MuSASplat: Efficient Sparse-View 3D Gaussian Splats via Lightweight Multi-Scale Adaptation
Abstract: Sparse-view 3D Gaussian splatting seeks to render high-quality novel views of 3D scenes from a limited set of input images. While recent pose-free feed-forward methods leveraging pre-trained 3D priors have achieved impressive results, most of them rely on full fine-tuning of large Vision Transformer (ViT) backbones and incur substantial GPU costs. In this work, we introduce MuSASplat, a novel framework that dramatically reduces the computational burden of training pose-free feed-forward 3D Gaussian splats models with little compromise of rendering quality. Central to our approach is a lightweight Multi-Scale Adapter that enables efficient fine-tuning of ViT-based architectures with only a small fraction of training parameters. This design avoids the prohibitive GPU overhead associated with previous full-model adaptation techniques while maintaining high fidelity in novel view synthesis, even with very sparse input views. In addition, we introduce a Feature Fusion Aggregator that integrates features across input views effectively and efficiently. Unlike widely adopted memory banks, the Feature Fusion Aggregator ensures consistent geometric integration across input views and meanwhile mitigates the memory usage, training complexity, and computational costs significantly. Extensive experiments across diverse datasets show that MuSASplat achieves state-of-the-art rendering quality but has significantly reduced parameters and training resource requirements as compared with existing methods.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces MuSASplat, a way to build 3D scenes from just a few photos without needing to know where the camera was for each photo. It aims to make the process both fast and light on computer memory, while still producing high‑quality 3D views.
Imagine painting a 3D scene by placing lots of tiny, soft, colored “blobs” in space. When you look at them from different angles, they blend to form the scene. That’s the basic idea behind 3D Gaussian splats. MuSASplat figures out where to put those blobs using only a few photos and much less computing power than earlier methods.
The main questions the paper asks
- How can we make good 3D models from only a small number of photos, without knowing the exact camera positions and without spending a lot of time and memory training a big model?
- Can we fine‑tune only small parts of a large vision model instead of the whole thing, and still get great results?
- Can we combine information from multiple photos quickly and consistently, without using slow, memory‑hungry “memory banks”?
How the method works (in simple terms)
To understand MuSASplat, it helps to know three ideas:
- 3D Gaussian splats: Think of building a 3D scene from many tiny, fuzzy balls of color. Together, they create realistic views from new angles and can be rendered quickly.
- Pose‑free: Most 3D methods need to know where each photo was taken (camera “pose”). This method does not—it learns geometry directly from the images.
- Vision Transformer (ViT): A powerful image model that looks at an image as a grid of small patches. It’s great at understanding images but can forget some of the image’s original “spatial layout.”
MuSASplat keeps a large pre‑trained ViT frozen (unchanged) and only trains a few small, smart add‑ons. This saves memory and time.
The two key add‑ons
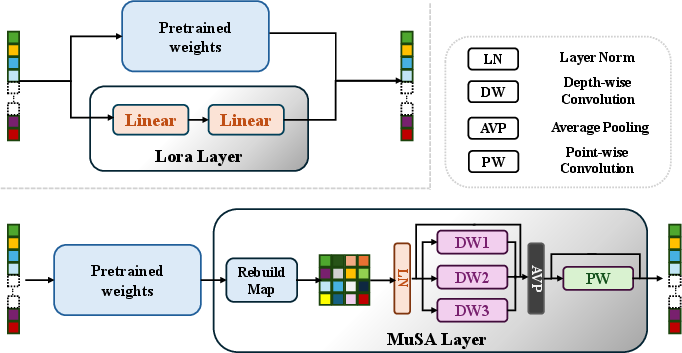
- Multi‑Scale Adapter (MuSA)
- Problem: Standard “small plug‑ins” like LoRA adjust the model using only patch tokens, which don’t fully capture the image’s spatial structure—important for 3D.
- Idea: Rebuild the patch tokens back into a mini image grid and run a few tiny depth‑wise convolutions (think “looking through magnifying glasses of sizes small, medium, and large”). This helps the model understand local shapes and edges across different scales.
