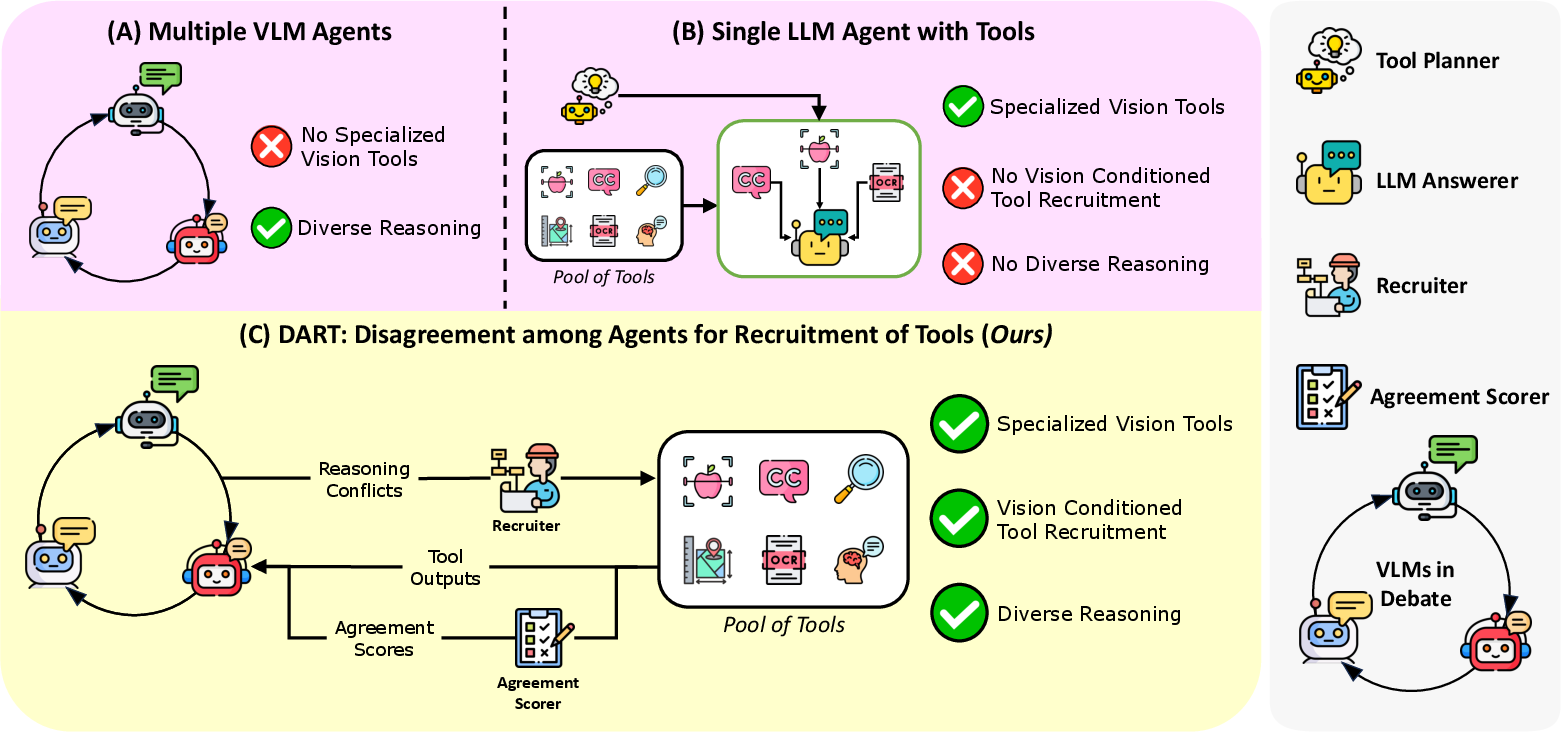
DART: Leveraging Multi-Agent Disagreement for Tool Recruitment in Multimodal Reasoning
Abstract: Specialized visual tools can augment LLMs or vision LLMs with expert knowledge (e.g., grounding, spatial reasoning, medical knowledge, etc.), but knowing which tools to call (and when to call them) can be challenging. We introduce DART, a multi-agent framework that uses disagreements between multiple debating visual agents to identify useful visual tools (e.g., object detection, OCR, spatial reasoning, etc.) that can resolve inter-agent disagreement. These tools allow for fruitful multi-agent discussion by introducing new information, and by providing tool-aligned agreement scores that highlight agents in agreement with expert tools, thereby facilitating discussion. We utilize an aggregator agent to select the best answer by providing the agent outputs and tool information. We test DART on four diverse benchmarks and show that our approach improves over multi-agent debate as well as over single agent tool-calling frameworks, beating the next-strongest baseline (multi-agent debate with a judge model) by 3.4% and 2.4% on A-OKVQA and MMMU respectively. We also find that DART adapts well to new tools in applied domains, with a 1.3% improvement on the M3D medical dataset over other strong tool-calling, single agent, and multi-agent baselines. Additionally, we measure text overlap across rounds to highlight the rich discussion in DART compared to existing multi-agent methods. Finally, we study the tool call distribution, finding that diverse tools are reliably used to help resolve disagreement.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DART, a way for multiple AI “agents” to work together to answer questions about images. When these agents disagree about what they see or how to answer, DART brings in the right expert tools (like text-reading or object-finding tools) to settle the argument. This makes the final answer more accurate and the discussion more useful.
