ControlVP: Interactive Geometric Refinement of AI-Generated Images with Consistent Vanishing Points
Abstract: Recent text-to-image models, such as Stable Diffusion, have achieved impressive visual quality, yet they often suffer from geometric inconsistencies that undermine the structural realism of generated scenes. One prominent issue is vanishing point inconsistency, where projections of parallel lines fail to converge correctly in 2D space. This leads to structurally implausible geometry that degrades spatial realism, especially in architectural scenes. We propose ControlVP, a user-guided framework for correcting vanishing point inconsistencies in generated images. Our approach extends a pre-trained diffusion model by incorporating structural guidance derived from building contours. We also introduce geometric constraints that explicitly encourage alignment between image edges and perspective cues. Our method enhances global geometric consistency while maintaining visual fidelity comparable to the baselines. This capability is particularly valuable for applications that require accurate spatial structure, such as image-to-3D reconstruction. The dataset and source code are available at https://github.com/RyotaOkumura/ControlVP .




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1) What this paper is about
This paper introduces a tool called ControlVP that fixes a common mistake in AI-generated pictures: wrong perspective. In real life, lines that are parallel (like the edges of a straight road or the sides of a building) look like they meet at a far–away point called a vanishing point. Many AI images mess this up, so buildings look slightly warped or “off.” ControlVP helps users quickly correct those mistakes so the image looks realistic.