- Benefit: You fine‑tune only a small number of new parameters, but you restore spatial awareness—the model becomes better at 3D with little extra cost.
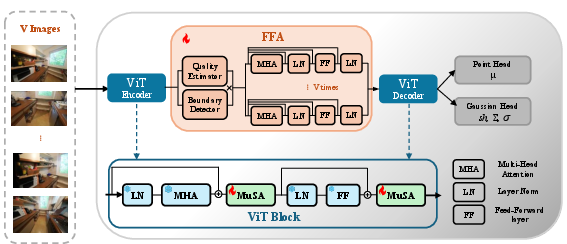
- Feature Fusion Aggregator (FFA)
- Problem: Many methods fuse multiple views using a “memory bank” (like a notebook shared across steps). It’s slow and uses a lot of GPU memory because it updates repeatedly for each image pair.
- Idea: Encode all input photos together in one go and fuse their features once, using light attention and simple scores that tell which parts of which photo are trustworthy (and which views cover useful boundaries).
- Benefit: Much faster training, lower memory use, and more consistent geometry across views.
A small extra trick for very few photos
When there are only two photos and they don’t overlap much, some parts of the scene are missing. MuSASplat first makes a rough 3D point cloud and then renders a few “in‑between” synthetic views (like making extra photos in between). Training with these extra views helps fill holes in the 3D model.
What they found and why it matters
Here’s what the experiments (on the RE10K and ACID datasets) showed:
- High quality with fewer resources:
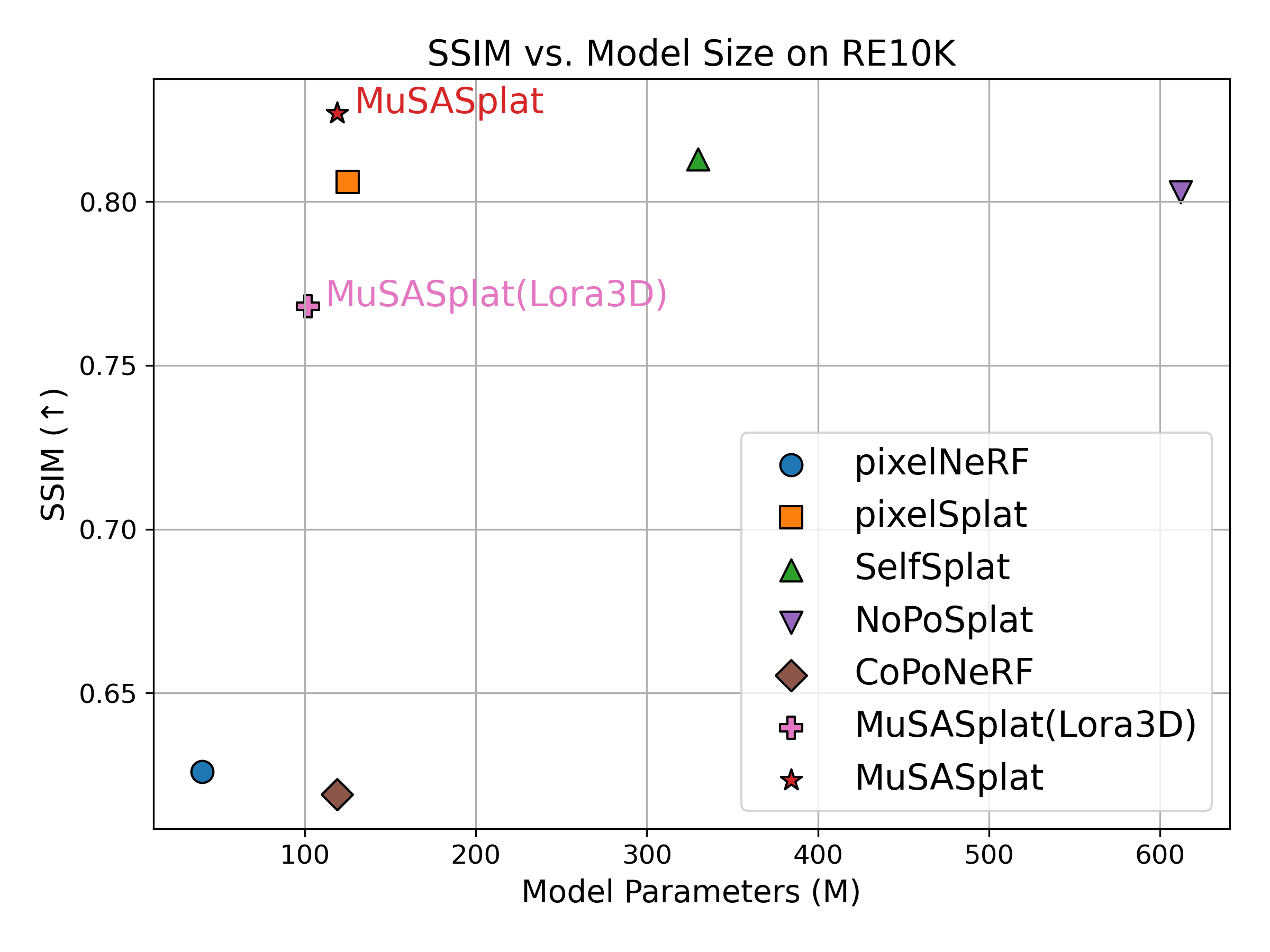
- MuSASplat matches or beats the quality of strong baselines while using far fewer trainable parameters (about 119 million vs. 612 million for a popular baseline).
- It avoids needing camera poses and still produces realistic new views.
- Faster and lighter training:
- The one‑pass Feature Fusion Aggregator speeds training up (reported up to about 4.2× faster than memory‑bank style fusion) and cuts peak memory use a lot.
- Strong results with more views (like 5 photos):
- MuSASplat clearly outperforms methods that rely on memory banks when given five views, producing sharper, more faithful images.
- Ablation (swap‑out) studies show what matters:
- Removing the Multi‑Scale Adapter hurts quality a lot, showing that restoring spatial awareness to the ViT is crucial.
- Replacing MuSA with a popular alternative (LoRA3D) also lowers quality, meaning MuSA’s multi‑scale spatial design works better for 3D.
- Replacing the Aggregator with a memory bank makes training much slower without improving results.
