A multimodal Bayesian Network for symptom-level depression and anxiety prediction from voice and speech data
Abstract: During psychiatric assessment, clinicians observe not only what patients report, but important nonverbal signs such as tone, speech rate, fluency, responsiveness, and body language. Weighing and integrating these different information sources is a challenging task and a good candidate for support by intelligence-driven tools - however this is yet to be realized in the clinic. Here, we argue that several important barriers to adoption can be addressed using Bayesian network modelling. To demonstrate this, we evaluate a model for depression and anxiety symptom prediction from voice and speech features in large-scale datasets (30,135 unique speakers). Alongside performance for conditions and symptoms (for depression, anxiety ROC-AUC=0.842,0.831 ECE=0.018,0.015; core individual symptom ROC-AUC>0.74), we assess demographic fairness and investigate integration across and redundancy between different input modality types. Clinical usefulness metrics and acceptability to mental health service users are explored. When provided with sufficiently rich and large-scale multimodal data streams and specified to represent common mental conditions at the symptom rather than disorder level, such models are a principled approach for building robust assessment support tools: providing clinically-relevant outputs in a transparent and explainable format that is directly amenable to expert clinical supervision.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in plain language)
This paper shows how computers can help doctors spot signs of depression and anxiety by listening to how people speak. Instead of only asking, “Does this person have depression or not?”, the system looks for specific symptoms (like low mood, low energy, trouble sleeping, worry) and combines clues from someone’s voice and words to estimate how likely each symptom is.
The main questions the researchers asked
- Can a computer model use short speech recordings to predict symptoms of depression and anxiety accurately and fairly?
- Is it better to predict at the symptom level (e.g., low mood, worry) than just say “yes/no” for a disorder?
- Can the model combine different kinds of speech information (how you sound and what you say) in a smart way?
- Are the results reliable across different kinds of people (age, gender, race/ethnicity, accents, devices)?
- Will the results be helpful and acceptable in real healthcare, and what do service users think?
How they did it (explained simply)
Think of the system like a team of detectives and a head detective:
- The recordings: People did two quick tasks—(1) read aloud and (2) talk about how they’ve felt recently.
- The clues:
- Paralinguistic clues: how the voice sounds (tone, speed, pauses).
- Linguistic clues: what the words mean (topics, wording).
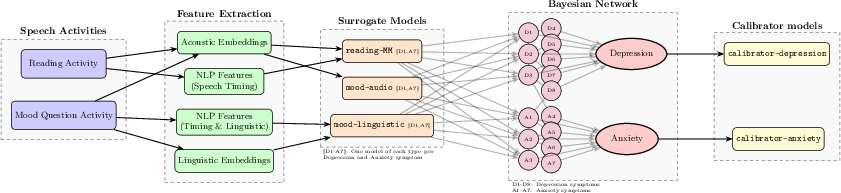
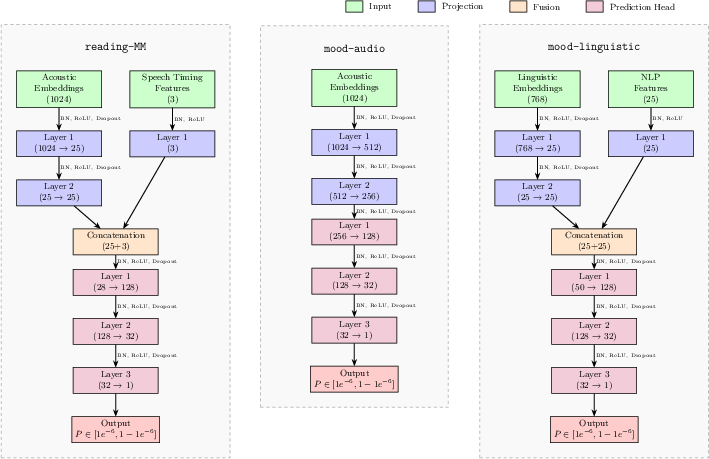
- The helpers (“surrogate models”): Small expert programs each focus on one symptom (like sleep problems or worry) and one type of clue (voice or words). Each helper gives its best guess about that symptom from its specific clues.
