No finite-size scaling or threshold estimates: how logical error rate scales with code distance and physical error rate, and whether the decoder achieves favorable thresholds, remain open.
- XYZ-decoding benefits are not characterized theoretically: while improvements are shown for one BB code, there is no formal analysis of when/why including both stabilizer types helps (vs. harms) under loopy Tanner graphs or specific noise models.
- Joint X–Z decoding is not attempted: decoding X and Z errors independently may leave performance on the table; a fully joint decoder leveraging correlations (e.g., Y components, circuit-induced dependencies) is unexplored.
- Circuit-level noise model details are insufficient: parameterization, gate-specific error channels, measurement error rates, leakage/correlated errors, and temporal correlations are not fully specified, limiting reproducibility and generality.
- Robustness to non-depolarizing and biased noise is unknown: performance under biased Pauli channels, amplitude/phase damping, leakage, crosstalk, or spatial-temporal correlations is not evaluated.
- Time-domain decoding is not detailed: the handling of measurement errors across rounds (e.g., sliding windows, 3D space-time graphs, or temporal coupling) is not described; opportunities to exploit temporal consistency in beam search are unaddressed.
- Integration with other BP-based improvements is missing: interactions with stabilizer inactivation, guided decimation, ordered Tanner forest, relay variants, or ambiguity clustering are not benchmarked.
- Comparative baselines are narrow: head-to-head evaluations against AC, BP-LSD, BP-Relay, decision-tree/A*, branch-and-bound, and linear/integer programming decoders are absent, especially for tail latency.
- Parallelization strategy is unspecified: although “easy to parallelize” is claimed, there is no concrete multi-core/GPU/FPGA mapping (beam-path scheduling, synchronization, memory footprint, communication overhead, scaling efficiency).
- System-level scaling is unvalidated: the claim that “three 32-core CPUs can decode 1000 logical qubits” lacks a full architecture-level model considering streaming bandwidth, OS jitter, queueing, load balancing across many concurrent decoders, and worst-case synchronization.
- Memory and bandwidth requirements are not reported: per-path state, LLR buffers, and masked-BP data structures are not quantified, impeding hardware feasibility assessments.
- Termination criteria and “anytime” behavior need design: early-stopping rules, confidence measures, and real-time tradeoffs between solution quality and latency are not formalized; how num_results affects accuracy vs. runtime is unclear.
- Handling of highly loopy Tanner graphs is not analyzed: beyond empirical robustness to length-4 cycles, there is no formal study of oscillations, damping, or the reliability-score dynamics in graphs with dense short cycles.
- Hardware-in-the-loop validation is absent: end-to-end tests under realistic measurement streams, latency/jitter constraints, and I/O pipelines (for trapped-ion or superconducting platforms) are not provided.
- Reproducibility lacks artifacts: code, configuration files, random seeds, and detailed simulator setups (e.g., Stim circuits, noise channels) are not released or documented for independent replication.
- Error diagnostics and failure modes are not characterized: when the decoder returns an incorrect correction, there is no analysis of common causes (e.g., mis-scored paths, pruning missteps, oscillation-induced masking) or targeted mitigations.
- Potential synergies with postselection and statistical-mechanics insights are unexplored: how beam search interacts with postselected QEC or spin-glass-inspired analyses (e.g., survey propagation) remains an open avenue.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with the paper’s current methods and performance results, along with sectors, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
- CPU-only real-time decoding for trapped-ion and neutral-atom QPUs (sector: hardware/quantum computing)
- What: Replace BP-OSD with the beam search decoder (e.g., beam width 32) in QPU control stacks to meet sub-millisecond per-round decoding (99.9 percentile under 1 ms at p=5×10⁻⁴) while improving logical error rates.
- Tools/products/workflows:
- A C++/Rust decoder library with Python bindings; integration into control software; runtime parameter tuning of beam_width and iteration counts; per-qubit microservices; on-node telemetry dashboard reporting tail latencies.
- Integration with existing simulators (e.g., Stim) for pre-deployment testing, and with hardware data acquisition pipelines for streaming syndromes to CPU decoders.
- Assumptions/dependencies:
- Noise rates at or below p≈5×10⁻⁴; circuit-level depolarizing noise model; CSS codes; tested codes like BB [[144, 12, 12]]; 12-round syndrome extraction cadence.
- Deterministic OS scheduling and low-latency I/O to deliver syndromes to CPU in time; sufficient CPU memory bandwidth.
- Tail latency results hold as systems scale; code distance and hardware drift may require retuning beam_width.