In everyday terms: MuSASplat gets more from less. It uses clever, small pieces to guide a big model, rather than retraining everything.
Why this is useful
- Practical 3D from fewer photos: Helpful for phones, drones, and robots that can’t capture hundreds of precisely posed images.
- Lower hardware demands: Easier to train on commonly available GPUs; makes research and production more accessible.
- Better building blocks: The Multi‑Scale Adapter is a general idea—other 3D systems can plug it in to improve with minimal cost. The single‑pass fusion approach is simpler and scales better with more views.
Limitations and next steps:
- It’s designed for static scenes (things that don’t move). Extending it to dynamic scenes would be exciting.
- It currently targets ViT‑based backbones; adapting it to newer architectures is a natural direction.
In short, MuSASplat shows a smart way to do 3D reconstruction from just a few unposed photos, keeping quality high while slashing the computing cost—making advanced 3D tech more practical and widely usable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, missing evaluations, and open research questions left by the paper. Each item is written to be concrete and actionable for follow-up work.
- Applicability beyond ViT: The method is tailored to ViT-style tokenization; its effectiveness on newer or non-ViT backbones (e.g., VGGT, ConvNeXt, diffusion-based encoders) remains untested.
- Dynamic scenes: The framework targets static scenes; handling dynamic content (moving objects, changing illumination, temporal consistency) is left unexplored.
- High-resolution scalability: Training and evaluation are performed at 256×256; performance, memory, and speed at higher resolutions (e.g., 512×512, 1024×1024) are not reported.
- Inference-time efficiency: The paper reports training speed (iterations per second) but does not provide end-to-end inference latency, throughput, or real-time feasibility on standard hardware.
- Aggregator scalability with number of views: FFA is evaluated only with 2 and 5 views; its computational complexity, memory scaling, and accuracy for larger V (e.g., 10–30 views) are unknown.
- Robustness to view overlap: While point-cloud augmentation is motivated by low overlap, there is no systematic evaluation across controlled overlap regimes (e.g., <10%, 10–30%, >50%).
