- The paper introduces a model space redesign that consolidates overlapping domains and objectives to reduce model count and optimize infrastructure for ads recommendations.
- It leverages unified data integration, Pareto-based feature selection, and cross-modal neural architectures to enhance scalability and training stability.
- Hierarchical distillation combined with hardware-aware optimizations yields measurable improvements in efficiency, revenue-driving metrics, and capacity savings.
Introduction
Meta Lattice introduces a comprehensive, production-proven methodology for cost-effective, industry-scale ads recommendation. The framework's core insight is that the deployment constraints, data fragmentation, and infrastructure costs endemic to large-scale recommender systems must be tackled together via fundamental “model space redesign”—functionally unifying multiple domains, objectives, and data modalities into consolidated models and model workflows. Lattice extends the Multi-Domain, Multi-Objective (MDMO) paradigm by introducing novel solutions for portfolio consolidation, cross-domain data integration, model unification, hierarchical distillation, and system-centric efficiency optimization.
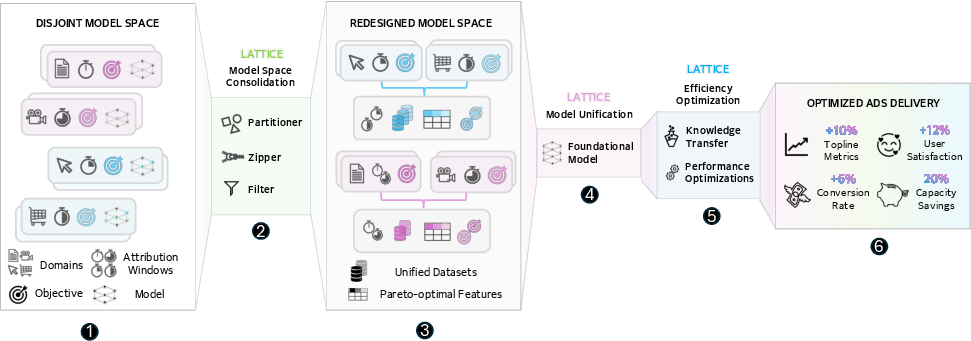
Figure 1: Lattice overview: heterogeneous datasets and windows are consolidated, features selected for Pareto-optimality, and all operations are unified in MDMO architectures distilled for efficient user-serving deployment.
Model Space Redesign through Portfolio Consolidation
Lattice generalizes MDMO by combining related domain-objective pairs (“portfolios”) into unified, efficiently deployable model groups. It addresses three primary bottlenecks prevalent in industry-scale settings:
- Economic Scalability: Reducing the number of required models by consolidating overlapping domains and objectives, optimizing overall infrastructure utilization.
- Data Fragmentation: Sharing and integrating datasets enables better inductive transfer; unified models learn from richer cross-domain interactions.
- Deployment Constraints: Real-time performance is maintained through hierarchical teacher-student deployment, leveraging distillation to decouple offline foundation model capacity from online serving latency.
Portfolio consolidation policies leverage user/item ID space overlap, feedback characteristics, and privacy/compute constraints, employing similarity metrics, empirical loss weighting, and resource allocation to optimally group and organize model space. Parameter untying and architectural disambiguation are applied to mitigate domain conflict.
Data Integration and Optimal Feature Selection
Lattice constructs unified datasets by concatenating multi-domain records and zero-padding missing features, homogenizing input spaces. For the delayed feedback intrinsic to ads, attribution window heterogeneity is tackled by probabilistically assigning impressions to distinct supervision windows (“Mixing Attribution Windows”), concurrently training multiple prediction heads per window. This sidesteps multi-pass instability and enables training data to span diverse freshness and completeness trade-offs.
Feature selection is recast as a multi-objective Pareto optimization, with relevance scores computed per portfolio. The algorithm iteratively selects features on the Pareto front—ensuring no domain is penalized—until a resource-constrained feature budget is met. This supports balanced task performance despite heterogeneous upstream data and business priorities.
