- The paper introduces CoherentGS, a framework combining deblurring and diffusion priors to achieve coherent 3D scene reconstruction from severely degraded inputs.
- The methodology fuses perceptual deblurring with diffusion-based geometric repair, using adaptive viewpoint selection to maintain cross-view consistency and eliminate artifacts.
- Experimental results validate that CoherentGS outperforms existing methods with improved PSNR, SSIM, and LPIPS metrics, especially in sparse view scenarios.
Coherent 3D Gaussian Splatting from Sparse and Motion-Blurred Views
Introduction and Motivation
Modern 3D Gaussian Splatting (3DGS) representations support highly efficient and expressive scene rendering, significantly advancing the capabilities of novel view synthesis (NVS). However, these models inherit severe fragilities under practical acquisition scenarios, particularly when the input is both sparse in viewpoint coverage and corrupted by non-negligible motion blur. This simultaneous sparsity and blur cause a compounded ill-posedness, manifesting as catastrophic view fragmentation and low-frequency geometric bias, which cannot be addressed by naïve extensions of existing 3DGS or NeRF deblurring pipelines.
The work "Breaking the Vicious Cycle: Coherent 3D Gaussian Splatting from Sparse and Motion-Blurred Views" (2512.10369) introduces the CoherentGS framework to directly address this intersectional challenge. The framework combines physically- and semantically-grounded priors, decoupling motion deblurring from generative geometric repair within a joint, consistency-aware optimization.
CoherentGS is predicated on an analysis demonstrating how existing 3DGS and deblur methods fall into weak local minima in this regime. When only a handful of blurry views are available, the representation degenerates to disjoint local clusters with pronounced low-frequency artifacts, rather than reconstructing a cohesive, structure-preserving 3D scene.
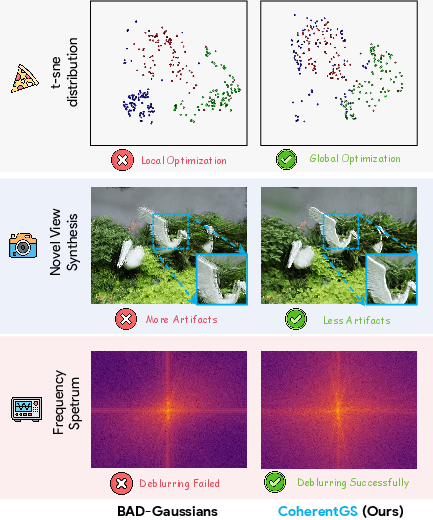
Figure 1: View fragmentation: NVS and t-SNE distributions with 3 input views show BAD-Gaussians collapse to local clusters, while CoherentGS maintains global geometric consistency.
Methodology
Dual Generative Priors: Deblurring and Diffusion
CoherentGS pivots away from single-prior methods by synergizing two distinct generative priors: a dedicated, pre-trained deblurring network (EVSSM) and a diffusion-based geometry completion model (Difix3D+). The deblurring prior is responsible for restoring high-frequency photometric detail lost to motion artifacts, while the diffusion prior provides geometric regularization and context-aware hallucination for unobserved viewpoints.
The deblurring module is not simply used for pixel-wise supervision. Instead, it operates as a perceptual teacher, distilling high-level feature information during training to the 3DGS model. This reduces overfitting to deblurring artifacts and maintains cross-view consistency of textures.
The diffusion prior is integrated via a score distillation-style approach, in which a reference-view conditioned denoising network acts as a single-step post-processor for intermediate 3DGS renders. Instead of direct pixel alignment, the resulting features are matched using a perceptual distance, with gradients blocked in the generative model, ensuring the 3DGS parameters are optimized to produce diffusion-coherent novel views.