What questions were the researchers trying to answer?
- How can we decide which vision tools to use, and when, so that AI agents can better understand images and answer questions?
- Can using disagreements between agents to trigger tool use lead to better answers than just having agents debate, or having a single AI plan tool use?
- Does this approach work across different kinds of image tasks, including tricky ones and even medical images?
- Does adding expert tools make agent discussions richer (with more new ideas) instead of repetitive?
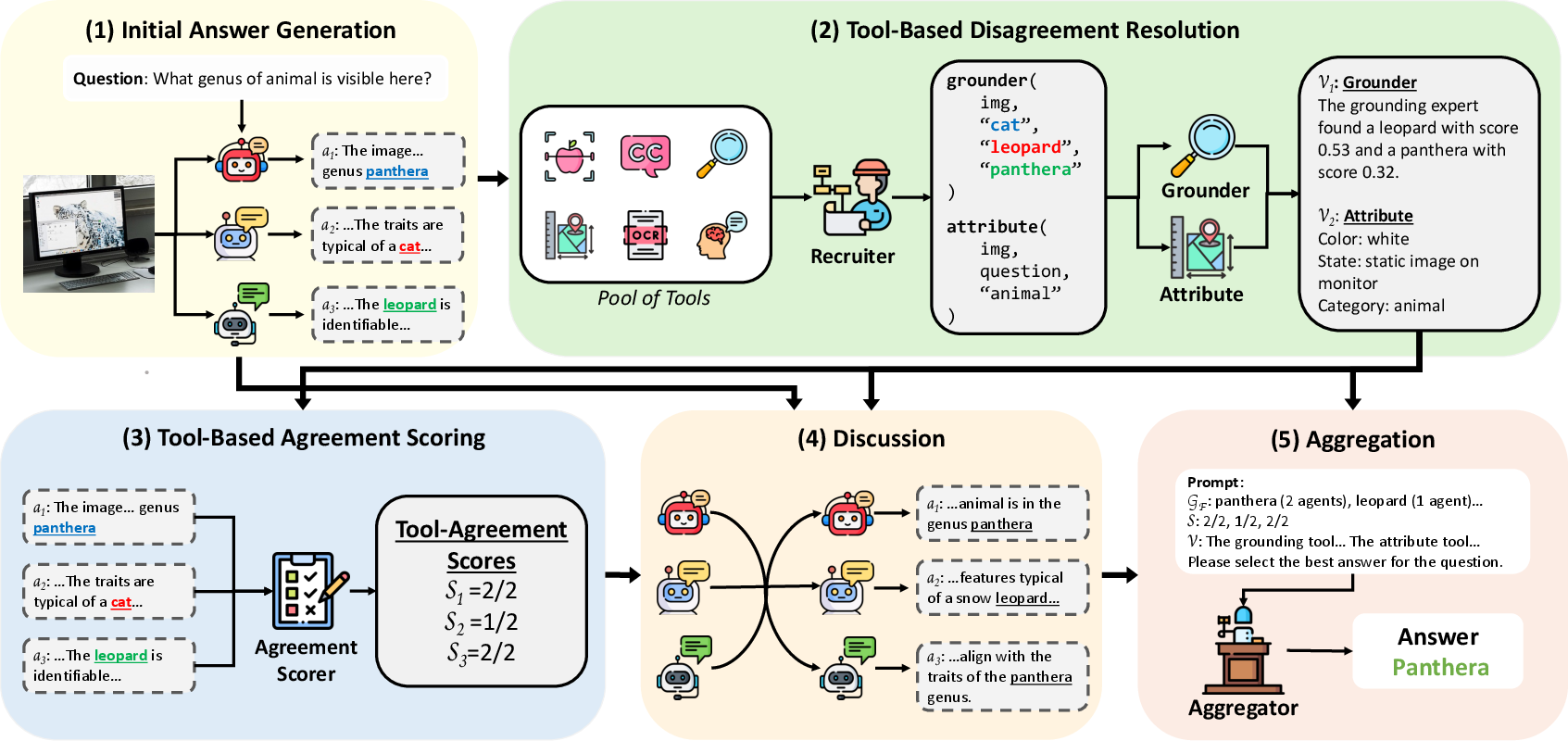
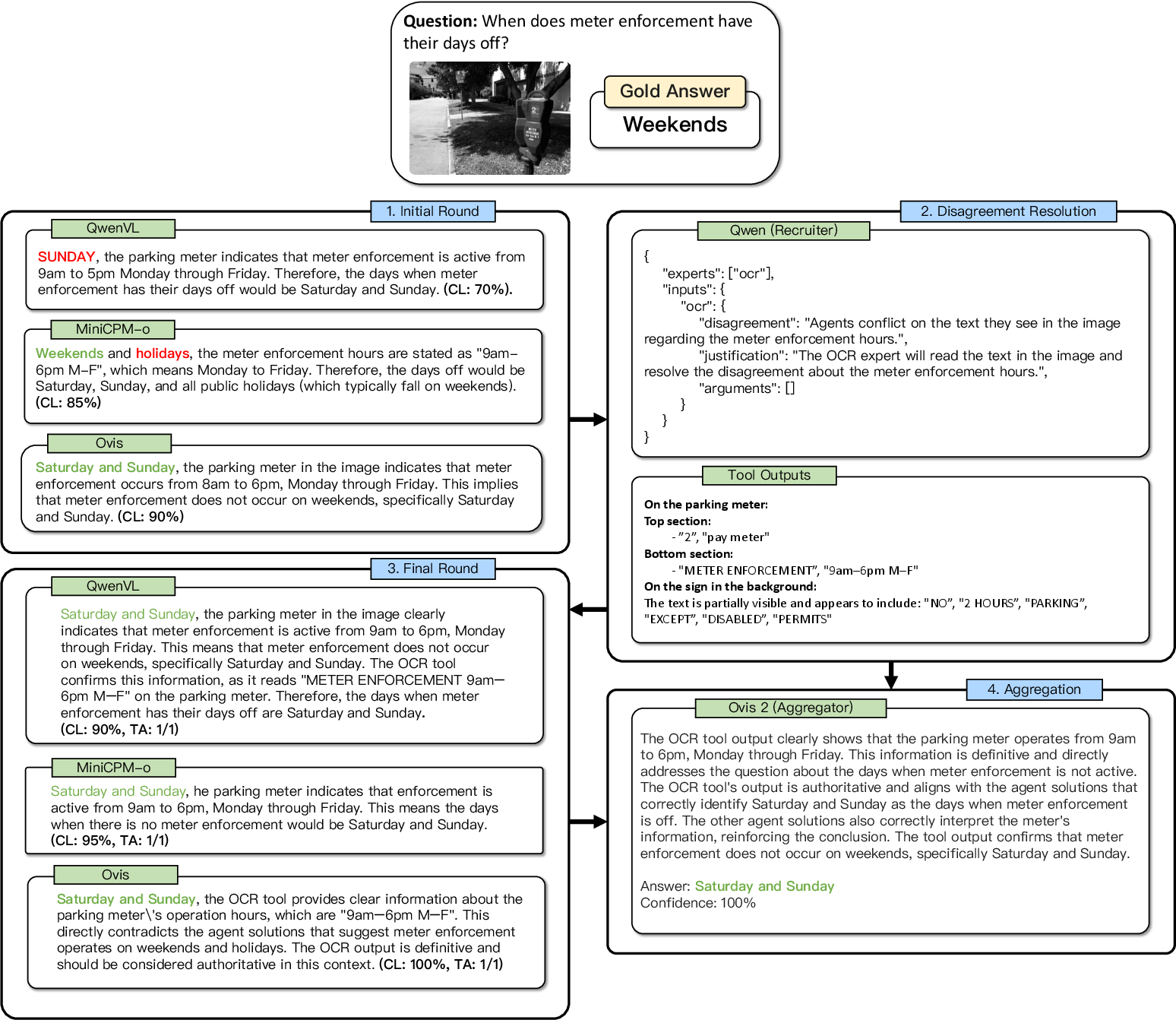
How does DART work?
Imagine three students looking at a picture and answering a question. They explain their thinking. If they disagree, a teacher brings in experts—like a colorimeter to check colors or a magnifier to read tiny text—to help them figure out who’s right. Then they discuss again and pick the best final answer.
DART follows five simple steps:
1) Initial Answers
Several vision-LLMs (VLMs)—AIs that can look at images and read questions—each give:
- an answer,
- a short explanation of their reasoning,
- a confidence score.
The system groups these answers to see where opinions differ.
2) Resolve Disagreements with Tools
A “recruiter” agent looks at the disagreements and decides which expert tools could help. It doesn’t just call tools randomly; it picks tools that address the exact point of conflict.
Common tool types include:
- Grounding: highlight specific objects the agents talked about.
- Object detection: find and label things in the image (like “dog,” “car”).
- OCR: read text in the image (like signs or labels).
- Spatial reasoning: check where things are relative to each other.
- Captioning: create a detailed description of the scene.
- Attribute detection: check details like color, material, or patterns.
3) Score Agreement with the Tools
Another AI compares each agent’s answer and reasoning to what the expert tools found. If an agent’s view matches the tools’ evidence, it gets a higher agreement score. Think of this like checking which student’s explanation lines up with the textbook.
