Tessellation GS: Neural Mesh Gaussians for Robust Monocular Reconstruction of Dynamic Objects
Abstract: 3D Gaussian Splatting (GS) enables highly photorealistic scene reconstruction from posed image sequences but struggles with viewpoint extrapolation due to its anisotropic nature, leading to overfitting and poor generalization, particularly in sparse-view and dynamic scene reconstruction. We propose Tessellation GS, a structured 2D GS approach anchored on mesh faces, to reconstruct dynamic scenes from a single continuously moving or static camera. Our method constrains 2D Gaussians to localized regions and infers their attributes via hierarchical neural features on mesh faces. Gaussian subdivision is guided by an adaptive face subdivision strategy driven by a detail-aware loss function. Additionally, we leverage priors from a reconstruction foundation model to initialize Gaussian deformations, enabling robust reconstruction of general dynamic objects from a single static camera, previously extremely challenging for optimization-based methods. Our method outperforms previous SOTA method, reducing LPIPS by 29.1% and Chamfer distance by 49.2% on appearance and mesh reconstruction tasks.


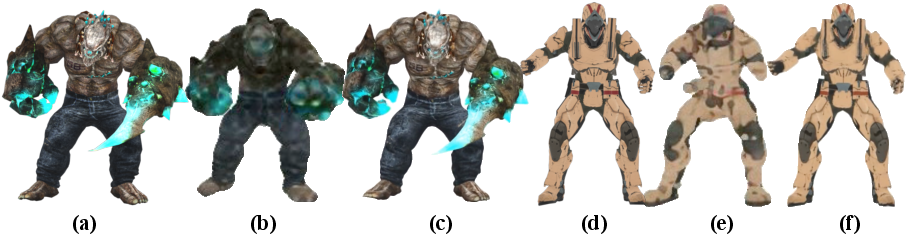
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to rebuild 3D models of moving, changing objects using just a single camera video. The goal is to make the result look realistic from any new camera angle, not just the angles seen during filming. The authors introduce a new method called Tessellation GS that attaches “soft dots” of color and detail to the surfaces of a 3D mesh, and carefully controls how these dots are placed and refined to avoid common mistakes.
What questions did the paper ask?
In simple terms, the researchers asked:
- How can we reconstruct detailed 3D shapes and appearances of moving objects from only one camera, even if the camera hardly moves or stays still?
- How can we stop the model from “overfitting” to the original camera view, so it still looks good from new viewpoints?
- Can we make this work for many types of objects, not just humans or known categories?
How did they do it?
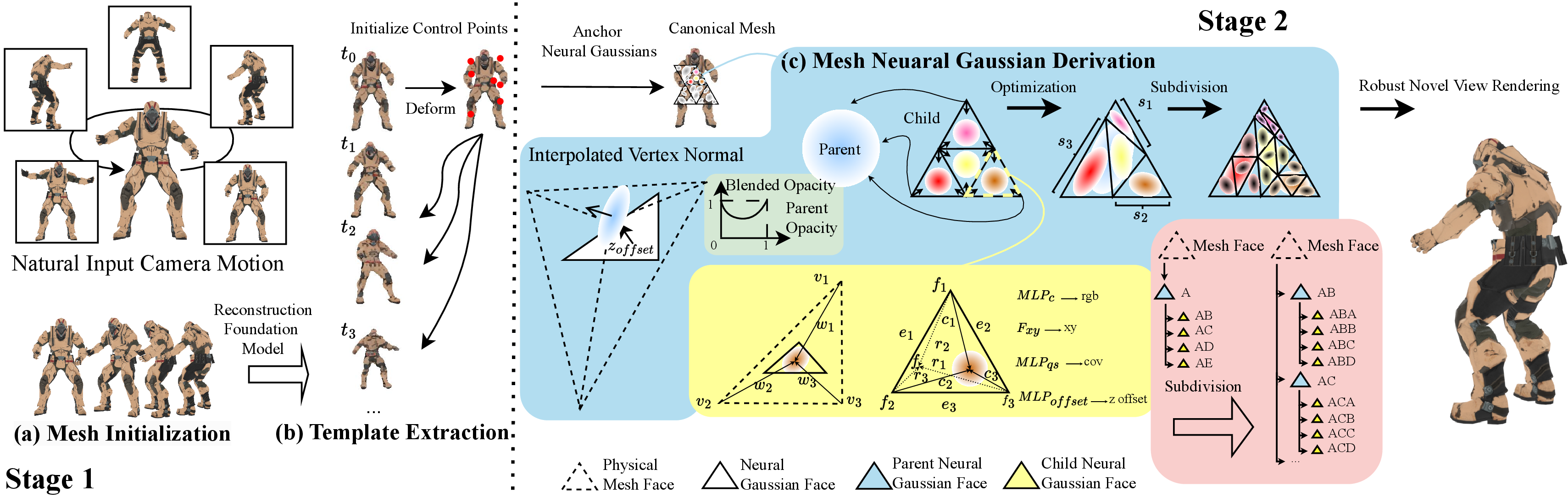
Think of a 3D object like a statue covered in tiny triangular tiles (a mesh). The paper uses two main stages:
Stage 1: Build a reliable starting shape and motion
- They use a “reconstruction foundation model” (LRM), which is a big AI model trained to guess 3D shapes from images, to get a rough 3D mesh for each frame of the video.
