EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Abstract: Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce”
1) What is this paper about?
This paper introduces EcomBench, a big, carefully designed “test” for AI assistants (called foundation agents) that help with e-commerce tasks. EcomBench checks how well these AIs can handle real problems people face when buying and selling online—like understanding rules, planning prices, managing stock, and making marketing decisions. Unlike many tests that use school-like puzzles, EcomBench uses real questions from actual e-commerce platforms to see if AIs can be useful in the real world.
2) What questions is the paper trying to answer?
The paper aims to find out:
- Can today’s AI assistants solve real e-commerce problems, not just classroom-style puzzles?
- How well do they handle tasks that require:
- Deep information searching (finding and checking facts),
- Multi-step reasoning (breaking a problem into several steps),
- Combining information from different places (web pages, rules, numbers)?
- Do different AI models have different strengths in areas like rules, pricing, logistics, and strategy?
- How should we build a fair, up-to-date test that matches the fast-changing world of e-commerce?
3) How did the researchers build and use EcomBench?
Think of EcomBench like a realistic exam designed with help from human experts:
- Human-in-the-loop (humans guiding the process): The team collected real questions from big e-commerce ecosystems (like ones you’d find on Amazon). They removed vague or opinion-based requests (e.g., “Is this product cool?”) and kept questions with clear, checkable answers. Experts then rewrote and verified the questions to make sure they were accurate, clear, and truly useful.
- Avoiding made-up questions: Instead of asking an AI to generate fake questions, they relied on human-written and human-checked tasks. This makes the test feel like the real problems sellers and buyers face.
- Tool hierarchy (finding truly hard questions): Imagine two toolboxes: a basic one (simple search and web browsing) and an advanced one (special e-commerce tools for prices and trends). The team used an AI with advanced tools to spot which questions are genuinely hard—ones that need many steps and careful reasoning if you only have the basic toolbox. These became Level 3 (the hardest) tasks.
- Task variety and difficulty levels:
- Policy Consulting (platform rules and compliance),
- Cost and Pricing,
- Fulfillment Execution (shipping, returns),
- Marketing Strategy,
- Intelligent Product Selection,
- Opportunity Discovery,
- Inventory Control.
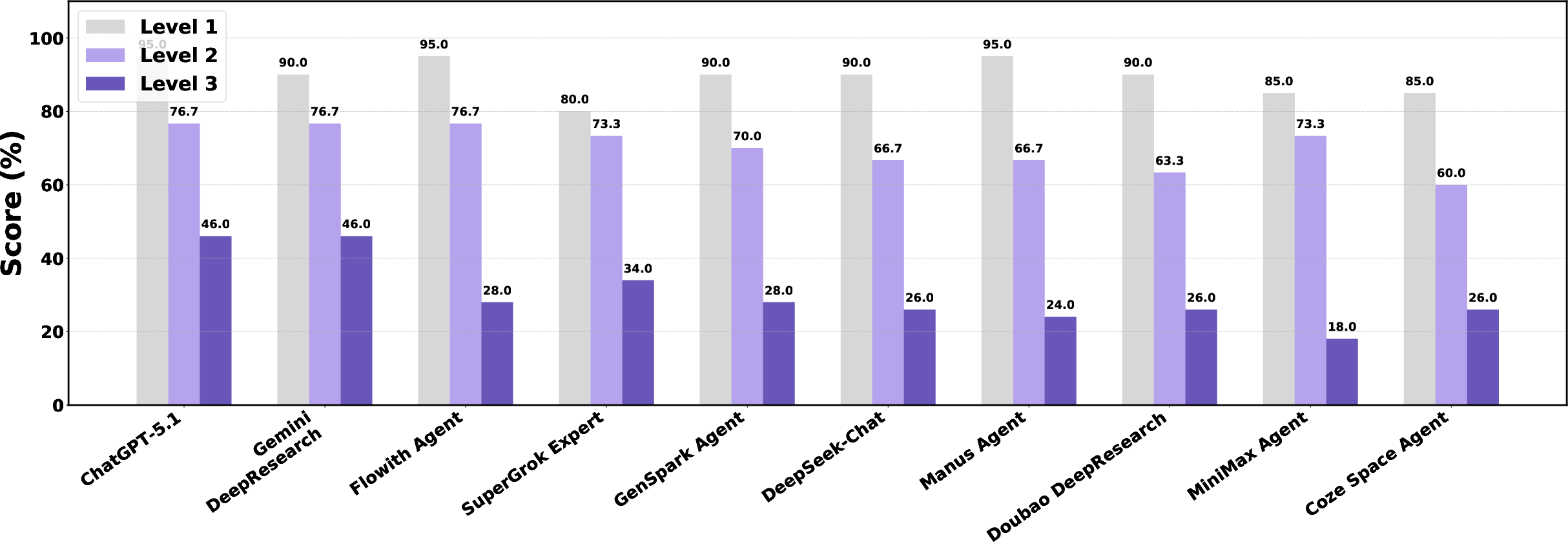
Each question is labeled by difficulty: - Level 1: simpler, basic knowledge and simple tool use, - Level 2: medium, multi-step reasoning, - Level 3: hard, long reasoning, combining sources, and careful planning.
