- The paper introduces the parallel shifts (PS) assumption to derive sharper counterfactual intervals for average treatment effects on treated units using interval data.
- It critiques naive scalar and interval-based extensions of parallel trends, demonstrating their limitations with examples like the minimum wage experiment.
- Empirical results using Card and Krueger data show that PS produces valid, monotonic, and interpretable identification sets, adaptable for covariate adjustments.
Introduction and Motivation
This paper rigorously extends the canonical difference-in-differences (DID) framework to settings where outcome variables are reported as intervals, reflecting practical occurrences in survey and administrative data (e.g., top-coded incomes, rounded employment counts). While partial identification and random set approaches have been leveraged in econometrics, existing DID analyses typically presume observable scalar outcomes and do not directly translate to interval-valued data. The authors provide a comprehensive critique of naive generalizations of the parallel trends (PT) assumption in this context and introduce the parallel shifts (PS) assumption, which yields theoretically desirable properties and empirically plausible identification sets for the average treatment effect on the treated (ATT).
Issues with Naive Parallel Trends Extensions
The DID estimator relies fundamentally on counterfactual inference—what would have happened to treated units absent the treatment—identified under the PT assumption. When outcomes are reported as intervals, classical approaches to imposing PT become ambiguous or problematic. The paper formalizes two natural extensions:
- Scalar Parallel Trends (SPT): The PT assumption is imposed on the unobserved scalar outcome Yit, with partial identification for its mean given observed intervals. The resulting bounds on the ATT are generally uninformative, as they aggregate worst-case combinations of lower and upper interval endpoints across groups and periods.
- Interval Parallel Trends (IPT): PT is imposed at the level of the interval endpoints (i.e., transporting both upper and lower bounds under a common affine map), but this can yield counterintuitive dynamics—such as the lower bound for the treated trending in the opposite direction of the control group.
Applying either method to the classic Card and Krueger (1994) minimum wage experiment, the identified sets for counterfactual means under SPT are extremely wide, failing to exploit available structure, while IPT often generates non-monotonic or incoherent bound movements, especially when pre-treatment interval lengths differ.
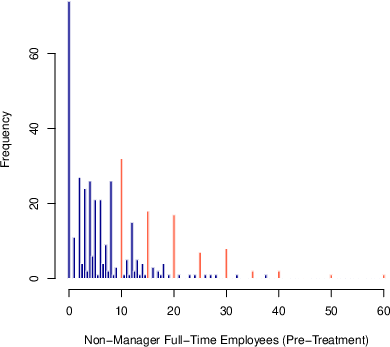
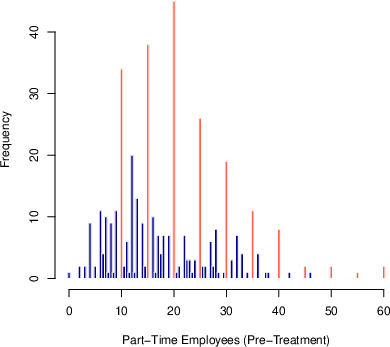
Figure 1: SPT and IPT strategies yield overly wide or non-interpretable counterfactual bound dynamics in employment intervals (Card & Krueger data).
The Parallel Shifts Assumption
To address the operational and theoretical deficiencies of SPT and IPT, the authors propose the parallel shifts (PS) assumption. Rather than matching time trends in means (as in SPT/IPT), the PS approach matches cross-sectional shifts between groups at each period, i.e., the difference between treated and control group means at baseline is preserved in the counterfactual period.
Formally, PS is implemented via a scaling and translation of the interval:
$\aE{\bm{Y}_{i2}(0) \mid D_i=1} = S\left(\aE{\bm{Y}_{i2}(0) \mid D_i=0}\right),$
where S(⋅) is an affine mapping determined by pre-treatment interval means and their lengths in both groups. This approach ensures the identified interval for counterfactual treated means is properly aligned with observed dynamics in both group and time dimensions.
A sequence of numerical examples demonstrates that PS always generates valid intervals, preserves proportional changes in interval length, and matches the qualitative trends of the control group, regardless of initial heterogeneity in interval widths or positions.
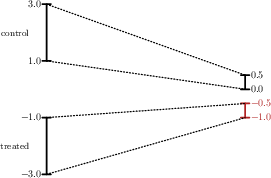
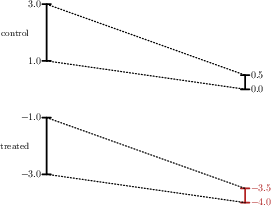
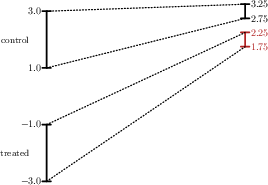
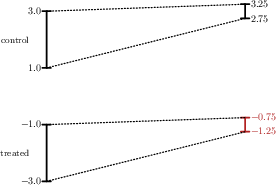
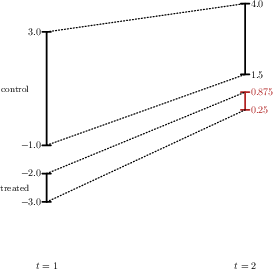
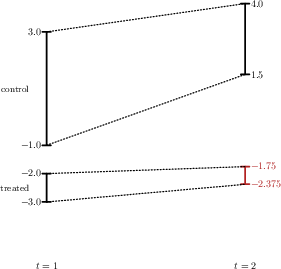
Figure 2: Example 1—Comparing IPT (left) and PS (right): PS respects the monotonicity and magnitude of control group trends for the treated group’s bounds.
