- The paper demonstrates that incorporating high-dimensional flow feedback significantly improves the learning performance of RL agents in chaotic fluid systems.
- Methodology includes using DreamerV3 on a tabletop water channel for drag maximization and minimization tasks, underscoring the impact of sensor feedback.
- Findings reveal that rich feedback is essential for policy discovery during training, while minimal feedback suffices for execution.
Using Reinforcement Learning to Probe the Role of Feedback in Skill Acquisition
Introduction
The paper "Using reinforcement learning to probe the role of feedback in skill acquisition" (2512.08463) offers a rigorous empirical and theoretical investigation into the dependence of skill acquisition on feedback modalities by directly leveraging generalist RL agents in physical, high-dimensional chaotic systems. Rather than employing human subjects, the study utilizes DreamerV3, a state-of-the-art model-based RL agent, to interact with a real-world spinning cylinder immersed in a turbulent flow. The experimental paradigm encompasses two canonical control tasks—drag maximization and drag minimization—allowing a systematic dissection of the informational prerequisites for both learning and execution of motor skills under varying feedback conditions.
Experimental Setup and Methodology
The experimental platform is a low-cost tabletop circulating water channel (CWC), depicted in Figure 1, housing an actuated cylindrical body whose rotation rate is directly controlled by the RL agent. Observations consist variably of drag force measurements, commanded and observed rotation rates, and optionally a high-dimensional flow field estimation computed in real time using particle image velocimetry (PIV). The dynamical environment is inherently infinite-dimensional, governed by the incompressible Navier–Stokes equations in a chaotic regime, rendering accurate simulation intractable and providing a compelling testbed for RL algorithms.

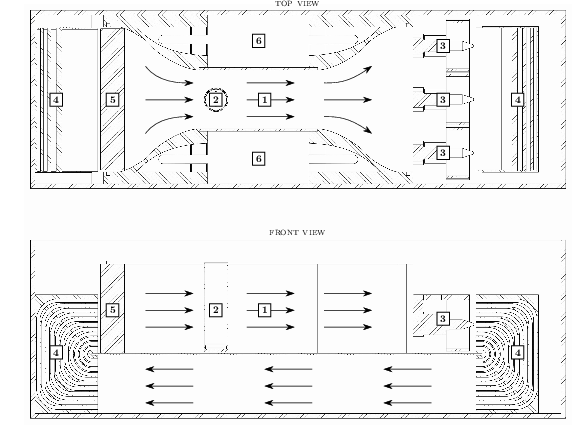
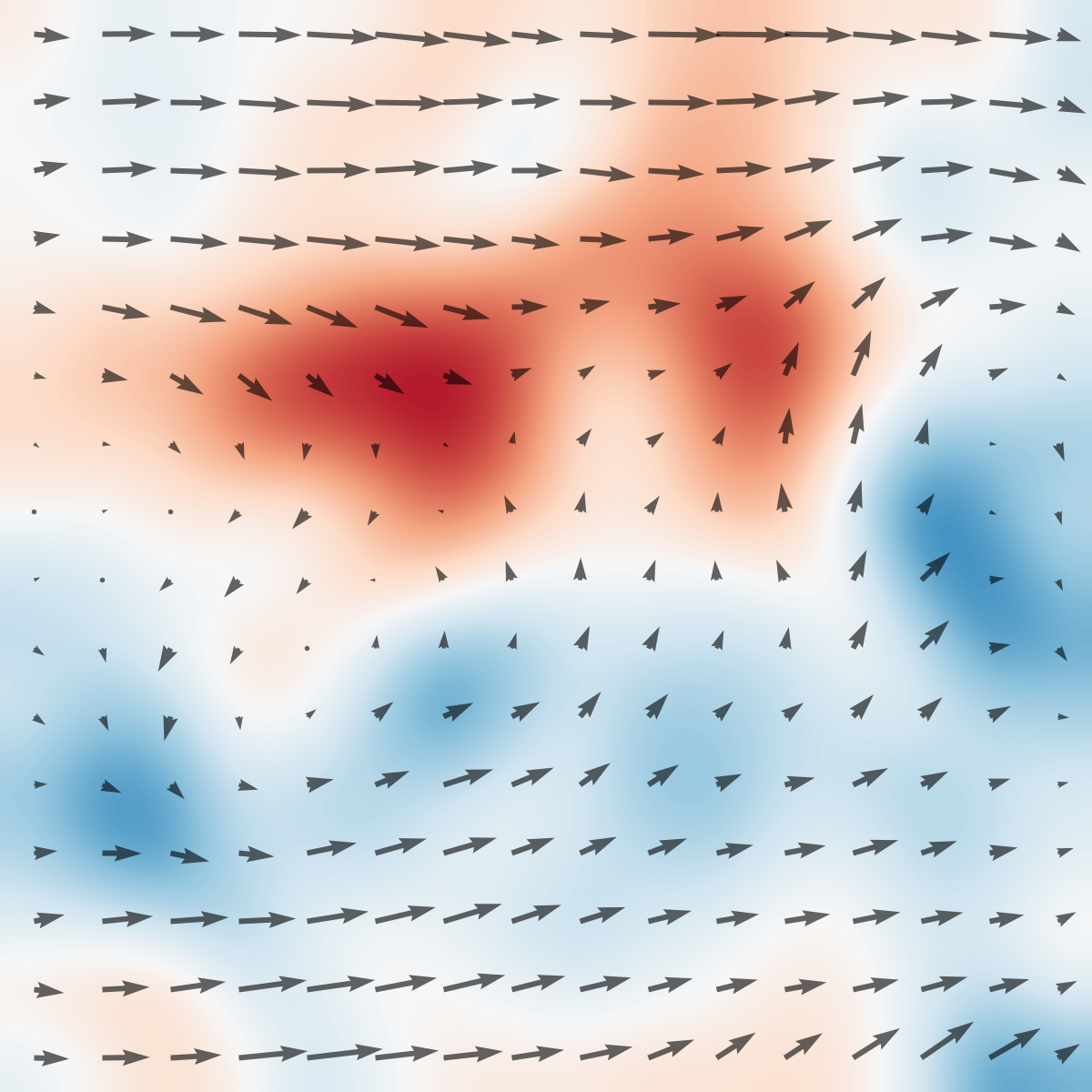