- Testing many AI models: They ran a range of well-known AI assistants on EcomBench and scored answers using a judging AI that compared each response to the ground-truth solution. Each question was scored as right (1) or wrong (0), and models’ average scores were reported.
- Regular updates: E-commerce changes fast (policy updates, new trends). EcomBench is updated quarterly to replace outdated or too-easy questions and add new, challenging ones.
4) What did they find, and why does it matter?
Main results:
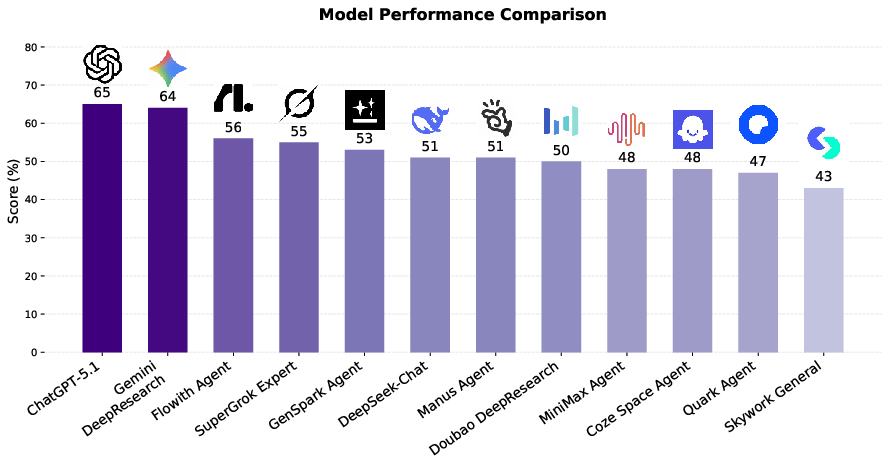
- AIs do well on easy tasks but struggle on hard, realistic ones. Models often scored 80–95% on Level 1 questions, but performance dropped sharply on Level 3. Even top models hovered around the mid-40% range at the hardest level. This shows that while AIs can handle simple e-commerce questions, they still have trouble with complex, multi-step tasks that require deeper reasoning and tool use.
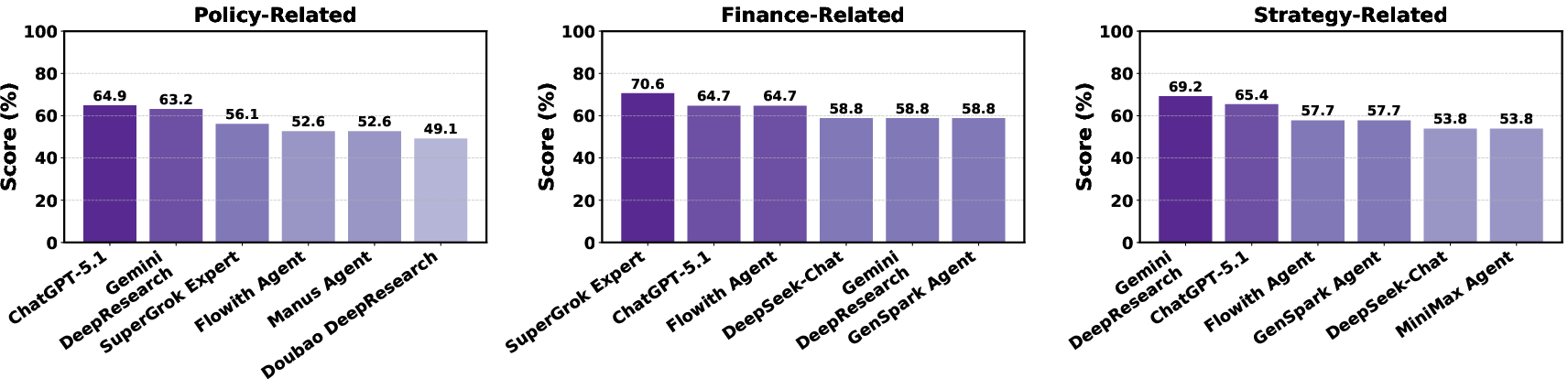
- Different models shine in different areas. For example, one model might be better at finance tasks (like pricing and inventory), while another excels at strategy (like marketing or selecting products). There isn’t one perfect model that wins everywhere.
