Voxify3D: Pixel Art Meets Volumetric Rendering
Abstract: Voxel art is a distinctive stylization widely used in games and digital media, yet automated generation from 3D meshes remains challenging due to conflicting requirements of geometric abstraction, semantic preservation, and discrete color coherence. Existing methods either over-simplify geometry or fail to achieve the pixel-precise, palette-constrained aesthetics of voxel art. We introduce Voxify3D, a differentiable two-stage framework bridging 3D mesh optimization with 2D pixel art supervision. Our core innovation lies in the synergistic integration of three components: (1) orthographic pixel art supervision that eliminates perspective distortion for precise voxel-pixel alignment; (2) patch-based CLIP alignment that preserves semantics across discretization levels; (3) palette-constrained Gumbel-Softmax quantization enabling differentiable optimization over discrete color spaces with controllable palette strategies. This integration addresses fundamental challenges: semantic preservation under extreme discretization, pixel-art aesthetics through volumetric rendering, and end-to-end discrete optimization. Experiments show superior performance (37.12 CLIP-IQA, 77.90\% user preference) across diverse characters and controllable abstraction (2-8 colors, 20x-50x resolutions). Project page: https://yichuanh.github.io/Voxify-3D/














Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Voxify3D, a new way to turn regular 3D models (called meshes) into “voxel art,” which looks like it’s built from tiny cubes—think Minecraft. The goal is to make the 3D model look stylish and blocky while still keeping important details (like eyes, ears, buttons) and using only a small set of colors, just like classic pixel art.
Key Questions the Paper Tries to Answer
The authors focus on three big problems that make automatic voxel art hard:
- How can we line up 2D pixels with 3D cubes so the result isn’t blurry or messy?
- How can we keep important features (like faces and shapes) even when we use fewer cubes and fewer colors?
- How can we train an AI to use a limited color palette (like 2–8 colors) while still learning smoothly?
How the Method Works (Simple Explanation)
Think of the method as a two-step process that teaches a 3D model to “dress up” like voxel art.
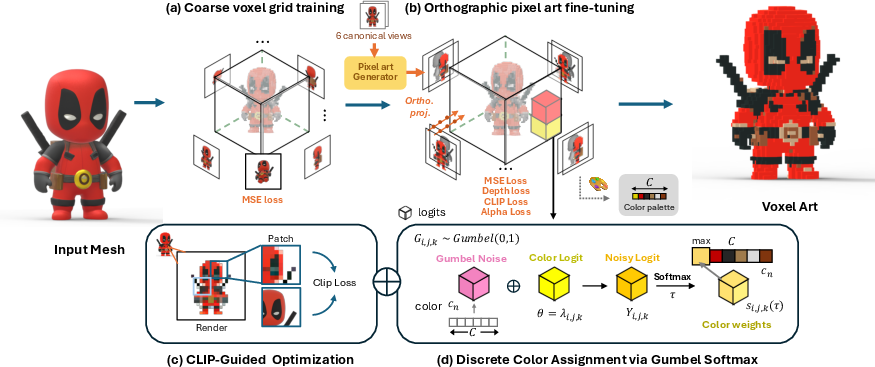
- First, a coarse training step builds a basic cube-based version of the model:
- The model is turned into a 3D grid of tiny cubes (voxels).
- Using a technique called volumetric rendering (imagine shining light through stacked transparent layers to see color and depth), it learns rough color and shape.