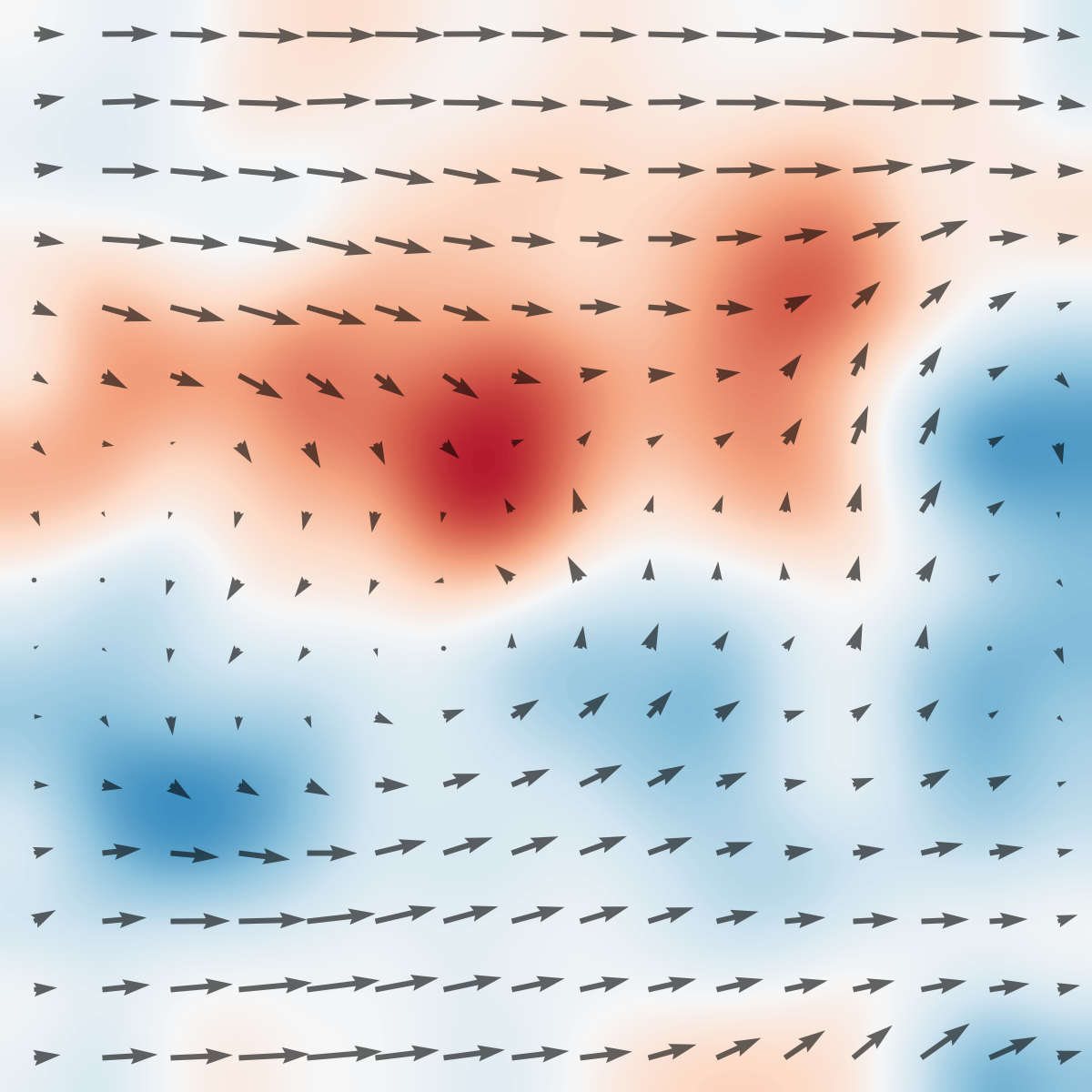
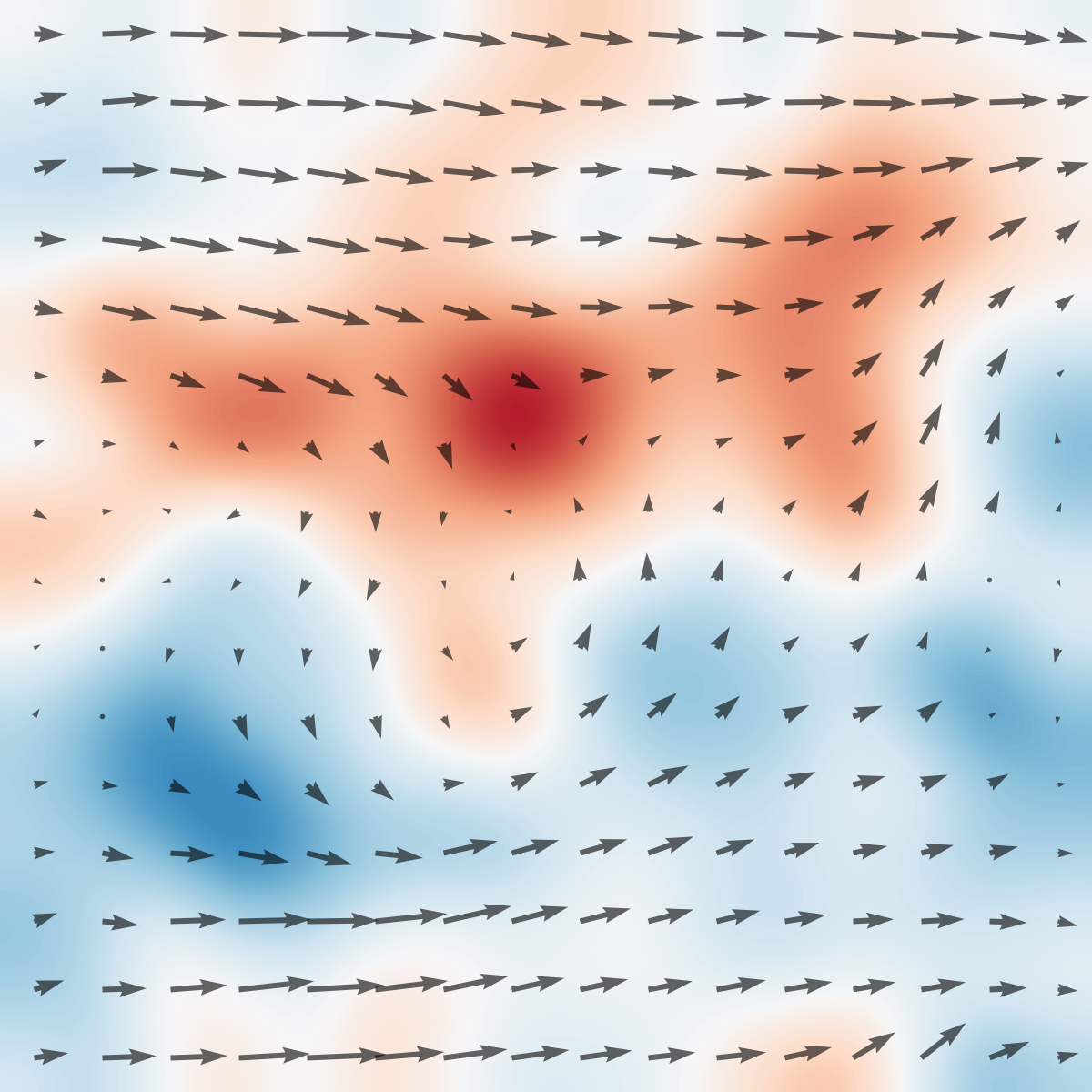
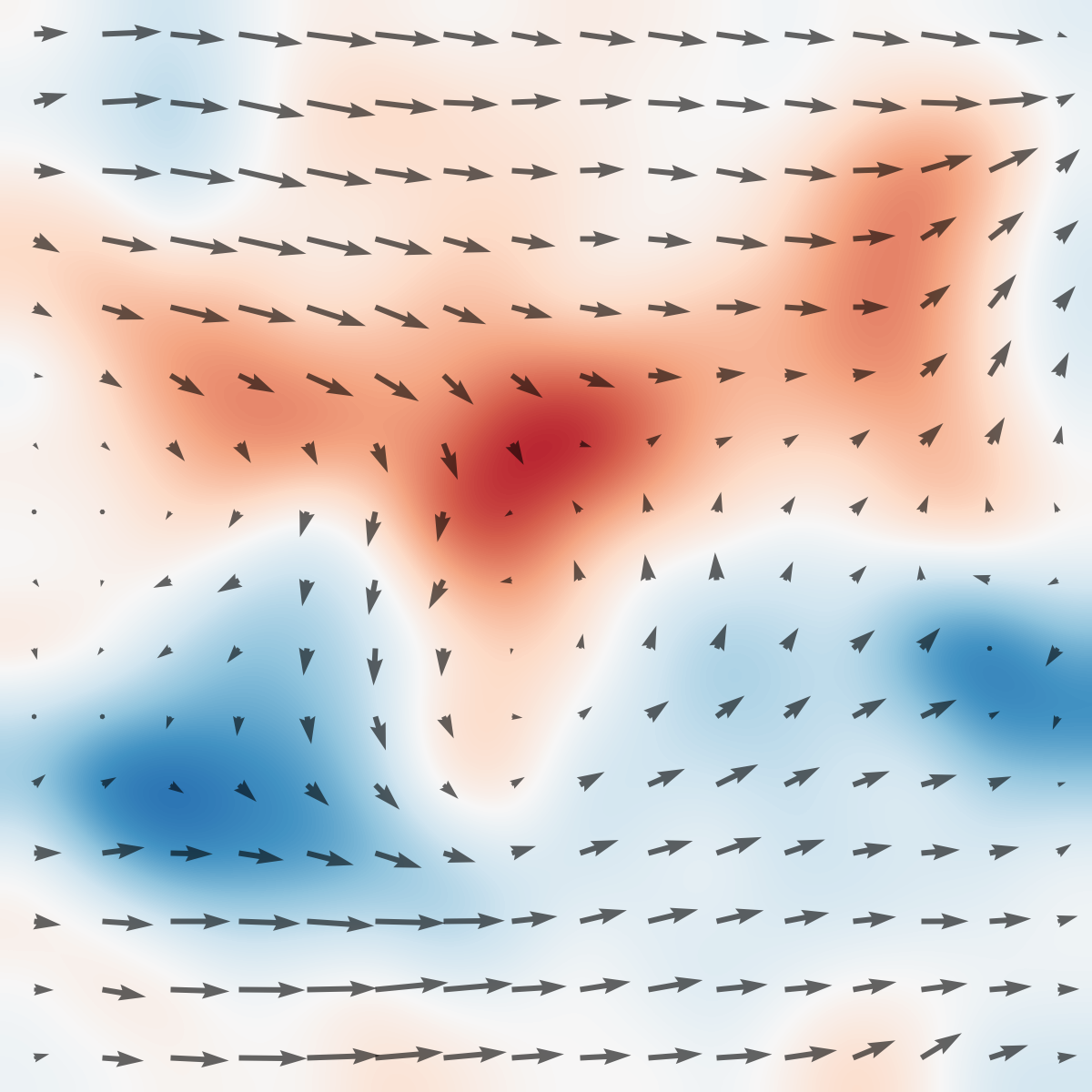
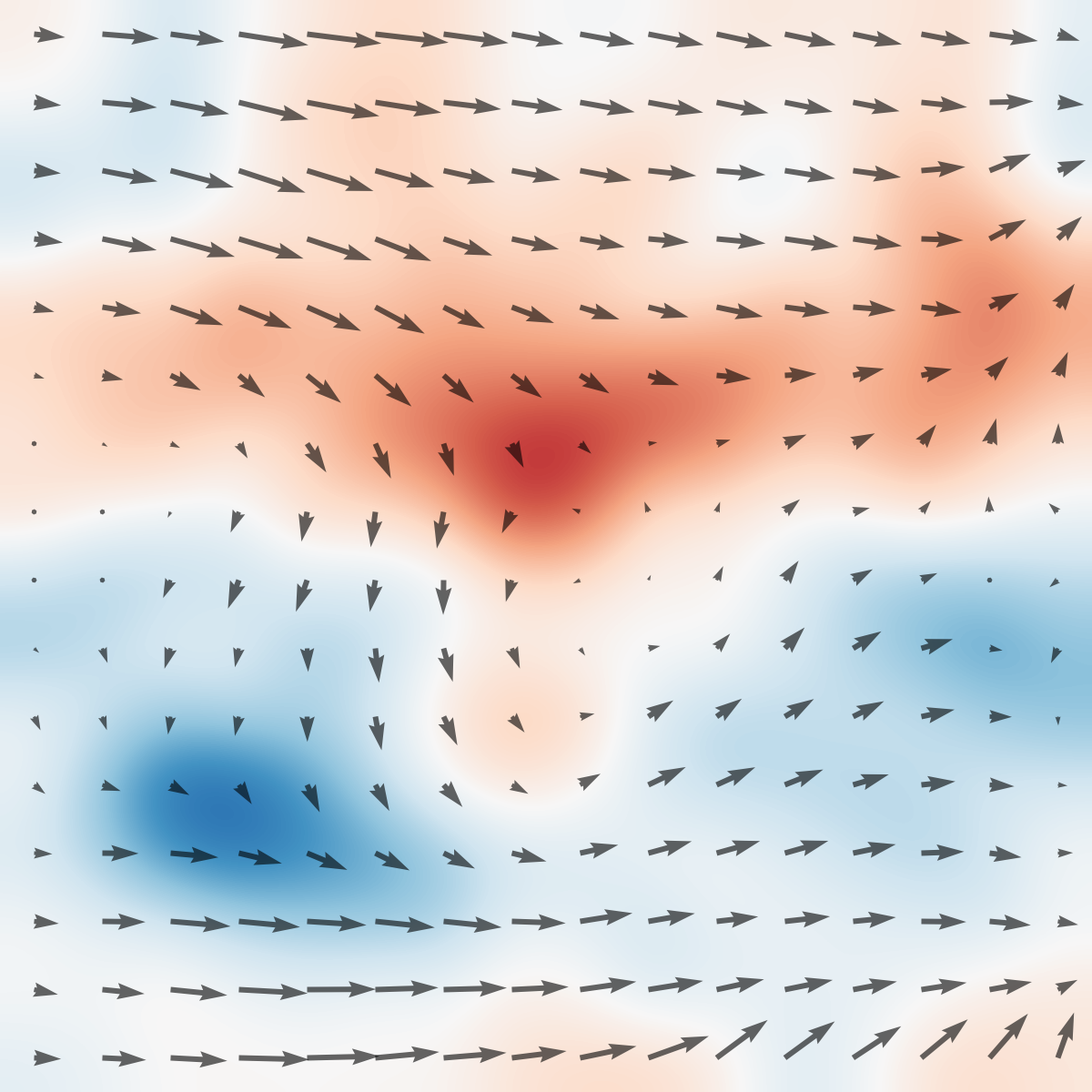
Figure 1: Top: The tabletop circulating water channel setup with labeled hardware components and PIV-based vorticity snapshots in the wake of the actuated cylinder.
The RL agent’s action space is the normalized instantaneous angular velocity ω(t) of the cylinder. Reward signal differs by task: for minimization, it is the episode-average decrease in drag with respect to baseline; for maximization, an increase.
Principal Findings
Role of Flow Feedback in Acquisition Versus Execution