Why it matters:
- Real e-commerce work is complex and high-stakes. You don’t want an AI that only gets easy questions right. EcomBench highlights where current AIs fall short and where they need to improve to be genuinely helpful to sellers, buyers, and platforms.
5) What does this mean for the future?
Implications and impact:
- Better training targets: EcomBench shows exactly the kinds of skills AIs need to improve—multi-step reasoning, careful use of tools, and combining facts from different sources in changing situations.
- Real-world relevance: Because it’s built from real user needs and regularly updated, EcomBench can guide AI developers to build assistants that work in the messy, fast-moving world of e-commerce.
- Expanding scope: Future versions aim to include more predictive and decision-focused tasks (like forecasting market trends or choosing products to sell), not just Q&A.
- Current limitations: Right now, EcomBench focuses on questions with clear answers rather than full-on interactive environments. It also requires ongoing human effort to maintain quality, which is time-consuming—but it keeps the benchmark realistic and trustworthy.
In short, EcomBench is a practical, evolving “report card” for AI assistants in e-commerce. It helps researchers and companies see what AIs can do today, where they struggle, and how to build smarter, more reliable tools for real businesses and customers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research and benchmark development.
- Dataset statistics are absent: number of questions, per-category counts, per-level distribution, average complexity, and temporal coverage are not reported.
- Data availability and licensing are unclear: there is no explicit release link, license, or reproducibility plan (datasets, evaluation scripts, judge prompts, seeds).
- Tool standardization is unspecified: agents likely differ in available tools (web browsing, e-commerce APIs), but the paper does not define a common toolset or environment, risking unfair comparisons.
- Evaluation conditions are not controlled or documented: it is unclear whether agents had web access, which tools were permitted, time limits, context windows, or rate limits—critical for comparability.
- LLM-judge details and validation are missing: judge model identity, prompt templates, decision criteria, calibration, and empirical reliability (precision/recall against human judgments) are not provided.
- No inter-annotator agreement metrics: while questions are “independently labeled,” there are no statistics on agreement (e.g., Cohen’s κ), disagreement resolution, or discard rates.
- Ground-truth provenance and citation are not documented: many tasks rely on regulations/standards; the sources and versions used for ground truth, plus links/citations per item, are not provided.
- Difficulty stratification has no quantitative validation: there is no evidence that level assignments correlate with measurable complexity (e.g., steps taken, tool calls, time-to-solve).
- Tool-hierarchy selection is not reproducible: the specialized tools used to identify Level-3 items, the rejection-sampling protocol, and parameters are not shared, limiting independent verification.
- Binary scoring may be too coarse: no policy for partial credit, numeric tolerance bands, unit normalization, or acceptance of multiple valid formulations in open-ended answers.
- No statistical significance or uncertainty reporting: evaluations lack confidence intervals, significance tests, or run-to-run variance, making comparative claims hard to substantiate.
- Contamination auditing is undefined: despite quarterly updates, there is no methodology to detect/model training data contamination or to guard against leakage from widely crawled sources.
- Privacy and ethics of “real user demands” are unaddressed: anonymization, consent, PII removal, and compliance with platform terms/policies are not discussed.
- Geographic and multilingual coverage are unclear: the benchmark appears English-centric with US/EU regulations; inclusion of other languages and markets (e.g., China, India, LATAM) is not specified.
- Modality limitations: e-commerce is inherently multimodal (images, product pages, tables), but tasks are text-only; plans and methods to incorporate multimodal evaluation are missing.