- Lower cost, higher throughput decoding for cloud QPU services (sector: cloud computing/operations)
- What: Use CPUs instead of FPGAs/ASICs to decode hundreds to thousands of logical qubits in trapped-ion or neutral-atom backends while improving logical performance (e.g., 5.6–17× lower LER vs BP-OSD at p=10⁻³).
- Tools/products/workflows:
- “Decoder-as-a-service” microservices with autoscaling; SLOs defined on 99.9 percentile latency to control queueing and batching; workload-aware beam_width tuning (e.g., beam8 for speed, beam32 for accuracy/speed balance).
- Assumptions/dependencies:
- The “three 32‑core CPUs for 1000 logical qubits” estimate depends on per-round latency, noisier codes requiring more iterations, and independence across qubits; cross-talk and code heterogeneity may change CPU needs.
- Drop-in decoder replacement in experimental stacks (sector: R&D labs/academia/industry prototyping)
- What: Replace BP-OSD in offline and online experiments to achieve better accuracy and dramatically better tail latency, enabling longer experiments and real-time demonstrations without specialized hardware.
- Tools/products/workflows:
- Side-by-side A/B testing harnesses (BP-OSD vs beam search) with matched seeds; parameter sweeps for beam_width and masked-BP iteration budgets; experiment notebooks using Stim or equivalent.
- Assumptions/dependencies:
- Comparable or consistent syndrome acquisition interfaces; robust logging for post-hoc analysis; fidelity of circuit-level noise approximations to real device behavior.
- Enhanced decoding with XYZ syndrome usage (sector: QEC algorithmics/controls software)
- What: Use both X and Z stabilizers for decoding (XYZ-decoding) to capture Y-error information without severe degradation from short cycles; the beam search reliability-score handles oscillations better than BP-OSD.
- Tools/products/workflows:
- Toggle between XZ and XYZ at runtime; autotune to select XYZ when tail latency and accuracy improve; reliability-score visualization to identify oscillatory nodes.
- Assumptions/dependencies:
- Code families remain CSS; Tanner graphs with length-4 cycles don’t break the masked-BP heuristic; reliability scoring based on summed LLRs remains robust under device-specific noise biases.
- Benchmarking and code selection for quantum LDPC deployments (sector: academia and industry R&D)
- What: Use the decoder to compare QLDPC families (BB, HGP, etc.) under circuit-level noise with realistic tail-latency constraints; select codes that meet latency and accuracy targets for a given device.
- Tools/products/workflows:
- Benchmark suites reporting both LER and 99.9 percentile runtimes; parameterized scenarios (beam8/32/64); decision support for choosing code-distance and decoder settings.
- Assumptions/dependencies:
- Transferability of simulation results to hardware; stable calibration of noise parameters; correctness of syndrome extraction circuits used in simulations.
- Training and teaching resource for QEC (sector: education/academic courses)
- What: Use a simple, performant beam-search-plus-BP decoder as a teaching exemplar for modern QEC decoding trends, tail latency considerations, and heuristic design.
- Tools/products/workflows:
- Course modules/labs with adjustable beam search parameters; visualization of branching and pruning; comparison against BP-OSD and other decoders.
- Assumptions/dependencies:
- Availability of open-source reference implementations; reproducible simulation environments.
- Quantum networking/repeater prototypes using QLDPC (sector: quantum communications)
- What: Apply the same CPU-based decoder to near-term repeater nodes using QLDPC codes to reduce end-to-end latency and improve fidelity in proof-of-concept systems.
- Tools/products/workflows:
- On-node CPU decoding; integration with entanglement swapping control logic; per-link tail-latency monitoring.
- Assumptions/dependencies:
- Repeater noise and timing budgets compatible with the measured runtimes; alignment between circuit-level noise in compute and channel noise in networking.
- Policy and procurement guidance with tail-latency metrics (sector: policy/standards/program management)
- What: Adopt 99.9 percentile decoding latency as a standard metric in RFPs, capability statements, and architecture trade studies; recognize CPU-only decoding viability for certain hardware (e.g., trapped ions).
- Tools/products/workflows:
- Standardized benchmarking protocols; procurement checklists that include tail latency, energy, and scaling projections; cost models that compare CPU vs FPGA/ASIC decoders.
- Assumptions/dependencies:
- Community agreement on reporting standards; representative workloads and noise models; long-run stability of decoder performance.
Long-Term Applications
These use cases require further research, scaling, hardware co-design, or broader ecosystem development.
- Hardware acceleration for fast-cycle platforms (e.g., superconducting qubits) (sector: hardware design/ASIC/FPGA)
- What: Map beam search + masked BP to FPGA/ASIC for microsecond windows; leverage inherent parallelism across beams or across logical qubits.
