LUNA: Linear Universal Neural Attention with Generalization Guarantees
Published 8 Dec 2025 in cs.LG and stat.ML | (2512.08061v1)
Abstract: Scaling attention faces a critical bottleneck: the $\mathcal{O}(n2)$ quadratic computational cost of softmax attention, which limits its application in long-sequence domains. While linear attention mechanisms reduce this cost to $\mathcal{O}(n)$, they typically rely on fixed random feature maps, such as random Fourier features or hand-crafted functions. This reliance on static, data-agnostic kernels creates a fundamental trade-off, forcing practitioners to sacrifice significant model accuracy for computational efficiency. We introduce \textsc{LUNA}, a kernelized linear attention mechanism that eliminates this trade-off, retaining linear cost while matching and surpassing the accuracy of quadratic attention. \textsc{LUNA} is built on the key insight that the kernel feature map itself should be learned rather than fixed a priori. By parameterizing the kernel, \textsc{LUNA} learns a feature basis tailored to the specific data and task, overcoming the expressive limitations of fixed-feature methods. \textsc{Luna} implements this with a learnable feature map that induces a positive-definite kernel and admits a streaming form, yielding linear time and memory scaling in the sequence length. Empirical evaluations validate our approach across diverse settings. On the Long Range Arena (LRA), \textsc{Luna} achieves state-of-the-art average accuracy among efficient Transformers under compute parity, using the same parameter count, training steps, and approximate FLOPs. \textsc{Luna} also excels at post-hoc conversion: replacing softmax in fine-tuned BERT and ViT-B/16 checkpoints and briefly fine-tuning recovers most of the original performance, substantially outperforming fixed linearizations.
The paper presents fully learnable kernel mappings that replace fixed random features in linear attention, eliminating the efficiency–expressivity trade-off.
It achieves state-of-the-art performance on long-range tasks like LRA, with a 65.44% average accuracy and notable gains in image and text understanding.
The work provides universal approximation guarantees with explicit error bounds while supporting streaming linear computation and post-hoc model conversion.
LUNA: Linear Universal Neural Attention with Generalization Guarantees
Motivation and Problem Formulation
Transformers have proven central to high-performing models in NLP, vision, multimodal, and scientific domains via their attention mechanism, but scaling attention remains computationally expensive due to the quadratic complexity in sequence length n. Linear attention variants reduce this cost, but traditionally rely on fixed or randomly-sampled feature maps (e.g., RFF, Performer), leading to a strict trade-off between efficiency and model expressivity. These static, data-independent feature maps constrain the kernel class, limiting the ability to optimally adapt attention to diverse tasks and modalities.
LUNA addresses this by introducing a fully learnable kernel architecture for attention. By endowing the kernel feature map itself with learnable parameters—input projections and channel-wise non-linear transformations—LUNA admits a parameterization that can discover inductive biases specific to each task while guaranteeing positive definiteness and efficiently supporting streaming/linear complexity computation.
Theoretical Framework
LUNA begins by kernelizing the standard dot-product attention. Traditional linearization approximates the exponential softmax kernel with a Monte Carlo average over random features (Bochner's theorem), employing sinusoidal or exponential features applied to random projections of the input. LUNA generalizes this in two critical aspects:
Learnable Projections and Nonlinearities: Instead of using fixed projections and nonlinearities, LUNA parameterizes both via neural modules—a matrix of learned projections W and a bank of channel-specific MLPsψℓ. Together, these induce a vector-valued, data-dependent kernel map ϕ(x;W,ψ,h), which is positive-definite and supports linear streaming computation.
Universal Approximation with Controlled Error: The proposed feature map structure is proven to possess the universal approximation property, extending the classic UAT to kernel approximation. LUNA provides explicit convergence and generalization guarantees, decomposing approximation error into parameterization (neural network expressivity) and finite sampling (Monte Carlo variance) terms. Under standard assumptions, Rademacher complexity scales as O~(1/n), with explicit exponential concentration bounds in both bounded and sub-exponential (e.g., ReLU) activation cases.
Computational Efficiency
LUNA's runtime cost is dominated by:
Computing learned projections: linear in ndm for m projections.
Channel-wise nonlinearity application: O(nmL).
Sufficient-statistics calculation for streaming linear attention: O(nD2), with D=mL.
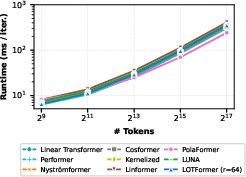
Despite the increased expressivity, empirical per-layer runtimes closely match those of vanilla linear attention, only marginally increasing compared to Performer or RFF due to efficient kernel computation, as depicted in the following runtime scaling analysis.
Figure 1: Per-layer runtime scaling of LUNA and linear attention baselines is linear in sequence length n; LUNA matches or slightly improves the runtime envelope while using data-adaptive, learnable kernels.
Empirical Results
Long Range Arena (LRA)
On the LRA benchmark, which measures long-context reasoning across various modalities, LUNA achieves new state-of-the-art results among efficient transformers:
LUNA delivers the highest average accuracy (65.44%), surpassing recent architecture-level advances (e.g., Performer, Skyformer, PolaFormer, LOTFormer), and achieves notable improvements on tasks such as Image (64.32%) and Text (73.41%), using comparable parameter counts and FLOPs as baselines.
