- The paper introduces the STAR framework that interleaves spatial and temporal tools to enhance precision in video question answering tasks.
- It leverages a diverse toolkit of 22 plug-and-play modules for object detection, frame selection, and action localization to boost efficiency.
- Empirical results show significant accuracy improvements and reduced computational costs across benchmarks like VideoMME and LongVideoBench.
Motivation and Problem Setting
Video Question Answering (VideoQA) demands integrated modeling of spatial contexts and temporal dynamics, challenging the capacity of Multimodal LLMs (MLLMs) to perform high-fidelity perception and reasoning across space and time. Existing Video-LLMs demonstrate limitations in computational efficiency and depth of reasoning due to process redundancy and weak spatiotemporal disentanglement. Tool-augmented LLMs, despite mitigating parametric limitations via specialized tools, commonly suffer from unidimensional tool use, reduced diversity, and disordered scheduling, resulting in reduced accuracy and efficiency in complex VideoQA tasks.
The proposed Video Toolkit is structured into three orthogonal tool types: spatial, temporal, and general-purpose. The toolkit encapsulates 22 functionally diverse, plug-and-play modules. Spatial tools focus on tasks like object detection, image captioning, and region-of-interest manipulation, while temporal tools handle frame selection, temporal grounding, and action localization. The inclusion of tools such as object detectors (YOLO, Grounding DINO) and frame selectors (e.g., A∗-based, grid-based methods) is critical for fine-grained localization and filtering in both domains. Tool invocation is standardized via tool cards, ensuring extensibility and unified access protocols.
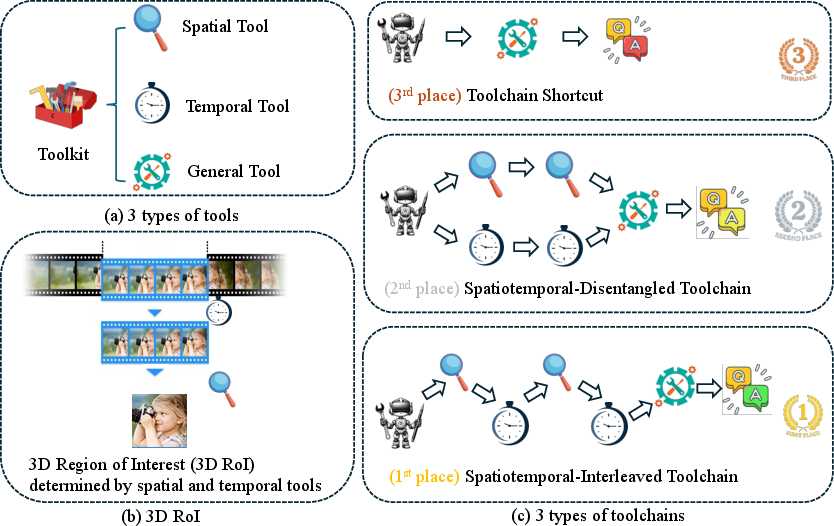
Figure 1: Toolkit categorization and comparison of toolchain scheduling strategies; spatiotemporal-interleaved toolchains achieve superior accuracy and frame efficiency due to progressive 3D RoI localization.
The toolkit supports integration of structured outputs (e.g., bounding boxes, captions) with LLM planners via natural language interfaces, enabling seamless information transfer and compositional reasoning.
STAR: Spatiotemporal Reasoning Framework
To address tool invocation and reasoning limitations, the SpatioTemporal Reasoning (STAR) Framework is introduced. STAR enforces an alternating scheduling constraint: temporal and spatial tools must be invoked in an interleaved fashion, preventing toolchain shortcut behaviors and promoting deep, multi-step reasoning. The toolchain adapts dynamically to question intent, video content, and context length, with progressiveness ensured through iterative frame expansion and 3D Region-of-Interest (3D RoI) localization.
STAR maintains a Visible Frame Dictionary, mediating information flows and facilitating iterated, bidirectional narrowing of search space in both time and space. The core LLM Planner autonomously selects tools, conditional on prior results, with general-purpose tools reserved for fallback when specialized modules are exhausted.

Figure 2: Visualization of the Video Toolkit, tool cards, visible frame dictionary, and demonstration of the STAR pipeline, highlighting sequential tool invocations by the LLM planner for complex VideoQA problems.
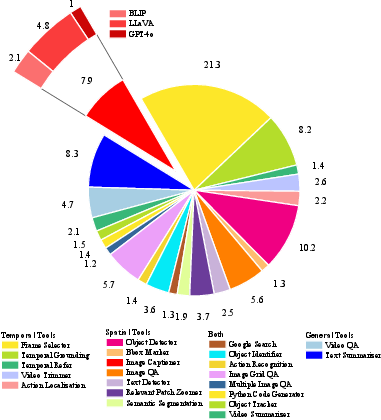
Figure 3: STAR algorithmic flow, showcasing alternating spatial and temporal tool invocations progressively focusing on the answer-relevant 3D RoI.
Experimental Results and Empirical Insights
Evaluation across multiple benchmarks (VideoMME, LongVideoBench, NExT-QA, EgoSchema) demonstrates that STAR-enhanced GPT-4o yields significant gains at fixed input budgets. On VideoMME, STAR produces an 8.2% absolute accuracy improvement over GPT-4o, outperforming all open-source Video-LLMs at or below the 8B scale and approaching the 72B class (Table and results referenced in the paper). On LongVideoBench, STAR yields a 4.6% gain and demonstrates superior robustness on long-form/needle-in-haystack queries. STAR also exhibits strong sample efficiency, reducing mean frames processed and decreasing computational cost by an order of magnitude over baseline methods.