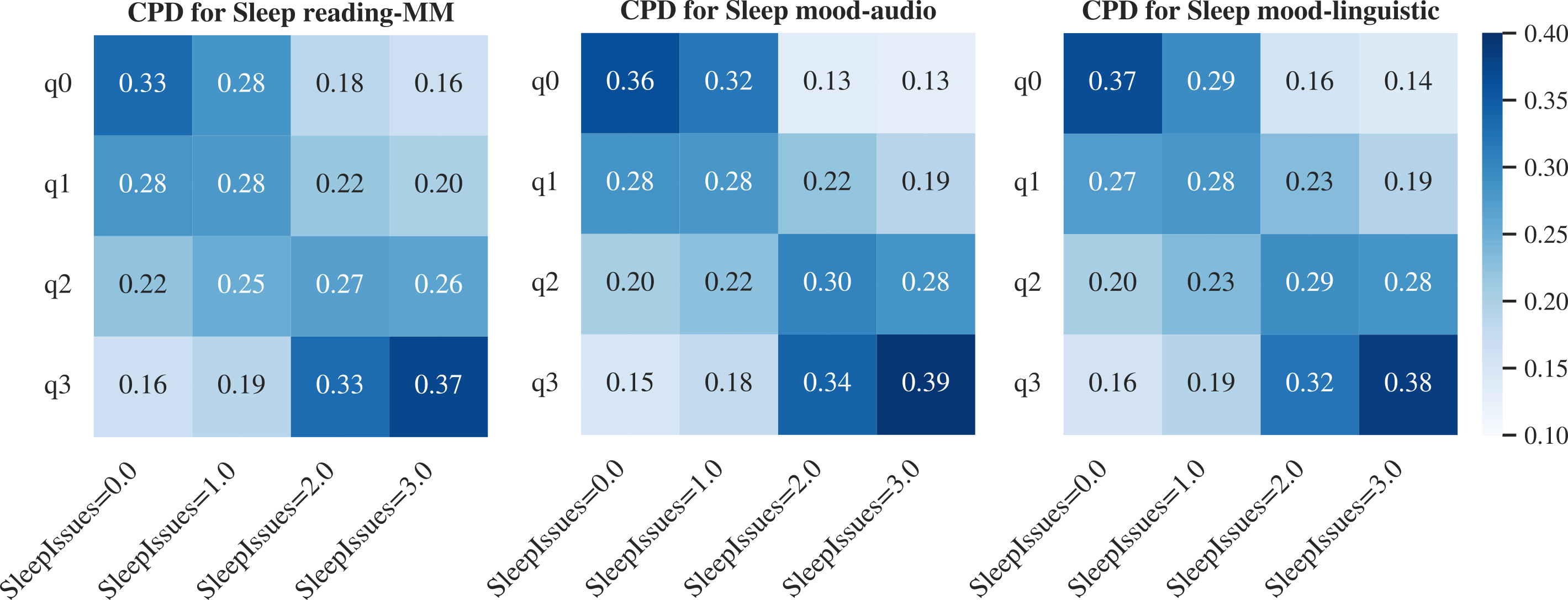
- The head detective (“Bayesian network”): This is a smart “web of probabilities.” It:
- Weighs each helper’s guess (trusting more reliable ones more).
- Understands that some symptoms often occur together (e.g., low energy and poor sleep).
- Combines everything to estimate how severe each symptom likely is and how likely overall depression or anxiety is.