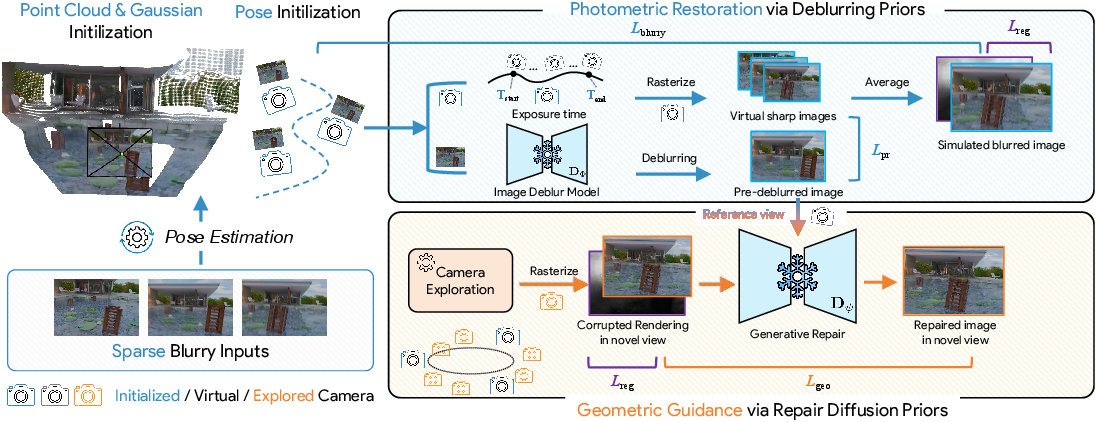
Figure 2: CoherentGS framework merging photometric restoration via deblurring priors and geometric correction with diffusion-based priors under the guidance of consistency metrics.
Consistency-Guided Camera Exploration
A critical innovation is the consistency-guided camera exploration module, which adaptively selects which unexplored viewpoints should be rendered and distilled for geometric repair. Traditional linear or elliptical interpolations either provide redundant, low-information guidance or lead to generative collapse by straying into insufficiently constrained image space regions. CoherentGS introduces Scene Adaptive Consistency Normalization (SACN): for each novel candidate pose, a per-scene normalized score quantifies the reliability of diffusion repair by assessing the deviation from training-view consistency. Only candidate viewpoints whose s~(T) fall in a well-calibrated band are included in the optimization.
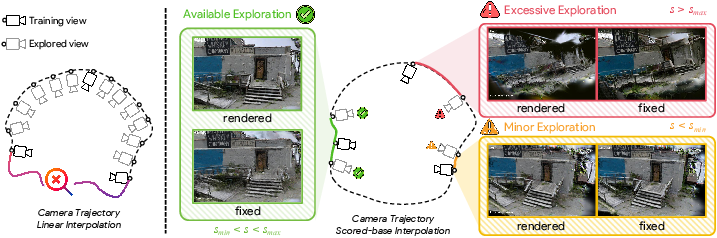
Figure 3: Comparison of trajectory sampling strategies: SACN outperforms linear and elliptical interpolation by maximizing geometric diversity without inducing unrecoverable hallucination.
Joint Photometric and Geometric Optimization
The CoherentGS training objective is a weighted sum comprising:
- Lblurry: Photorealistic reconstruction loss for synthesized blurry renders vs. observations, modeled with exposure-aware pose integration.
- Lpr: Perceptual distillation loss matching the 3DGS’s sharp output to feature representations from the EVSSM deblurring prior.
- Lgeo: Geometric consistency loss enforcing similarity to the denoised, reference-conditioned diffusion repair output.
- Lreg: Depth smoothness regularization in the sense of [regnerf], essential for suppressing floaters and promoting planar stability under ambiguity.
Warm-up strategies, in which the deblurring prior dominates early optimization before the generative prior is introduced, are critical for disentangling blur from semantic content.
Experimental Validation
Comparative Results
CoherentGS was validated on two benchmarks: the synthetic and real subsets of the Deblur-NeRF dataset and the proposed DL3DV-Blur dataset, designed to probe outdoor, large-scale, and unconstrained geometry under photorealistic blur synthesis. Experiments focus on the extreme regime of 3, 6, and 9 input views.

Figure 4: Qualitative NVS on Deblur-NeRF: CoherentGS achieves substantially superior detail and fidelity across all sparsity regimes.
For the most sparse regime (3 views), CoherentGS achieves strong performance increase over representative baselines. For instance, on Deblur-NeRF synthetic with 3 views:
- PSNR: 21.12 vs. BAD-Gaussians 19.58
- SSIM: 0.671 vs. BAD-Gaussians 0.555
- LPIPS: 0.195 vs. BAD-Gaussians 0.274
These gains are consistent and often amplified in real-data and outdoor settings, where generative-only baselines fail with geometric inconsistencies and standard deblurring or 3DGS methods severely oversmooth.

Figure 5: Qualitative NVS on DL3DV-Blur: CoherentGS maintains fine edge structure and correct geometry under severe outdoor motion blur.
Frequency and Geometric Consistency
Fourier domain analysis substantiates that CoherentGS, unlike diffusion-only or photo-supervised baselines, faithfully recovers the ground-truth spectral envelope, indicating physically plausible edge and texture distribution without introducing spurious periodic artifacts.