- They pick one mesh as the “canonical” or reference shape.
- Then they add “control points” (like puppet joints) and a small neural network (an MLP) that learns how these points move over time. This motion lets the reference mesh deform to match each frame’s shape.
- They use smart losses (rules for learning), including a robust version of Chamfer distance (a way to measure how close two shapes are), to handle noisy or flickering outputs from the foundation model.
Stage 2: Add fine details without overfitting, using Tessellation GS
- They place 2D Gaussian “splats” (soft, blurry dots of color) on the mesh’s triangle faces. Anchoring to the mesh keeps the dots on the surface, preventing floating blobs or stretched artifacts.
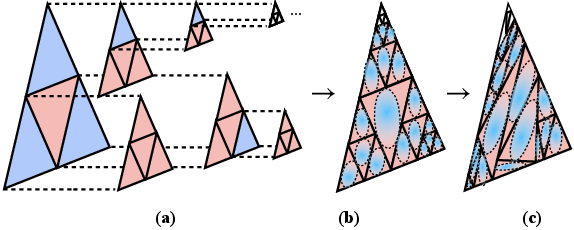
- Each triangle can be split into smaller triangles in a structured way (a “quad-tree” on the triangle). This is like cutting a pizza slice into four smaller slices when you need more detail.
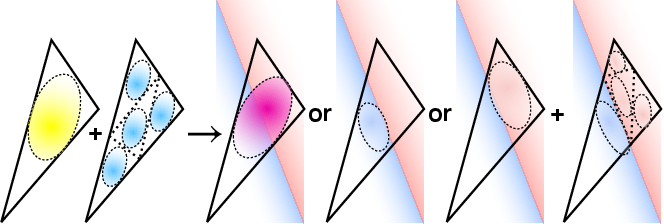
- The splats have “opacity” rules where parent and child splats compete: if fine detail is needed, parent opacity lowers and child splats take over; if not, parents stay opaque and children turn off. This adaptively adds detail only where needed.
- They limit the size and direction of splats so they don’t stretch along camera rays (a common overfitting issue), and allow small offsets from the surface only when triangles are small (so fine details can be carved carefully).
- They train appearance with simple image losses (like L1 and SSIM), and sometimes add extra cues like optical flow (how pixels move over time) and surface normals from other models to make the learning more stable, especially for static cameras.
Key terms explained simply
- Monocular reconstruction: building a 3D model from one camera.
- Mesh: a net made of tiny triangles that form a 3D surface.
- 2D Gaussians: soft dots of color attached to the surface; these blend smoothly and can represent detailed textures efficiently.
- Overfitting to view: the model looks great from the training camera’s angles but breaks when viewed from new angles.
- Chamfer distance: a score that tells how close two shapes’ surfaces are; lower is better.
- LPIPS: a measure of how realistic images look to a perceptual model; lower is better.
What did they find?
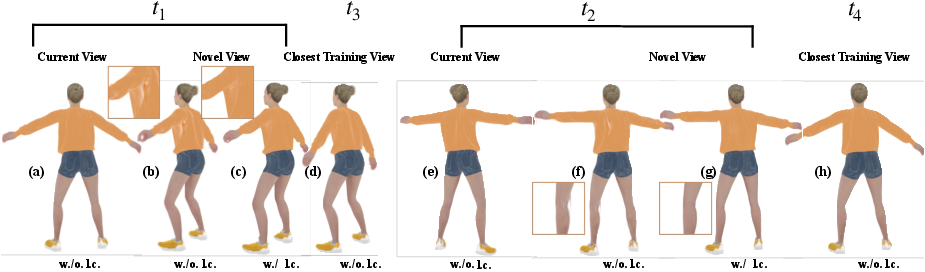
- Their method reconstructs moving objects from single-camera videos with more realistic appearance and more accurate geometry than previous methods, especially when the camera view is limited.
- On benchmark tasks, they reduced LPIPS by 29.1% (better visual quality) and Chamfer distance by 49.2% (better geometry) compared to the best prior work.
- The meshes they produce are sharper and less noisy because the splats are tied closely to the mesh surface and constrained properly.
