- The paper presents a novel framework that captures relational visual similarity through group-based captioning and contrastive learning.
- It leverages a vision-language model to disentangle relational logic from attribute biases, improving retrieval and analogical image generation.
- Empirical results show that the relsim model outperforms baselines like LPIPS, CLIP, and DINO, aligning more closely with human judgment.
Relational Visual Similarity: A Framework for Human-Like Analogical Perception
Introduction
Visual similarity metrics play a central role in modern computer vision, underpinning tasks in retrieval, recognition, and generative modeling. Canonical approaches, including LPIPS, CLIP, and DINO, conceptualize similarity primarily in terms of perceptual or attribute features, such as color, texture, and class semantics. However, human perception also robustly supports relational similarity: abstraction over analogical structure, where the mapping between entities is defined by the correspondence of relationships rather than raw attribute overlap. "Relational Visual Similarity" (2512.07833) systematically formulates, benchmarks, and learns this missing axis of similarity, proposing new data, models, and evaluation protocols for capturing logic- and abstraction-driven visual correspondence. This essay analyzes the technical design, empirical results, and implications of the work.
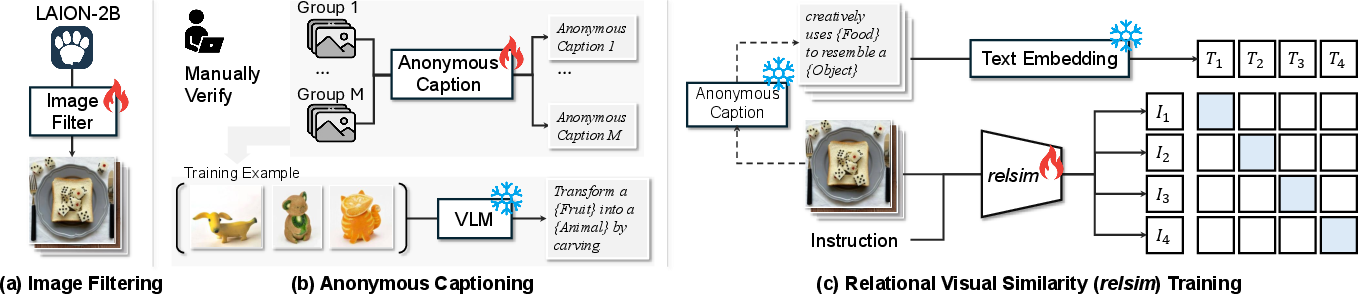
Figure 1: Overview of the pipeline for constructing a relational image similarity model leveraging image filtering, anonymous group-based captioning, and contrastive vision-LLM training.
While attribute similarity is easily framed via low- (pixels), mid- (features), or high-level (concepts/classes) signal matching, relational similarity requires comparing the relations among visual elements. The authors identify that existing datasets are fundamentally limited in this regard: BAPPS and ImageNet, for example, only support attribute correspondence.
To address this, the pipeline begins with large-scale filtering of LAION-2B. A VLM (Qwen2.5-VL-7B) is fine-tuned on human-labeled data to select “relationally interesting” images—those with compositional or analogical structures. This process surfaces roughly 114k images, which are then further curated.