- Tools/products/workflows:
- RTL implementations with on-chip memory for LLR states; beam pruning units; deterministic, low-jitter scheduling; hybrid CPU+FPGA co-processing.
- Assumptions/dependencies:
- Memory bandwidth and on-chip storage sufficient for larger codes; bounds on worst-case branching still compatible with hard real-time constraints; formal verification of deterministic latencies.
- Cluster-scale decoder orchestration for thousand-logical-qubit systems (sector: cloud/infra/DevOps)
- What: Build decoding microservices with QoS-aware scheduling, autoscaling, and beam_width adaptation to meet per-round SLOs across heterogeneous codes and devices.
- Tools/products/workflows:
- Kubernetes-style orchestration; telemetry-driven control loops adjusting decoder parameters to avoid tail blowups; resilience features (fallback to smaller beam widths under load).
- Assumptions/dependencies:
- Accurate load forecasting; minimal data-movement overhead from data acquisition to compute nodes; robust isolation between tenants.
- Cross-layer co-optimization of codes, circuits, and decoder (sector: compiler/runtime/QEC co-design)
- What: Co-design syndrome extraction schedules and Tanner graphs to reduce harmful short cycles, tuned to the beam-search reliability heuristic; adapt code choice dynamically in response to live noise.
- Tools/products/workflows:
- Compiler passes that reorder stabilizer measurements; online code switching; parameter autoselection driven by telemetry (e.g., oscillation detection via LLR sums).
- Assumptions/dependencies:
- Reliable, low-overhead observability of decoder internals; safe hot-swapping of decoder and code parameters in live experiments.
- Hybrid decoders and plug-in heuristics (sector: QEC algorithm engineering)
- What: Combine beam search with union-find, AC, BP-LSD, or post-selection to exploit complementary strengths; use reliability scoring as an early-stage pruning heuristic.
- Tools/products/workflows:
- Modular decoder framework with interchangeable front-ends/post-processors; policies that escalate through increasingly expensive stages only as needed.
- Assumptions/dependencies:
- Careful interface design to avoid redundant work; stability of hybrid pipelines across a range of noise regimes.
- Scaling studies and theory for large distances and asymptotics (sector: theory/academic research)
- What: Analyze scaling of accuracy and latency tails with code distance and degree distributions; explore connections to statistical mechanics (spin-glass behavior, expansion) informed by the reliability metric.
- Tools/products/workflows:
- Rigorous bounds on convergence/failure probabilities; asymptotic performance guarantees analogous to classical LDPC + BP; datasets and benchmarks at growing code sizes.
- Assumptions/dependencies:
- New theoretical tools to handle degeneracy and short cycles; availability of compute resources for large-scale simulations.
- ML-assisted branching and parameter control (sector: ML for systems)
- What: Learn node-selection policies, beam pruning criteria, or iteration budgets to minimize latency tails subject to accuracy targets; online adaptation to nonstationary noise.
- Tools/products/workflows:
- Reinforcement learning or bandit controllers; interpretable features derived from LLR oscillations and reliability scores; safety constraints to prevent catastrophic latency spikes.
- Assumptions/dependencies:
- Stable and ethical data collection; guardrails for QoS; explainability requirements in regulated environments.
- Standardization of decoding APIs and performance reports (sector: standards/policy)
- What: Define common APIs, telemetry fields (incl. 99.9 percentile), and test suites so vendors can certify decoders and enable fair comparison.
- Tools/products/workflows:
- Open benchmark corpora; conformance tests; consortium-driven specs.
- Assumptions/dependencies:
- Multi-stakeholder buy-in; maintenance of public testbeds.
- Quantum networking and distributed QEC at scale (sector: quantum internet)
- What: Deploy the decoder in repeater chains and distributed logical memories where timing budgets are tighter and losses differ from circuit noise; explore hardware acceleration for edge nodes.
- Tools/products/workflows:
- Co-design with entanglement distillation protocols; node-local accelerators; network-aware beam-width adaptation.
- Assumptions/dependencies:
- Accurate network noise/latency models; compatibility with link-layer protocols and clocking.
- Cross-domain adaptations to other loopy graphical models (sector: communications, storage, robotics, finance, energy)
- What: Port “masked BP + beam search + reliability score” to classical LDPC scenarios with problematic short cycles (e.g., high-density flash channels), or to general inference problems where BP oscillates:
- Communications/storage: enhanced decoding for dense LDPCs or channels with memory.
- Robotics/computer vision: robust approximate inference in SLAM or stereo with loopy factor graphs.