- Interaction and multi-turn evaluation are not included: the benchmark focuses on single-turn QA rather than interactive workflows, tool orchestration, or UI navigation tasks common in e-commerce.
- Process-level metrics are absent: there is no measurement of reasoning quality, plan optimality, number of tool calls, or efficiency (e.g., steps-to-correct), which are central to agentic performance.
- Domain coverage gaps: categories omit important areas such as customer support dialogue, fraud/abuse detection, dispute resolution, procurement/sourcing, and compliance audits across platforms.
- Predictive and decision-theoretic tasks are only promised: concrete protocols for forecasting ground truth (windows, targets), probabilistic scoring, and backtesting are not specified.
- Robustness stress tests are missing: tasks with conflicting sources, noisy data, adversarial perturbations, or policy updates mid-solve are not included.
- Economic impact linkage is unexplored: the benchmark does not connect scores to business outcomes (ROI, conversion, margin uplift), leaving external validity to real operations unquantified.
- Versioning and governance of updates are undefined: no detailed changelog policy, backward compatibility guarantees, or governance structure for community submissions and review.
- Fairness and bias analysis is absent: no assessment of whether tasks disproportionately favor certain seller sizes, categories, or regions; fairness across segments is not measured.
- Agent personalization/context handling is unspecified: many tasks require seller-specific data; the benchmark does not define standardized assumptions or how to handle missing context.
- Rounding, units, and ambiguity handling need formalization: numeric tasks can fail due to minor formatting; explicit acceptance ranges and unit normalization policies are not provided.
- Sustainability and cost of maintenance are open: the human-in-the-loop approach is resource-intensive; strategies for scaling annotation quality and cost control are not outlined.
- Leaderboard reproducibility and ablations are missing: no experiments disentangle reasoning quality from tool availability or test sensitivity to judge choices and evaluation settings.
- Access and compliance risks are unaddressed: advising on regulatory/tax matters carries legal risk; the benchmark lacks a safety taxonomy and safeguards for harmful or non-compliant outputs.
Glossary
- Acceptance Quality Limit (AQL): A statistical quality control threshold used to decide whether to accept a batch based on sampled defects. Example: "is inspected using an AQL 1.0 sampling standard."
- Agentic frameworks: Architectures that interleave reasoning and tool use to enable autonomous decision-making in LLM agents. Example: "agentic frameworks like ReAct~\citep{yao2023react}"
- Autonomous agents: LLM-driven systems capable of independent reasoning, planning, and acting in environments. Example: "autonomous agents~\citep{team2025tongyi, qiu2025alita, kimiresearcher, zeng2025glm, Li2025webthinker}"
- Composite question-answering: Tasks that require integrating multiple operations or knowledge sources to produce a single answer. Example: "composite question-answering tasks"
- Cross-source knowledge integration: Combining information from multiple external sources to form a coherent, accurate answer. Example: "cross-source knowledge integration"
- Data contamination: Leakage of test information into training data, artificially inflating evaluation performance. Example: "reducing the potential risks of data contamination"
- dBi: A unit of antenna gain referenced to an isotropic radiator. Example: "using a 4 dBi antenna,"
- dBm: A unit of power expressed in decibels relative to 1 milliwatt. Example: "Calculate the equivalent isotropically radiated power (EIRP) in dBm."
- Department of Energy (DOE) Level VI efficiency standard: A U.S. energy efficiency regulation for external power supplies specifying minimum performance requirements. Example: "complies with the U.S. Department of Energy (DOE) Level VI efficiency standard"
- Difficulty stratification: The systematic partitioning of tasks into tiers to reflect increasing complexity. Example: "To validate our difficulty stratification"
- E-commerce-specific tools: Specialized utilities (e.g., price retrieval, trend analysis) tailored to e-commerce tasks. Example: "more advanced, e-commerce-specific tools"
- EN 300 328: An ETSI standard governing 2.4 GHz wideband transmission systems, including requirements for emissions. Example: "according to EN 300 328."
- Equivalent Isotropically Radiated Power (EIRP): The effective radiated power of a transmitter–antenna system assuming an isotropic radiator, used to assess compliance and coverage. Example: "equivalent isotropically radiated power (EIRP)"
- EU Radio Equipment Directive (RED): European Union regulation setting essential requirements for radio equipment safety and spectrum use. Example: "under the EU Radio Equipment Directive (RED)."