Figure 2: Examples contrasting images deemed relationally interesting (complex internal structure) versus ordinary (surface-level attributes).
Crucially, the relational structure is not directly annotated at the image level but is instead revealed via anonymous group-based captioning. Manually curated groups of images (532 groups, 2-10 images/group) are used to elicit the shared underlying logic (i.e., “growth process of {Subject} described in 4 stages”). VLMs generate and humans verify such group-based captions that avoid object-specific language, acting as abstraction anchors for the images.
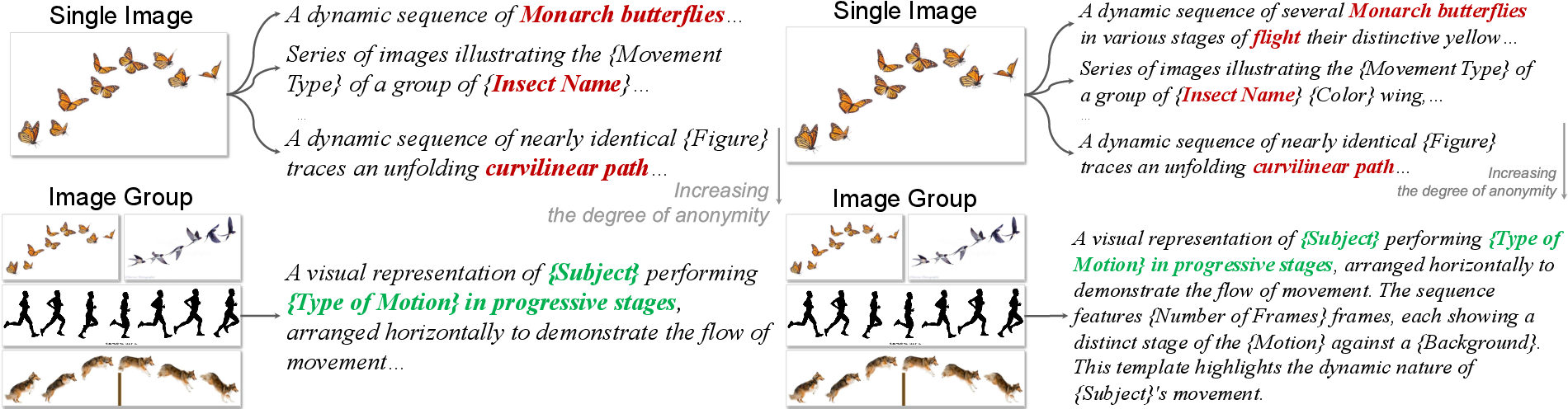
Figure 3: Demonstration that group context is necessary to reliably elicit anonymous relational captions that avoid overfitting to surface content.
Relational Visual Similarity Model
Given image–caption pairs {(Ii,Ai)}, the relational visual similarity (relsim) model is realized as a vision-language encoder (Qwen2.5-VL-7B for images, MiniLM for text), operating under an InfoNCE-style contrastive learning objective. Images are mapped close in feature space if and only if their anonymous (relational) captions are similar. The process discards surface-level alignment, rewarding logic-based correspondence.
This marks a methodological pivot: instead of leveraging vision-only backbones, the approach insists that relational reasoning is fundamentally dependent on language-based abstraction and world knowledge. By freezing text encoders and instructing the image encoder with logic-focused prompts, the model is explicitly disentangled from attribute similarity bias.
Empirical Analysis
Evaluation Protocol
Evaluation is performed in the context of image retrieval: given a query, retrieve its most relationally similar instance from a mixed real-world database. Baselines include LPIPS, CLIP (image and text), DINO, and caption-driven retrieval via CLIP-T and Qwen-T; these span the spectrum from low-level to semantic similarity and include both direct and language-proxy approaches. Notably, caption baselines operate by independently describing images with Qwen-generated anonymous captions, highlighting the necessity of group-driven abstraction.
Automated judgments are performed via GPT-4o, which is instructed to focus exclusively on analogical/relational logic, ignoring raw perceptual and semantic similarity.
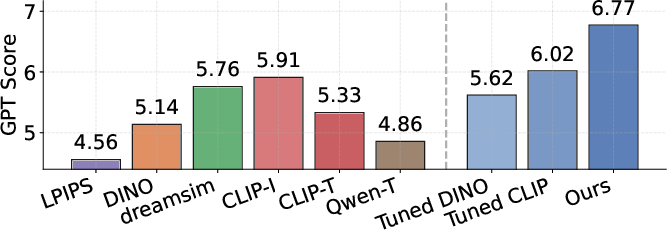
Figure 4: Quantitative comparison of retrieval metrics — relsim outperforms all established baselines at relational similarity matching.
The main findings:
- Standard metrics fail: LPIPS (4.56) and DINO (5.14) underperform on relational similarity, validating that self-supervised and pixel/feature-level models lack analogical abstraction.
- Vision-language superiority: CLIP-I (5.91) is stronger due to richer semantics, but remains attribute-dominated. Only the relsim VLM (6.77) meaningfully encodes relational logic.
- Group-based captioning is critical: Captioning from a single image (CLIP-T, Qwen-T) is insufficient, inadvertently leaking attribute content.
- Vision-only finetuning is not enough: Even finetuned DINO/CLIP on the relational dataset cannot match VLM-based relsim, emphasizing the unique role of language.
Human Alignment
A/B user studies comparing relsim with each baseline confirm that humans robustly prefer the relsim-driven retrievals (42.5–60.7% preference rates), and that relational similarity is both perceived and operationalized distinct from attribute-based judgments.
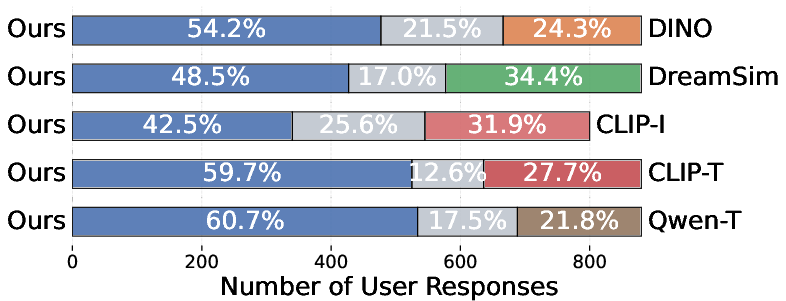
Figure 5: AB test user study: relsim achieves significantly higher preference rates than all attribute-based or one-image captioning baselines.
Relational and Attribute Similarity as Complementary Signals
Visualization of the similarity space demonstrates that relational similarity and attribute similarity span orthogonal axes. Their combination yields the richest assessments, enabling discovery of logical matches regardless of attribute coincidence.