2) The main questions the authors asked
In simple terms, the researchers wanted to know:
- Can we help AI-made images follow real-world perspective rules, especially vanishing points?
- Can users give simple guidance (like drawing building outlines) so the AI fixes only what’s wrong without ruining the rest?
- Can we design a learning rule that teaches the AI to line up edges toward the right vanishing point?
- Will these fixes improve the geometry while keeping the image looking natural and high-quality?
3) How the method works (explained simply)
Think of ControlVP like a smart “perspective fixer” for AI images. Here’s the idea in everyday terms:
- The problem: In a photo-like image, parallel lines (like windows, walls, or street edges) should appear to meet at the same point in the distance (the vanishing point). When they don’t, the picture feels wrong.
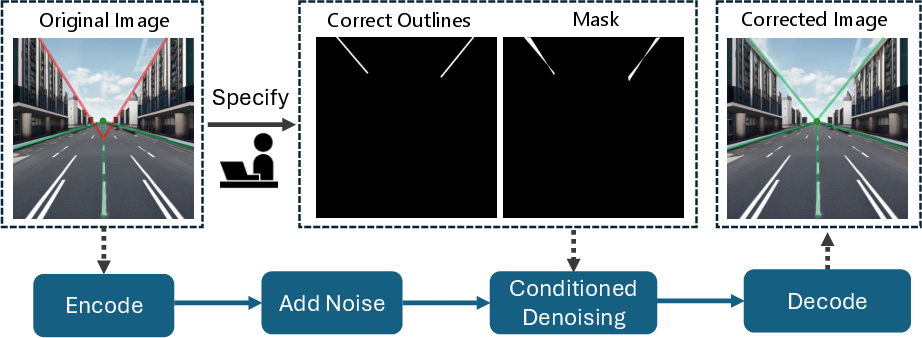
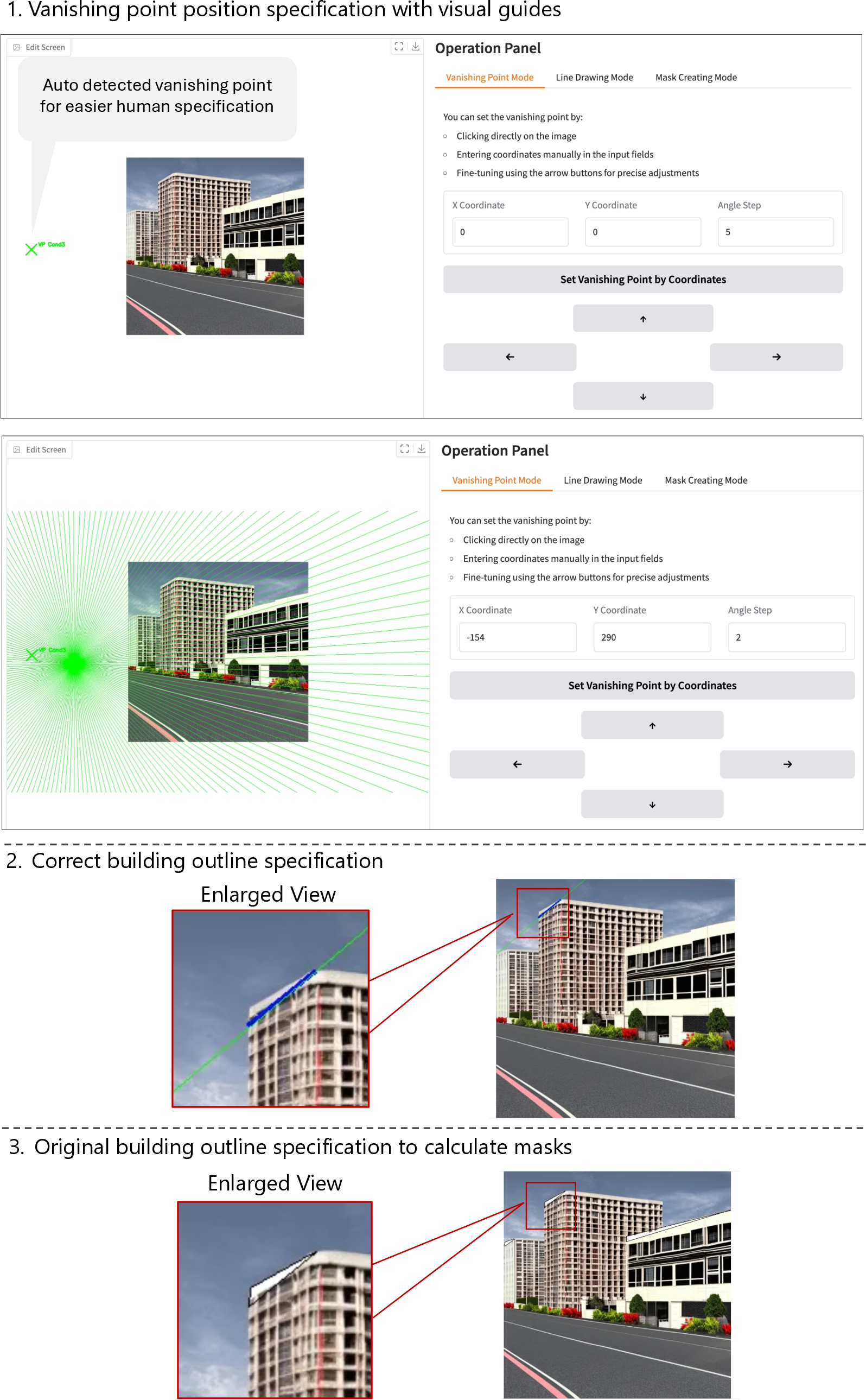
- The user’s role: Through a simple interface, you:
- Mark where the vanishing point should be.
- Sketch the correct outlines of parts of a building (and where the original, wrong outlines are).
- The system makes a mask so it only changes the parts that need fixing, leaving the rest untouched.
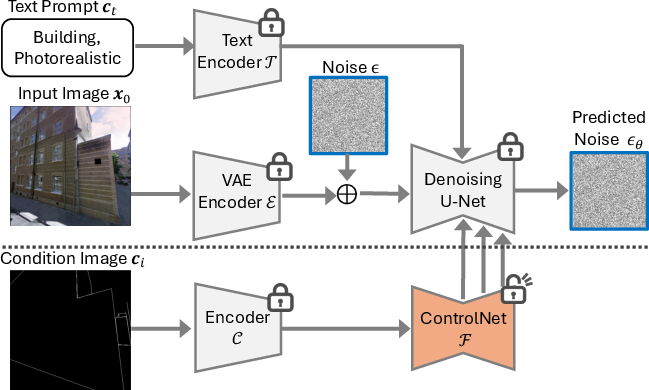
- The engine under the hood:
- It uses a popular image-making AI called a diffusion model (similar to Stable Diffusion), plus an add-on called ControlNet. Imagine ControlNet as a “tracing guide” that helps the AI follow your outlines.
- It performs “inpainting,” which means it redraws only the masked areas while blending them smoothly back into the image.