- Finance/energy: faster probabilistic inference in risk models or grid state estimation where BP oscillation is common.
- Tools/products/workflows:
- Factor-graph libraries with plugin decimation/branching; reliability-score diagnostics for oscillations; hybrid with existing LP/A* solvers.
- Assumptions/dependencies:
- Problem structure supports masked variable fixing without breaking correctness; beam pruning yields favorable speed-accuracy tradeoffs; domain-specific validation.
Notes on key assumptions and dependencies across applications
- Performance numbers are reported for specific codes (e.g., BB [[144, 12, 12]]), circuit-level depolarizing noise, and particular iteration budgets; extrapolation to larger distances and other noise models requires validation.
- Tail latency benefits rely on bounded branching via beam_width and effective pruning; aggressive settings increase compute and may harm worst-case latency.
- Real-time deployment hinges on end-to-end latency, including data movement from readout electronics to CPUs; OS jitter and I/O can dominate if not engineered carefully.
- XYZ-decoding benefits depend on the decoder’s robustness to short cycles; results may vary with code structure and hardware error asymmetries.
- For superconducting platforms with microsecond budgets, hardware acceleration or deeper co-design will likely be necessary.
Glossary
- 99.9 percentile runtime: The latency threshold such that 99.9% of decoding instances complete at or below this time. "to estimate the logical error rate and the 99.9 percentile runtime"
- Ambiguity Clustering (AC) decoder: A decoder that partitions matrix inversion into independent sub-problems to reduce average runtime. "The ambiguity clustering (AC) decoder~\cite{wolanski2024introducing}"
- ASIC: Application-Specific Integrated Circuit; specialized hardware used to accelerate decoding tasks. "without any parallelization or specialized hardware (FPGA, ASIC)"
- Automorphism-based decoder: A parallel BP approach that exploits code automorphisms by decoding multiple permuted inputs. "The automorphism-based decoder of~\cite{koutsioumpas2025automorphism} runs BP in parallel over many inputs obtained by applying an automorphism of the code."
- Backtracking: A search strategy that revisits earlier decisions to explore alternative branches when decoding. "Guided decimation is combined with backtracking in the decision-tree decoder of~\cite{ott2025decision}."
- Beam search decoder: A heuristic decoder that explores multiple candidate paths while pruning to a fixed beam width. "We propose a decoder for quantum low density parity check (LDPC) codes based on a beam search heuristic guided by belief propagation (BP)."
- Beam width: The maximum number of candidate paths retained during beam search. "A variant of our beam search decoder with a beam width of 64 achieves a reduction in logical error rate."
- Belief propagation (BP): A message-passing algorithm on a factor/Tanner graph used to infer marginal probabilities. "the so-called belief propagation (BP) decoder~\cite{pearl1982reverend}"
- Bivariate bicycle (BB) code: A family of quantum LDPC codes with favorable performance and structure. "We perform numerical simulations under circuit level noise for the bivariate bicycle (BB) code at noise rate "
- BP-GD (Guided Decimation): A BP variant that fixes the value of selected qubit nodes based on reliability. "Guided decimation (BP-GD) fixes the value of the most reliable qubit node~\cite{yao2024belief, gong2024toward}."
- BP-GDG decoder: A BP-based decoder that combines guided decimation with branching in early rounds. "Our beam search decoder shares several similarities with the BP-GDG decoder proposed in \cite{gong2024toward}."
- BP-LSD decoder: A localized statistics decoding approach that partitions inversion into smaller sub-problems. "The ambiguity clustering (AC) decoder~\cite{wolanski2024introducing} and the BP-LSD decoder~\cite{hillmann2024localized} eliminate the BP-OSD bottleneck by partitioning the matrix inversion into sub-problems"
- BP-OSD decoder: BP followed by ordered statistics decoding; accurate but often too slow due to matrix inversion. "and we compare with the BP-OSD decoder which has been the default quantum LDPC decoder for the past six years."
- Branching: Splitting a decoding path by fixing a selected error node to alternative values (0/1). "branching over the least reliable error node"
- Circuit level noise: A realistic error model that injects faults at the gate and measurement level of circuits. "We perform numerical simulations under circuit level noise"
- Circuit-level simulations: Performance studies that incorporate detailed gate- and measurement-level noise processes. "Moreover, circuit level simulations proved that several instances of quantum LDPC codes outperform surface codes"
- CSS codes: Calderbank–Shor–Steane codes where X and Z errors are corrected using separate stabilizer sets. "Since both BB codes and HGP codes simulated in this paper are CSS codes"
- Decision-tree decoder: A search-based decoder that explores a tree of constrained qubit assignments. "Guided decimation is combined with backtracking in the decision-tree decoder of~\cite{ott2025decision}."