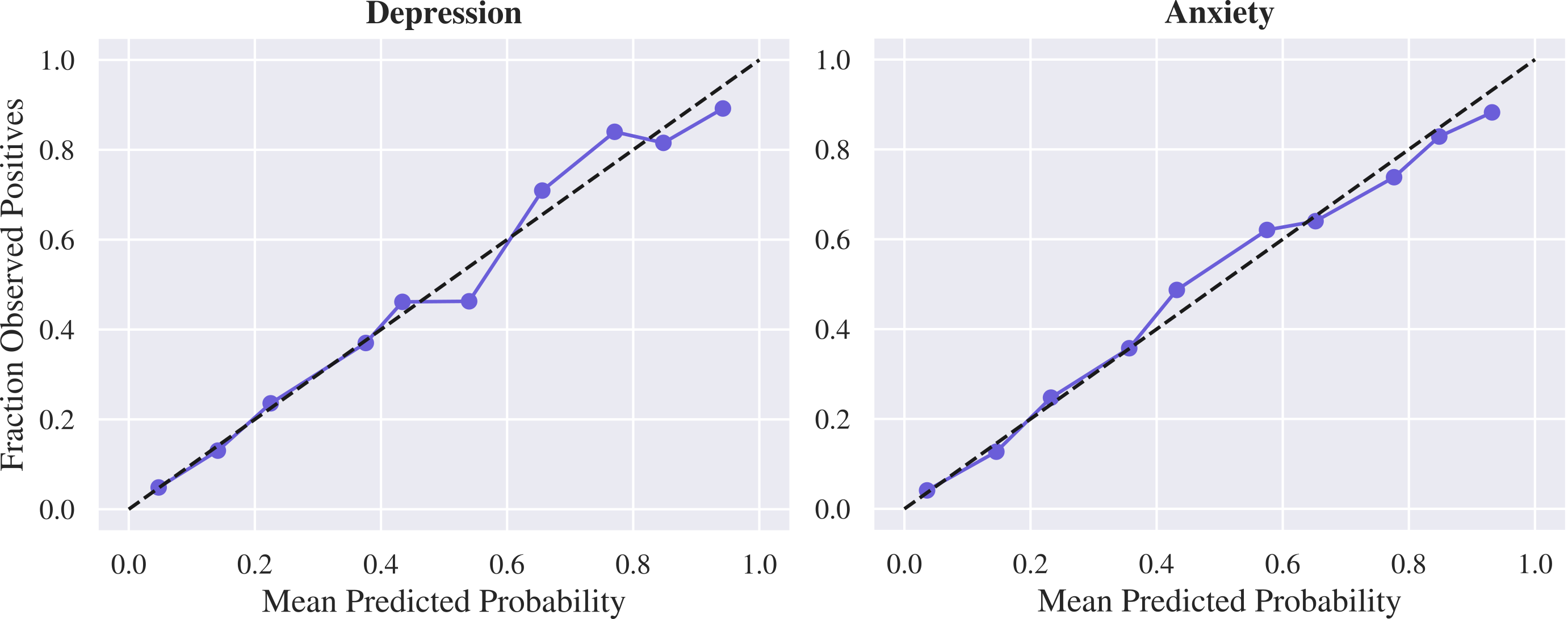
- Calibration (making numbers mean what they say): Finally, they adjust the model so that, for example, a “70% chance” really matches about 70 out of 100 people having the condition.
They trained and tested this on a very large dataset—over 30,000 different speakers—split into:
- A development set to build the models,
- A separate set to fine-tune calibration,
- A fully separate, unseen test set to check how well it works in practice.
What they found (and why it matters)
- Strong overall accuracy and honest probabilities
- For both depression and anxiety, the model was good at telling apart who likely does and does not have the condition (ROC-AUC about 0.84, which is considered strong).
- Its probability scores were well calibrated (so a “75% chance” really meant about 75% of people with that score had the condition).
- Symptom-level predictions worked well
- Many individual symptoms were predicted in the “fair-to-good” range (often around 0.70–0.80 ROC-AUC).