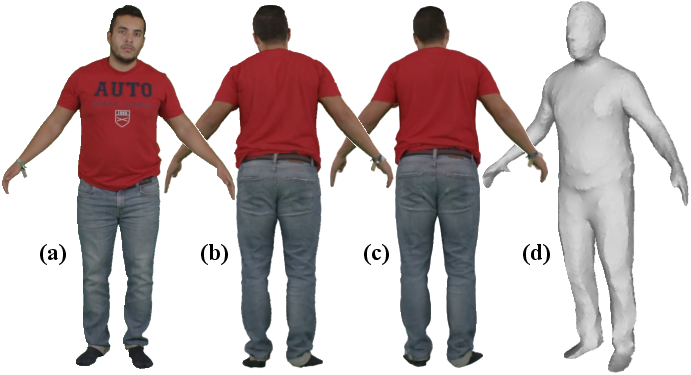
- It works not only on synthetic datasets but also on real-world videos (like a deforming cactus toy) and with static cameras (like people turning in place), and it trains in about 90 minutes for 500 frames on a single GPU.
Why does this matter?
- It pushes 3D reconstruction closer to everyday use: you can capture a moving object with a phone and get a detailed, stable 3D model.
- It avoids relying on special templates (like human body models), so it can handle a wide variety of objects.
- By preventing overfitting to the training view, the models look good from new angles, which is crucial for animation, AR/VR, games, and visual effects.
A simple takeaway
Imagine painting a moving statue with soft dots that stick to its surface. If you place and control those dots smartly—only adding more where detail is needed, and keeping them from stretching or floating—you get a clean, realistic 3D result that still looks great when you walk around it. That’s the core idea of Tessellation GS.
Limitation to keep in mind
The method relies on having a decent starting mesh from the foundation model. If the object’s shape changes drastically (like splitting into parts), handling those “topology changes” is still hard and left for future work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Sensitivity to LRM priors: The method heavily depends on per-frame meshes from a large reconstruction model (LRM), but there is no quantitative analysis of how reconstruction quality varies with LRM errors (flicker, low resolution, bias across object categories, reflective/transparent surfaces). Establishing robustness bounds and fallback strategies when LRM fails is left unexplored.
- Canonical mesh selection: The canonical mesh is chosen as the first frame by default; no criteria or automated strategy is provided to select a stable canonical reference under significant motion or pose variation. The impact of canonical choice on downstream deformation and appearance quality is not evaluated.
- Topology changes: Handling merges/splits, holes, and self-contact is explicitly listed as a limitation. There is no mechanism for dynamic topology (mesh merge/division) with consistent face correspondence, nor an evaluation on scenarios with changing topology.
- Motion model capacity and selection: The number of control points (30) and the hierarchical temperature schedule are fixed and heuristic. There is no guidance on how to size or place control points for different objects or deformation complexity, nor analysis of failure modes for highly articulated or fine-scale nonrigid motion.
- Occlusion and self-intersection: While the approach constrains Gaussian placement to reduce view-overfitting, it does not address scene-level occlusions, self-intersections, or complex layering (e.g., thin structures folding) in a principled way. Evaluation on sequences with severe self-occlusion is missing.
- View-dependent appearance and lighting changes: The appearance decoders do not explicitly model view-dependent reflectance (specularities, BRDF effects) or time-varying illumination. The impact on scenes with strong non-Lambertian properties or lighting changes is not measured.
- Backgrounds and multi-object scenes: The method targets a single dynamic foreground object; there is no strategy for handling complex backgrounds, multiple interacting objects, or segmentation errors when LRM outputs include background geometry.
- Reliability of external priors (RAFT flow, DSINE normals): The method leverages RAFT for optical flow and DSINE for normals (only in static-camera setups), but does not analyze sensitivity to their failure cases (large displacement, motion blur, occlusion, textureless regions). Ablations removing or replacing these priors are absent.
- Gaussian opacity coupling and subdivision heuristics: The competitive opacity rule uses a fixed β=0.9 and subdivision/pruning thresholds (opacity < 0.1, > 0.9, 90% iteration condition) with fixed schedules (every 2000–5000 iterations). There is no study of sensitivity, convergence guarantees, or principled criteria for adaptive thresholds.
- Offset constraint design: The scale-dependent Gaussian offset constraint is heuristic (bounded by mean edge length, tanh modulation, barycentric factor). Its bias on fine geometry (thin structures), potential degeneracy, and alternatives (e.g., learned offset priors, curvature-aware constraints) are not explored.
- Subdivision stability and degeneracy: The learnable subdivision ratios s1, s2, s3 can, in principle, create near-degenerate triangles. Safeguards, conditioning, or guarantees against degenerate faces are not described, and numerical stability under frequent subdivision is not evaluated.
- Mesh resolution control: The pipeline uses Taubin smoothing and face subdivide/collapse to reach a “desired initial number of Gaussians,” but criteria for selecting mesh resolution, its effect on performance, and automatic adaptation mechanisms are not provided.
