- The paper introduces a self-sustained two-stage framework that integrates high-recall YARA rules with lightweight ML to reduce false positives and support continuous analyst feedback.
- It proposes the novel Simula method for seedless synthetic data generation, creating balanced datasets without relying on historical labeled attacks.
- Active learning and simple lexical models enable near-real-time threat detection over petabyte-scale logs, ensuring operational scalability and improved precision.
Democratizing ML for Enterprise Security: A Self-Sustained Attack Detection Framework
Hybrid Approach: Motivations and Architecture
The persistent predominance of rule-based detections in enterprise security, despite considerable advances in ML, stems from operational efficiency, data scarcity, and the skill gap separating security engineering and data science. Rule-based systems such as those implemented with YARA offer fast matching and a familiar operational paradigm but suffer high rates of both false positives and false negatives due to pattern rigidity and unsustainable manual tuning. Conversely, ML-driven detectors, while capable of adaptive learning and distribution shift resilience, are hindered by computation demands and the practical challenge of training robust models without large volumes of accurately labeled attack data.
To resolve these dual limitations, the paper proposes a two-stage hybrid detection pipeline. The first stage employs intentionally broad, high-recall YARA rules, ensuring comprehensive threat coverage but admitting a flood of noisy positives. The second stage introduces a downstream ML classifier, tasked with suppression of false positives and calibrated to the investigation budget and operational constraints.
This system is underpinned by an active feedback loop: results from analyst investigations are continuously incorporated into model retraining cycles to mitigate rule degradation and adapt to evolving threats and network contexts.
Synthetic Data Generation via Simula
A core innovation of the framework is its use of Simula, a seedless synthetic data generation methodology. Simula utilizes taxonomic reasoning and agentic scenario synthesis to create balanced, high-diversity training sets without requiring either historical labeled data or in-depth ML expertise. Security analysts define strategies and taxonomies, which Simula transforms into expansive sets of realistic positive and negative samples, subject to automated quality assessment by a critic LLM. This democratizes ML training, enabling domain experts to serve as guiding "teachers" without direct engagement with model internals.
Lightweight Model Selection and Scalability
Empirical evaluation within the framework discounts the necessity of heavyweight transformer or embedding models for command-line threat classification tasks. Most notably, simple lexical models—e.g., n-gram tokenization—are shown to match or surpass the performance of embedding-based models such as CmdCaliper and RETSim for discriminating terminal command line usage (Figure 1).
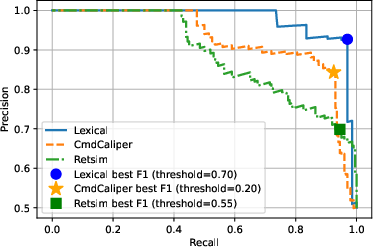
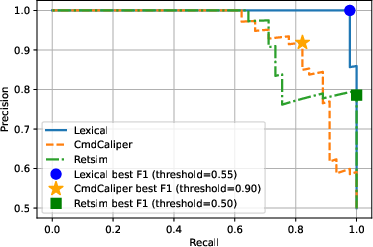
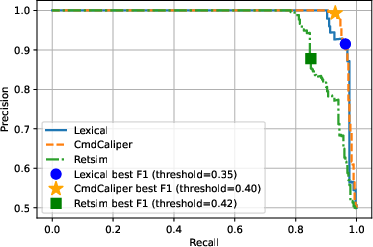
Figure 1: Precision-Recall curve comparing model performances across lexical (N-gram), CMDCaliper, and RETSim models for three enterprise detection scenarios.
The computational efficiency of lexical modeling ensures operational scalability, supporting near-real-time inference across petabyte-scale daily log volumes while maintaining feasible alert volumes for human analysts.
Active Learning and Analyst Efficiency
The framework incorporates active learning principles for feedback ingestion, assigning time-decaying weights to analyst-labeled data points and adjusting for class imbalance—critical in environments with a ratio of benign-to-malicious instances orders of magnitude apart. Feedback-driven retraining enables rapid adaptation to novel threats and network changes, avoiding the stagnation associated with static rule sets.
Extensive live deployment and A/B testing demonstrate the active learning pipeline’s superiority. The active model not only preserves coverage on known incidents, but consistently identifies additional true positives and reduces false positive tickets relative to a fixed, non-updatable baseline, quantifying a net gain in both threat detection and analyst efficiency.
Quantitative Validation
The system has been evaluated across multiple Google-internal security scenarios, including reverse shell, hacking tools, and living-off-the-land (LOTL) attacks. It processes over 250 billion daily raw events, reducing them through staged filtering and ML inference to fewer than one ticket per detection scenario per day—a reduction factor of nine orders of magnitude. Simula-generated synthetic datasets with 20,000 balanced samples in 20 minutes enable models to achieve a precision-recall F1 score of 0.95, outperforming labor-intensive manually curated datasets by a significant margin.
Theoretical and Practical Implications
This framework demonstrates that self-sustaining, analyst-guided threat detection pipelines are operationally feasible and can maintain precision and adaptability at hyperscale. The use of reasoning-centric synthetic data generation and lightweight ML offers clear advantages: reduced deployment and maintenance overhead, robust performance against distributional drift, and new avenues for democratized ML application across domains with severe data scarcity or privacy risk.
These results suggest a paradigm shift in applied enterprise ML security, privileging automation, reasoning-based synthetic data, and continuous analyst-in-the-loop adaptation over static, heuristic-heavy practices.
Prospective Directions
Further research opportunities arise in exploring chunking approaches and hybrid lexical-semantic models for improved handling of long, complex command lines, as well as the generalization of seedless synthetic data generation to additional security and operational domains. The established feedback-driven continuous adaptation pipeline can be extended to support broader classes of security events, anomaly types, and federated organizational deployments.
Conclusion
The proposed framework effectively integrates rule-based filtering, lightweight ML classification, reasoning-driven synthetic data generation, and active learning to deliver scalable, precise, and maintainable enterprise threat detection. By enabling security analysts to guide model refinement without deep ML expertise and rigorously validating efficiency and adaptability at production scale, the system offers a compelling blueprint for the democratization of ML in security operations.