- Then, a fine-tuning step polishes the look using pixel art rules:
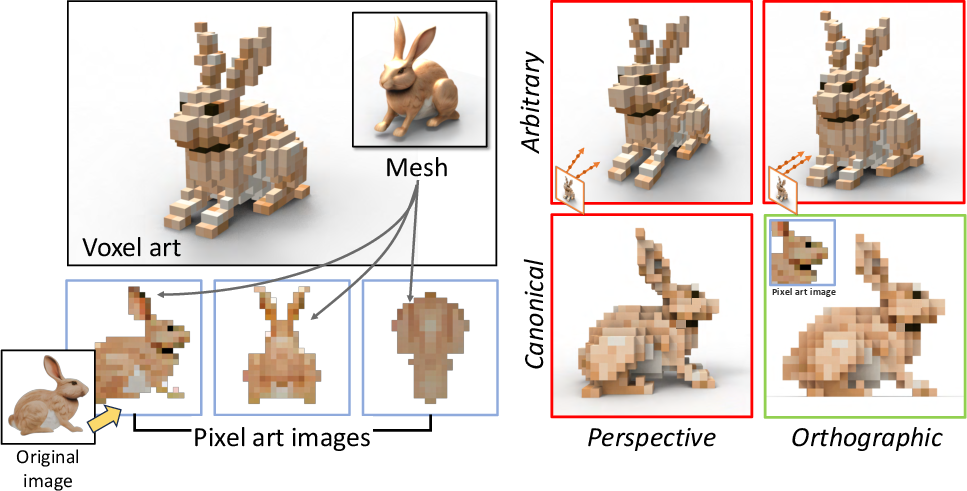
- It uses six “orthographic” views (front, back, left, right, top, bottom). Orthographic means all lines are parallel—like a blueprint—so pixels line up perfectly with cubes. This avoids camera distortion (perspective), which would make edges misalign and look blurry.
- It compares these views to pixel-art versions of the model to guide the style and edges.
- It adds a “depth” check to make sure the blocky shape still matches the original 3D structure.
- It uses CLIP, an AI that understands images and meaning, but focuses on small patches. This helps the method keep local details (like eyes or patterns) even when the overall image is simplified.
- Finally, it limits colors using a fixed palette. Instead of guessing any color, each cube must pick a color from a small “crayon box.” A trick called Gumbel-Softmax lets the AI choose from these discrete colors while still being trainable. Early on it “softly” considers several colors; later, it settles on exact choices.
Extra controls:
- You can choose the number of colors (like 2, 4, or 8) and how the palette is made (methods like K-means or Median Cut—these just group similar colors).
- You can adjust resolution (how many cubes across, like 20×, 30×, 50×), which balances detail and blockiness.
Main Results and Why They Matter
- The method produces cleaner, more stylish voxel art than other approaches (like simple downsampling, procedural tools in Blender, or text-guided 3D stylization), especially keeping key features.
- It scores highest on CLIP-IQA (a measure of how well images match a descriptive prompt): 37.12 on average across 35 examples.
- In a user study with 72 people, Voxify3D was preferred most of the time:
- 77.90% for best abstract detail
- 80.36% for overall appeal
- 96.55% for keeping the original geometry
- Ablation tests (turning components off) show each part matters. Without orthographic views, pixel-art supervision, CLIP patches, or Gumbel-Softmax, the results get blurrier, less clear, or lose meaningful features.
- You get strong creative control: change the number of colors or the resolution to get more minimal or more detailed styles.
Why this is important:
- It bridges the gap between 2D pixel art rules and 3D voxel style, making the blocky look precise and meaningful.
- It gives artists and game developers an easy way to create consistent voxel assets without hand-tuning every detail.
What This Could Lead To
- Game assets: Fast, consistent voxel characters and objects that look great and keep their identity.
- Design and fabrication: The paper even shows LEGO-style renders, hinting at physical builds with limited color sets.
- Education and tools: A clearer path to teaching AI how to work with discrete palettes and blocky styles.
- Future improvements: The authors note thin parts and very fine details can be lost at low resolutions; future work could add special rules or geometry tricks to handle these better.
Overall, Voxify3D makes it much easier to turn complex 3D models into stylish, blocky voxel art that still looks like the original, all while using a small, controlled set of colors.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances mesh-to-voxel-art generation but leaves several aspects underexplored. Below is a concrete list of gaps and open questions that can guide future research:
- Multi-view pixel art consistency: The six-view pixel art supervision is generated per view with a 2D pixelizer, which may produce cross-view inconsistencies. How can a 3D-aware, multi-view-consistent pixelization model be designed to ensure coherent stylization across all views?
- Discrete geometry quantization: The method discretizes colors via Gumbel-Softmax but keeps geometry as continuous density. How can occupancy be quantized to a truly discrete voxel grid (e.g., via straight-through estimators for binary occupancy or differentiable binarization) without losing thin structures?
- Adaptive resolution and voxel sizing: Voxel resolution and cell size are fixed per object. Can saliency-aware or anisotropic voxel grids dynamically adjust resolution (e.g., higher resolution around faces/hands) to preserve thin features under strict palette constraints?