- Ground-truth answers: Verified, authoritative answers used as the standard for evaluation. Example: "ground-truth answers"
- Human-in-the-loop: A curation or evaluation process that relies on human expertise for refinement and verification. Example: "using our human-in-the-loop data engine."
- Long-horizon planning: Reasoning and action sequencing over many steps to reach goals that require extended coordination. Example: "long-horizon planning"
- Out-of-band emission attenuation: Required reduction of emissions outside the assigned band to limit interference. Example: "out-of-band emission attenuation"
- Peer validation: Cross-checking by multiple experts to confirm the correctness and clarity of items or labels. Example: "subjected to peer validation"
- Persona-based user simulations: Evaluation setups where synthetic users with defined personas interact with agents to test capabilities. Example: "persona-based user simulations"
- ReAct: A framework that interleaves reasoning (thought) and acting (tool use) to improve task performance. Example: "ReAct~\citep{yao2023react}"
- Rejection sampling: A filtering method that retains samples meeting certain criteria by probabilistically rejecting others. Example: "apply rejection sampling to retain questions"
- Retrieval-Augmented Generation (RAG): Techniques that enhance LLMs by fetching external documents to ground generation. Example: "Retrieval-Augmented Generation (RAG)~\citep{lewis2020retrieval}"
- Tool-hierarchy-based question selection: A method of selecting difficult tasks by testing solvability with increasingly capable toolsets. Example: "we adopt a tool-hierarchy-based question selection approach."
- Tool Hierarchy: An ordering of tools from basic to advanced used to characterize task difficulty and agent capability. Example: "using a Tool Hierarchy approach."
- Verifiable answers: Responses that can be checked definitively against objective criteria or authoritative sources. Example: "with verifiable answers"
Practical Applications
Immediate Applications
Below are concrete applications that can be deployed now, grounded in EcomBench’s tasks, curation process, evaluation protocol, and difficulty design. Each item includes likely sector(s), potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
- Procurement-grade evaluation harness for e-commerce agents
- Sectors: e-commerce platforms, retail marketplaces, software procurement
- What it is: Use EcomBench as an acceptance test to compare internal/third‑party agents on policy consulting, pricing, fulfillment, marketing, selection, opportunity discovery, and inventory tasks. Establish SLAs and minimum pass rates by level/category.
- Tools/products/workflows: CI/CD integration for agent updates; score dashboards; per-category leaderboards; regression gates using LLM-judge + human spot checks.
- Assumptions/dependencies: License/access to EcomBench; reliable LLM judges calibrated to reduce false positives; mapping between benchmark distribution and in‑house task mix.
- Task-aware model routing and ensemble strategies
- Sectors: e-commerce platforms, contact centers, BPOs
- What it is: Route user requests to the model that performs best per EcomBench category (e.g., send finance tasks to the strongest finance agent).
- Tools/products/workflows: Category classifier (7-class taxonomy); router microservice; fallback and escalation rules for Level‑3 items.
- Assumptions/dependencies: Stable relative performance across time; latency/cost trade-offs; observability to detect drift and re-train routers.
- Compliance and policy QA for customer-facing assistants
- Sectors: policy/regulatory, compliance, legal, e-commerce seller services
- What it is: Validate assistants on Level‑1/2 Policy Consulting tasks (e.g., DOE efficiency limits, AQL acceptance probability, VAT registration guidance).
- Tools/products/workflows: Policy test packs per jurisdiction; “compliance badge” scoring; release checklists to prevent policy hallucinations.
- Assumptions/dependencies: Up-to-date regulations; clear jurisdiction metadata; legal review of assistant outputs and disclaimers.
- Pricing and landed-cost assistant validation
- Sectors: finance, cross-border trade, e-commerce operations
- What it is: Benchmark agents that compute quotes, VAT/duties, configuration fees, FX conversions, and total payable amounts.
- Tools/products/workflows: Embedded calculators (VAT, customs, FX); audit trails for intermediate steps; invoice-ready output.
- Assumptions/dependencies: Accurate and fresh rates (tax, customs, FX); verifiable formulas; coverage of edge cases (bundles, thresholds).
- Logistics and fulfillment troubleshooting checks
- Sectors: logistics, operations, customer support
- What it is: Use Fulfillment Execution tasks to evaluate agents that recommend shipping options, returns/exchanges, and route improvements.