- It adds a special training rule called Vanishing Point Loss. In simple terms, this rule rewards the AI when edges in the image point toward the vanishing point and penalizes it when they don’t. This trains the model to respect perspective.
- A small but important trick:
- They tune a setting called guidance (Classifier-Free Guidance) so the model strongly follows the outline instructions without making the texture look weird. For their task, turning this up helps the AI obey the geometric guidance while keeping the image detailed.
4) What they found and why it matters
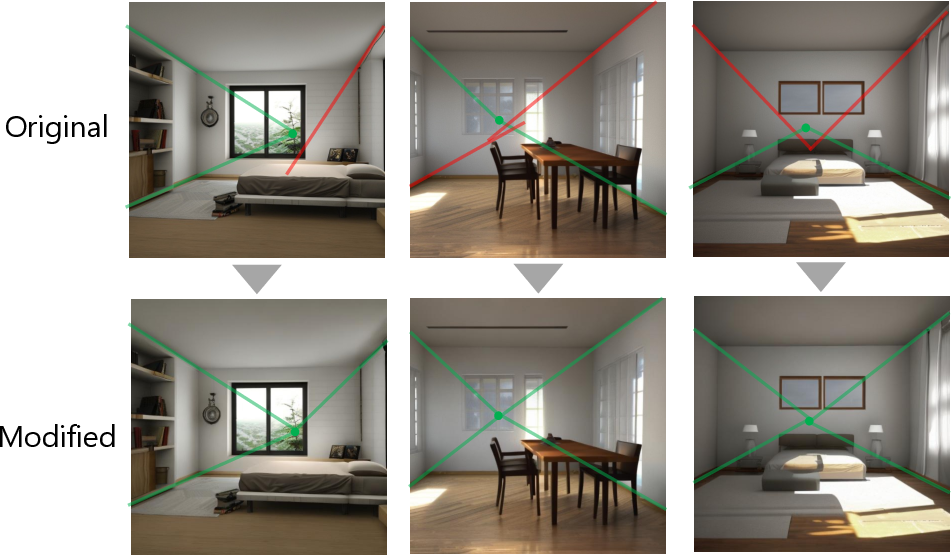
In their tests, ControlVP:
- Fixed perspective errors better than other methods. Measured by “angle accuracy” (how well lines point to the correct vanishing point), their results were consistently higher.
- Kept the image looking natural. They checked “perceptual similarity,” which roughly means “does it still look like the original?” ControlVP stayed close to the original while fixing geometry.
- Beat a previous method that needed depth maps (extra 3D information). That older approach often couldn’t correct warped lines because it relied on depth taken from the already-wrong image. ControlVP doesn’t need that extra data—just your outlines.
- Worked on images from different AI models and even generalized to indoor scenes (like hallways), not just outdoor buildings.
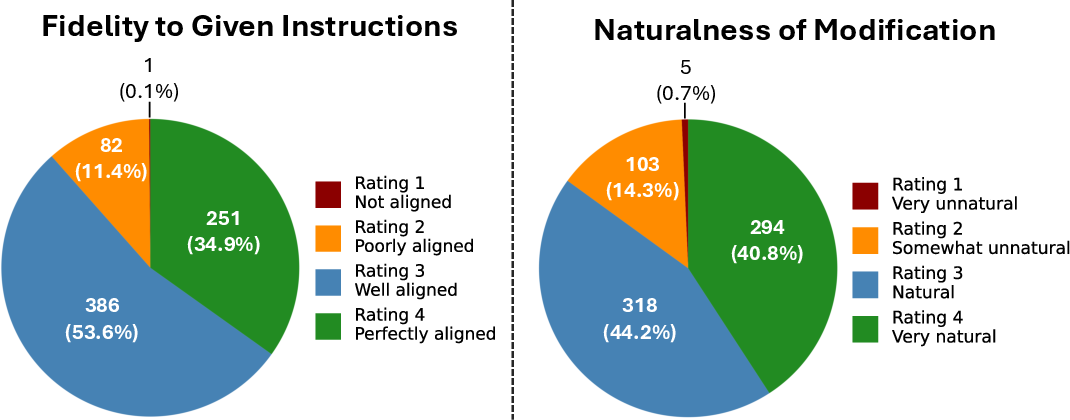
- Was preferred by people in a user study, who said the corrected images both lined up well and looked natural.