- Palette learning vs. extraction: Palettes are pre-extracted (K-means, Max-Min, Median Cut, SA), not learned. Can palettes be optimized end-to-end (with differentiable palette colors and counts) under constraints like color harmony, style references, or real-world inventories (e.g., LEGO/Minecraft)?
- Spatially varying palettes: A single global palette may underfit objects with heterogeneous regions (skin, cloth, metal). How to introduce region- or part-specific palettes that remain globally coherent and avoid color bleeding at boundaries?
- Dithering and patterning: Pixel/voxel art often relies on dithering and patterns to suggest shading with limited colors. How can controllable, view- and face-aware dithering/pattern priors be integrated into voxel surfaces while maintaining semantic clarity?
- Lighting and shading robustness: Palette extraction from rendered images is sensitive to lighting. How to obtain lighting-invariant palettes (e.g., via intrinsic decomposition or flat-shading canonicalization) and ensure consistent colors under varying illumination?
- View planning and coverage: Six axis-aligned orthographic views may miss slanted or occluded features. Can adaptive view planning (e.g., principal-axis alignment, more views, importance sampling) improve coverage of salient details?
- Canonicalization and orientation: The pipeline assumes axis-aligned canonical views. How can automatic canonicalization (e.g., PCA or learned orientation) be used to align meshes for optimal pixel–voxel correspondence?
- Patch-based CLIP semantics: CLIP patch size (fixed 80×80) and sampling strategy are not adapted to object scale or feature saliency. Can adaptive patching (based on learned saliency or part segmentation) improve semantic preservation at extreme discretization?
- CLIP domain fit and alternatives: CLIP was trained on natural images, not voxel art. Would domain-specific encoders (e.g., DINOv2 fine-tuned on pixel/voxel art) or multi-modal supervision (text + exemplar voxel art) reduce semantic drift and improve stylization fidelity?
- Evaluation metrics for voxel art: Beyond CLIP-IQA and user studies, there is no metric for palette adherence, edge sharpness, voxel–pixel alignment, or multi-view consistency. Can standardized quantitative metrics for voxel-art aesthetics be established?
- Scalability and efficiency: Experiments focus on relatively modest voxel resolutions (20×–50×). What are the memory, speed, and quality trade-offs at larger grids (e.g., 256³–1024³), and can sparse voxel structures or hierarchical grids be integrated to scale?
- Robustness to mesh quality: The method assumes clean meshes. How does it handle noisy, non-manifold, hollow, or texture-heavy meshes, and can pre-processing or learned priors mitigate artifacts?
- Scene-level and multi-object cases: Experiments target single assets. How does the method extend to multi-object scenes with backgrounds, occlusions, and interactions, including palette management across objects?
- Material and shading models: Colors are treated as albedo-like values without material properties. Can simple PBR-aware stylization (flat/specular toggles, ambient occlusion-aware coloring) be introduced without violating voxel-art aesthetics?
- Automatic selection of palette size: Color count (2–8) is user-chosen. Can the model automatically pick palette size to maximize semantic fidelity under constraints (e.g., budget, fabrication limits), possibly via discrete model selection?
- Temporal consistency for animation: The pipeline is frame-agnostic. How can temporal constraints be added to ensure consistent voxel stylization across animations or pose sequences?
- Training schedule sensitivity: The final 2,000 iterations emphasize the front view, which may bias artifacts. What is the impact of different view-emphasis schedules, temperature annealing curves, and loss weightings, and can these be auto-tuned?
- Export and interoperability: Practical pipelines to export voxel grids to common game engines or voxel editors (with format, LODs, and per-face colors) are not described. What conversion tools and standards are needed for deployment?
- LEGO/physical fabrication: The LEGO application is demonstrated only as renders. How can assembly-aware optimization (brick inventory constraints, connection stability, stress and overhangs) be made differentiable and integrated into voxel selection?
- Handling thin and intricate structures: The paper notes loss of fine details at low resolution. Can topology-aware regularizers, skeleton-preserving constraints, or anisotropic occupancy priors better protect thin parts?
- Per-face color assignment: Each voxel is a single color; in practice, faces may need distinct colors to improve silhouette and feature contrast. How can per-face palette assignments be learned while keeping coherence?