4) Discussion Round
All agents see:
- the expert tools’ outputs,
- each other’s answers,
- the agreement scores.
They then revise their answers, giving more weight to the tools (since those are specialized experts). The idea is to encourage more thoughtful discussion based on new, solid evidence.
5) Final Aggregation
A final “aggregator” agent reviews the revised answers plus tool evidence and picks the single best answer with a short reasoning.
What did they find?
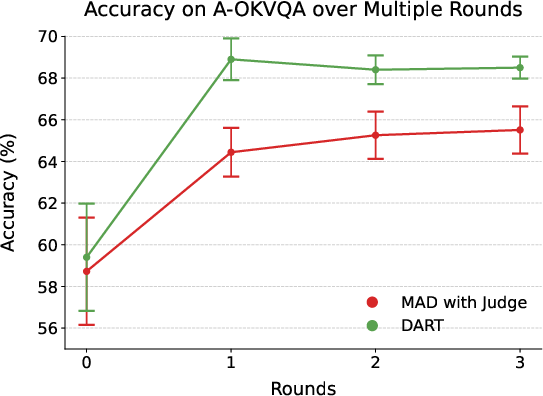
- DART beat strong baselines on several benchmarks:
- A-OKVQA (uses world knowledge): DART was about 3.4% better than the next-best multi-agent debate system and 4.3% better than the best single-agent method.
- MMMU (large, diverse tasks): about 2.4% better than the next-best multi-agent system.
- NaturalBench (tricky, human-easy but AI-hard images): DART also came out on top.
- M3D (medical images): adding a medical expert tool helped DART outperform the best single-agent model by about 1.3%.
- DART’s discussions were more “fruitful”:
- When comparing text overlap between initial and revised answers, DART showed much lower overlap. That means agents were adding new ideas and not just repeating themselves—thanks to tool evidence.
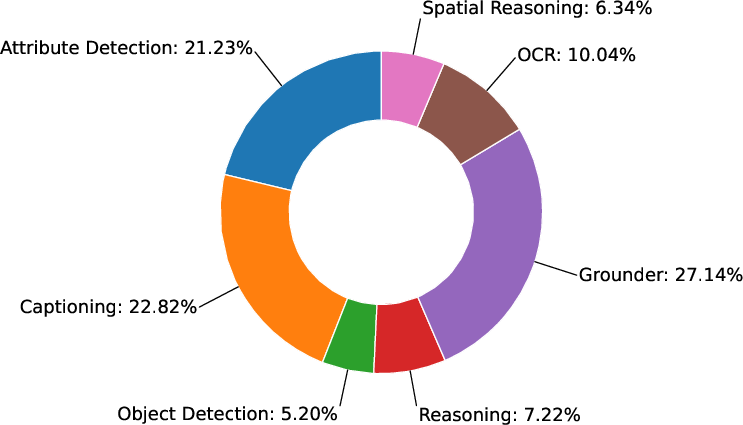
- Tools were used in a balanced way:
- Grounding, captioning, and attribute detection were called often (each over 20% of the time), which shows many disagreements were about scene details like “what is there,” “how it looks,” and “how to describe it.”
- OCR, spatial reasoning, and object detection were used less often but still mattered.
- Diversity among agents helps:
- Using different models leads to more meaningful disagreements (about 1.32 per question) than using one model multiple times (about 0.49). More disagreement means more chances to call useful tools, and better final answers.
- Using only one model in DART reduced accuracy by about 4.6% on A-OKVQA.
- Expert tools really matter:
- Replacing specialized tools with a single general-purpose model made performance drop by about 2.9%.
- Removing expert tools caused a drop similar to removing diverse agents. Both parts—multiple agents and expert tools—are important.
- Agreement scores (the “which student matches the expert?” measure) also improved results by about 1.1%.
Why does this matter?
DART shows a practical way to make AI better at understanding images and answering questions:
- It treats AI agents like a team that can debate and learn from outside experts, instead of guessing blindly.
- It doesn’t plan tool use in a vacuum; it triggers tools when agents actually disagree, saving time and focusing on the real problem.
- It adapts to new areas—like medicine—by adding the right domain tools.
- It makes discussions more evidence-based and less repetitive, which leads to more reliable answers.
This points toward a future where AI systems act like smart teams: generalists who reason and specialists who provide targeted, factual checks. That can improve accuracy and trust in AI for everyday tasks, education, and high-stakes fields like healthcare.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to be concrete and actionable for future research.
- Tool correctness and reliability: The framework instructs agents to defer to expert tools over VLM reasoning if they conflict, but there is no systematic evaluation of tool error rates, failure modes, or inter-tool disagreement resolution. When tools are wrong or disagree with each other, how should the system detect and handle these cases?
- Coarse agreement scoring: Agreement is scored as binary per tool and averaged uniformly across tools. This ignores partial agreement, relative importance of tools, tool-specific confidence scores, and differing tool accuracies across skills or domains. Can calibrated, continuous, or learned per-tool weights improve aggregation and robustness?
