- The paper introduces the P2S framework with an Adaptive Span Generator that efficiently narrows the temporal search space in hour-long videos.
- It employs LLM-driven query decomposition with dual evidence channels to accurately align query semantics with video content.
- Empirical results demonstrate that P2S outperforms both supervised and other zero-shot methods, achieving up to 2.4x higher accuracy.
Zero-Shot Long Video Moment Retrieval via Adaptive Point-to-Span Modeling
Problem Setting and Motivation
Zero-shot Long Video Moment Retrieval (ZLVMR) as formulated in "Point to Span: Zero-Shot Moment Retrieval for Navigating Unseen Hour-Long Videos" (2512.10363), seeks to temporally localize events in hour-long, highly variable videos based on natural language queries, without any dataset- or task-specific training. The exponential scaling of the temporal search space in long videos imposes severe computational and semantic limitations, which render both the supervised and prior zero-shot approaches ineffective or infeasible in practical regimes.
The prevailing paradigm in long video retrieval decomposes the problem into a “Search-then-Refine” scheme: a coarse search for candidate segments, followed by expensive multi-modal refinement. However, supervised models overfit and cannot generalize to out-of-distribution queries or datasets typical of real-world applications (Figure 1).
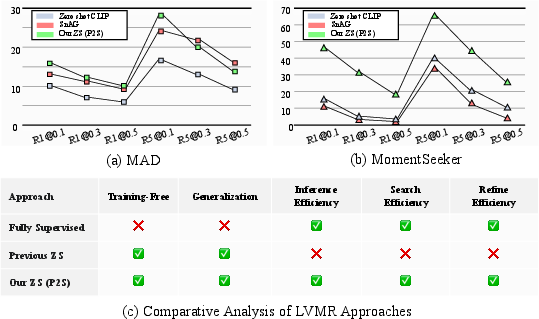
Figure 1: Comparison of zero-shot P2S with recent supervised and zero-shot baselines on in- and out-of-distribution data, highlighting significant generalization and efficiency gains.
Search Phase: Temporal Search Space Saturation
In very long videos, conventional zero-shot methods employing uniform candidate proposal or exhaustive sliding window strategies result in temporal search space saturation: an overwhelming number of spurious candidate segments, dominated by false positives, and overwhelming the subsequent refinement phase (Figure 2).
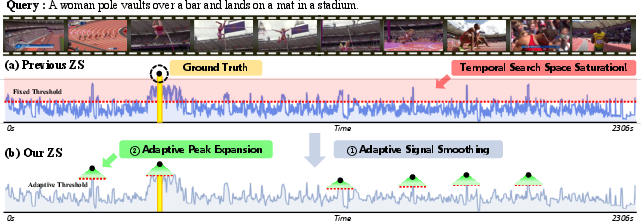
Figure 2: Scaling search strategies for long-form videos leads to an explosion of candidate windows, neutralizing the utility of the search step. P2S restricts candidates to robust similarity regions.
This saturation — catastrophic in the hour-long regime — both imposes heavy computational burden and increases susceptibility to semantic discrepancies, especially since evidence for nuanced queries may occur sparsely or be fragmented.
Point-to-Span (P2S): Methodological Contributions
The P2S framework sidesteps both supervised overfitting and search space saturation through two principal technical advances: the Adaptive Span Generator (ASG) and Query Decomposition with evidence-driven Proposal Refinement. The complete system is illustrated in Figure 3.
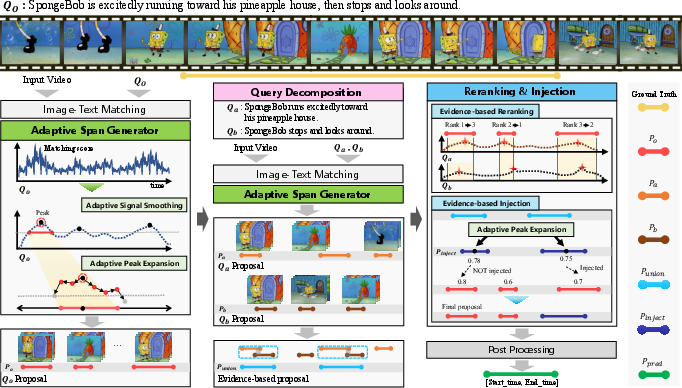
Figure 3: P2S architecture – adaptively generates candidate spans, semantically decomposes queries, and governs proposal refinement using distributed evidence across sub-events.
Adaptive Span Generator
The ASG sequentially (1) computes a similarity signal between the input video and query via pre-trained vision-LLMs such as CLIP, (2) adaptively smooths the signal to account for video-specific noise statistics, and (3) adaptively expands from statistically significant peaks to generate candidate spans.
By setting adaptive thresholds and expansion parameters as a function of signal statistics (rather than as fixed hyperparameters), P2S ensures candidate compactness and robustness over extreme variability in length, content, and format. Empirical comparison confirms that ASG yields stable, competitive performance without expensive parameter re-tuning across datasets, whereas fixed-parameterized baselines show significant failure in cross-domain deployment (Figure 4).
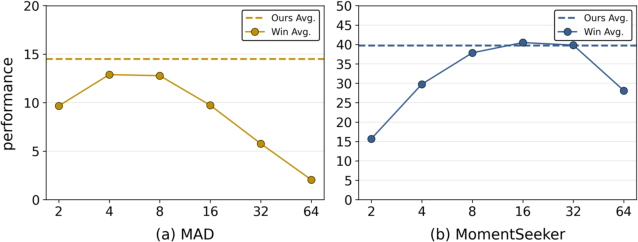
Figure 4: Adaptive span generation is robust to window size, unlike fixed-window baselines which are highly fragile and require dataset-specific tuning.
Query Decomposition and Evidence Channels
A core innovation is the LLM-driven semantic decomposition of the natural language query Qo into temporally ordered sub-queries (Qa, Qb), each capturing structured evidence aligned with start/end event states (Figure 5). This step is carefully engineered to preserve semantic integrity and avoid hallucination via rule-based prompting and atomic-action disentanglement.