- Point-cloud augmentation details: Critical hyperparameters (e.g., number of synthetic views K, pose interpolation strategy, selection criteria) and sensitivity analyses are missing; failure modes when the predicted point cloud or relative pose is inaccurate are not studied.
- Pose usage in evaluation: It is unclear whether ground-truth camera poses are used for rendering target views at test time or if the system relies wholly on predicted poses; a clear protocol and ablation are needed.
- Geometry-centric metrics: Evaluations rely on PSNR/SSIM/LPIPS; geometric quality (e.g., Chamfer distance, completeness, normal accuracy, depth error) is not measured, limiting insight into 3D fidelity.
- Occlusion reasoning: FFA uses per-token confidence and a “boundary-view” mask but lacks explicit occlusion modeling or visibility reasoning; ablations isolating these components are absent.
- Hyperparameter sensitivity of MuSA: The impact of reduction ratio r, kernel sizes (3/5/7), zero-init strategy, and adapter placement across transformer layers is not systematically studied.
- Adapter placement strategy: No analysis of how many MuSA layers to insert, in which blocks, or the trade-offs between shallow vs. deep insertion in the backbone.
- Adapter combinations: Potential synergies between MuSA and other parameter-efficient methods (e.g., LoRA, adapters with cross-attention, QR-LoRA) are not explored.
- Memory usage quantification: Claims of 0.3× peak memory reduction and 4.2× speedup lack detailed breakdowns across V, resolution, and batch size; comprehensive profiling and reproducibility are needed.
- Out-of-distribution robustness: Performance under challenging conditions (specular/transparent surfaces, textureless regions, low-light, motion blur, heavy noise) is not evaluated.
- Scale/canonical frame ambiguity: The approach relies on DUSt3R-like pointmaps for joint calibration; robustness to metric-scale ambiguity, drift, or global alignment errors is not analyzed.
- Gaussian count and densification: The strategy N ∝ V is heuristic; mechanisms for adaptive densification, pruning, or quality-aware Gaussian allocation (and comparison to recent densification methods) are not examined.
- FFA design choices: Threshold τ, λ weighting, and the use of log mask inside softmax are not specified/ablated; numerical stability and sensitivity analyses are missing.
- Failure cases: The paper does not present qualitative/quantitative failure modes (e.g., hallucinations, floaters, over-smoothing), nor diagnostics to predict when MuSASplat will underperform.
- Dataset breadth: Evaluation is limited to RE10K and ACID; generalization to other benchmarks (e.g., ScanNet++, Tanks & Temples, Mip-NeRF 360, real-world handheld captures) is untested.
- Variable-length sequences: The aggregator’s behavior and accuracy under variable-length or streaming view inputs (common in real applications) are not demonstrated, unlike memory-bank methods designed for this setting.
- Confidence calibration: The per-token confidence output used in FFA is not calibrated or validated (e.g., reliability diagrams); the effect of miscalibrated confidences on fusion quality is unknown.
- Theoretical justification: There is no formal analysis of why spatial multi-scale depth-wise adapters outperform low-rank token-space updates for 3D tasks; a principled study could guide adapter design.
- Resource-constrained deployment: Memory and speed on low-VRAM GPUs (e.g., 8–12 GB) and mobile/edge settings are not reported; practical deployment constraints are unclear.
Practical Applications
Practical Applications of MuSASplat
Below are actionable, real-world applications that stem from the paper’s findings and innovations—chiefly the lightweight Multi-Scale Adapter (MuSA), the single-pass Feature Fusion Aggregator (FFA), and pose-free, feed-forward sparse-view 3D Gaussian Splatting. Each item notes sector relevance, potential tools or workflows, and assumptions or dependencies that may affect feasibility.
Immediate Applications
These can be prototyped or deployed with current capabilities and typical cloud or workstation GPUs.
- Pose-free 3D asset creation from a few photos for content pipelines (media/entertainment, AR/VR, gaming)
- Tools/products/workflows: “Pose-free 3DGS API” as a cloud service; Blender/Unity/Unreal plugin that takes 2–5 images and outputs splat-based assets; pipeline step replacing COLMAP in sparse-view scenarios.