- Lack of ground-truth validation of “agreement” signal: The paper does not quantify how well agreement scores correlate with true answer correctness or visual perception accuracy across datasets and question types. A formal calibration analysis and statistical validation is missing.
- Disagreement-only tool recruitment: Tools are invoked only when agents disagree; if agents agree on a wrong answer (shared blind spot), tools are not recruited. When and how should tools be called proactively (e.g., based on uncertainty, question type, or image complexity) even under agent agreement?
- Recruitment agent reliability: The LLM-based recruitment agent decides which tools to call and generates tool inputs, but there is no measurement of its precision/recall in detecting disagreement points, nor the quality/consistency of generated tool parameters across prompts and seeds.
- Tool input generation brittleness: Tool inputs (queries, attributes, spatial relations) are produced by an LLM without a formal specification or constraints. How sensitive is performance to prompt phrasing and parameterization quality, and can structured interfaces or schema validation reduce errors?
- Conversion of non-linguistic tool outputs: Outputs from detectors/grounders (e.g., boxes, scores) are minimally post-processed into text. This likely discards confidence, geometry, and quantitative information. What is the impact of richer structured fusion (e.g., using coordinates, scores, object graphs) on reasoning and aggregation?
- Aggregator agent selection and training: The aggregator is a prompted VLM (Ovis2 found best empirically), but there is no principled method or training objective for aggregation, nor analysis of aggregator bias (e.g., toward longer or tool-heavy rationales). Could a trained aggregator or learned voting scheme outperform prompt-based selection?
- Number and diversity of agents: Gains with three diverse agents are shown, but there is no analysis of the optimal number of agents, diversity metrics, diminishing returns, or sensitivity to the choice of backbone models. How does performance scale with agent count and heterogeneity?
- Efficiency, latency, and cost trade-offs: Multi-agent debate plus tool calling introduces computational and latency overhead. The main text lacks detailed runtime and cost profiling per dataset, per question, and per tool call. What are the Pareto frontiers between accuracy and resource usage?
- Statistical rigor: Improvements are reported without confidence intervals, variance across seeds/temperatures, or statistical significance tests. Future work should provide error bars and hypothesis testing to substantiate reported gains.
- Dataset coverage and granularity: Evaluation is limited to four VQA-style benchmarks (mostly images; one medical 3D dataset). Generalization to video QA, interactive tasks, referential grounding, complex spatial-temporal reasoning, open-ended generative tasks, and non-visual tool integration (e.g., web search, KB retrieval) remains unexplored.
- Category-level performance analysis: On M3D, DART does not consistently outperform baselines across all categories (e.g., Organ, Abnormality). Fine-grained error analyses and per-category failure modes are not provided, limiting targeted improvements.
- Tool portfolio design: The tool set is fixed and manually chosen. There is no method to learn which tools to include, prioritize, or retire, nor to automatically incorporate new tools beyond manual addition (as with MedGemma). Can meta-learning or policy learning optimize tool portfolios per domain and question type?
- Round structure and discussion dynamics: The paper does not systematically study the number of discussion rounds, convergence behavior, or whether multiple rounds yield diminishing returns or amplify errors. When should discussion stop, and how do different debate protocols affect outcomes?
- Robustness to adversarial or noisy inputs: Sensitivity to adversarial questions, adversarial images (e.g., occlusions), tool perturbations, and inconsistent agent rationales is not evaluated. What defenses or robustness mechanisms are needed?
- Bias and fairness considerations: Tools and agents may propagate or amplify dataset or model biases. The paper does not assess demographic or content biases, nor fairness impacts across subpopulations or domains.
- World knowledge tools: A-OKVQA requires external knowledge, yet the tool set is primarily visual. The impact of adding non-visual tools (e.g., structured KBs, web search, calculators) and policies for when to recruit them is unexplored.
- Agreement vs. self-confidence fusion: Agents have self-reported confidence and tool-based agreement scores, but there is no principled fusion method (e.g., Bayesian/ensemble calibration, learning-to-rank) or analysis of conflicts between the two signals.
- Error cascades from tool prompts: If the recruitment agent misidentifies disagreement or crafts suboptimal tool prompts (e.g., wrong attribute names), downstream reasoning can be derailed. How can verification, iterative refinement, or constraint-based prompting reduce such cascades?
- Reproducibility details: Key prompt templates (recruitment, agreement scoring, aggregation), temperatures, tool parameterization schemas, and stopping criteria are not fully specified in the main text. A standardized protocol would aid reproducibility and fair comparison.
- Measuring “fruitful discussion”: Lower text overlap is used as a proxy for richer debate, but this metric can favor verbosity or lexical variation without improving correctness. What better measures (e.g., factual grounding, claim verification, causal reasoning steps) can quantify discussion quality?
- Unified structured fusion: The current approach relies on LLMs to read tool outputs and agent rationales. A missing direction is a structured fusion layer (e.g., graph-based or neuro-symbolic) that aggregates multi-tool evidence with uncertainty, enabling more interpretable and reliable aggregation.