Figure 5: Sub-queries localize start/end boundaries and serve as independent evidence channels for semantic span refinement.
Each sub-query is then aligned with the video to provide additional, contextually distinct “evidence channels” (Sa, Sb), which in conjunction with the original similarity signal are leveraged to rectify misalignment (semantic discrepancy) between peak similarity regions and the ground-truth event boundaries.
Evidence-based Proposal Refinement
This dual-evidence mechanism governs two steps: reranking of initial candidates via summation of peak evidence scores from Sa and Sb, and evidence-union-driven “injection” of missed event intervals — whereby candidate windows provably supported across evidence channels and not surfaced by the initial search are dynamically discovered and promoted. This rerank-and-inject procedure mitigates both precision and recall loss due to the limitations of CLIP-like representations in capturing multi-faceted, compositional semantics (Figure 6).

Figure 6: Qualitative examples: (a) Reranking by evidence signals sharpens the event boundary; (b) Injection recovers missed moments.
Empirical Results and Analysis
P2S is evaluated on MAD and MomentSeeker, long-form video retrieval benchmarks with extreme challenges: low moment-to-video ratios, diverse content, and unseen query styles. On MAD, P2S matches or marginally exceeds supervised SOTA methods (e.g., RevisionLLM), despite not utilizing any training or annotation; on MomentSeeker — where the data is out-of-domain or scarce — P2S exhibits a dramatic advantage, with up to 2.4x higher average accuracy relative to strong supervised and zero-shot competitors. The framework also outperforms alternative proposals for query decomposition, including naive splits and delimiter heuristics, and generalizes across LLM architectures and parameter scales with negligible variance (<0.5%).
Ablation studies confirm (1) the essentiality of adaptive mechanisms for robust search and (2) the complementary gains from dual evidence refinement modules. Queries that require compositional understanding are localized with higher precision and recall due to sub-query evidence aggregation, as shown both qualitatively and quantitatively.
Computational and Practical Considerations
The P2S system is efficient: all critical steps except query decomposition scale linearly with video length, and the LLM-based decomposition incurs a fixed, small latency (∼0.5s/query) decoupled from video duration. Proposal refinement via operations on similarity matrices is lightweight relative to model forward passes in prior pipelines. The overall method processes hour-long videos in under a second per query, making it viable for real-world applications (see runtime breakdown table in the paper).
Qualitative illustrations demonstrate P2S’s ability to disambiguate complex, multi-step events, resolve signal ambiguity, and suppress massive background context in genuinely long sequences (Figure 7).

Figure 7: (a) Compositional query decomposition allows precise moment reconstruction; (b) Adaptive search filters background to target rare, short actions in extremely long videos.
Theoretical and Practical Implications
P2S establishes a new meta-architecture for zero-shot video retrieval that is (1) training-free, (2) robust to broad shifts in video domain, length, and query compositionality, and (3) computationally efficient at scale. It demonstrates that task-specific training or large-scale, costly supervised collection is not a requirement for high-precision, scalable temporal grounding. The methodology further generalizes: distributed evidence-driven refinement, adaptive Signal–Proposal coupling, and structured query decomposition constitute a framework extendable to other zero-shot event localization tasks and modalities.
Main outstanding challenges remain: P2S performance is ultimately bounded by pre-trained visual-text features (e.g., CLIP’s representational defects) and the one-off overhead of LLM query processing. Enhancements involve investigating end-to-end architectures with open-vocabulary visual features optimized for the long-horizon regime, or lightweight query transformers replacing LLMs while retaining semantic fluency and robustness.
Conclusion
The P2S zero-shot framework resolves the dual intractabilities of search space explosion and semantic discrepancy in hour-long video retrieval, without any task- or dataset-specific training. This is achieved by synergizing adaptive, stat-driven search and multi-channel evidence-based proposal refinement through robust query decomposition. The framework outperforms contemporary SOTA supervised and zero-shot models on both in- and out-of-domain benchmarks, with distinct computational and practical advantages. This work decisively shifts the paradigm toward data- and compute-efficient long-horizon video understanding, and motivates future exploration in foundation models and cascaded evidence reasoning architectures.