- Core symptoms like low mood, loss of interest, nervousness, and uncontrollable worry were especially well predicted.
- Handles different presentations (not everyone has the same symptoms)
- The model performed well for typical and less typical patterns of depression and anxiety symptoms, suggesting it can handle real-life variety.
- Severity scores matched real-life impact
- The model’s severity estimates lined up well with standard questionnaire scores (PHQ-8, GAD-7).
- Higher predicted severity also matched lower quality of life and more day‑to‑day difficulties, showing the predictions are meaningful.
- Fairness across groups
- Performance stayed high across age groups, genders, race/ethnicity groups, different accents, and device types.
- Some small differences in calibration (how well probabilities match outcomes) were found between certain groups, especially for anxiety by sex, but these were generally modest and can be improved (for example, by group‑specific calibration).
- Multimodal “backup” helps reliability
- Using both how you sound (paralinguistic) and what you say (linguistic) gave better and more robust results than either one alone.
- This redundancy is useful: if one type of input isn’t great (e.g., someone doesn’t share much, or there’s background noise), the other can still help.
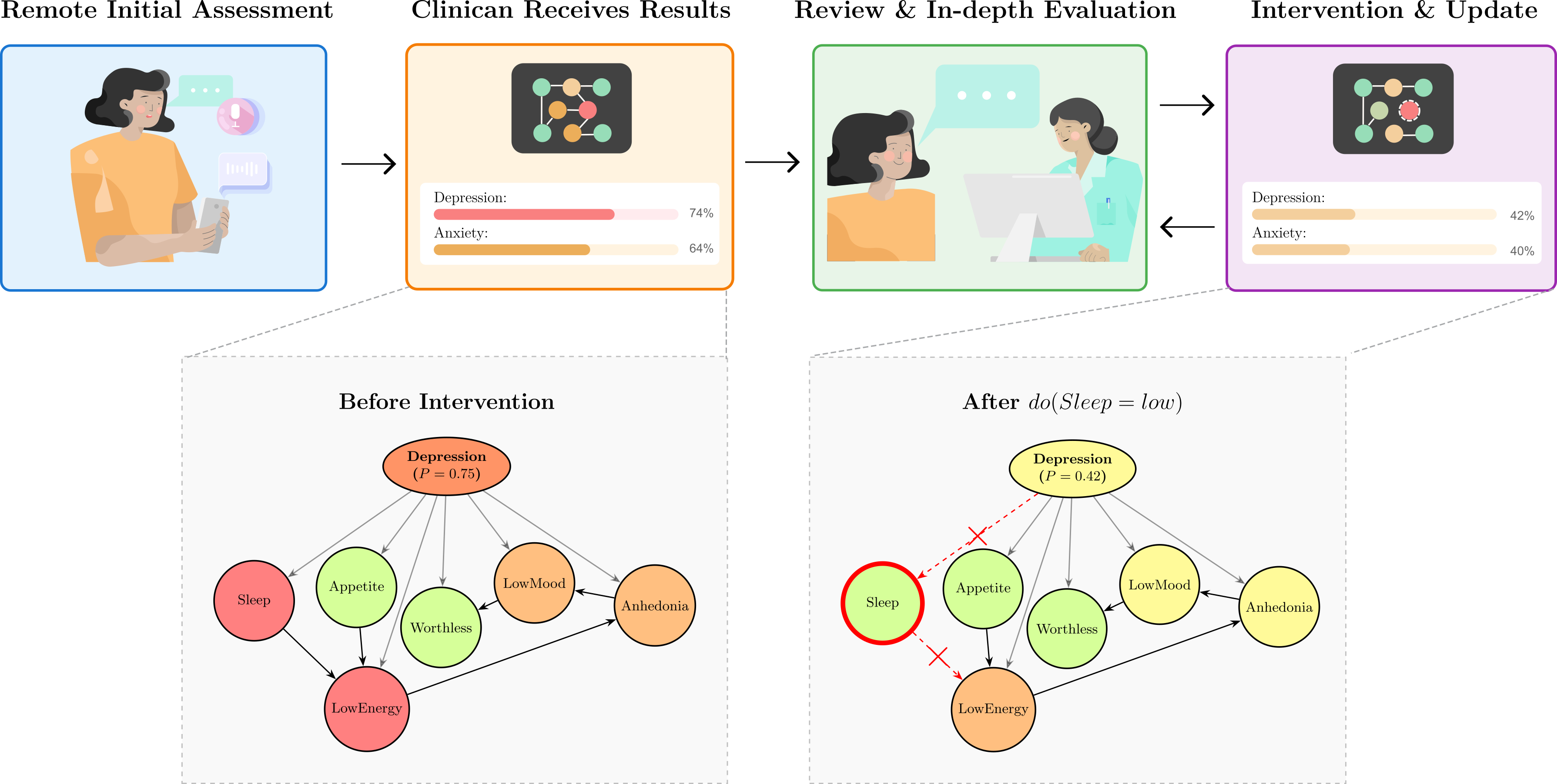
- Clinician-in-the-loop: predictions can be adjusted
- The system can be explained and edited by a clinician. For example, if poor sleep is due to caring for a sick family member rather than mental health, the clinician can tell the model to reduce sleep’s influence and see updated results. This keeps human judgment in charge.
- Useful as a screening tool
- In a population where about 3 in 10 people have depression or anxiety, a positive result meaningfully raised the odds someone truly had the condition, and a negative result lowered the odds. That’s good for triage: who to follow up with more closely.
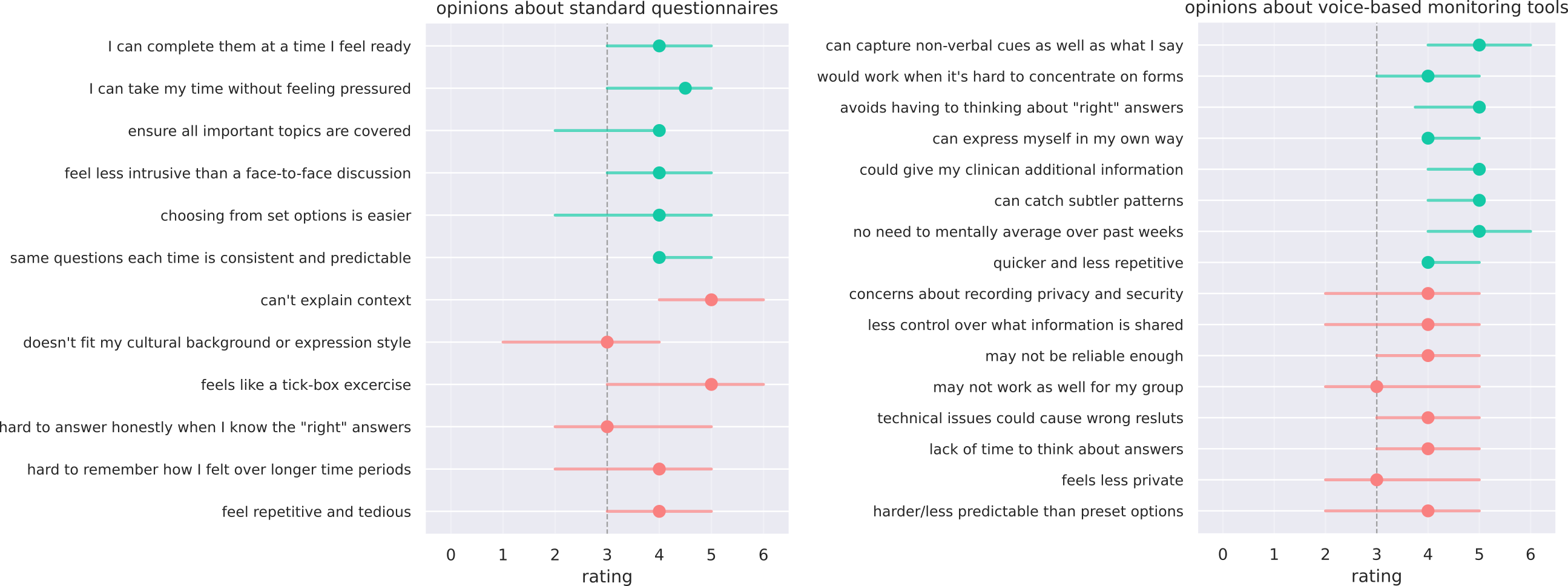
- What service users thought
- Many liked the idea (about 7 in 10 were excited or interested), especially the chance to capture tone and nuance beyond tick‑box forms.