- Safety and reliability guarantees: There are no guarantees on worst-case behavior, nor mechanisms for abstention or deferral to human oversight when tools/agents disagree or confidence is low. Designing fail-safe policies remains open.
Glossary
- A-OKVQA: A benchmark for visual question answering that requires external/world knowledge. "beating the next-strongest baseline (multi-agent debate with a judge model) by 3.4% and 2.4% on A-OKVQA and MMMU respectively."
- Aggregation: The final pipeline step where the system compiles tool outputs and agent answers to produce the final answer. "in the (5) Aggregation step."
- Aggregator agent: A model that selects the best final answer using agent outputs and tool information. "We utilize an aggregator agent to select the best answer by providing the agent outputs and tool information."
- Agreement scorer: An LLM module that compares agent outputs to tool outputs and assigns agreement labels. "an agreement scorer LLM produces a binary agreement score"
- Agreement scores: Scores indicating how closely an agent’s outputs align with expert tool outputs. "by providing tool-aligned agreement scores that highlight agents in agreement with expert tools"
- Attribute detection: Identifying properties (e.g., color, texture, style) of objects in an image. "DART uses grounding, object detection, OCR, spatial reasoning, captioning, and attribute detection tools."
- Captioning: Generating descriptive text that summarizes an image’s content. "DART uses grounding, object detection, OCR, spatial reasoning, captioning, and attribute detection tools."
- Chain-of-Thought (CoT): A prompting approach that elicits step-by-step reasoning from models. "we prompt each answering agent Ai to use CoT to generate a candidate answer"
- Chameleon: A tool-calling system that uses an LLM planner to invoke tools via word matching. "Chameleon adopts a more robust compositional approach, utilizing an LLM-based planner"
- DART: A multi-agent framework that leverages inter-agent disagreement to recruit expert tools in multimodal reasoning. "We introduce DART, a multi-agent framework that uses disagreements between multiple debating visual agents to identify useful visual tools"
- Debate with Consensus: A multi-agent baseline that selects the most frequent answer among agents. "For multi-agent baselines, we use Debate with Consensus and Debate with Judge."
- Debate with Judge: A multi-agent baseline where a separate judge model selects the best answer. "For multi-agent baselines, we use Debate with Consensus and Debate with Judge."
- Finetuned models: Models adapted to specific tasks through additional training to improve specialized performance. "The grounding, object detection, OCR, and spatial reasoning tools are implemented as expert, finetuned models."
- Grounder: A grounding tool that links textual phrases to specific regions in an image. "the grounder can be used if an agent mentioned an object that another agent missed"
- Grounding: Aligning text references (phrases) with corresponding visual regions in an image. "grounding, OCR, and spatial reasoning"
- GroundingDINO: A specialized model for phrase grounding/localization in images. "GroundingDINO (grounding)"
- InternVL-2.5 MPO: A vision-LLM variant used as a tool for captioning, attribute detection, and reasoning. "InternVL-2.5 MPO (captioning, attribute, and reasoning)"
- Jaccard Index: A set-based similarity metric measuring overlap between token sets. "with ROUGE-L and Jaccard Index decreasing by 0.173 and 0.289 respectively"
- LLaVA-1.6: A vision-LLM baseline used for single-agent comparisons. "we include LLaVA-1.6 (Mistral)"
- MedGemma 4B: A medical-domain multimodal model used as an expert tool. "we additionally insert MedGemma 4B into the pool of tools to serve as a medical expert."
- M3D-VQA: A medical visual question answering dataset with 3D medical scans. "we evaluate how well DART adapts to a new tool by testing it on M3D-VQA"
- MiniCPM-o 2.6: A vision-LLM used as an answering agent in experiments. "MiniCPM-o 2.6"
- MMMU: A large, multi-discipline multimodal understanding and reasoning benchmark. "on A-OKVQA and MMMU respectively."
- Multi-agent debate: A method where multiple agents discuss and refine reasoning to improve answers. "engaging in multi-agent debate"
- NaturalBench: A benchmark of natural adversarial VQA samples aimed at testing visual comprehension. "NaturalBench, which is designed to rigorously test VLMs on their visual comprehension"
- Object detection: Identifying and localizing objects within an image. "object detection, OCR, spatial reasoning"
- OCR: Optical character recognition; extracting textual content from images. "object detection, OCR, spatial reasoning"
- OCR-Qwen: An OCR-specific tool based on the Qwen family. "OCR-Qwen (OCR)"
- Ovis2: A vision-LLM used as both answering agent and aggregator. "Ovis2"
- Qwen2.5-VL: A vision-LLM used as an answering agent baseline. "Qwen2.5-VL"
- Recruitment agent: An LLM that detects inter-agent disagreements and selects tools to resolve them. "We detect disagreements among the agents' answers {ai} and answer reasoning chains {ri} using a recruitment agent."