This matters because perspective is a big part of how we understand space. If the geometry is off, the image feels fake. Better vanishing point consistency means:
- More realistic and trustworthy images.
- Improved usefulness for tasks like turning images into 3D models, architecture previews, robotics, or navigation research—areas that depend on accurate geometry.
5) Why this research is useful and what could come next
ControlVP shows that:
- Simple user guidance (drawing outlines and picking a vanishing point) can help AI fix geometry without ruining style or details.
- We can train AI to respect real-world rules of perspective, making AI art and design more dependable.
Possible impacts and future directions:
- Designers, architects, and 3D artists can quickly clean up AI images for professional use.
- Researchers can use more reliable AI images for tasks like depth or 3D reconstruction.
- Future work could handle more scene elements (like roads and markings), reduce the amount of manual input, and extend from single images to consistent video corrections over time.
In short, ControlVP is like giving AI a ruler and a perspective guide: it makes pictures not just pretty, but also structurally believable.
Knowledge Gaps
Below is a concise, actionable list of the knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Extend beyond building outlines to other geometric elements (e.g., road markings, street lines, furniture, interiors) and to curved/organic structures where “parallelism” is ambiguous.
- Support simultaneous correction of multiple vanishing points in one scene (e.g., 2–3 principal directions), including how to specify, optimize, and reconcile intersecting masks and constraints.
- Develop automatic detection of VP inconsistencies and proposal of corrected outlines (auto-annotation), and quantify robustness to noisy or imperfect user inputs (outline endpoints, VP positions).
- Provide systematic sensitivity analyses and auto-tuning for key hyperparameters (threshold angle θ, VP loss weight λ, image guidance scale ω2, mask width/feathering), with principled defaults.
- Quantify the impact of the 2-step denoising approximation used in VP loss computation versus full denoising; explore alternative training-time approximations (e.g., distillation, teacher–student).
- Evaluate edge detector choices (Sobel vs learned detectors like HED/DexiNed) and robustness under occlusions, repeated patterns, texture clutter, extreme lighting, blur, and shadows.
- Measure semantic and prompt conformity after correction (content drift, material/identity changes), not just geometric alignment; include text-prompt fidelity metrics.
- Introduce region-specific geometric metrics (inside masks) such as line straightness, VP scatter, and re-projection error, in addition to global AA and PSD.
- Broaden baselines for fair comparison (e.g., edge-conditioned ControlNet, normals+depth conditioning, classical geometric post-warping) and train perspective-loss baselines with clean synthetic depth to avoid confounds from distorted depth.
- Validate downstream benefits quantitatively for tasks that rely on projective geometry (monocular depth, image-to-3D reconstruction, lane detection, SLAM), rather than asserting potential utility.
- Extend to video with temporal consistency: per-frame VP tracking, cross-frame constraints, optical-flow-aware losses, flicker/stability analysis, and style consistency across frames.
- Test generalization across diverse cities/architectural styles and non-Manhattan scenes; provide quantitative indoor evaluations rather than only qualitative examples.
- Assess high-resolution scalability (runtime, memory) and artifact mitigation for tiling/patch-based processing at megapixel resolutions.
- Report end-to-end interactivity metrics (latency per correction, average user time, throughput) to substantiate “interactive” claims and scalability for bulk corrections.
- Incorporate camera model awareness by estimating/using intrinsics/extrinsics to tie VP constraints to physical projection; evaluate if camera-aware losses improve consistency.
- Formalize and empirically validate the outside-mask “ideal latent/noise” handling (reverse-process fidelity, boundary behavior), and analyze artifacts when this assumption breaks.
- Clarify GUI support for specifying multiple VPs, overlapping masks, and complex scene layouts; evaluate performance when correcting more than one VP simultaneously.
- Provide a principled analysis of classifier-free guidance on sparse image conditions (why large image guidance scales help, failure thresholds, interactions with text CFG), beyond empirical observations.
- Strengthen evaluation robustness: quantify sensitivity to errors in VP detection during AA computation; expand and diversify the evaluation dataset (size, scene types), report inter-annotator agreement, and release detailed labels.