- Dataset breadth and benchmarks: Evaluation focuses on characters, with limited quantitative analysis on non-character categories (architecture, vehicles) or complex topologies. Can broader, standardized benchmarks for mesh-to-voxel-art be built?
- Comparisons to palette-based neural fields: Methods like PaletteNeRF/color-decomposition approaches are cited but not compared. How does Voxify3D perform against palette-aware 3D baselines under identical conditions?
- Reproducibility and assets: The paper references a project page, but clarity on code, trained models, and curated mesh/pixel-art pairs is limited. Establishing open datasets of meshes with artist-created voxel-art ground truth would facilitate benchmarking.
- Semi-transparency and effects: Voxel art sometimes employs transparency or emissive effects. How can the pipeline handle discrete transparency/emission palettes and prevent artifacts in volumetric rendering?
- Interior geometry and cavities: Orthographic supervision focuses on exterior surfaces. What strategies (e.g., ray sampling into interiors, cross-sections) can ensure correct stylization for hollow or concave objects?
Practical Applications
Immediate Applications
The method transforms existing 3D meshes into palette‑constrained voxel art with controllable abstraction. Below are deployable use cases, mapped to sectors, with potential tools/workflows and feasibility notes.
- Gaming and Digital Media (asset production and optimization)
- Use cases: Batch convert high‑poly characters/props into voxel art for Minecraft‑like games, retro/low‑poly titles, trailers, and marketing art; create consistent stylized Level‑of‑Detail (LOD) variants with 2–8 color palettes for memory/bandwidth savings; produce voxel impostors for distant rendering.
- Potential tools/products/workflows: Blender/Houdini plug‑in wrapping Voxify3D; Unity/Unreal importers that export .vox/.glTF with a palette and occupancy grid; CLI to process asset libraries; palette editor that swaps K‑means/Median‑Cut palettes and counts (2–8 colors); automated LOD batch jobs.
- Assumptions/dependencies: Access to original meshes and usage rights; GPU for training (two‑stage DVGO + fine‑tuning); CLIP and pixel‑art generator model availability/licensing; method tuned for 20×–50× voxel grids and small palettes (2–8 colors), so very fine detail may be lost.
- AR/VR and Mobile (bandwidth‑friendly stylized assets)
- Use cases: Precompute voxelized avatars/props with discrete palettes to minimize texture variety and memory footprint in mobile AR apps; consistent brand palettes across assets.
- Potential tools/products/workflows: Offline batch conversion pipeline; glTF/Draco compressed voxel grids; WebGL viewer for voxel models; palette‑locked texture atlases for engine integration.
- Assumptions/dependencies: Offline preprocessing acceptable (not real‑time); mobile runtime shaders for voxel rendering or mesh proxy generation; quality depends on suitable voxel resolution.
- Toy, Maker, and 3D Printing (concepting and fabrication prep)
- Use cases: Generate LEGO‑style concept renders and printable voxel figurines with limited color channels; prepare occupancy grids for multi‑material 3D printers (mapping palette to printer materials).
- Potential tools/products/workflows: Export voxel occupancy + palette; slicer profiles mapping colors to filaments/resins; render pipelines (e.g., KeyShot) for sales/marketing visuals; early feasibility checks for brick‑based designs.
- Assumptions/dependencies: Physical assembly planning (brick layout, connectivity, stability) is out of scope and requires separate tools; for multi‑material prints, printer/material availability and color matching are needed.
- Education (graphics, vision, and art curricula)
- Use cases: Teaching modules on orthographic rendering, volumetric rendering, CLIP‑based semantic losses, and Gumbel‑Softmax quantization; exercises on abstraction and palette design.
- Potential tools/products/workflows: Jupyter notebooks reproducing two‑stage training; classroom demos converting campus models to voxel art; open‑source tutorial assets.
- Assumptions/dependencies: Access to GPUs in labs; model weights/licenses for CLIP and pixel‑art generator; simplified datasets for fast runs.
- Creative Platforms and UGC (creator tools and marketplaces)
- Use cases: “Upload mesh → get voxel art” web service for avatars, collectibles, and shop thumbnails; consistent palette sets for branding; easy re‑coloring via palette swaps.