- ROUGE-1/2/L: N-gram overlap metrics used to measure textual similarity between responses. "across all metrics (ROUGE-1/2/L and Jaccard Index)"
- Self-Consistency: A method that samples multiple reasoning paths and selects a consistent answer. "Self-Consistency (5-way)"
- Self-Refinement: A method where a model iteratively improves its own output via self-feedback. "Self-Refinement"
- SpaceLLaVA: A model/tool focused on spatial reasoning in visual scenes. "SpaceLLaVA (spatial)"
- Spatial reasoning: Understanding spatial relationships and layouts in images. "grounding, OCR, and spatial reasoning"
- Tool-Based Agreement Scoring: The pipeline step computing agreement between agents and tool outputs. "Then, in (3) Tool-Based Agreement Scoring, DART compares the expert tool outputs and agent answers to calculate agreement scores."
- Tool-Based Disagreement Resolution: The pipeline step where tools are invoked to resolve detected inter-agent disagreements. "our method uses the answers and reasoning chains from the answering agents in (2) Tool-Based Disagreement Resolution"
- Tool call distribution: The breakdown of how frequently different tools are invoked. "Finally, we study the tool call distribution, finding that diverse tools are reliably used to help resolve disagreement."
- ViperGPT: A tool-calling system that generates executable code to invoke external tools. "ViperGPT utilizes a code generation model to predict executable code that leverages required tools for a given question."
- Vision-LLM (VLM): A model that processes and reasons over both visual and textual inputs. "vision-LLMs (VLMs)"
- Visual Question Answering (VQA): Answering natural-language questions about images. "Visual Question Answering (VQA)"
- YOLOv11: An object detection model used as an expert tool. "YOLOv11 (object detection)"
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating DART’s disagreement-triggered tool recruitment, multimodal agents, and tool-aligned agreement scoring into existing systems and workflows.
- Multimodal customer support for e-commerce and logistics — Sector: software/e-commerce. Tools/workflow: VLM agents debate product questions from user-uploaded photos; disagreements trigger attribute detection, OCR, grounding (e.g., color, size, SKU), aggregator returns a calibrated answer with agreement scores; low agreement escalates to human. Dependencies: reliable OCR/grounding models, latency budgets, privacy compliance for user images.
- Accessibility assistant for visually impaired users — Sector: healthcare/daily life. Tools/workflow: on-device or mobile assistant that reads signs/menus (OCR), describes scenes (captioning/attribute tools), and indicates relative positions (spatial reasoning); disagreement gating increases trust before speaking outputs. Dependencies: safe local processing or secure cloud, robust OCR in diverse lighting/fonts, consent and privacy.
- Radiology triage and QA copilot — Sector: healthcare. Tools/workflow: apply DART to 3D medical image Q&A (e.g., M3D) with a medical expert tool (e.g., MedGemma); disagreement between generalist agents prompts domain tools; outputs include agreement scores to flag studies needing attention. Dependencies: non-diagnostic use initially, integration with PACS/RIS, HIPAA compliance, clinical validation; regulatorily constrained deployment.
- Industrial inspection and quality control — Sector: manufacturing/robotics. Tools/workflow: VLM agents review line images; when defect identification disagrees, call object detection/grounding/spatial tools; aggregator provides pass/fail plus localized evidence and confidence. Dependencies: calibrated cameras, representative training data, real-time inference constraints, plant network security.
- Document processing and KYC/AML verification — Sector: finance/government. Tools/workflow: disagreement-triggered OCR and grounding to extract fields from IDs, forms, invoices; agreement scores route uncertain cases to human review; audit logs preserve tool calls and evidence. Dependencies: high-accuracy OCR for diverse languages/fonts, PII protection, regulatory auditability.
- Content moderation and visual misinformation detection — Sector: media/platforms. Tools/workflow: agents debate claim-image pairs; disagreements trigger grounding/OCR/attribute tools to check presence of claimed objects/text; agreement scores support moderator decisions. Dependencies: scalable tool orchestration, human-in-the-loop policies, dataset drift monitoring.
- Data labeling and curation for ML pipelines — Sector: academia/MLops/software. Tools/workflow: auto-label VQA-style tasks; only hard/disagreed items invoke tools; agreement scores set confidence for acceptance and trigger relabeling; text-overlap metrics monitor discussion quality. Dependencies: labeling budget, annotation guidelines, tool APIs, reproducibility standards.
- UI automation and software testing from screenshots — Sector: software/QA. Tools/workflow: agents interpret UI states; disagreements call OCR/spatial reasoning to verify element positions, texts, and states; generate test assertions with confidence. Dependencies: screenshot fidelity, tool robustness to GUI variations, integration with CI pipelines.
- STEM tutoring on diagrams, charts, and figures — Sector: education. Tools/workflow: students upload visuals; agents debate interpretations; recruit spatial/attribute/OCR tools on disagreements; explain answers with evidence and agreement scores. Dependencies: curriculum-aligned prompts, pedagogical guardrails, avoidance of hallucinations on novel diagrams.