- Depolarizing noise: A channel that applies random Pauli errors (including Y) with specified probabilities. "the circuit-level noise model assumes that qubits undergo depolarizing noise during unitary gates and idling time."
- Detector node: A node representing a stabilizer measurement (syndrome) in the Tanner graph. "and detector nodes associated with syndrome measurement results."
- FPGA: Field-Programmable Gate Array; reconfigurable hardware used for fast, low-latency decoding. "without any parallelization or specialized hardware (FPGA, ASIC)"
- Hypergraph product (HGP) code: A quantum LDPC construction from classical codes via hypergraph product. "hypergraph product (HGP) codes~\cite{tillich2013quantum}"
- Length-4 cycles: Short cycles in the Tanner graph that degrade BP accuracy and cause oscillations. "the induction of length-4 cycles in the corresponding Tanner graph"
- Log-likelihood ratio (LLR): The logarithm of odds of error/no-error used as BP messages and reliability measures. "the absolute value of the sum of its posterior LLRs over all BP iterations in the current round."
- Logical error rate: The probability that decoding yields a logical failure (incorrect logical state). "A variant of our beam search decoder with a beam width of 64 achieves a reduction in logical error rate."
- Masked BP: Running BP while fixing (masking) selected error-node values and excluding them from further updates. "BP is replaced by a masked BP ignoring the previously fixed error nodes."
- Min-sum BP: An approximation of BP using min-sum message updates instead of exact sum-product. "BP-OSD decoder is configured with 30 min-sum BP iterations"
- Minimum-weight solution: The valid correction with the lowest estimated weight selected among candidate paths. "The decoder then returns the minimum-weight solution it finds."
- Order-10 combination-sweep OSD: A specific configuration of ordered statistics decoding with sweep order 10. "BP-OSD decoder is configured with 30 min-sum BP iterations followed by order-10 combination-sweep OSD."
- Ordered Tanner forest post-processing (BP-OTF): A cycle-free post-processing step to improve BP-based decoding. "The ordered Tanner forest post-processing (BP-OTF) is executed in a cycle-free subgraph of the Tanner graph~\cite{iolius2024almost}."
- Pauli-Y component: The Y error in depolarizing noise that triggers both X- and Z-type stabilizers. "Since depolarizing noise includes a Pauli-Y component"
- Pruning: Discarding low-scoring paths to keep only the most promising candidates within the beam width. "pruning to reduce the number of paths to the beam width"
- Reliability metric: A per-node measure (e.g., absolute summed LLR) used to identify unstable or oscillating nodes. "the reliability metric for each error node is the absolute value of the sum of its posterior LLRs over all BP iterations in the current round."
- Reliability score: A per-path aggregate metric used to rank and prune candidate decoding paths. "the set is sorted by a reliability score"
- Stabilizer code: A quantum error-correcting code defined by commuting Pauli operators (stabilizers). "the concept of marginal error probability for a single qubit in a stabilizer code is not well-defined."
- Stabilizer inactivation (SI): A BP modification that removes (inactivates) the least reliable stabilizer to reduce harmful cycles. "Stabilizer inactivation (SI) removes the value of the least reliable stabilizer node~\cite{du2022stabilizer}."
- Stabilizer node: A Tanner graph node representing a stabilizer constraint. "Stabilizer inactivation (SI) removes the value of the least reliable stabilizer node"
- Syndrome extraction round: One cycle of measuring stabilizers to obtain error syndromes. "runtime per syndrome extraction round below 1ms"
- Tanner graph: A bipartite graph connecting error nodes to detector (stabilizer) nodes for message passing. "sending data through the edges of the graph representing the code, which we call the Tanner graph"
- Trapped ion architectures: Quantum computing platforms where decoding latency budgets are on the order of milliseconds. "We identify the beam search decoder with beam width of 32 as a promising candidate for trapped ion architectures"
- Union find decoder: A fast decoder (not originally for LDPC) adapted to quantum LDPC, bottlenecked by matrix inversion. "This matrix inversion is also the bottleneck when adapting the union find decoder to quantum LDPC codes~\cite{delfosse2022toward}."
- XYZ-decoding: A strategy that uses both X- and Z-type stabilizers simultaneously for decoding. "which utilizes both X and Z syndrome outcomes simultaneously for decoding"
- XZ-decoding: A strategy that decodes X and Z errors separately using only the corresponding stabilizer type. "plots the logical error rate of the BB code using two strategies: standard XZ-decoding and XYZ-decoding"
Collections
Sign up for free to add this paper to one or more collections.