- Common concerns: privacy/security, trust and accuracy (including across diverse groups), tech reliability, and making sure tools support—rather than replace—human care.
Why this matters and what could happen next
- Better support for clinicians: Doctors already listen for tone, speed, and fluency. This tool measures those features consistently and combines them with what’s said, giving clearer, symptom‑by‑symptom insights that can guide conversations and care.
- Focus on symptoms, not labels: Since treatment plans often target specific problems (e.g., sleep, concentration, worry), symptom‑level tracking can help personalize care and monitor progress over time.
- Fairness and scale: Using a very large, diverse dataset improves reliability and helps detect and reduce bias. Continued testing with more accents, languages, and clinical labels will make it stronger.
- Human oversight remains key: Because the model’s reasoning is transparent and editable, clinicians and patients can keep control and context at the center.
- Next steps: Validate against clinician diagnoses, expand to more data types (like simple thinking tasks or wearable data for sleep/restlessness), strengthen fairness calibrations, and set clear privacy protections so users feel safe and in control.
In short, this study shows a practical, explainable way to use voice and speech to help spot and track depression and anxiety symptoms. It doesn’t replace clinicians—it gives them better tools to understand, discuss, and support each person’s mental health.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Ground-truth validity: Validate condition and symptom predictions against clinician-administered assessments (e.g., SCID, MINI, structured MSE) rather than self-reported PHQ/GAD-derived labels, including adjudication of discordant cases.
- External generalizability: Conduct external, cross-site validation on independent cohorts (different providers, geographies) to assess transportability and robustness to dataset shift.
- Language and cultural coverage: Evaluate performance in non-English languages, broader accent/dialect families, and among non–first-language speakers; quantify effects of cross-cultural communication styles on both paralinguistic and linguistic channels.
- Underrepresented groups and intersectionality: Assess fairness across more granular and intersectional subgroups (e.g., race × gender × age), including transgender and nonbinary identities disaggregated from “woman, non-binary,” socioeconomic status, education, and region.
- Age extremes and special populations: Test in adolescents, older adults (65+), and populations with speech/communication differences (e.g., stuttering, dysarthria, aphasia), neurodevelopmental conditions, or sensory impairments.
- Clinical comorbidities and differential diagnosis: Evaluate performance in the presence of comorbid psychiatric/neurological disorders (e.g., bipolar, PTSD, psychotic disorders) and medical causes of overlapping symptoms (e.g., hypothyroidism, sleep apnea).
- Medication and substance effects: Quantify the impact of psychotropics (e.g., SSRIs, antipsychotics), sedatives, and substance use on speech/voice signals and prediction bias.
- Longitudinal utility: Establish test–retest reliability, sensitivity to change, and minimal clinically important differences (MCIDs) for symptom and condition severity estimates under real treatment trajectories.
- Real-world deployment and impact: Run prospective implementation studies and randomized pragmatic trials to test workflow integration, clinician acceptance, and effects on detection rates, referral times, and patient outcomes.