- Remote infrastructure monitoring (e.g., energy/utilities) — Sector: energy/public works. Tools/workflow: camera feeds analyzed by agents; disagreements trigger object detection/grounding to confirm anomalies (leaks, corrosion); alerts include visual evidence and confidence. Dependencies: edge compute or low-latency cloud, robust models in outdoor conditions, alarm fatigue mitigation.
- Multimodal model evaluation and benchmarking — Sector: academia. Tools/workflow: use DART’s disagreement analytics, text-overlap metrics, and tool-call distribution to study perception gaps, calibrate aggregators, and design new benchmarks (e.g., NaturalBench-style adversarial sets). Dependencies: compute resources, diverse agent pools, standardized reporting.
Long-Term Applications
The following applications require further research, domain-specific tool maturation, scaling, validation, or regulatory pathways before broad deployment.
- Perception arbitration in autonomous robots and vehicles — Sector: robotics/automotive. Tools/workflow: onboard multi-agent perception; disagreement triggers specialized modules (e.g., LiDAR-camera fusion, fine-grained object detectors); agreement thresholds gate planning actions. Dependencies: real-time inference on edge hardware, safety certification, robust tool coverage across weather/lighting, formal verification of arbitration logic.
- Clinical decision support for diagnosis across modalities (CT/MRI/ultrasound) — Sector: healthcare. Tools/workflow: multimodal agents with domain expert tools analyze studies; calibrated agreement used as a decision aid and triage signal; provenance logs for audit. Dependencies: FDA/CE approval, large-scale clinical validation, bias assessment, interoperability (DICOM), stringent privacy.
- AI governance and auditability frameworks based on agreement scores — Sector: policy/regulation/compliance. Tools/workflow: require systems to log disagreement-triggered tool calls, evidence, and agreement metrics; use thresholds for risk class routing and human review; standardize explainability artifacts. Dependencies: policy adoption, standards bodies participation, consensus on metrics and acceptable risk, secure logging.
- Scientific image analysis copilots (microscopy, astronomy, materials) — Sector: research/industrial R&D. Tools/workflow: plug domain-specific vision tools into DART; use disagreement recruitment to reduce false positives; provide evidence-backed results for scientists. Dependencies: high-quality domain tools, labeled datasets, reproducible pipelines, validation against established methods.
- Geospatial and remote sensing for disaster response and climate monitoring — Sector: public sector/NGOs/energy. Tools/workflow: agents analyze satellite/aerial imagery; disagreements trigger change detection/segmentation tools; outputs include spatial evidence and confidence for responders. Dependencies: specialized tools for large imagery, temporal modeling, data access agreements, operational readiness.
- Video QA and temporal reasoning (e.g., integrating TraveLER-like planners) — Sector: software/media/surveillance. Tools/workflow: extend DART to video; disagreements across frames recruit temporal/spatial tools; plan re-queries and evidence accumulation. Dependencies: efficient video tools, temporal grounding reliability, compute scaling, latency.
- Generalized tool marketplace and dynamic router — Sector: software/platforms. Tools/workflow: productize DART as an orchestration platform where third-party expert tools register capabilities; disagreement-triggered router selects tools; standardized evidence schemas. Dependencies: ecosystem standards, tool certification, billing/security, developer adoption.
- On-device edge deployments for privacy-preserving multimodal assistants — Sector: consumer/IoT/enterprise. Tools/workflow: quantized agents and tools running locally; disagreement gating reduces compute and preserves privacy; occasional cloud fallback. Dependencies: model compression, hardware acceleration, battery constraints, incremental updates.
- Cross-modal expansion to audio, time-series, and tabular tools — Sector: finance/industrial/healthcare. Tools/workflow: extend disagreement-triggered recruitment beyond vision (e.g., waveform analyzers, ECG tools, anomaly detection on sensors); multimodal aggregator calibrates across modalities. Dependencies: mature domain tools, multi-modal alignment methods, unified evidence scoring.
- Safety-critical decision gating and risk-aware orchestration — Sector: aviation/defense/process industries. Tools/workflow: formalize agreement thresholds and uncertainty budgeting; only permit actions when tool-agent alignment exceeds certified bounds; log provenance for incident analysis. Dependencies: rigorous reliability modeling, standards compliance, human oversight protocols.
- Training paradigms that leverage disagreement as curriculum signals — Sector: academia/ML research. Tools/workflow: use disagreement points to generate hard examples, improve perception-training for VLMs, and fine-tune tool routers/aggregators. Dependencies: scalable training infrastructure, high-quality labels at disagreement loci, method generalization across tasks.
- Legal and digital forensics evidence analysis — Sector: legal/public safety. Tools/workflow: apply DART to verify visual claims (presence, text, tampering cues); disagreement triggers specialized forensic tools; aggregate with confidence for casework. Dependencies: validated forensic tools, chain-of-custody requirements, admissibility standards.
Collections
Sign up for free to add this paper to one or more collections.