A pivotal outcome is the dissociation between the informational demands of learning and those of execution. With access to high-dimensional flow feedback during training, DreamerV3 discovers high-performance policies for both drag extremization tasks within minutes—remarkable given the complexity of the flow and the absence of simulation. When the executed policy (i.e., the action sequence) is replayed open-loop (without any feedback or observations, but in the same initialization), the realized performance nearly matches the online closed-loop trajectory.
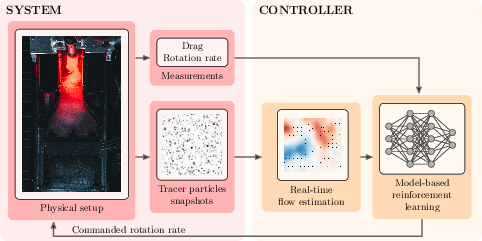
Figure 2: System overview: The RL agent commands the rotation; observations can include varying subsets of proprioceptive and exteroceptive signals, including the PIV flow estimate.

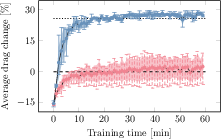
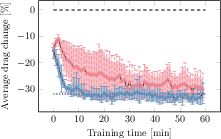
Figure 3: Training curves for drag variation (normalized) for DreamerV3 with and without flow feedback in both tasks, showing mean and min-max bands.
Notably, withholding flow feedback during training produces drastically asymmetric results:
- In drag minimization, the agent reliably discovers good (albeit more variable and slower-converging) policies even in the absence of flow feedback.
- In drag maximization, discovery of high-performance policies fails entirely without flow feedback—even though the task is equivalent up to reward sign, physical system, and open-loop action complexity.