- Characterize limits under extreme geometric edits (large deviations from the original), define plausibility constraints to avoid overcorrection, and propose safeguards or user feedback mechanisms.
Glossary
- 2-step denoising: A training-time approximation that decodes an image from latents in two denoising steps to reduce computational cost while maintaining fidelity. "To approximate this generation process efficiently, we adopt the 2-step denoising method~\cite{zhao2023diffswap}."
- Angle accuracy (AA): A metric that measures how closely detected vanishing-point directions align with specified targets, reported at angular thresholds. "We adopted two metrics, angle accuracy (AA) and perceptual similarity distance (PSD), to measure the consistency with VP and overall image quality of the corrected images, respectively."
- Camera calibration: The process of estimating a camera’s internal (intrinsic) and external (extrinsic) parameters from images. "Early research in the 90s primarily focused on camera calibration, \ie, estimating internal parameters (focal length, principal point, and distortion) and external parameters (rotation, translation) from one or multiple images~\cite{caprile1990using, guillou2000using, cipolla1999camera}, without calibration targets (\eg, checkerboard)."
- Classifier-free guidance (CFG): An inference-time technique that interpolates between conditional and unconditional noise predictions to strengthen adherence to conditions. "Classifier-free guidance (CFG)~\cite{ho2021classifierfree} is an inference-time technique that enhances the fidelity of input conditions by interpolating between conditional and unconditional noise predictions as follows:"
- ControlNet: An extension to diffusion U-Nets that adds trainable conditional branches to control generation with spatial inputs (e.g., edges, depth). "ControlNet~\cite{zhang2023adding} extends LDM's capability by enabling image conditioning."
- Denoising diffusion probabilistic models: Generative models that iteratively remove noise from data following a learned stochastic process. "RePaint~\cite{lugmayr2022repaint} leverages denoising diffusion probabilistic models with a resampling strategy to maintain consistency between inpainted and unmasked regions."
- Depth-conditioned latent diffusion model: A latent diffusion model that uses depth maps as conditioning signals to guide generation. "To address this issue, they fine-tuned a depth-conditioned latent diffusion model~\cite{Rombach_2022_CVPR} using an additional loss term considering VP consistency."
- Depth maps: Per-pixel measurements of scene distance used as geometric conditioning for image generation. "ControlNet~\cite{zhang2023adding} enables spatial conditioning through various image-based inputs such as edge maps, depth maps, and human pose."
- Douglas-Peucker algorithm: A curve simplification algorithm that approximates contours by reducing points while preserving shape. "Concretely, we extracted contours and approximated them as polygons using the Douglas-Peucker algorithm~\cite{ramer1972,douglas1973}."
- Graphical user interface (GUI): An interactive interface for specifying vanishing points and outlines during inference. "The user instruction for specifying target VPs and building outlines is performed through a graphical user interface (GUI) we developed."
- Image-to-3D reconstruction: Techniques that infer 3D geometry from 2D images for downstream applications. "This capability is particularly valuable for applications that require accurate spatial structure, such as image-to-3D reconstruction."
- Inpainting: The process of filling or modifying masked regions in images to reconstruct content consistently. "We then apply an inpainting technique that selectively modifies these masked regions according to the provided geometric guidance"
- Latent Diffusion Models (LDMs): Diffusion models operating in a compressed latent space via a VAE to generate high-quality images efficiently. "Latent Diffusion Models (LDMs) were first introduced alongside Stable Diffusion~\cite{Rombach_2022_CVPR}, which serves as the base model for our research."
- Light Detection and Ranging (LiDAR): A sensing technology that measures distances using laser pulses for 3D scene understanding. "Most recent work such as~\cite{zhao2024extrinsic} which proposes a method for external calibration of Light Detection and Ranging (LiDAR) and cameras using VPs, demonstrates that the use of VPs for calibration remains an active and evolving research topic."
- Manhattan world hypothesis: The assumption that dominant scene directions align to three orthogonal axes, used in VP detection. "We employ the state-of-the-art VP detection method~\cite{lin2022deep} that does not rely on the Manhattan world hypothesis."
- Perceptual similarity distance (PSD): A learned perceptual metric that quantifies semantic differences between images using deep features. "We adopted two metrics, angle accuracy (AA) and perceptual similarity distance (PSD), to measure the consistency with VP and overall image quality of the corrected images, respectively."