- Assumptions/dependencies: Static scenes; some view overlap; pretrained ViT backbones (e.g., DUSt3R-like) available; inference on GPU; 256×256 input resolution—higher-res support may need tuning.
- Rapid 3D product models for e-commerce from minimal imagery (e-commerce/retail)
- Tools/products/workflows: Web capture widget → MuSASplat backend → web 3D viewer; “3D-from-few-photos” SKU ingestion service; A/B tests comparing conversion with 3D views.
- Assumptions/dependencies: Controlled lighting/backgrounds improve fidelity; privacy-compliant image handling; cloud GPU for batch processing.
- Lightweight property digitization for listings and virtual tours (real estate, AEC)
- Tools/products/workflows: Mobile scanning app capturing 2–5 unposed photos per room; batch FFA fusion; automated 3D tour generation; “compute-aware” job queue using MuSA to minimize GPU cost.
- Assumptions/dependencies: Mostly static interiors; sufficient overlap; edge devices may need cloud offload; accuracy expectations aligned to marketing, not survey-grade CAD.
- Quick artifact digitization in museums and archives (cultural heritage)
- Tools/products/workflows: Digitization kit with minimal capture; MuSASplat reconstruction; splat-to-mesh conversion for archival formats.
- Assumptions/dependencies: Static objects; minimal occlusion; standardized lighting; downstream tooling to convert Gaussians to meshes when needed.
- Fast site snippets and micro-maps from sparse drone shots (mapping/GIS, surveying-lite)
- Tools/products/workflows: Drone capture → pose-free fusion → 3D splat scene; small-area recon in low-overlap capture regimes; field validation via rendered novel views.
- Assumptions/dependencies: Not a replacement for survey-grade pipelines; requires overlap and static environments; may need domain-specific fine-tuning.
- Parameter-efficient adaptation of existing ViT-based geometric pipelines (software/ML Ops)
- Tools/products/workflows: “MuSA Adapter SDK” to retrofit NoPoSplat/SelfSplat-like models; fine-tune for new domains with ~5× fewer trainable params; training orchestration that targets single-GPU budgets.
- Assumptions/dependencies: ViT backbones; zero-init adapter integration; datasets for domain adaptation.
- Replacing memory banks in multi-view fusion to cut cost without quality loss (software/ML Ops, 3D vision teams)
- Tools/products/workflows: Drop-in FFA module to reduce memory footprint and speed up training/inference; benchmarking internal pipelines for throughput gains.
- Assumptions/dependencies: Batch processing of views supported; static scenes; integration effort with existing encoders/decoders.
- Education and research labs: teaching pose-free 3D reconstruction on modest hardware (academia, education)
- Tools/products/workflows: Course labs using MuSASplat on single RTX-class GPUs; reproducible notebooks; student projects comparing adapter mechanisms (MuSA vs. LoRA3D).
- Assumptions/dependencies: Access to RE10K/ACID-like datasets; GPU availability; open-source or internal codebase.
- Claims documentation and remote inspections with quick 3D from few images (finance/insurance, field services)
- Tools/products/workflows: Adjuster capture app; muSASplat reconstruction; annotated 3D scenes for reporting.
- Assumptions/dependencies: Static targets; privacy/security controls; expectations calibrated to qualitative inspection, not engineering accuracy.
- Social/mobile 3D posts (consumer apps)
- Tools/products/workflows: Mobile capture of 2–5 photos → cloud inference → embeddable 3D splat viewer; creator tools for AR stickers/backgrounds.
- Assumptions/dependencies: Latency tolerances; network connectivity; device-offloading or efficient on-device inference if optimized.
Long-Term Applications
These need further research, optimization, validation, or scaling (e.g., dynamics, on-device real-time, larger scenes).
- Real-time dynamic scene reconstruction from sparse video (media/AR/VR, robotics)
- Tools/products/workflows: Live AR experiences with moving objects; streaming adapter/aggregator that handles temporal consistency; splat densification on-the-fly.