- Theoretical understanding of overfitting suppression: The constraints and hierarchical 2D GS are empirically effective, but there is no theoretical analysis (e.g., bounds on anisotropy, coverage, or regularization strength) explaining why and when view-overfitting is alleviated.
- Generalization across datasets and categories: Evaluation is limited to Smooth D-NeRF (re-rendered with natural camera motion), People-Snapshot, and one Unbiased4D video. Broader, diverse, in-the-wild tests (textures, materials, occlusions, lighting, camera shake) with systematic metrics are missing.
- Baseline coverage: Comparisons focus on TiNeuVox, HexPlane, and DG-Mesh. Newer dynamic Gaussian or mesh-based methods (and multi-view variants with monocular ablations) are omitted, limiting the assessment of relative progress.
- Geometry ground truth and metrics: Chamfer distance is reported “unitless” at 1e−3 scale and appears tied to LRM data. There is no evaluation against ground-truth meshes for most scenes, nor error decomposition (topology, fine detail, smoothness) to clarify what geometry improvements the method achieves.
- Pose estimation and camera calibration errors: The pipeline assumes accurate posed images. The robustness to pose/camera intrinsics errors (e.g., rolling shutter, lens distortion, jitter) is not tested.
- Static-camera cases without normals: Normal supervision (DSINE) is used only for static cameras; the minimal cues required for static cameras without additional priors (e.g., shading, multi-light cues) and the method’s failure envelope are unknown.
- Runtime scalability and memory at high resolution/long sequences: While training time/memory are reported for 500 frames on a 3090, the scalability to higher-resolution video, longer sequences, or real-time/interactive applications is not addressed.
- Reproducibility details: Critical hyperparameters remain under-specified or heuristic (e.g., robust Chamfer threshold d, MLP architectures and layer widths, feature dimensions beyond 128, learning-rate schedules per module). A systematic ablation on these choices and open-source release would improve reproducibility.
- Foreground extraction/segmentation: The approach presumes clean object meshes from LRM; handling imperfect segmentation (leakage of background, missing parts) and its impact on Tessellation GS has not been explored.
- Failure analysis and diagnostics: Beyond qualitative ablations, there is no structured failure analysis (when/why artifacts arise, diagnostics to detect them early, automated corrective procedures).
- Alternative priors and self-supervision: It remains open whether other priors (depth-from-video, shading cues, physics constraints, silhouettes) or self-supervised strategies could replace or complement LRM and external models to reduce dependency on pretrained components.
- Downstream tasks: The paper focuses on reconstruction quality; it does not explore applications such as motion retargeting, editing, or physical plausibility checks, nor how Tessellation GS can support these tasks (e.g., consistent UVs, semantic parts, controllable deformations).
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can be built now using the paper’s method and insights, along with sector links, plausible tools or products, and key assumptions/dependencies.
- Single-camera volumetric capture for media production (Media/Entertainment, Gaming, AR/VR)
- What: Reconstruct dynamic props, performers, and moving objects from a single handheld or static camera to produce meshes and photorealistic novel views, without multi-camera rigs.
- Tools/Products: Blender/Unreal plug-ins; a “Tessellation GS Capture” desktop app; GLTF/USD export of dynamic meshes; pipeline scripts that chain LRM → Stage-1 deformation → Stage-2 TGS.
- Workflow: Record 20–60s clip → run LRM per-frame meshes → 2-stage Tessellation GS (≈90 minutes for ~500 frames on a single 3090 GPU) → export textured mesh + view synthesis.
- Assumptions/Dependencies: Requires a reliable reconstruction foundation model (LRM) per frame, camera pose estimation, sufficient texture, moderate motion; limited robustness to topological changes; GPU access.
- Cloud mobile app for user-generated dynamic 3D assets (Consumer Software, Social Media, AR/VR)
- What: Smartphone capture of pets, toys, or people; cloud-side Tessellation GS converts single videos into shareable volumetric posts and AR assets.
- Tools/Products: Mobile capture SDK; cloud GPU service; content moderation; automatic background handling; social export (USDZ/GLB).
- Assumptions/Dependencies: Stable or slowly moving camera; privacy handling; camera intrinsic/extrinsic estimation; LRM inference at scale; bandwidth for uploads.
- Offline free-viewpoint replays from single-camera sports footage (Sports Analytics/Media)
- What: Generate novel views of athletes from broadcast or training footage with a single camera; analyze motion and appearance in 3D.
- Tools/Products: “Free-View Lab” desktop/cloud tool; analysis plug-ins; mesh and flow overlays.
- Assumptions/Dependencies: Known/estimated camera poses; controlled motion and occlusions; acceptable offline latency (not real-time); regulatory approval for athlete data.
- Digital performance capture for cultural heritage and arts (Arts/Heritage, Education)
- What: Digitize dance, theater, and performance pieces from archival single-camera videos to produce volumetric archival assets.
