- The paper presents VCM and FCM protocols that rethink traditional video coding by emphasizing machine-consumable features for AI inference.
- It employs temporal and spatial resampling alongside feature tensor compression, achieving up to 97% bandwidth savings in object detection and tracking tasks.
- Experimental results indicate that FCM can outperform edge inference with negligible codec impact, supporting privacy-preserving and scalable distributed AI.
Emerging Standards for Machine-to-Machine Video Coding
Introduction
The paradigm shift from human-centric to machine-centric consumption of visual content has prompted the development of specialized video coding standards that optimize representations for downstream AI tasks rather than human perception. This essay provides a detailed summary and analysis of "Emerging Standards for Machine-to-Machine Video Coding" (2512.10230), which overviews the design, operational principles, and empirical evaluation of MPEG's Video Coding for Machines (VCM) and Feature Coding for Machines (FCM) standards. The discussion encompasses the technical core of each standard, a comparative experimental analysis, and a critical examination of codec choices in the context of intermediate neural feature transmission.
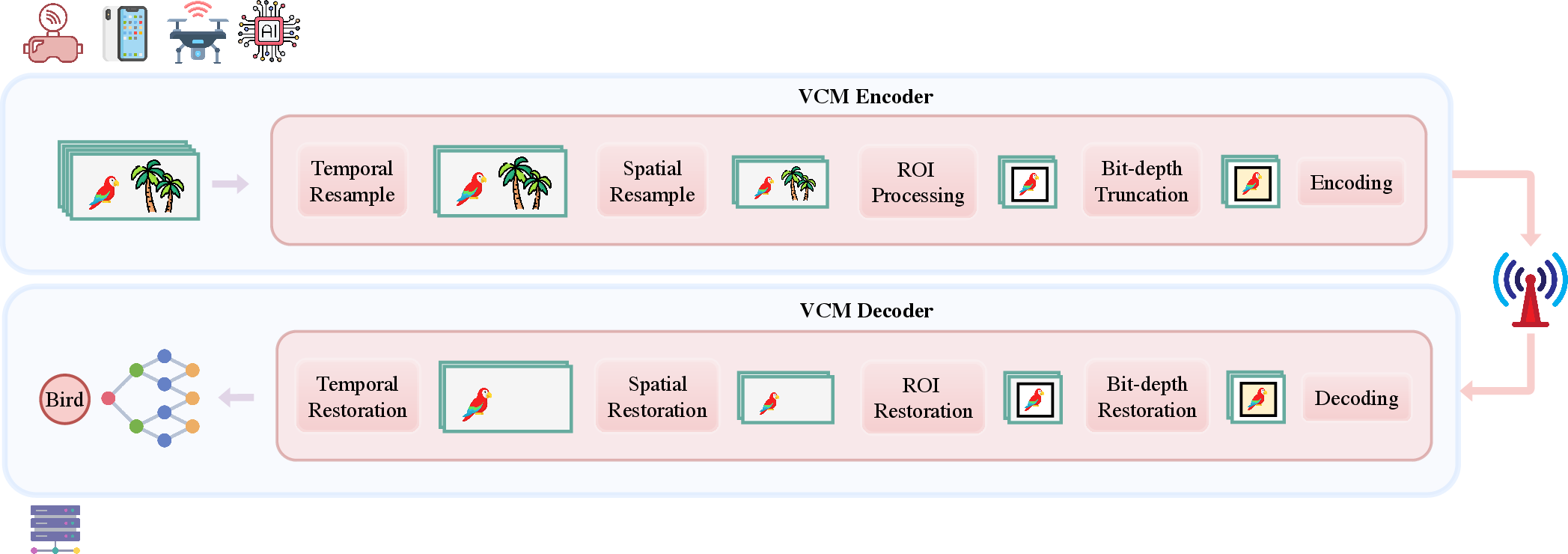
Figure 1: Overview of Video Coding for Machines (VCM).
Video Coding for Machines (VCM): Pixel Domain, Task-Optimized Video Coding
VCM rethinks conventional video compression pipelines for the context of automated inference rather than subjective visual quality. The coding framework integrates a suite of pre-processing tools to prioritize information relevant to downstream tasks—such as object detection and tracking—before lossy compression with a standard video codec.
- Temporal Resampling aggressively prunes frames with redundant semantic content based on analysis of inter-frame object similarity (IoU-based tracking), adaptive scene dynamics, or deterministic frame dropping. The intent is to minimize temporal redundancy while preserving critical cues.
- Spatial Resampling dynamically adjusts resolution using Object Occupancy Distribution metrics, eschewing unnecessary pixel density in spatial regions with low task-related information.
- Region of Interest (ROI) Processing focuses the bit budget on semantically critical regions via ROI extraction, margin-dilation, merging, and temporal stability enforcement, typically suppressing background detail.
- Bit-depth Truncation systematically reduces sample precision, leveraging the observed robustness of inference models to quantization—thus cutting bitrate with limited accuracy loss.