- Assumptions/dependencies: Extending from static to dynamic scenes; fast temporal fusion; motion handling; robust to occlusions.
- On-device multi-camera fusion for robots and wearables (robotics, XR)
- Tools/products/workflows: Edge runtime with FFA on Jetson/Apple Neural Engine-class hardware; multi-camera SLAM-lite reconstruction without explicit pose.
- Assumptions/dependencies: Optimized kernels; memory-aware batching; hardware acceleration; safety and reliability standards.
- City/block-scale mapping and digital twins from opportunistic captures (AEC, smart cities, energy)
- Tools/products/workflows: Pipeline that aggregates many sparse views from various sources; hierarchical fusion; splat-to-CAD conversion for downstream BIM.
- Assumptions/dependencies: Scalability of FFA to hundreds/thousands of views; data governance; storage/compute budgets; mesh conversion fidelity.
- Multi-sensor fusion for autonomous driving and mobile platforms (autonomy, transportation)
- Tools/products/workflows: FFA-like mechanisms extended to combine cameras with depth/radar/LiDAR; pose-light reconstruction aiding perception modules.
- Assumptions/dependencies: Real-time constraints; safety-critical validation; automotive-grade datasets; integration with existing stacks.
- Healthcare imaging from sparse RGB or endoscopic views (healthcare)
- Tools/products/workflows: Assistive reconstruction in surgery rooms for spatial awareness; pre-op planning from limited intra-op imagery.
- Assumptions/dependencies: Significant domain adaptation; clinical validation; privacy and compliance; accuracy thresholds; robustness to specularities and tissue motion.
- Policy and sustainability: compute-efficient 3D AI standards (policy, sustainability offices in tech)
- Tools/products/workflows: Procurement guidelines encouraging parameter-efficient adapters; reporting on energy savings versus full-model fine-tuning; best-practice documents for low-footprint 3D AI.
- Assumptions/dependencies: Standardized metrics for energy/compute; industry participation; lifecycle assessments.
- 360-degree and immersive space synthesis at scale (media/entertainment, education)
- Tools/products/workflows: Integration with 360 capture pipelines; optimized FFA for panoramic inputs; immersive education content.
- Assumptions/dependencies: Training with 360 datasets; handling extreme FOV distortions; UX integration.
- Integration with emerging backbones (e.g., VGGT) and non-ViT architectures (software/ML research)
- Tools/products/workflows: Generalized adapter design for spatial awareness in new backbones; cross-architecture benchmarking.
- Assumptions/dependencies: Redesign of MuSA-like adapters; compatibility layers; retraining.
- Disaster response and humanitarian assessment from sparse imagery (public sector, NGOs)
- Tools/products/workflows: Rapid 3D situational awareness from a handful of field images; remote triage tools; overlays with damage annotations.
- Assumptions/dependencies: Reliability under adverse conditions; diverse scene generalization; ethical and privacy considerations.
- Industrial asset inspection and facility twins (energy, manufacturing)
- Tools/products/workflows: Sparse maintenance captures → 3D recon → anomaly tagging; periodic updates to digital twins.
- Assumptions/dependencies: Safety protocols; domain-specific fine-tuning; mesh or metric outputs where needed.
- Standards for splat-to-mesh conversion and interoperable formats (industry consortia, standards bodies)
- Tools/products/workflows: Guidelines and libraries to convert Gaussian splats to mesh/CAD; interoperability with existing 3D formats.
- Assumptions/dependencies: Community consensus; robust conversion algorithms; fidelity and metric accuracy requirements.
Notes across applications:
- The method is tuned for static scenes and relies on pretrained ViT backbones; dynamic and high-resolution scenarios require further work.
- FFA enables single-pass fusion but assumes batch processing of all views; streaming or incremental fusion will need design changes.
- Accuracy expectations should match use case: MuSASplat targets generalizable, perceptual-quality reconstructions rather than survey-grade metrology.
- Compute reduction is a central benefit; on-device viability depends on additional engineering (kernel optimization, quantization, model distillation).