- Tools/Products: Capture-assist tool for museum digitization; mesh post-processing and retargeting tool.
- Assumptions/Dependencies: Sufficient video quality; scene lighting variability; potential manual curation when LRM outputs flicker; archival ethics.
- Robotics/simulation asset generation from monocular real-world footage (Robotics, Software/Simulation)
- What: Convert dashcam or lab videos into dynamic 3D assets for training and simulation (e.g., moving pedestrians, deforming objects).
- Tools/Products: “Monocular-to-4D” asset pipeline; ROS/Gazebo integration; scenario libraries.
- Assumptions/Dependencies: Offline processing; domain gaps (lighting, motion blur); segmentation of target objects; camera calibration or SLAM-derived poses.
- Product marketing and e-commerce dynamic showcases (Marketing/E-commerce, Advertising)
- What: Create dynamic 3D product spins and motion-rich demos (e.g., flexible materials) from a single rotating camera.
- Tools/Products: Studio workflow extensions; automated processing presets; WebGL viewers for novel-view playback.
- Assumptions/Dependencies: Controlled studio setup; specular/transparent materials may need special handling; privacy and IP policies.
- Academic benchmarking and reproducible research kits (Academia)
- What: Use Tessellation GS as a baseline for monocular dynamic reconstruction studies; compare methods with reduced view-overfitting.
- Tools/Products: Open-source code release; Docker environments; evaluation scripts for LPIPS/Chamfer distance and novel-view robustness.
- Assumptions/Dependencies: Availability of LRM, RAFT (optical flow), DSINE (normals) priors; standardized datasets with realistic camera motion.
- Forensic and insurance analysis from single CCTV clips (Public Safety, Insurance)
- What: Reconstruct dynamic object motion and scene geometry to aid incident review from a single vantage point.
- Tools/Products: Incident-reconstruction offline toolkit; report generation with meshes and replays.
- Assumptions/Dependencies: Video quality and compression; camera metadata; human factors and evidentiary standards; non-real-time.
- Research-grade gait and motion studies without motion-capture suits (Healthcare Research)
- What: Extract 3D motion and geometry from single static or slow-moving cameras for laboratory gait studies or rehab assessments.
- Tools/Products: Lab pipeline; mesh tracking overlays; data export for biomechanics software.
- Assumptions/Dependencies: Research-only (not clinical); careful validation; privacy compliance; controlled environments.
- Education content creation and lab exercises (Education)
- What: Teach differentiable rendering and dynamic reconstruction with a tangible pipeline; produce class projects and demonstrations from student videos.
- Tools/Products: Curricula modules; simplified GUI; preconfigured datasets and code notebooks.
- Assumptions/Dependencies: Access to GPU resources; supervision for correct camera pose estimation; safe-to-share datasets.
Long-Term Applications
These use cases require further research and engineering, including scaling, speedups, robustness to topological changes, or regulatory/operational readiness.
- Real-time telepresence avatars from a single webcam (Communications, AR/VR)
- What: Live 3D avatars with photorealistic novel views from monocular input for video calls or streaming.
- Needed advances: Incremental/online optimization; faster/leaner deformation and appearance updates; low-latency inference; robust pose estimation under jitter; privacy/consent tooling.
- Assumptions/Dependencies: Significant model acceleration; reliable background handling; sustained compute on device or edge.
- Single-camera free-viewpoint sports broadcast (Sports Media)
- What: Near-real-time reconstructions allowing viewer-controlled perspectives during live events with a single broadcast camera.
- Needed advances: Multi-stage acceleration; occlusion and crowd handling; automatic camera pose tracking; edge/cloud orchestration.
- Assumptions/Dependencies: Broadcast integration; legal rights and data protection; hardware-accelerated pipelines.
- On-device monocular 4D reconstruction for mobile AR (Mobile, AR/VR)
- What: Capture and render dynamic objects on smartphones without cloud dependence.
- Needed advances: Model compression; efficient LRM substitutes; hardware-friendly splatting; energy-aware scheduling.
- Assumptions/Dependencies: Future mobile GPUs/NPUs; battery and thermal constraints; OS-level permissions.
- City-scale monocular 4D mapping for traffic analytics (Smart Cities, Mobility)
- What: Reconstruct dynamic traffic participants from fixed CCTV to support safety analytics and planning.
- Needed advances: Multi-scene scaling; multi-object segmentation and tracking; handling severe occlusion/topological changes; privacy-preserving pipelines.
- Assumptions/Dependencies: Governance frameworks; public buy-in; secure data infrastructure.
- Clinical-grade motion capture without markers (Healthcare)
- What: Certified gait/rehab assessments using single-camera dynamic reconstructions for hospitals/clinics.
- Needed advances: Accuracy/robustness validation vs. gold standards; regulatory approvals; standardized protocols; interpretability tooling.
- Assumptions/Dependencies: Controlled illumination; patient privacy; risk management.