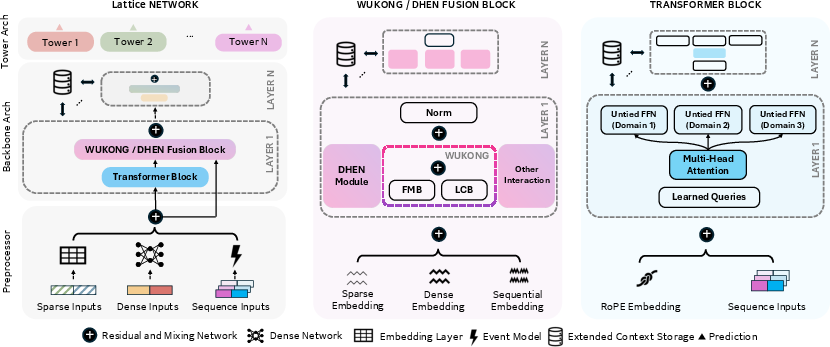
Figure 2: Unified architecture interleaving sequence and non-sequence learning modules enables handling heterogeneous domain inputs.
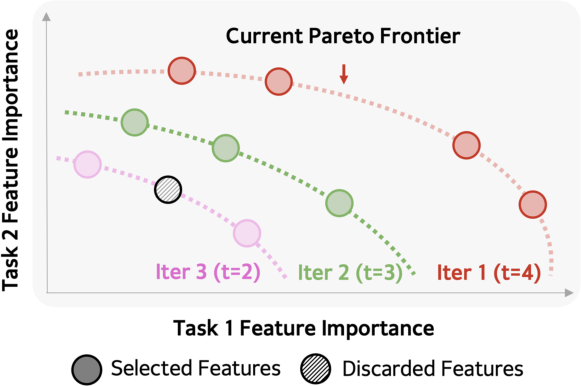
Figure 3: Iterative Pareto feature selection with T=9 out of ∣F∣=10 is visualized; early iterations extract features benefiting all portfolios.
Model Unification: Heterogeneous Multi-Modality Learning
Each consolidated portfolio leverages a unified neural architecture capable of ingesting mixed-format data: categorical, dense, and sequence features. The model design employs three-staged preprocessor-backbone-task modules:
- Feature Processors: Project categorical/dense/sequence modalities into a shared embedding space.
- Backbone: Interleaves transformers (with RoPE, context storage, cross-attention modules) and Wukong/DHEN-style interaction blocks to facilitate cross-modal and cross-domain feature fusion.
- Task Modules: Task-specific heads, combined with parameter untying for domain separation, enable unbiased specialization post-shared representation learning.
Architectural adaptations reinforce training stability: QK-norm for modality contention, bias elimination and Swish-RMSNorm for low-precision friendliness, and a cross-domain correlation loss for task alignment. MetaBalance is employed for gradient reweighting across objectives to counteract training instability.
Hierarchical Distillation and Knowledge Transfer
To maximize quality under deployment constraints, large teacher (“foundational”) models operate asynchronously, precomputing user-item embeddings stored with short TTL. At both training and inference, lightweight online models retrieve these embeddings or teacher logits, using them as enriched input features and distillation targets. This “inference-time knowledge transfer” presents a crucial extension over standard (training-only) distillation approaches by persistently augmenting student models with up-to-date teacher state, resulting in significant gain in knowledge transfer ratio and online model quality.
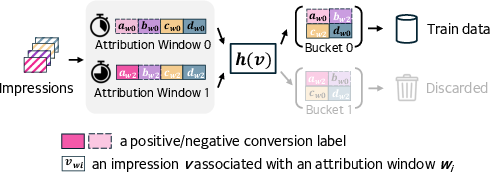
Figure 4: K=2 attribution windows for 4 impressions visualized, supporting consistent knowledge transfer via delayed supervision.
System and Hardware-Driven Efficiency Optimizations
Lattice achieves substantial cost reductions via several hardware-aware strategies:
- Distributed Training: Hybrid parallelism with TorchRec (embedding sharding), FSDP (dense synchronization), DDP, and FP8/BF16/FP32 mixed precision are tightly integrated. Row/tensor scaling and custom FBGEMM kernels underpin high-throughput training and inference.