- Thresholding and decision support: Move beyond a fixed 0.5 threshold—perform decision curve analysis, context-specific threshold optimization (e.g., maximize NPV in triage), and net benefit/cost-effectiveness evaluations under varying prevalence.
- Calibration maintenance: Develop and test demographic-specific calibration and ongoing post-deployment recalibration strategies to manage drift and base-rate shifts (e.g., sex differences in anxiety).
- Handling missing or degraded inputs: Quantify performance degradation and uncertainty when one or more modalities are missing or low-quality; implement abstention policies and confidence-based routing to humans.
- Robustness to signal quality: Stress-test against background noise, microphone variability, codecs/compression, bandwidth constraints, and room acoustics; characterize degradation across SNR levels.
- ASR/NLP error sensitivity: Measure how automatic speech recognition errors (WER) and NLP parser biases vary by accent, dialect, and speech rate, and how these propagate to clinical predictions.
- Task design and leakage: Assess generalization when prompts do not solicit mood-content explicitly (to avoid semantic overlap with PHQ/GAD items); compare neutral tasks (e.g., picture description) and spontaneous speech in varied contexts.
- Symptom coverage gaps: Improve lower-performing symptoms (e.g., concentration, restlessness, appetite) by integrating additional modalities (cognitive tasks, actigraphy, sleep/passive sensing) and quantify their incremental utility.
- Multimodal fusion strategy: Systematically compare fusion architectures (early, late, hybrid) against the current surrogate-to-BN pipeline; perform ablation to justify architectural choices and quantify redundancy benefits.
- Causal assumptions and do-operations: Clarify and empirically validate the causal interpretability of the BN structure; test whether clinician do-operations produce clinically plausible counterfactual changes across diverse cases.
- Uncertainty communication: Determine how to present probabilistic symptom and condition uncertainties to clinicians and patients (e.g., credible intervals) to reduce automation bias without overwhelming users.
- Human factors and clinician-in-the-loop: Conduct usability studies of the explanation UI, do-operation workflows, and supervision burden; assess how clinician edits are logged, audited, and reconciled with accountability/liability.
- Safety and harm mitigation: Define safeguards for false positives/negatives in high-stakes contexts, crisis risk detection (e.g., suicidality, which is out of scope here), escalation pathways, and user feedback practices.
- OOD and misuse detection: Build out-of-distribution detectors for atypical speech, spoofing, or intentional manipulation; study vulnerability to TTS/voice conversion attacks and propose countermeasures.
- Regulatory pathway: Specify evidence requirements for classification as a medical device (e.g., UKCA/CE/FDA), including post-market surveillance plans and adherence to ISO/IEC 42001 governance in practice.
- Privacy and data governance: Prototype privacy-preserving pipelines (on-device processing, federated learning, differential privacy), data retention policies, and user controls aligned with voiced participant concerns.
- Representativeness and selection bias: Quantify how a consented, platform-based, predominantly White and tech-comfortable sample biases performance; replicate in clinical settings including severe cases and underserved populations.
- Survey generalizability: Expand acceptability research beyond a small, self-selected sample; co-design with diverse service users and clinicians to refine requirements and address skepticism toward AI-based tools.
- Device and environment diversity: Extend fairness and robustness testing to a wider variety of devices (entry-level smartphones, feature phones with headsets), OS versions, and low-connectivity settings.
- Open science and reproducibility: Provide sufficient methodological detail, code, and (where ethical) data access or synthetic datasets to enable independent replication and auditing.
- Broader condition coverage: Explore extending the BN to additional conditions and transdiagnostic dimensions (e.g., anergia, anergonia, irritability) and assess whether symptom-level modeling improves differential diagnosis.
- Ethical boundaries of automation: Define guardrails ensuring the tool augments rather than replaces clinical contact, and measure impacts on therapeutic alliance and patient autonomy over time.
Collections
Sign up for free to add this paper to one or more collections.