- Insurance and legal-grade reconstruction from consumer videos (Insurance, Legal/Forensics)
- What: Standardized workflows to reconstruct incidents from dashcams/home cameras for claims or court evidence.
- Needed advances: Evidentiary robustness; chain-of-custody tooling; bias mitigation; expert review processes.
- Assumptions/Dependencies: Industry standards; forensic validation; model explainability.
- Topological change-aware dynamic reconstruction (Core Research, Software)
- What: Robustly handle object splits, merges, and topology changes during motion while preserving mesh-Gaussian correspondence.
- Needed advances: Mesh merge/division algorithms with consistent faces; adaptive priors; stronger geometric regularizers; learning correspondence under topology variation.
- Assumptions/Dependencies: New representations or hybrid methods; extended dataset coverage.
- Foundation workflows for category-agnostic dynamic capture (Software Platforms)
- What: Turn Tessellation GS into a general SDK with modular priors and auto-tuning across domains.
- Needed advances: Unified interfaces for LRM, optical flow, normal priors; automated camera pose estimation; error diagnostics; scalable cloud orchestration.
- Assumptions/Dependencies: Vendor-neutral APIs; sustained maintenance; community benchmarks.
- Privacy, consent, and IP governance for 3D recon from single videos (Policy)
- What: Policy frameworks to manage consent, identity protection, and ownership of reconstructed 3D assets.
- Needed advances: Technical safeguards (watermarking, anonymization); legal instruments; best-practice guidelines for capture and sharing.
- Assumptions/Dependencies: Multi-stakeholder agreement; enforcement mechanisms; compliance tooling.
- Real-time robotics perception using monocular dynamic 3D (Robotics)
- What: On-robot reconstruction of dynamic obstacles for navigation and manipulation with a single camera.
- Needed advances: Embedded acceleration; robust segmentation; resilience to motion blur and lighting; online updates without drift.
- Assumptions/Dependencies: Specialized hardware; field reliability testing; safety certifications.
Notes on feasibility across applications:
- Core dependencies include a robust LRM for per-frame meshes, camera pose estimation, optical flow and normal priors (e.g., RAFT, DSINE), and adequate GPU resources.
- The method is robust to view-overfitting and works with slowly moving or static cameras but currently relies on a stable canonical mesh and is limited with topological changes.
- Processing is offline with current training times (~90 minutes for ~500 frames on a single RTX 3090), which is suitable for production and research pipelines but not yet for real-time experiences.
Glossary
- 2D GS: A variant of Gaussian Splatting constrained to 2D surfaces, often anchored to mesh faces for improved geometric fidelity. "We propose Tessellation GS, a structured 2D GS approach anchored on mesh faces, to reconstruct dynamic scenes from a single continuously moving or static camera."
- 3D Gaussian Splatting (GS): An explicit scene representation using anisotropic 3D Gaussian volumes for efficient differentiable rendering. "3D Gaussian Splatting (GS) enables highly photorealistic scene reconstruction from posed image sequences"
- 4D methods: Approaches that model scene dynamics across space and time (spatiotemporal), often leveraging temporal embeddings or factorization. "Such \"4D\" methods leverages spectral-biasedness of MLP or spatial-temporal factorization but relies on explicit or implicit (camera movement) multi-view input."
- Adaptive face subdivision: A strategy that refines mesh faces based on local detail to guide where and how Gaussians should be subdivided. "Gaussian subdivision is guided by an adaptive face subdivision strategy driven by a detail-aware loss function."
- Anisotropic: Direction-dependent property; in GS, Gaussians can have different scales along axes, which can cause view-dependent artifacts. "struggles with viewpoint extrapolation due to its anisotropic nature"
- Animatable Gaussians: A Gaussian-based method that models pose-dependent appearance and deformation for dynamic objects. "similar to Gaussian Avatar~\cite{hu2024gaussianavatar} and Animatable Gaussians~\cite{li2024animatable}"
- Avatar-like methods: Template-based human reconstruction approaches that fit category-specific models (e.g., SMPL) with pose-conditioned attributes. "On the other hand, avatar-like methods~\cite{hu2024gaussianavatar, guo2023vid2avatar, zheng2023pointavatar, li2024animatable} enable per-pose Gaussian attributes modeling for human performance reconstruction"
- BANMo: A method that builds canonical templates and correspondence for dynamic objects, inspiring control-point driven deformations. "Then similar to BANMo~\cite{yang2022banmo}, our deformation model initializes control points and optimize their positions and a time-conditioned MLP to drive their motions."
- Barycentric coordinate: A coordinate system relative to a triangle’s vertices used to interpolate positions or features on faces. "Each Gaussian has a learnable barycentric weight to interpolate from the 3 vertices to decide their barycentric coordinate."