- Potential tools/products/workflows: Web API/microservice with job queue; palette‑editing UI; WebGL preview; batch conversion for partner studios.
- Assumptions/dependencies: Server‑side GPU capacity; content moderation and IP rights management; latency tolerance for per‑asset processing.
- Research and Benchmarking (academia and R&D)
- Use cases: Benchmarking semantic preservation under discretization; evaluating differentiable palette quantization at varying voxel sizes and palette counts; ablation studies on orthographic vs. perspective supervision.
- Potential tools/products/workflows: Release of training scripts, CLIP‑IQA evaluation, and reference palettes; reproducible experimental configs.
- Assumptions/dependencies: Dataset licensing; reproducibility requirements (fixed seeds, versions); continued availability of referenced models.
- Branding and Marketing (visual identity and stylization)
- Use cases: Rapid creation of on‑brand voxel iconography and mascots with fixed palettes; social media content and ads aligned to retro aesthetics.
- Potential tools/products/workflows: Design team pipeline with palette libraries; automated exports for social formats.
- Assumptions/dependencies: Palette and resolution selected to preserve key brand features; designer oversight for final selection.
- Personal/Daily Use (custom avatars and gifts)
- Use cases: Voxelized profile pics, desk toys, and keepsakes derived from personal 3D scans or creator meshes; color‑limited 3D prints for home printers.
- Potential tools/products/workflows: Desktop app or plug‑in; consumer‑grade slicer integration with color mapping.
- Assumptions/dependencies: User has a mesh or 3D scan; basic familiarity with printing or service providers.
Long-Term Applications
These opportunities require further research, engineering, or ecosystem development before broad deployment.
- Real‑Time or Near‑Real‑Time In‑Engine Voxelization (software, gaming, AR/VR)
- Use cases: On‑the‑fly stylization effects (e.g., “voxelize this enemy on hit”); dynamic LOD conversion with palette adherence; interactive palette swapping during gameplay.
- Potential tools/products/workflows: Lightweight neural modules or distillation to fast networks; GPU kernels for orthographic alignment in real time.
- Assumptions/dependencies: Significant optimization or model compression; addressing training‑time CLIP and Gumbel‑Softmax overhead; quality trade‑offs.
- Prompt‑to‑Voxel Asset Creation (content generation pipelines)
- Use cases: Single‑step text‑to‑voxel asset creation by chaining mesh generation and Voxify3D stylization; mass asset bootstrapping for new titles or UGC platforms.
- Potential tools/products/workflows: Integrations with text‑to‑3D (e.g., diffusion‑based mesh generation) followed by palette‑constrained voxelization; automated validation with CLIP‑IQA.
- Assumptions/dependencies: Robust mesh generation with clean topology; end‑to‑end alignment of semantics through discretization; compute costs.
- Fully Automated LEGO/Brick Assembly Planning (manufacturing/toys/robotics)
- Use cases: Convert voxel outputs into feasible, buildable brick layouts with connection strength, stability, and cost optimization; generate step‑by‑step instructions; robot‑assisted assembly.
- Potential tools/products/workflows: Brick decomposition solvers respecting palette, gravity, clutch power, and inventory; BOM generation; integration with BrickLink/Studio; robotic path planning.
- Assumptions/dependencies: Advanced combinatorial solvers; material and connection models; standards for instruction generation; safety constraints.
- Progressive Streaming and Cloud Gaming Assets (software, networks)
- Use cases: Stream voxel representations progressively (coarse→fine, 2→8 colors) to reduce startup bandwidth; palette‑aware compression for consistent visual identity.
- Potential tools/products/workflows: New streaming codecs for voxel grids and palettes; edge servers performing on‑the‑fly palette edits.
- Assumptions/dependencies: Client runtimes that render voxel assets; standardization across engines; QoS requirements.
- Domain‑Specific Simplification and Communication (education, scientific visualization)
- Use cases: Massing studies in architecture; simplified anatomical/engineering models for instruction; science communication with stylized voxel forms.
- Potential tools/products/workflows: Domain‑tuned palette templates and abstraction levels; instructors choose palettes to emphasize structures.
- Assumptions/dependencies: Validation that simplification preserves critical semantics; specialized palette guidance per domain.