Figure 6: Two-dimensional visualization shows that relational and attribute similarity partition the space in qualitatively distinct ways.
Qualitative Retrieval and Generation
By constructing a similarity search space, the authors illustrate that relsim can retrieve analogically related images that are maximally dissimilar at the pixel or class level.

Figure 7: Given a query, relsim retrieves images matching its underlying logic rather than surface appearance — enabling logic-driven search.
For generative tasks, relsim provides a direct handle for analogical image generation: unlike normal editing, which enforces attribute transfers, relsim can guide VLMs or diffusion models to map or generate images that share conceptual structure with a provided prompt.

Figure 8: “Analogical image generation” — relsim enables generation that preserves logic/structure rather than superficial attributes.
Quantitative benchmarks evidence a performance gap: proprietary models (GPT-4o-image, Gemini 2.5) better support analogical generation over open-source VLMs, but the upper bound is defined by relsim rather than CLIP or LPIPS.

Figure 9: Proprietary models show improved ability for complex relational transformations, yet open-source models lack in analogical generation.
Theoretical and Practical Implications
Theoretical Implications: By formalizing relational visual similarity, the paper exposes an axis of abstraction critical for human-like perception and analogy. This challenges the attribute-dominated paradigm and suggests that next-generation models must fundamentally encode relations and logic, ideally through language–vision synergy.
Practical Implications: Applications include retrieval (finding images matching not by class but by conceptual logic), analogical editing and idea generation, creative image composition, and richer evaluation benchmarks for generative models. Notably, the relsim metric can diagnose and drive improvements in open-source VLMs, which currently lag in analogical reasoning.
Limitations and Future Directions
The main constraint of the current approach is scalability: anonymous captioning depends on manually curated groups and VLM-derived captions, which may encode biases or omit relevant but subtle logics. Additionally, each image can support multiple relational structures; handling user intent and structure selection is yet unsolved. Automating the expansion and annotation of relational logics is necessary for broader adoption.
Conclusion
By proposing relsim and a scalable pipeline for capturing relational visual similarity, this work fundamentally extends the operational definition of image similarity in computer vision. The results establish robust empirical evidence that attribute and relational similarity are distinct and complementary, demand vision-language modeling, and directly support human-aligned analogical reasoning. Future developments likely include large-scale relational benchmarking, improved analogical generation, and unified joint modeling of attribute and relational similarity dimensions.