Glossary
- 3D Gaussian Splatting (3DGS): A rendering technique that models a scene using a set of anisotropic 3D Gaussians and rasterizes them for novel view synthesis. "3D Gaussian Splatting (3DGS)\,\cite{kerbl20233d} accelerates rendering by analytically rasterising anisotropic Gaussians, yet it inherits the same dense-capture requirement."
- AdamW: An optimizer that decouples weight decay from gradient updates, improving training stability in deep networks. "Our model is implemented in PyTorch and trained using AdamW with learning rate , weight decay $0.05$, and gradient clipping of $0.5$."
- anisotropic Gaussians: Gaussian distributions with direction-dependent covariance, used to represent localized radiance with orientation. "3D Gaussian Splatting (3DGS)\,\cite{kerbl20233d} accelerates rendering by analytically rasterising anisotropic Gaussians"
- batch-wise encoding: Processing all inputs in a batch simultaneously rather than sequentially, increasing throughput and consistency. "In contrast, our aggregator performs batch-wise encoding and decoding of all input views simultaneously."
- boundary detector: A module (typically an MLP) that flags views likely to contribute important boundary geometry for fusion. "In parallel, a second MLP (boundary detector) detects boundary-view indicators from global pooled features"
- camera calibration: Estimating camera intrinsics and extrinsics to align views in a common 3D frame. "DUSt3R~\cite{wang2024dust3r} is a ViT-based approach that jointly solves camera calibration and 3D reconstruction using only images."
- canonical space: A unified coordinate frame to which per-view estimates are projected for consistent supervision and fusion. "our method estimates per-view point maps and projects them to a canonical space, enabling consistent 3D Gaussian supervision directly from uncalibrated RGB images."
- COLMAP: A widely used structure-from-motion software for estimating camera poses and sparse 3D reconstructions. "usually estimated by structure-from-motion algorithms such as COLMAP \cite{schonberger2016structure}"
- cost volumes: 3D tensors that encode correspondence costs across depth/hypotheses, used in multi-view geometry. "a growing body of feed-forward methods~\cite{yu2021pixelnerf,wang2021ibrnet,chen2021mvsnerf,johari2022geonerf,xu2023wavenerf,charatan2024pixelsplat,chen2024mvsplat} build cost volumes or exploit epipolar geometry"
- depth-wise convolutions: Convolutions applied per channel independently, enabling efficient spatial processing with fewer parameters. "apply a set of multi-scale depth-wise convolutions"
- differentiable Gaussian splatting: A rendering operation of Gaussian primitives that supports gradient-based optimization. "where denotes differentiable Gaussian splatting."
- DUSt3R: A ViT-based model that predicts dense pointmaps to jointly solve camera calibration and 3D reconstruction from unposed image pairs. "DUSt3R~\cite{wang2024dust3r} is a ViT-based approach that jointly solves camera calibration and 3D reconstruction using only images."
- epipolar geometry: The geometric relationship between two views that constrains corresponding points along epipolar lines. "build cost volumes or exploit epipolar geometry"
- Feature Fusion Aggregator (FFA): A single-pass module that fuses multi-view features without iterative memory updates, improving efficiency. "In addition, we introduce a Feature Fusion Aggregator that integrates features across input views effectively and efficiently."
- Gaussian head: A network head that predicts parameters of 3D Gaussian primitives from encoded features. "NoPoSplat \cite{ye2024no} combines DUSt3R~\cite{wang2024dust3r} with a 3D Gaussian head and achieves competitive performance through full-model fine-tuning."
- GELU: A smooth, non-linear activation function commonly used in Transformer architectures. "The result is passed through a point-wise convolution and a GELU activation, then projected back to the original dimension:"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank updates into frozen layers. "Low-Rank Adaptation (LoRA)~\cite{hu2022lora} is a widely adopted strategy for parameter-efficient fine-tuning."
- LoRA3D: A 3D adaptation of LoRA for neural rendering/geometry models to reduce fine-tuning parameters. "We also report MuSASplat (LoRA3D), a variant where our adapter is replaced with LoRA3D~\cite{lu2024lora3d}"
- LPIPS: A learned perceptual similarity metric used to evaluate the visual fidelity of reconstructions. "The RGB loss $\mathcal{L}_{\text{rgb}$ follows NoPoSplat and consists of a weighted sum of mean squared error (MSE) and perceptual LPIPS loss"
- memory banks: External feature stores updated across views/pairs to accumulate multi-view information. "Unlike widely adopted memory banks, the Feature Fusion Aggregator ensures consistent geometric integration across input views and meanwhile mitigates the memory usage, training complexity, and computational costs significantly."