Restoration modules ensure the reversibility of pre-processing prior to consumption by DNN-based inference models. This architecture aligns the bitrate allocation with task saliency, offering substantial bandwidth reduction relative to streaming uncompressed video.
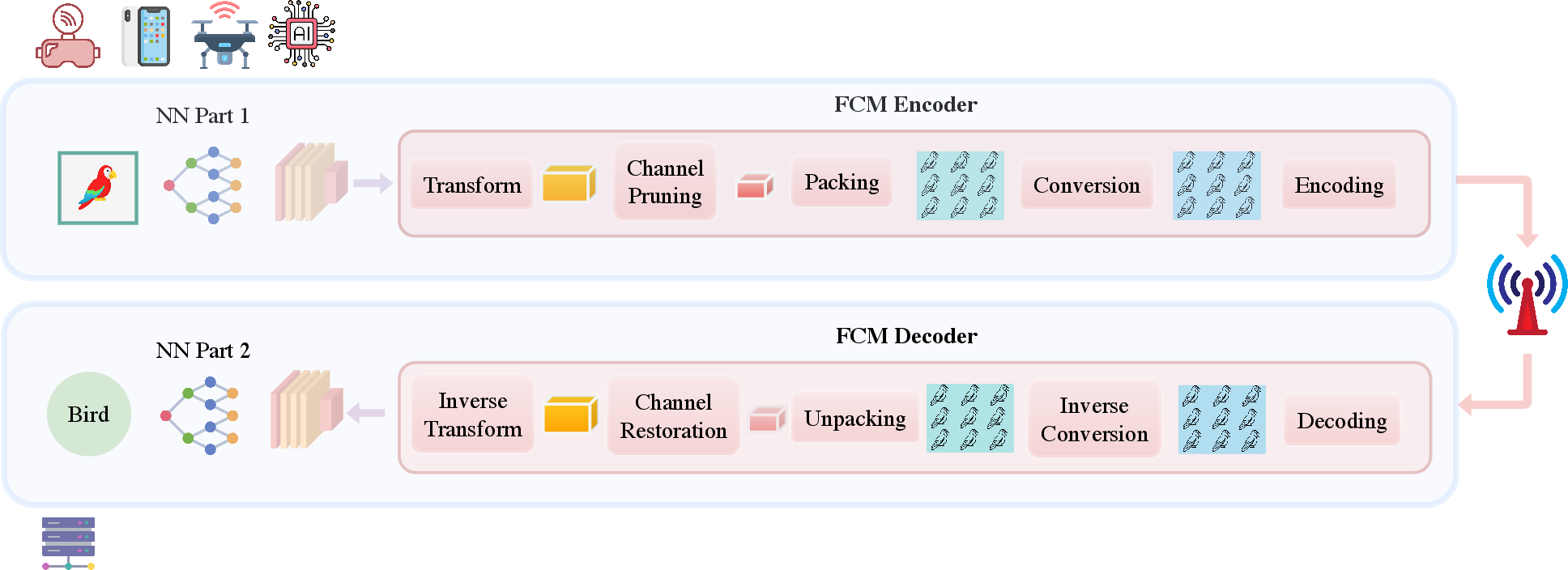
Figure 2: Overview of Feature Coding for Machines (FCM).
Feature Coding for Machines (FCM): Distributed Inference via Feature Domain Compression
FCM leverages a split-inference paradigm, partitioning the neural network between edge and server such that only intermediate feature tensors are transmitted. This substantially reduces bandwidth, preserves privacy, and offloads initial computation to edge devices, capitalizing on their limited compute resources and often otherwise unused NPUs.
Key FCM Processing Steps
- Learned Transform applies dimensionality reduction to the high-dimensional intermediate feature tensor Xt, also transmitting global statistics (mean μ, std σ) necessary for precise feature reconstruction post-decoding.
- Channel Pruning eliminates redundant channels, relying on content-dependent heuristics, with signaling of pruned indices using an efficient Lexicographic Combinatorial Rank (LCR) encoding.
- Packing/Conversion arranges the pruned tensor as a conventional image and quantizes floating-point values to fixed-bit depth, transmitting encoder-side statistics for accurate post-decompression normalization.
- Conventional Codec Compression uses a standard video or image codec (e.g., AVC, HEVC, VVC) to compress the feature frame and side information.
- Statistical Refinement and Unpacking at the decoder restores the feature tensor's global distribution and structure using the transmitted statistics and indices, achieving minimal distribution shift before inverse transformation.
- Channel Restoration and Inverse Transform fill pruned channels and map the refined reduced tensor back to the original multi-scale feature space, reconstructing inputs for server-side inference.
This pipeline ensures that features transmitted for collaborative intelligence are privacy-preserving (non-reconstructable to the raw image), highly compressed, and maintain high downstream task fidelity.