- Model Search & Execution Optimization: An iterative search framework dynamically explores FSDP sharding and model hyperparameters (batch, embedding size, layer width), guided by scaling laws that predict quality/complexity trade-offs. Beam/Bayesian optimization, dynamic programming, and scaling-aware objective re-ranking identify near-optimal throughput-quality trade-offs, with iterative refinements yielding up to 20% throughput improvements on 128 A100 GPUs.
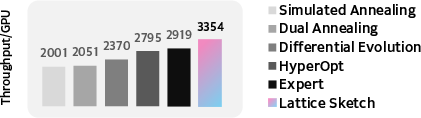
Figure 5: Lattice's execution optimizer yields 20% throughput improvement over expert-tuned Wukong baseline on 128 A100 GPUs.
Figure 6: Iterative refinement yields sustained hardware throughput improvements.
Empirical Results and Industrial Impact
Extensive experiments on public (KuaiVideo) and Meta internal datasets demonstrate that Lattice outperforms 10 strong baselines, achieving:
- Up to 1% relative loss reduction on billion-scale datasets (significant at Meta’s production scale).
- 20% capacity savings via portfolio/model count reduction and compute sharing.
- 10% improvement in revenue-driving top-line metrics, 11.5% in ads quality, and 6% in conversions upon deployment to Meta ads systems.
For ablation, contributions to the top-line gain are disaggregated: portfolio consolidation (36%), data integration (11%), model unification (13%), efficiency optimization (23%), and knowledge transfer (17%).
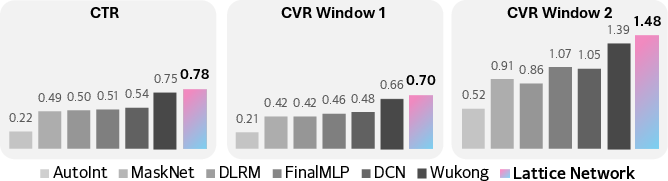
Figure 7: Relative loss improvement over AFN on large-scale industry datasets confirming the superiority of Lattice.
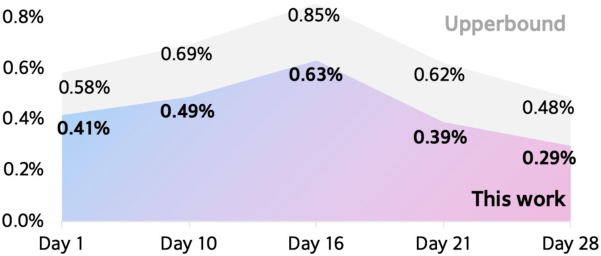
Figure 8: Consistent loss improvements across a month, compared with the upper bound provided by idealized label availability.
Implications and Future Directions
Lattice demonstrates that holistic “model space redesign,” merging multiple innovations in portfolio consolidation, data curation, and unified architecture, is a feasible solution for scalable industrial recommendation. Its design enables the transition from domain/objective-siloed learning to cross-domain representation, unlocking scaling law benefits in regimes previously limited by cost and latency. The hierarchical knowledge transfer and system-hardware co-design are critical for maintaining quality-efficiency balance.
Areas for future exploration include:
- Automated, continual portfolio optimality under non-stationary domain/usage dynamics.
- End-to-end integration with generative recsys models, multimodal/foundation pretraining, and self-adaptive model maintenance under feedback delays.
- Further reducing human intervention in sharding/model search via meta-learning and more aggressive scaling law exploitation.
Conclusion
Meta Lattice operationalizes a paradigm shift in recommender system engineering for industrial ads ecosystems, showing that with deliberate consolidation of domain-objective space, integrated data and model workflows, and hardware-software co-design, it is possible to achieve step-function improvements in both efficacy and cost-efficiency. This framework sets a new standard for systematic recommendation model deployment at extreme scale, with immediate applicability to any environment facing high-dimensional, heterogeneous, and latency-constrained recsys workloads (2512.09200).