- Canonical mesh: A reference mesh chosen as the canonical (rest) configuration from which deformations to other frames are defined. "We have LRM output corresponding meshes to each frame of the input video and choose one (in our experiments simply the first mesh) to be canonical mesh."
- Chamfer distance: A metric for geometric similarity between point sets/meshes, measuring average closest-point discrepancies. "Our method outperforms previous SOTA method, reducing LPIPS by 29.1\% and Chamfer distance by 49.2\% on appearance and mesh reconstruction tasks."
- Control points: A set of points driving mesh deformation via learned motions and vertex skinning weights. "our deformation model initializes control points and optimize their positions and a time-conditioned MLP to drive their motions."
- Convex hull: The smallest convex set containing all mesh vertices; constraining control points inside it stabilizes deformation. "this keeps the control points within the convex hull of the mesh."
- Deformation field: A learned mapping that displaces canonical geometry over time using control points and motion MLPs. "we propose to learn a deformation field with control points whose movements are defined by a motion MLP"
- Differentiable rendering: Rendering models with differentiable image formation to enable gradient-based optimization from images. "With the spark of differentiable rendering, the task has shifted from solely relying on special equipments like depth cameras and LiDARs to leveraging more accessible multi-camera or monocular video setup."
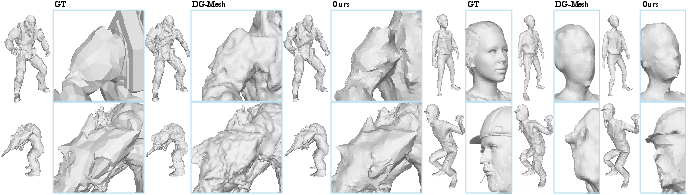
- DG-Mesh: A mesh-anchored Gaussian method for dynamic scenes that uses regularization but can still overfit in monocular settings. "DG-Mesh utilized Laplacian regularization to ensure smoothness of the reconstructed geometry."
- DSINE: A model used to provide normal supervision signals for training, particularly with static cameras. "We use normal supervision provided by DSINE~\cite{bae2024rethinking} only for static cameras."
- Edge length regularization: A constraint penalizing changes in mesh edge lengths to preserve local structure during deformation. "where we penalize edge length changes with respect to canonical mesh"
- Farthest Point Sampling (FPS): A strategy to select a diverse set of points by iteratively choosing the farthest point from the current set. "To initialize the control nodes, we use farthest point sampling (FPS) to select 30 points"
- Gaussian Avatar: A pose-conditioned Gaussian approach for human performance reconstruction used as a reference for pose embeddings. "similar to Gaussian Avatar~\cite{hu2024gaussianavatar} and Animatable Gaussians~\cite{li2024animatable}"
- Gaussian occlusion: Overlapping or hidden Gaussians that are unsupervised by training views, causing artifacts in novel views. "that both avoids Gaussian occlusion and scale overfitting"
- Gaussian opacities: Opacity parameters of Gaussians, used here to compete between parent/child Gaussians to control subdivision without gradients. "We utilized Gaussian opacities for gradient-free Gaussian subdivision."
- Gaussian Splats: Rendered Gaussian primitives representing surfaces or volumes when splatted into the image plane. "mesh based GS~\cite{guedon2024sugar, gao2024mesh} anchor Gaussian Splats to mesh faces"
- Gaussian offset: A learned displacement of Gaussians along face normals to model fine geometric details under constraints. "for Gaussian offset along the face normal direction, rather than employing a soft Gaussian anchoring constraint as in DG-Mesh~\cite{liu2024dynamic}, we introduce a scale-dependent anchoring strategy."
- Geometry prior: A prior estimate of object shape used to initialize or constrain reconstruction in absence of multi-view cues. "we propose to use a template-free geometry prior to anchor our surfel-like Gaussian attributes."
- HexPlane: A method that factorizes spatiotemporal information into planes decoded by MLPs for dynamic scene modeling. "HexPlane factorizes spatiotemporal information into several feature planes that are decoded by MLP."
- ICP (Iterative Closest Point): An algorithm to align two shapes by iteratively matching closest points and estimating rigid transforms. "We then perform ICP (Iterative Closest Point) between canonical mesh and each of the meshes in the sequence."
- Laplacian regularization: A mesh smoothness constraint penalizing deviation from the Laplacian (mean neighbor position) to reduce noise. "DG-Mesh utilized Laplacian regularization to ensure smoothness of the reconstructed geometry."
- Large Reconstruction Model (LRM): A foundation model used to extract per-frame coarse geometry priors from images. "we apply large reconstruction model (LRM) to extract coarse geometry frame by frame."