Theoretical Properties and Desirability
The authors provide rigorous justification for the PS mapping, presenting necessary and sufficient conditions (interval validity, proportionality in changes, and preservation of directionality) that uniquely select PS among continuous affine maps of interval-valued data. Thus, PS is the only plausible extension satisfying key desiderata for interval DID designs.
Additionally, PS generalizes readily to conditional DID settings, incorporating observed covariates via definition of S(⋅;X) and maintains nonempty, interpretable identified sets for the ATT.
Empirical Application: Reanalysis of Card and Krueger (1994)
Applying the PS identification strategy to the New Jersey-Pennsylvania fast-food minimum wage experiment, the paper codes rounded employment counts as intervals (e.g., values at multiples of 5 become [k−5,k+5]). The PS-identified set for the NJ counterfactual aligns well with observed trends in PA, yielding tighter and more plausible intervals than SPT or IPT.
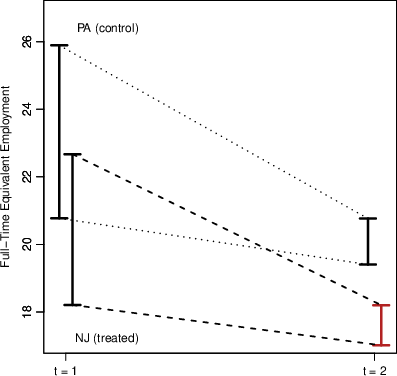
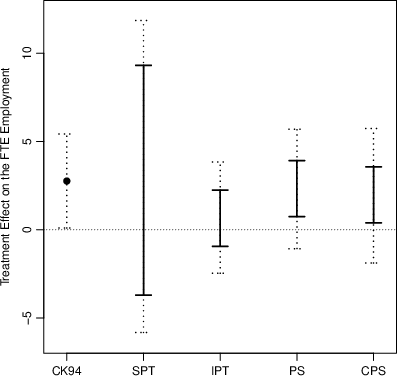
Figure 3: The PS-identified interval for the treated group closely tracks trends in the control group, providing a valid and sharp identification set for the ATT.
For the ATT, the PS and covariate-adjusted PS (CPS) sets both favor positive effects of the policy intervention, though the identified intervals include zero, in line with subsequent administrative data analysis [Card & Krueger 2000]. These results are robust to the choice of covariates and statistical inference is implemented using established methods for partially identified parameters.
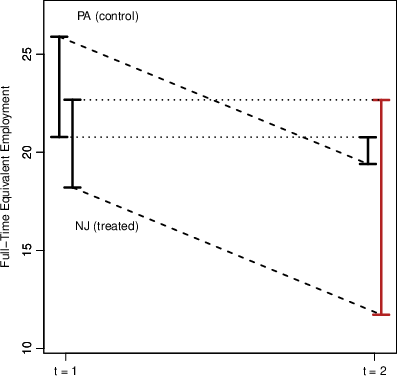
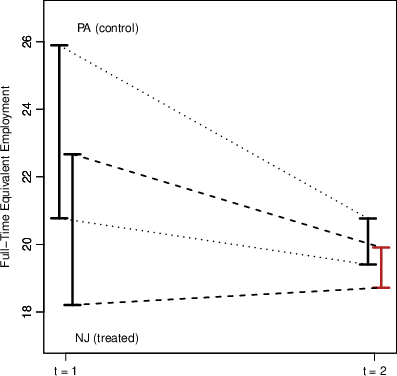
Figure 4: M—The empirical bounds for the ATT under PS and alternative assumptions using the Card & Krueger design.
Conclusion
This paper establishes the parallel shifts assumption as the canonical identification strategy for DID when outcomes are interval-valued, showing that alternative generalizations (SPT/IPT) fail to deliver economically meaningful or sharp partial identification regions. PS, grounded in a rigorous mapping framework, ensures valid, parsimonious, and interpretable ATT estimation in empirical settings plagued by coarsened or rounded reporting. Its empirical performance is verified using influential policy analysis data, and its generalization to covariate adjustment and more complex designs is immediate.
Further inquiry could adapt PS to multi-period or staggered adoption designs [CS21], accommodate fuzzy assignment [de Chaisemartin 2018], or integrate variation-bound sensitivity frameworks [Manski & Pepper 2018, Rambachan & Roth 2023], thereby expanding the practical toolkit for causal inference with interval-reported data.