Experimental Results and Comparative Analysis
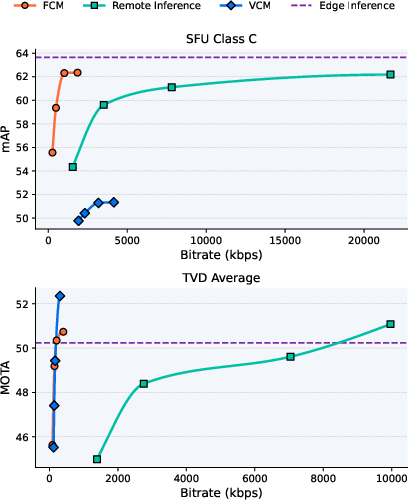
Figure 3: Rate-accuracy comparison of VCM, FCM, edge inference, and remote inference on SFU Class C and TVD Average.
In the experimental protocol, VCM and FCM are benchmarked alongside edge and remote inference baselines for object detection (SFU dataset, mAP metric) and object tracking (TVD, MOTA metric). FCM consistently approaches or even marginally outperforms edge inference at a dramatically lower bitrate—achieving near-full mAP at 90–95% bitrate reduction over remote inference, and >97% bandwidth savings in tracking scenarios.
VCM, while reducing bitrate relative to uncompressed remote inference, saturates in performance at higher bitrates and underperforms FCM in the low to medium bitrate operational regime, especially for object detection. Interestingly, both FCM and VCM can marginally surpass edge inference accuracy at high bitrates, potentially due to implicit regularization or denoising from compression artifacts.
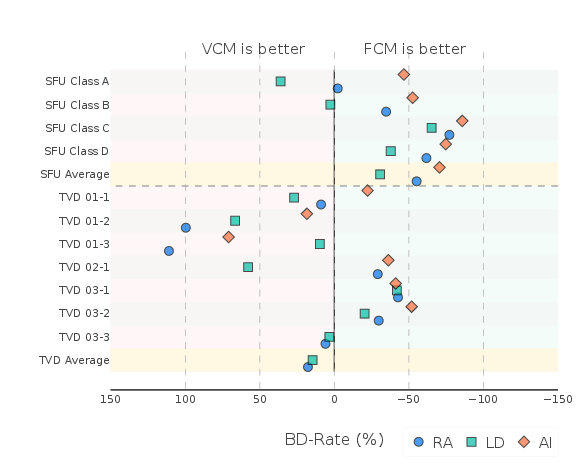
Figure 4: BD-Rate results of FCM with respect to the VCM anchor under the VCM Common Test Conditions (CTC); negative values indicate FCM's bandwidth savings.
BD-Rate (Bjontegaard Delta Rate) results further quantify FCM's advantage: on object detection tasks, FCM provides an average BD-Rate savings of −55.21% (RA), −30.73% (LD), and −70.54% (AI) compared to VCM, reflecting over 50% reduction in bandwidth at equivalent performance. In tracking, FCM's efficiency is more sequence-dependent, with mean BD-Rate deltas sometimes positive due to task-specific data distributions, but it remains competitive overall.
Codec Choice in Feature Coding: VVC, HEVC, and AVC
A critical aspect of FCM deployment is the selection of the internal video codec. The analysis reveals that replacing VVC (H.266) with HEVC (H.265) engenders negligible task performance degradation—only 1.39% BD-Rate increase on average—whereas using AVC (H.264) incurs a substantially higher BD-Rate penalty (32.28%). For the tracking task, codec choice is even less consequential, with HEVC slightly outperforming VVC and AVC maintaining moderate degradation. Consequently, deployment on legacy hardware with HEVC support is essentially consequence-free in the context of feature-domain machine-to-machine communication.
Practical and Theoretical Implications
Adoption of VCM/FCM standards impacts not only raw bandwidth efficiency and infrastructure cost but also privacy, scalability, and edge-cloud device orchestration. By shifting toward intermediate feature transmission, FCM decouples system design from human-perceptual optimization, supports federated and collaborative intelligence, and offers improved privacy through irreversibility. The findings on codec invariance suggest a migration pathway utilizing existing hardware for immediate benefits, rather than waiting for full VVC ecosystem enablement.
Theoretically, FCM's explicit consideration of feature distribution alignment (statistical refinement before and after compression) codifies best practices for high-fidelity distributed inference. The efficiency gains and robustness to codec architecture indicate that feature compression—paired with accurate side metadata—is a viable path to near-lossless collaborative inference.
Future Directions
Continued research should focus on achieving absolute task-level near-lossless transmission (sub-1% mAP/MOTA drop relative to edge inference), refining transform and pruning methods for broader generalizability, and algorithm-hardware co-design for next-generation distributed AI workloads. This includes adaptive layer splitting, end-to-end trainable coding pipelines, and use-case specific privacy/compression trade-off characterization. The interaction between compression-induced perturbations and task robustness requires deeper study, especially for critical applications where minimal accuracy decrease cannot be tolerated.
Conclusion
The transition to VCM and FCM standards marks a substantial progression in the ecosystem of machine-to-machine visual communication. Empirical evidence demonstrates strong bitrate savings for FCM, with negligible or minimal impact from codec selection, reinforcing the deployability of feature coding solutions within current and future hardware. As machine vision continues to supplant human observers as the primary consumer of image/video data, the continued refinement of these coding standards is essential for efficient, scalable, and privacy-conscious AI deployment.