- LiDARs: Laser-based sensors that measure distances to reconstruct 3D structure, formerly central to scene capture pipelines. "With the spark of differentiable rendering, the task has shifted from solely relying on special equipments like depth cameras and LiDARs"
- LPIPS: A learned perceptual metric assessing image similarity aligned with human perception. "Our method outperforms previous SOTA method, reducing LPIPS by 29.1\%"
- Mesh-Gaussian quad tree: A hierarchical scheme subdividing mesh faces into Gaussian faces, enabling adaptive Gaussian density. "We build mesh-Gaussian quad tree as demonstrated in \cref{fig:pipeline} (c) and \cref{fig:quad}."
- Mesh-GS: A mesh-based Gaussian Splatting approach that aligns Gaussians to mesh faces to reduce overfitting. "mesh based GS~\cite{guedon2024sugar, gao2024mesh} anchor Gaussian Splats to mesh faces"
- MLP (Multi-Layer Perceptron): A neural network used to decode features, weights, motions, and appearance in the pipeline. "TiNeuVox and HexPlane factorizes spatiotemporal information into several feature planes that are decoded by MLP."
- Monocular differentiable rendering: Single-camera differentiable rendering methods that combine photometric and geometric constraints. "Recent monocular differentiable rendering methods incorporate geometric constraints alongside photometric loss with implicit NeRF or explicit Gaussian Splatting representation."
- Normal consistency regularization: A loss encouraging neighboring vertex normals to be similar, promoting surface smoothness. "Normal consistency regularization ensures smoothness of mesh surface."
- Optical flow: The per-pixel motion field between frames, used here as a prior to regularize dynamic reconstruction. "where is the difference between the rendered optical flow and the optical flow predicted by RAFT~\cite{teed2020raft}."
- Pose embedding: A learned vector encoding pose-related signals (e.g., control point positions) to model pose-dependent appearance. "To model pose dependent apperance, we encode the location of the 30 control points into a pose embedding "
- PSNR: A pixel-wise fidelity metric (Peak Signal-to-Noise Ratio) for image reconstruction quality. "PSNR "
- RAFT: A state-of-the-art optical flow estimator used to provide flow priors during training. "the optical flow predicted by RAFT~\cite{teed2020raft}"
- Radial basis function: A kernel function (here Gaussian) used to weight influence based on distance for skinning weights. " is an isotropic Gaussian kernel for radial basis function whose scales are determined by the average nearest neighbor distance of the control points at initialization"
- Robust Chamfer Distance (RCD): A truncated Chamfer loss variant that caps large errors to stabilize training. "Our proposed robust Chamfer distance that truncate loss to zero above a threshold."
- Scaffold GS: A Gaussian Splatting variant that encodes local geometry into compact neural features to combat overfitting. "Scaffold GS~\cite{lu2024scaffold} partially solved the overfitting issue by encoding local geometric structures in compact neural features."
- Sigmoid activation: A bounded nonlinearity used to constrain Gaussian scales relative to triangle dimensions. "Gaussian scales are constrained to a maximum of one-fourth of the base and height of their respective triangles by applying a sigmoid activation to the decoded $\mathbf{s_{2D}$"
- Skinning weight: The per-vertex weights associating vertices to control points for deformation. "we jointly optimize the skinning weight of mesh vertices to drive the mesh."
- SMPL: A parametric human body model commonly used as a category-specific template. "category-specific template, e.g. SMPL~\cite{loper2015smpl}."
- Spectral-biasedness: The tendency of MLPs to fit low-frequency components first, impacting temporal modeling. "Such \"4D\" methods leverages spectral-biasedness of MLP"
- SSIM: A perceptual image similarity metric (Structural Similarity Index) used as a photometric loss. ""
- Structure from Motion (SfM): A multi-view geometry pipeline recovering camera poses and sparse geometry from images. "DG-Mesh generates noisy meshes due to its reliance on SfM to initialize meshes"
- Taubin smoothing: A mesh smoothing technique that reduces noise while preserving features. "We fix the mesh by Taubin smoothing~\cite{taubin}"
- Template-free: Methods that do not rely on category-specific templates, enabling general, category-agnostic reconstruction. "In terms of template-free method, DG-Mesh~\cite{liu2024dynamic}, TiNeuVox~\cite{fang2022TiNeuVox}, and HexPlane~\cite{cao2023hexplane} pose various structural and loss designs."
- TiNeuVox: A dynamic NeRF-like method that factorizes spatiotemporal content into feature planes. "TiNeuVox and HexPlane factorizes spatiotemporal information into several feature planes that are decoded by MLP."
- Time-conditioned: A modeling approach where networks or embeddings are conditioned on time to capture dynamics. "NeRF based methods~\cite{fang2022TiNeuVox, park2021hypernerf, pumarola2021d, park2021nerfies, cao2023hexplane, li2022neural} usually uses a time-conditioned or per-frame embedding conditioned NeRF"
- View-overfitting: Over-optimization to training views that harms novel-view generalization. "We also proposed two constraints for mesh Gaussians to avoid view-overfitting."
Collections
Sign up for free to add this paper to one or more collections.