- Perspective Loss: A loss that encourages alignment of edges with vanishing-point directions by comparing edge strengths along rays from VPs. "The proposed ``Perspective Loss'' works as follows."
- Simultaneous Localization and Mapping (SLAM): Robotic techniques that estimate a robot’s position while building a map of the environment. "Their utility has been demonstrated particularly in Simultaneous Localization and Mapping (SLAM) technology~\cite{lim2021avoiding, ji2015rgb}."
- Sobel filters: Gradient-based operators used to compute edge intensities and directions in images. "our loss computation process begins with applying Sobel filters to both the predicted initial image $\mathbf{\hat{x}_0$ and the ground truth initial image to obtain their edge directions and intensities."
- Stable Diffusion: A widely used text-to-image latent diffusion model for high-quality image synthesis. "The emergence of models such as Stable Diffusion (SD)~\cite{Rombach_2022_CVPR} and Imagen~\cite{saharia2022photorealistic} has popularized the technology to generate high-quality images from text prompts."
- U-Net: A convolutional encoder–decoder architecture used here as the denoising backbone in diffusion models. "It creates a trainable copy of the pretrained denoising U-Net~\cite{ronneberger2015u} that processes additional input conditions such as edges, poses, or, in our case, building outlines."
- Vanishing point (VP): The point in an image where projections of parallel 3D lines converge under perspective projection. "A VP is a geometric concept describing the point in a 2D image where parallel lines in 3D space appear to meet."
- Vanishing Point Loss: A loss introduced to enforce edge alignment with VP directions using thresholded and weighted edge comparisons. "To further improve the geometric consistency of the generated images, we introduce a new loss function called Vanishing Point Loss."
- Variational Autoencoder (VAE): A generative encoder–decoder model that compresses images into latent space for diffusion-based synthesis. "LDMs achieve high-quality image generation with relatively few inference steps by utilizing a Variational Autoencoder (VAE)~\cite{kingma2013auto} that compresses images into a lower-dimensional latent space where the diffusion process operates."
- Video semantic segmentation: The task of assigning semantic labels to pixels across video frames, often leveraging geometric cues. "Guo et al.~\cite{guo2024vanishing} leveraged VPs in video semantic segmentation, using VP cues to improve frame-to-frame correspondence."
Practical Applications
Immediate Applications
The following applications can be deployed now, using the released code, dataset, and a standard diffusion stack (e.g., Stable Diffusion v2.1 + ControlNet) with GPU access.
- Perspective-correct post-processing for architectural concept art — Sectors: architecture, design, media
- Use: Clean up AI-generated exteriors/interiors where parallel structural lines (facades, beams, corridors) don’t meet at consistent vanishing points before client presentations or portfolio renders.
- Tools/workflow: SD/SD-WebUI + ControlVP extension; designer sketches desired building outlines and target VP in the GUI; inpainting executes localized fixes; export to Photoshop/Blender board.
- Assumptions/dependencies: User can identify intended VP(s) and draw rough outline edits; scenes are building-dominant; GPU required.
- Matte painting and key art refinement — Sectors: film/VFX, gaming, advertising
- Use: Enforce consistent perspective across digitally painted or AI-generated plates for set extensions, key art, and marketing visuals.
- Tools/workflow: DCC (Nuke/Photoshop) + ControlVP inpaint pass; perspective QA step with automated VP detection, then artist-guided correction; versioning in ShotGrid.
- Assumptions/dependencies: Manual guidance; limited to masked regions; edge detail preserved if guidance scale tuned.
- Quality gate for AI content pipelines — Sectors: creative agencies, publishers, platforms
- Use: Automatic VP consistency check and assisted correction for large batches of generated images to meet brand or platform quality standards.
- Tools/workflow: Batch VP detection (e.g., Deep VP detection) → flag inconsistencies → semi-automatic ControlVP GUI corrections → final human approval.
- Assumptions/dependencies: Tolerance thresholds (e.g., AA@5°) defined by team; some manual throughput still needed.
- Synthetic data sanitization for vision tasks — Sectors: autonomous driving, robotics, mapping
- Use: Correct VP errors in synthetic street scenes used to train lane detection, road topology extraction, or SLAM modules.