Feedback as a Catalyst for Skill Discovery
A core claim, empirically justified in the study, is that the information needed to learn a high-performance policy can far exceed that required to execute it. In drag maximization, the flow system exhibits deceptive non-minimum-phase transients: actions that ultimately increase drag initially reduce it. This effect, evidenced by anti-correlated early rewards, leads to failed exploration and suboptimal policy search without enriched feedback signals. Inclusion of the flow feedback resolves the aliasing and misleading transients, facilitating the successful discovery of the open-loop maximizing input.
Figure 4: Replay of learned policies in open loop shows close agreement between closed-loop (blue) and replayed (red) drag profiles; the advantage of feedback is marginal at execution except for small corrections.
Figure 5: Aggregated results over multiple observation configurations; flow feedback is critical for sample-efficient optimization in drag maximization but not for minimization.
Insensitivity to Model Size and Algorithm Choice
Ablations confirm that the observed phenomena are robust to variations in observation subsets, DreamerV3 model size, method of feedback removal (branch omission vs. null input), and persist across multiple standard RL baselines (PPO, SAC), which fail to solve the maximization task without privileged feedback.
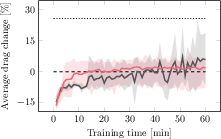
Figure 6: Learning dynamics under model size variation; performance outcomes are invariant to model parameter count.
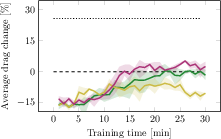
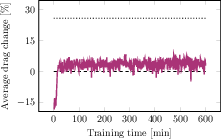
Figure 7: PPO, PPO-R, and SAC fail to approach optimal drag-maximizing performance without flow feedback.
Theoretical and Practical Implications
Feedback, Exploration, and Non-Minimum-Phase Dynamics
The experimental outcomes directly intersect with robust and adaptive control theory, especially regarding non-minimum-phase systems where transient system responses can actively mislead reward-driven exploration. The findings empirically instantiate classical learning-theoretic results: sufficiently rich observations during training can resolve ambiguities and mitigate pathologies that confound generic model-free RL in high-dimensional, partially observable, nonlinear environments.
The study motivates a new class of observation-adaptive agents: architectures where sensor input selection, and even feedback utilization per se, is dynamic and context-dependent, potentially regulated by epistemic uncertainty estimates or predicted performance loss. Existing paradigms such as asymmetric actor-critic, distilled privileged sensing, and event-triggered RL are referenced, but the results here go further—arguing for architectures that can exploit high-dimensional feedback during learning yet disregard it (except for marginal corrections) during execution. This model aligns with empirical motor-control phenomena observed in humans and biological systems and suggests fertile directions for both theory and hardware implementations.
Fluids Control and Benchmarks
On the domain science side, the work contributes an open-source, physically grounded benchmark for fluids control with high-throughput, real-time flow estimation—a resource-poor area where simulation has severe limitations.
Outlook and Future Directions
The study's methodology is broadly extensible to other nonlinear, non-minimum-phase physical systems. Next steps include theoretically characterizing the regimes under which task/reward design, system dynamics, or observation structure create "kind" versus "wicked" learning conditions; developing adaptive-feedback RL architectures that optimize the cost-performance tradeoff of sensor utilization; and applying these principles to higher-dimensional embodied control in robotics and bio-inspired automation.
The experimental testbed also positions itself as a foundation for research into continual learning, adversarial fluid control, and sensor placement optimization, among other lines.
Conclusion
This work provides compelling evidence that skill acquisition in complex physical environments often demands a richer sensorimotor data stream than is required for optimal execution, a property linked to system dynamics and reward structures. Flow feedback is shown to be essential for learning high-performance open-loop policies in non-minimum-phase tasks but unnecessary for their deployment. These findings underscore the limitations of fixed-observation RL pipelines and motivate research into flexible, observation-adaptive agent designs. The low-cost physical infrastructure and benchmark released by the authors pave the way for longitudinal and cross-domain investigations into the fundamental mechanics of sensorimotor learning.