Ablation studies reveal:
- No Constraint and naively prompted toolchains result in short, low-diversity chains, high redundancy, and reduced efficiency.
- Star interleaving constraint produces longer, more diverse operations and a balanced tool usage distribution.
- All tool categories contribute positively to accuracy and efficiency, with frame selector and object detector showing largest impact.
See also empirical case visualizations:
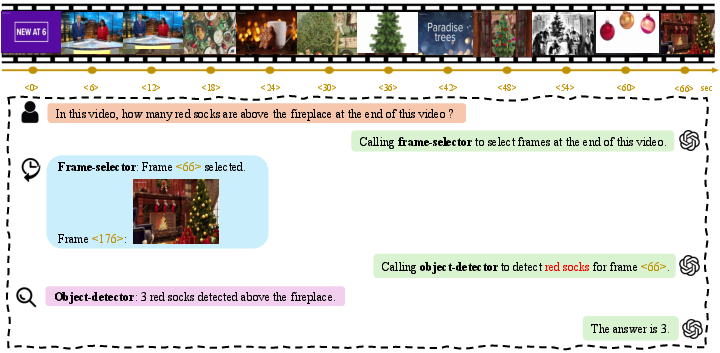
Figure 4: Example of a counting problem from VideoMME, resolved via cascade of frame selection and object detection.
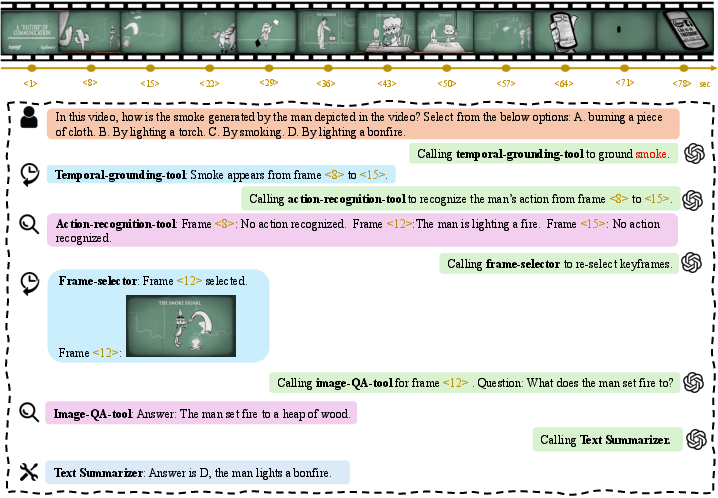
Figure 5: Action recognition example, solved by temporal navigation followed by fine-grained action localization.
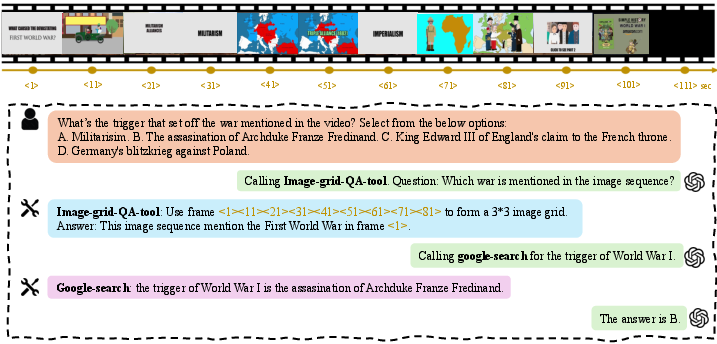
Figure 6: Action reasoning problem that requires interplay between sequence understanding and spatial reasoning tools.
Theoretical Implications and Limitations
Progressive 3D RoI localization through spatiotemporal interleaving mitigates MLLM parametric limitations by externalizing nonparametric, specialized reasoning. The STAR approach effectively operationalizes deliberate visual thinking strategies analogous to chain-of-thought techniques in LLMs, but in the visual domain. The framework uncovers the bottlenecks of MLLM architectures on synthetically long, complex, and temporally entangled queries, and provides a pathway for compositional, explicit reasoning in high-dimensional video spaces.
Current limitations include reliance on proprietary LLMs (e.g., GPT-4o) for the planner and dependence on external API latency/cost. STAR does not yet natively process multimodal cues such as audio, subtitles, or global event context, which remain as avenues for future extension.
Conclusions and Outlook
The STAR framework demonstrates consistent, robust improvements across challenging VideoQA tasks by combining explicit spatiotemporal tool scheduling with adaptive, multi-step LLM planning. This architecture both enhances answer accuracy and reduces computational overhead, suggesting that composable, tool-augmented strategies are crucial for next-generation video understanding agents.
Future research directions include integrating lightweight open-source planners, extending the toolkit to cover audio/speech and narrative modalities, and formalizing compositional abstraction hierarchies for complex event reasoning. The methods presented lay the foundation for more autonomous, accurate, and computationally efficient video analysis systems adaptable to real-world, multi-scale tasks.
Reference: "Tool-Augmented Spatiotemporal Reasoning for Streamlining Video Question Answering Task" (2512.10359)