- Accessible and Inclusive Design Systems (policy, HCI, product design)
- Use cases: Palette‑constrained assets tailored for color‑vision deficiencies; standards for color contrast and legibility in stylized assets; compliance guidance for retro‑style UIs.
- Potential tools/products/workflows: Accessibility checkers tied to palette choices; policy documents for color‑safe voxel assets in public‑facing apps.
- Assumptions/dependencies: Research validating accessibility benefits in 3D stylization; alignment with WCAG‑like criteria extended to 3D.
- Automated QA and Moderation for Stylized Assets (platform operations)
- Use cases: Check that UGC voxel assets meet palette limits, semantic fidelity, or brand rules; detect IP or content violations with CLIP‑based cues before publishing.
- Potential tools/products/workflows: CLIP‑IQA thresholds; palette compliance validators; automated report generation.
- Assumptions/dependencies: False positive/negative management; human review loops; policy alignment and legal constraints.
- Cross‑Modal Training and New Benchmarks (academia, R&D)
- Use cases: New datasets and tasks on “semantic preservation under extreme discretization” across views; studies on differentiable discrete optimization in 3D; orthographic vs. perspective supervision benchmarks.
- Potential tools/products/workflows: Shared leaderboards; standardized six‑view orthographic protocols; open palettes and reference meshes.
- Assumptions/dependencies: Community adoption; reproducible baselines; compute funding.
- Sustainable Content Pipelines (policy, sustainability)
- Use cases: Evaluate whether palette‑constrained voxel assets reduce storage, bandwidth, and energy consumption in distribution; inform green guidelines for asset pipelines.
- Potential tools/products/workflows: Measurement frameworks comparing voxel vs. photoreal pipelines; best‑practice documents for studios.
- Assumptions/dependencies: Empirical studies of end‑to‑end impact; industry participation for data sharing.
Notes on Global Dependencies and Assumptions
- Technical: Availability of CLIP and the pixel‑art supervision model; GPU compute for training; scalability to large asset libraries; performance of Gumbel‑Softmax schedules in varied content.
- Content: Access to high‑quality meshes and rights to process/redistribute them; acceptance of abstraction limits (20×–50× grids, 2–8 colors).
- Integration: Engine/toolchain support for voxel rendering or mesh proxies; exporters/importers (.vox, .glTF); UI for palette control and QA.
- Quality constraints: Thin structures and intricate details may require higher voxel resolutions or future geometric priors; orthographic six‑view supervision can miss deep concavities without additional view strategies.
Glossary
- Accumulated transmittance: In volume rendering, the cumulative probability that a ray has not been absorbed up to a given sample along its path. Example: "where is the number of samples along the ray, the density, the distance between consecutive samples, the accumulated transmittance, and the opacity at sample ."
- Alpha channel: An image channel encoding pixel transparency, often used as a mask. Example: "where is a binary mask from the pixel art alpha channel (1 for background),"
- Alpha loss: A loss term encouraging transparency in background regions to avoid spurious density. Example: "We also use an alpha loss to suppress density in background regions, enforcing background transparency to avoid floating density artifacts:"
- Axis-aligned views: Camera views aligned with the principal axes, used for consistent orthographic supervision. Example: "rendering orthographic projections from six axis-aligned views"
- CLIP-IQA: A CLIP-based image quality assessment metric measuring semantic alignment with text prompts. Example: "We adopt the CLIP-IQA framework."
- CLIP loss: A perceptual loss using CLIP embeddings to enforce semantic alignment between rendered outputs and references. Example: "A CLIP loss computed over rendered patches and mesh images encourages semantic alignment while being memory-efficient."
- Cosine similarity: A similarity measure between two vectors (e.g., CLIP embeddings) based on the cosine of the angle between them. Example: "and compute a perceptual loss via cosine similarity:"
- Density grid: A voxel grid storing volumetric densities that govern occupancy and opacity in volume rendering. Example: "DVGO directly optimizes two explicit voxel grids: a density grid for spatial occupancy and a color grid for appearance."
- Discretization: The process of representing continuous signals (geometry/colors) with a limited set of discrete elements, such as voxels or palette colors. Example: "patch-based CLIP alignment that preserves semantics across discretization levels;"
- DVGO: Direct Voxel Grid Optimization, an explicit voxel-based radiance field formulation for fast training and rendering. Example: "Stage~1 (Sec.~\ref{sec:stage_1}) builds a coarse voxel radiance field using DVGO~\citep{sun2022direct} to establish geometric and color foundations."