- Tools/products/workflows: Playbooks mapped to benchmark scenarios; standard operating procedures (SOP) generator; exception handling templates.
- Assumptions/dependencies: Access to carrier constraints and tariffs; dynamic service levels; integration with OMS/WMS APIs for context.
- Benchmark-driven agent tool design and prioritization
- Sectors: software/tooling, developer platforms
- What it is: Leverage the tool hierarchy concept to prioritize building high-value, domain tools (e.g., product price fetchers, trend analyzers, VAT/duty calculators, RF/EIRP checkers).
- Tools/products/workflows: Tool library roadmaps; “step-count reduction” metrics to quantify impact; developer SDKs for tool plugins.
- Assumptions/dependencies: Clear tool APIs; authoritative data sources; governance for tool reliability and deprecation.
- Human-in-the-loop data engine for internal dataset curation
- Sectors: academia, enterprise AI teams, applied research
- What it is: Replicate EcomBench’s curation pipeline (seed mining from real demands; expert refinement; peer validation) to build private, verifiable datasets.
- Tools/products/workflows: Annotation guidelines; multi-annotator consensus; disagreement adjudication; verifiability audits.
- Assumptions/dependencies: Access to real user demands; budget for expert labeling; privacy controls and data minimization.
- Quarterly drift monitoring and product readiness checks
- Sectors: product management, MLOps, governance
- What it is: Use EcomBench’s quarterly updates as canary suites to detect model regressions and policy misalignment as rules/markets change.
- Tools/products/workflows: Scheduled test runs; change logs linking failures to new regulations; rollback gates and mitigations.
- Assumptions/dependencies: Timely uptake of benchmark updates; alerting and incident response; ownership for remediation.
- Academic benchmarking for agentic reasoning and tool use
- Sectors: academia, AI research labs
- What it is: A vertical, real-world benchmark to study multi-step reasoning, cross-source integration, tool-augmented planning, and category-specific generalization.
- Tools/products/workflows: Open evaluations; ablation studies on tool availability; training curricula aligned with Level‑1/2/3 tasks.
- Assumptions/dependencies: Reproducible evaluation harness; transparency on scoring; careful use to prevent contamination in model training.
- Seller onboarding and SME tutor evaluation
- Sectors: SMB services, marketplaces, daily life (small sellers)
- What it is: Validate onboarding tutors that guide VAT registration, listing compliance, basic pricing, and promo setup using Level‑1/2 items.
- Tools/products/workflows: Checklists per marketplace; interactive wizards; region-specific variants.
- Assumptions/dependencies: Localization; jurisdiction-specific rules; clear disclaimers for compliance-critical steps.
- Education and competitions
- Sectors: education, professional training
- What it is: Classroom labs and hackathons using EcomBench tasks to teach practical applied AI in e-commerce operations.
- Tools/products/workflows: Course modules; lightweight leaderboards; rubric-based grading aligned to verifiable answers.
- Assumptions/dependencies: Educational licensing; simplified subsets for teaching; scaffolding for tool use.
Long-Term Applications
These applications require further research, scaling, integration with live systems, or standardization before broad deployment.
- Agent certification standards for e-commerce compliance and safety
- Sectors: policy/regulatory, marketplaces, consumer protection
- What it is: Build a formal certification standard where agents must pass category/level thresholds (with human audits) to be approved for compliance-critical use.
- Tools/products/workflows: Standardized test suites; third-party auditors; public “accuracy and recency” labels; incident reporting protocols.
- Assumptions/dependencies: Multi-stakeholder governance; legal frameworks; funding for ongoing maintenance and impartial oversight.
- Live, in-situ evaluation with marketplace data
- Sectors: e-commerce platforms, large retailers
- What it is: Continuous benchmarking of agents against real production tasks (masked/ghost mode) with privacy-preserving telemetry, tied to SLAs and auto-remediation.
- Tools/products/workflows: Sandboxed evaluation lanes; safe replay; online/offline metrics reconciliation.
- Assumptions/dependencies: Data privacy and consent; robust red-teaming; negligible performance overhead.
- Closed-loop learning from benchmark-to-production
- Sectors: MLOps, applied ML
- What it is: Use benchmark failures to synthesize new hard cases via tool hierarchy; feed into fine-tuning, DPO/RLAIF, or RL training for agentic improvement.