- Tools/workflow: Generate scenes → VP audit → ControlVP fix on flagged samples → remeasure AA metrics → ingest into training set.
- Assumptions/dependencies: Domain gap remains vs. real data; scenes must expose line geometry; throughput bound by GPU and human-in-the-loop.
- Preprocessing for image-to-3D reconstruction — Sectors: 3D vision, AR/VR, digital twins
- Use: Improve single-image reconstruction and camera estimation by ensuring straight, VP-consistent edges before reconstruction.
- Tools/workflow: ControlVP refine → structure-from-motion/NeRF pipeline → camera calibration/mesh recovery.
- Assumptions/dependencies: Correction improves geometry cues but does not by itself add metric depth; benefits largest for man-made scenes.
- Real estate and interior staging polish — Sectors: real estate, e-commerce, interior design
- Use: Fix “AI hallway” distortions (warped door frames, skewed furniture lines) in AI-staged interiors for listings and catalogs.
- Tools/workflow: Vendor CMS plugin; quick outline edit + inpaint; batch PSD report to ensure minimal deviation from original textures.
- Assumptions/dependencies: Scenes with clear rectilinear structure; staff trained to specify intended VP quickly.
- Perspective teaching and critique — Sectors: education (art, architecture), MOOCs
- Use: Interactive lessons demonstrating VP errors and corrections; students practice by redefining outlines and seeing immediate corrections.
- Tools/workflow: Classroom GUI + projector; curated examples from released VP inconsistency dataset; automated scoring via AA metrics.
- Assumptions/dependencies: Curriculum alignment; student devices need mid-tier GPU or hosted service.
- Research baselines and benchmarks — Sectors: academia, R&D labs
- Use: Train/test geometry-aware generation methods using the released dataset and VP loss; compare against Perspective Loss.
- Tools/workflow: ControlVP training scripts; ablations (with/without VP loss, CFG scales); publish AA/PSD benchmarks.
- Assumptions/dependencies: Dataset bias (London-centric HoliCity training) may affect cross-city generalization.
- Editorial image correction for print and web — Sectors: magazines, newspapers, marketing
- Use: Correct subtle perspective artifacts that can diminish perceived realism or credibility in AI-enhanced imagery.
- Tools/workflow: Editorial QA with VP detector overlay; ControlVP quick-pass inpainting; export with audit log.
- Assumptions/dependencies: Human judgment to set acceptable thresholds; time-per-image budget.
- Compliance labeling and audit support — Sectors: policy, platform governance
- Use: Provide a measurable record (AA scores) that AI images used in submissions (e.g., planning consultations) meet minimal geometric plausibility.
- Tools/workflow: VP scan → report with per-VP angular errors → optional ControlVP fix → rescan and archive.
- Assumptions/dependencies: Policies define acceptable AA thresholds; still requires local expert review for intent.
Long-Term Applications
These applications need further research, automation, or scaling (e.g., fully automatic constraint inference, video coherence, broader geometric priors).
- Fully automatic VP detection-and-correction without user input — Sectors: software, creative tools, platforms
- Vision: One-click fix that infers dominant parallel groups, targets VPs, and heals distortions automatically.
- Emerging tools/workflow: Line/plane detection + learned Manhattan/world priors + ControlVP-like inpainting; optional user override.
- Dependencies: Robust line grouping in diverse scenes; avoiding over-correction; uncertainty-aware UI.
- Geometry-aware diffusion models by design — Sectors: foundation models, graphics
- Vision: Train base T2I models with built-in VP and planarity constraints (e.g., integrated VP loss) to reduce post-hoc fixes.
- Emerging tools/workflow: Joint training with structural priors, contour conditions, and multi-constraint losses; geometry-aware schedulers.
- Dependencies: Large-scale training data with reliable geometric signals; balanced trade-offs vs. texture fidelity.
- Video-level perspective correction with temporal coherence — Sectors: film/VFX, generative video, robotics simulation
- Vision: Frame-consistent correction for Sora-like clips; stable VPs and outlines over time.
- Emerging tools/workflow: Optical flow/feature tracking to propagate masks and VP targets; diffusion-based inpainting with temporal losses.
- Dependencies: Design of temporal VP loss; compute budgets; prevention of flicker and drift.