- Entropy loss: A regularization term that encourages confident (low-entropy) predictions, here used to reduce background artifacts. Example: "and uses entropy loss to maintain clear geometry and reduce background artifacts."
- Gumbel noise: Noise sampled from the Gumbel distribution to enable differentiable sampling over categorical choices. Example: "Gumbel noise is added to produce noisy logits:"
- Gumbel-Softmax: A reparameterization trick enabling differentiable sampling from categorical distributions, used here for palette selection. Example: "Gumbel-Softmax enables differentiable sampling for end-to-end color optimization, yielding coherent, stylized voxel art."
- Logit: The unnormalized score or input to a softmax used to produce categorical probabilities. Example: "each voxel stores a color logit vector "
- Max-Min (palette selection): A palette extraction strategy selecting colors by maximizing minimum distances to previously chosen colors. Example: "Each row corresponds to a different palette extraction method: K-means, Max-Min, Median Cut, and Simulated Annealing."
- Median Cut (palette extraction): A color quantization algorithm that recursively partitions the color space to build a representative palette. Example: "Each row corresponds to a different palette extraction method: K-means, Max-Min, Median Cut, and Simulated Annealing."
- Mesh-projected depth: The depth values obtained by projecting a 3D mesh onto the image plane, used as supervision. Example: "and $D_{\text{gt}$ is the mesh-projected depth."
- Opacity: The per-sample or accumulated measure of how much light is blocked along a ray in volume rendering. Example: "and the opacity at sample ."
- Orthographic pixel art supervision: Using orthographic renders of pixel art to supervise 3D optimization, ensuring pixel-voxel alignment. Example: "orthographic pixel art supervision that eliminates perspective distortion for precise voxel-pixel alignment;"
- Orthographic projection: A projection method with parallel rays, removing perspective distortion. Example: "Orthographic projection serves specialized domains: aerial orthophotos~\cite{yue2025nerfortho, chen2025ortho}, CAD reconstruction~\cite{zhou2025gaussiancad}, and furniture assembly~\cite{hu2023plankassembly}."
- Orthographic rendering: Rendering with parallel rays rather than perspective, used to align pixels and voxels. Example: "six-view orthographic rendering that eliminates perspective distortion for precise alignment;"
- Palette-constrained quantization: Restricting colors to a small, discrete palette during optimization to achieve a stylized look. Example: "palette-constrained Gumbel-Softmax quantization enabling differentiable optimization over discrete color spaces with controllable palette strategies."
- Patch-based CLIP alignment: Applying CLIP guidance on local image patches to preserve semantics at low resolutions. Example: "patch-based CLIP alignment that preserves semantics across discretization levels;"
- Ray casting: Tracing rays through a volume to compute accumulated color and opacity. Example: "parallel ray casting "
- Semantic collapse: Loss of critical semantic features when aggressively discretizing or downsampling representations. Example: "addressing semantic collapse that standard perceptual losses fail to prevent."
- Straight-through variant: A training trick where discrete choices are used in the forward pass while gradients flow through a soft relaxation. Example: "Later, we switch to the straight-through variant, where the forward pass uses a one-hot selection at , while gradients are backpropagated through the soft weights."
- Temperature annealing: Gradually lowering the softmax temperature during training to move from soft to hard categorical selections. Example: "We anneal the temperature during training to encourage smooth exploration in the early stages and sharper, more discrete selections later."
- Total variation (TV) regularization: A regularizer promoting spatial smoothness by penalizing large gradients in the voxel grid. Example: "and employs total variation (TV) regularization to enforce spatial smoothness,"
- Volumetric rendering: Rendering technique that integrates color and opacity along rays through a volume. Example: "computed via volumetric rendering (\cref{eq:vol_render})."
- Voxel-based radiance field: A radiance field represented on a voxel grid for explicit, efficient rendering and optimization. Example: "(a) Coarse voxel grid training: Given a 3D mesh, we render multi-view images and optimize a voxel-based radiance field (DVGO~\citep{sun2022direct}) using MSE loss to learn coarse RGB and density."
Collections
Sign up for free to add this paper to one or more collections.