Notably, the ablation analysis shows that learning both projections and channel nonlinearities is essential—fixed-feature variants (e.g., RFF) experience catastrophic drops in accuracy, while neural parameterization recovers and surpasses softmax-attention performance.
Figure 2: Visualization of learned ϕ channel responses in LUNA—the resultant learned nonlinearities diverge significantly from fixed basis functions, adapting to the data distribution (see layer-wise and task-wise specialization).
Post-hoc Conversion of Fine-tuned Transformers
LUNA supports a conversion pipeline that allows replacing softmax attention in already-trained models (e.g., BERT-base on GLUE, ViT-B/16 on ImageNet-1K) with LUNA attention, followed by brief task-specific fine-tuning:
On GLUE, LUNA recovers 99.5% of BERT-FT's original dev accuracy—better than Hedgehog, T2R, and exponential-feature conversions.
On ImageNet-1K, LUNA matches or slightly exceeds softmax ViT-B/16 accuracy despite using linear attention, a first for non-exponential learned kernelizations.
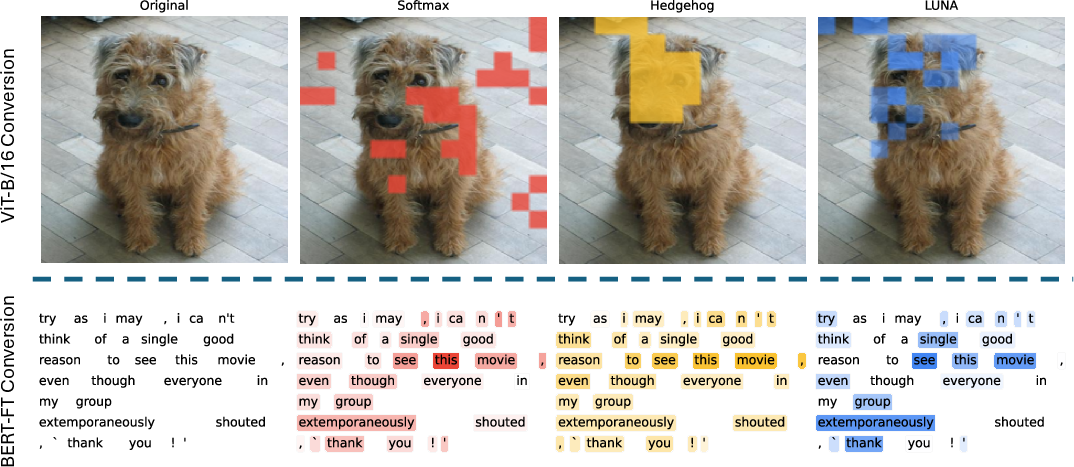
Qualitative visualization of the learned CLS attention shows that LUNA yields sharper, more semantically aligned highlights than other linear attention schemes, reflecting its ability to learn task-specific inductive biases.
Figure 3: CLS-based attention heatmaps for image (ViT) and text (BERT) tasks: LUNA localizes salient regions and sentiment spans more precisely than fixed-feature or exponential-feature baselines.
Ablation Studies
A systematic exploration of the projection count m and channels L reveals optimal performance at moderate values, with degradation for excessive expansion, underscoring the importance of balancing expressivity and over-parameterization. Furthermore, kernel ablation confirms that learnability (especially the removal of multiplicative gating) stabilizes training and enhances accuracies vis-à-vis hand-crafted features or basic additive banks.
Implementation and Practical Considerations
The LUNA feature map is modular, comprising parametrized projections (shared or per-channel), a bank of scalar MLPs per projection/channel pair, and simple integration with standard Q/K/V projections. The implementation is compatible with both random and learnable initializations and can be efficiently parallelized due to the chunked computation strategy for large token batches.
Implications and Future Directions
LUNA robustly demonstrates that linear attention mechanisms, unshackled from the bias of fixed kernel bases, can both approach and surpass the accuracy of full softmax attention—without incurring quadratic computation. Its universal approximation results, together with high-probability concentration bounds, provide a new theoretical foundation for efficient transformer architectures. The compositional kernel family parametrized by LUNA opens several avenues:
Task-adaptive, data-driven kernel search and meta-learning across domains.
Efficient deployment of transformers in memory- or time-constrained applications requiring long context, with minimal degradation in predictive power.
Deeper understanding and interpretability of learned self-attention via visualization of kernel basis specialization.
Potential further compression, regularization, and distillation strategies leveraging the smooth spectrum of kernel parameterization.
Conclusion
LUNA eliminates the core expressivity–efficiency dichotomy in linear attention by replacing static random or exponential features with a learnable, universal kernel-inspired architecture, while preserving positive-definite streaming forms and linear time complexity. This architectural leap yields state-of-the-art accuracies in long-range benchmarks and enables high-fidelity post-hoc conversion of pretrained transformers. The joint theoretical and empirical advances position LUNA as a viable default for efficient, high-capacity sequence modeling.