- Beyond buildings: generalized constraint editing (roads, rails, furniture) — Sectors: transportation, retail, manufacturing
- Vision: Extend correction to road markings, shelving, machinery, vehicle bodies—any parallel-line-dominant structures.
- Emerging tools/workflow: Semantic segmentation + class-specific geometric constraints (e.g., lane parallelism, orthogonality).
- Dependencies: Robust semantic parsing; multiple-class geometric priors; mixed-manifold scenes.
- CAD-in-the-loop and reverse-engineering pipelines — Sectors: AEC, manufacturing, BIM
- Vision: Convert corrected outlines and VPs into parametric CAD constraints; update BIM elements from AI concepts.
- Emerging tools/workflow: Edge/VP extraction → camera calibration → parametric fit; round-trip edits between image and CAD model.
- Dependencies: Reliable calibration; handling occlusions; mapping 2D edits to valid 3D constraints.
- Consistency constraints across multi-view/multi-image generation — Sectors: AR/VR, digital twins
- Vision: Enforce cross-view geometric consistency for sets of images, enabling better multi-view reconstruction and texturing.
- Emerging tools/workflow: Bundle adjustment-like loss over generated views; shared VP/plane constraints; ControlNet conditioning per view.
- Dependencies: Viewpoint estimation; scalable multi-view training; conflict resolution among views.
- Standards and certification for synthetic imagery used in engineering and planning — Sectors: policy, public sector, AEC
- Vision: Require geometry metrics (e.g., minimum AA@5°) for AI imagery in planning submissions, tender visuals, or public consultations.
- Emerging tools/workflow: Open benchmarks and audit tools; certified checkers embedded in submission portals.
- Dependencies: Stakeholder consensus; allowances for artistic exceptions; clear measurement protocols.
- Real-time mobile capture aids and AR overlays — Sectors: mobile, AR, education
- Vision: On-device VP guides and corrective overlays while shooting or composing; AR lines snap to inferred VPs.
- Emerging tools/workflow: Lightweight VP detector + guidance UI; post-capture fix with mobile diffusion.
- Dependencies: Efficient models for edge devices; UX minimizing user burden.
- Simulation asset validation for autonomous systems — Sectors: autonomous driving, robotics
- Vision: Large-scale automated correction/validation of synthetic environments to reduce sim-to-real geometry gaps.
- Emerging tools/workflow: Scene graph → render → VP audit → batch corrections with control signals; feedback to scene generator.
- Dependencies: Integration with simulators (CARLA, Unreal); automatic outline generation; throughput scaling.
- Cross-modal calibration and supervision from generated imagery — Sectors: sensing, calibration, robotics
- Vision: Use VP-consistent synthetic images to supervise camera intrinsics/extrinsics estimation or LiDAR-camera calibration strategies.
- Emerging tools/workflow: VP cues + known scene priors → self-supervised calibration modules; synthetic-to-real transfer.
- Dependencies: Domain adaptation; ensuring synthetic cues translate to real hardware performance.
- Automated “GeoLint” for platforms — Sectors: social media, marketplaces, stock libraries
- Vision: Platform-level linting that flags and optionally auto-corrects geometric implausibility in uploads or listings.
- Emerging tools/workflow: VP/planarity scanner, confidence scoring, optional ControlVP-like correction, user opt-in.
- Dependencies: False positive management; policy alignment; compute costs at platform scale.
Common Assumptions and Dependencies
- Human-in-the-loop: Current pipeline relies on users to specify desired VPs and outlines; fully automatic operation is a long-term goal.
- Scene type: Strongest benefits in man-made, rectilinear scenes (architecture/interiors); performance may degrade on organic or highly non-Manhattan scenes.
- Compute: Diffusion-based inpainting requires GPU; batch or real-time use needs resource planning.
- Training data bias: Model trained on HoliCity (London) exteriors; indoor/generalization promising but not guaranteed; further domain data helps.
- Quality trade-offs: Higher guidance scales improve VP alignment but can increase perceptual distance; tuning per use case is required.
- Legal/compliance: Use of corrected AI imagery in regulated contexts may require disclosure and audit trails (store AA scores, masks, parameters).
Collections
Sign up for free to add this paper to one or more collections.