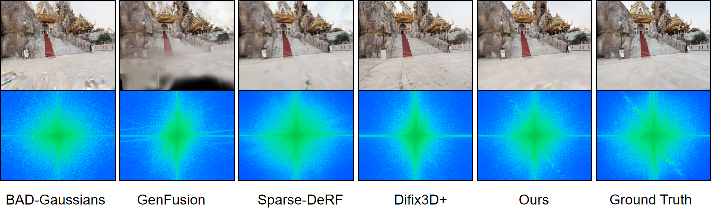
Figure 6: Frequency spectrum analysis demonstrates CoherentGS aligns with GT and avoids the grid-like hallucinations common in generative priors.
Explicit depth map visualization (see Supplementary, Figure 7) and ablation studies further confirm that the model’s improvements are not solely increases in perceptual quality but also consistently enhance 3D geometric coherence across views. Omitting the deblur or geometric prior, or using naively sampled viewpoint sets, creates clear artifacts or floating regions.
Ablation and Analysis
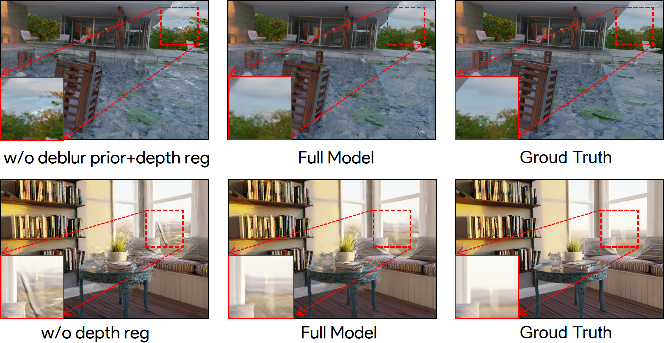
Figure 8: Supervised signal ablation: all major priors and regularization terms are crucial for the observed coherent improvement.

Figure 9: SACN sampling provides view diversity with improved geometric and appearance consistency relative to standard strategies.
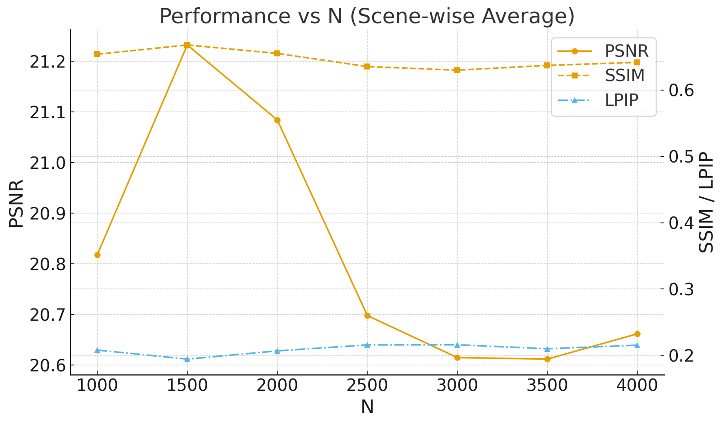
Figure 10: Warm-up length analysis for generative prior injection shows stable transition and peak quality at N=1500 iterations.
Practical and Theoretical Implications
Practically, CoherentGS makes it feasible to reconstruct coherent, detailed 3DGS scenes from drastically undersampled and motion-degraded imagery—pushing Gaussian Splatting into realistic, in-the-wild acquisition domains where dense videos are not achievable.
Theoretically, the results support several key conclusions:
- Explicit integration of task-specialized priors (not merely data-augmented supervision) is necessary to break the degeneracies induced by simultaneously sparse and blurred input, as current photometric and generative priors alone fail.
- Geometric repair in generative models becomes tractable when supported by photometric deblurring and viewpoint selection mechanisms that maximize the informativeness and consistency of distillation signals.
- The physically-accurate modeling of camera exposure and integrating trajectory estimation within generative 3D optimization is essential for disentangling structural and appearance ambiguity.
Looking forward, the modular architecture outlined here can be extended to additional forms of degradation (e.g., defocus, lighting artifacts) by including specialized generative priors. Scene-adaptive reliability metrics open avenues for active viewpoint selection in both data acquisition and online adaptation.
Conclusion
CoherentGS (2512.10369) establishes a formal, experimentally validated framework for novel view synthesis under severe degradation. By marrying deblurring, diffusion-based geometric completion, and adaptive viewpoint sampling, it sets a new standard for practical robustness and quality in explicit 3DGS representations. Its architectural principles—including dual semantic and geometric generative priors, perceptual distillation, and reliability-aware viewpoint planning—provide a general template for robust neural field modeling under real-world constraints.