- Multi-Scale Adapter (MuSA): A lightweight ViT adapter that restores spatial reasoning via multi-scale depth-wise convolutions. "First, it introduces a Multi-Scale Adapter that enables efficient fine-tuning of ViT-based backbones."
- NeRF: Neural Radiance Fields; a continuous volumetric representation for neural rendering of novel views. "NeRF\,\cite{mildenhall2021nerf} inaugurated neural rendering by modelling scenes as continuous radiance fields"
- novel-view synthesis: Rendering previously unseen views of a 3D scene from limited observations. "Though 3D reconstruction with neural radiance field (NeRF) \cite{mildenhall2021nerf} and 3D Gaussian Splatting (3DGS) \cite{kerbl20233d} has achieved impressive novel-view synthesis"
- parameter-efficient fine-tuning: Techniques that adapt large models by training only a small subset or lightweight modules. "Low-Rank Adaptation (LoRA)~\cite{hu2022lora} is a widely adopted strategy for parameter-efficient fine-tuning."
- patchified token sequence: The sequence of image patches converted to tokens for ViT processing. "Specifically, we rebuild the patchified token sequence back into a spatial feature map, preserving the image’s spatial layout"
- per-scene optimization: Training a model separately for each scene, often costly and time-consuming. "The recent feed-forward networks~\cite{charatan2024pixelsplat, chen2024mvsplat, chen2024mvsplat360} obviate per-scene optimization"
- point head: A network component that predicts 3D points (e.g., a sparse point cloud) from features. "from the same frozen ViT backbone followed by a point head"
- pointmap: A dense mapping from image pixels to 3D points in a specified camera coordinate frame. "it predicts dense 3D point clouds, referred to as pointmaps, which establish a per-pixel 2D-to-3D mapping."
- PSNR: Peak Signal-to-Noise Ratio; a reconstruction quality metric measuring pixel-level fidelity. "We report PSNR, SSIM, and LPIPS~\cite{zhang2018unreasonable} on both the RE10K and ACID datasets"
- quality estimator: An MLP that predicts token-wise confidence scores to guide cross-view fusion. "a lightweight MLP (quality estimator) estimates a confidence score for each token:"
- rasterising: Rendering by discretely projecting continuous primitives (e.g., Gaussians) onto the image plane. "3D Gaussian Splatting (3DGS)\,\cite{kerbl20233d} accelerates rendering by analytically rasterising anisotropic Gaussians"
- residual connection: A skip pathway that adds transformed features back to the original stream to stabilize learning. "Finally, we fuse the attended features with the original using an MLP residual connection:"
- softmax: A normalization function that converts scores to probabilities for attention weighting. "$\mathbf{A}^{v}= \mathrm{softmax}\!\left( \frac{\mathbf{Q}^{v}(\mathbf{K}^{v})^\top}{\sqrt{d} + \log \mathbf{M}^{v} \right)$"
- spherical harmonics (SH): A basis for representing view-dependent color/radiance in Gaussians. "and SH representing color."
- SSIM: Structural Similarity; a perceptual metric assessing image structure preservation. "We report PSNR, SSIM, and LPIPS~\cite{zhang2018unreasonable} on both the RE10K and ACID datasets"
- structure-from-motion: A class of algorithms that recover 3D structure and camera motion from images. "usually estimated by structure-from-motion algorithms such as COLMAP"
- Swin Transformer: A hierarchical Transformer with shifted windows that preserves spatial locality. "While SelfSplat employs a Swin Transformer backbone that preserves spatial structures"
- Vision Transformer (ViT): A Transformer architecture that operates on image patches as tokens. "most of them rely on full fine-tuning of large Vision Transformer (ViT) backbones"
Collections
Sign up for free to add this paper to one or more collections.