- Tools/products/workflows: Failure harvesting pipelines; automatic hard-sample generation; curriculum schedulers by difficulty.
- Assumptions/dependencies: Guardrails against overfitting/contamination; compute budgets; careful evaluator calibration to prevent reward hacking.
- Autonomous tool synthesis and refinement
- Sectors: developer platforms, software ecosystems
- What it is: Agents analyze multi-step traces to propose new high-level tools that minimize action steps (e.g., bundled “landed-cost + compliance precheck” tools).
- Tools/products/workflows: Tool opportunity miners; code generation with verification; human review loops.
- Assumptions/dependencies: Secure codegen; runtime sandboxes; versioning and rollback; standardized tool registries.
- End-to-end multi-agent orchestration for e-commerce operations
- Sectors: operations, marketing, finance, logistics
- What it is: Coordinated agents for product launch plans, cross-border compliance, pricing experiments, ad budget allocation, and inventory control with long-horizon planning.
- Tools/products/workflows: Orchestration frameworks; shared memory/blackboards; governance for decision rights; simulation-before-deploy.
- Assumptions/dependencies: Reliable tool APIs; strong auditability; clear human-in-the-loop escalation for high-risk moves.
- Predictive and decision-oriented benchmark expansion
- Sectors: strategy, finance, merchandising
- What it is: Extend EcomBench beyond verifiable fact Q&A into forecasting (demand, pricing elasticity), scenario planning, and A/B policy impact analysis.
- Tools/products/workflows: Ground-truth curation for time-based labels; backtesting harnesses; causal evaluation methods.
- Assumptions/dependencies: Access to historical/market data; robust leakage controls; agreed evaluation windows and metrics.
- Policy sandboxing and ex-ante impact testing
- Sectors: regulators, industry associations
- What it is: Use benchmark-like tasks to simulate upcoming regulatory changes (e.g., tax thresholds, return policies) and quantify agent readiness and merchant impact.
- Tools/products/workflows: Synthetic-but-realistic scenarios; stakeholder consultation dashboards; “readiness scores” by sector/region.
- Assumptions/dependencies: Cooperation with regulators; up-to-date policy drafts; validation against real outcomes post-implementation.
- Benchmark-driven agent marketplaces and procurement hubs
- Sectors: software marketplaces, procurement
- What it is: Public hubs where agents list certified scores by category/level and regions supported, enabling buyers to match needs to proven capabilities.
- Tools/products/workflows: Standardized score cards; API-based proofs; renewal schedules tied to quarterly updates.
- Assumptions/dependencies: Trusted maintainers; anti-gaming mechanisms; interoperability standards.
- Multilingual and multi-jurisdictional expansion
- Sectors: global commerce, localization providers
- What it is: Extend tasks across languages and regional rules (non-English ecosystems), ensuring localized compliance and accuracy.
- Tools/products/workflows: Regional expert networks; locale-specific tool plugins; translation + legal alignment checks.
- Assumptions/dependencies: Regional expert availability; continuous policy tracking; culturally appropriate guidance.
- Robustness, safety, and fairness suites for economic impact
- Sectors: AI safety, governance, responsible AI
- What it is: Add stress tests for conflicting sources, adversarial prompts, cost-sensitive errors, and fairness across seller sizes/types to quantify real economic risks.
- Tools/products/workflows: Cost-weighted scoring; counterfactuals; “safe fail” playbooks and escalation protocols.
- Assumptions/dependencies: Consensus on risk metrics; access to realistic adversarial data; independent audits.
Notes on Cross-Cutting Assumptions and Dependencies
- Data freshness: Many tasks rely on current regulations, tax rates, customs thresholds, or market conditions; pipelines must regularly refresh sources.
- Verifiability and judging: LLM-based judges should be calibrated and periodically audited with human evaluation to mitigate false scoring and reward hacking.
- Tool quality: High-level tools (e.g., VAT/duty/EIRP calculators, trend analyzers) require authoritative data, versioning, and transparent logic.
- Legal and ethical considerations: Compliance assistants must include disclaimers, human escalation paths, and jurisdiction-specific guidance; logging and auditability are essential.
- Domain expert availability: Human-in-the-loop curation and quarterly updates depend on expert time and budget.
- Generalization vs overfitting: Use held-out updates and anti-contamination practices to ensure benchmarks remain meaningful as training data evolves.
Collections
Sign up for free to add this paper to one or more collections.