- The paper introduces MaxRM in random forests by optimizing worst-case risk to achieve robust performance across heterogeneous environments.
- It reformulates leaf value assignments via convex optimization using post-hoc, local, and global strategies to minimize risks like MSE, negative reward, and regret.
- Empirical results on simulations and California housing data show that MaxRM-RF outperforms standard random forests and competing GDRO methods under distribution shifts.
Maximum Risk Minimization with Random Forests: Robust Learning under Heterogeneous Environments
Random forests (RFs) are highly effective for regression across a diverse range of noise settings but generally operate under the pooled empirical risk minimization (ERM) framework, which assumes i.i.d. data. This assumption fails in out-of-distribution (OOD) regimes—specifically, when data are partitioned into multiple environments, each following potentially different marginal and conditional distributions. OOD generalization aims to ensure robust performance on test data whose distribution may differ from those observed during training.
This work formalizes OOD robustness by minimizing the maximum risk across all training environments—a principle referred to as Maximum Risk Minimization (MaxRM). While MaxRM aligns with distributionally robust optimization (DRO) and group DRO (GDRO) formulations, most prior efforts focus either on parametric linear models or deep neural networks, both with limitations: the former lacks model flexibility and the latter is vulnerable to architectural and hyperparameter choices, especially in the regression setting.
The authors propose novel, computationally efficient variants of random forests that directly target MaxRM objectives using several risk functions: mean squared error (MSE), negative reward (NRW, closely related to explained variance), and regret (i.e., excess risk relative to the best predictor in the class). The paper delivers theoretical guarantees, including new consistency and generalization results for regret-based MaxRM, and demonstrates substantial empirical advantages over both GDRO (with neural networks) and magging estimators in simulation and real data.
Random Forests under MaxRM: Algorithmic Advances
MaxRM-Based Tree Construction and Post-Hoc Adjustment
Standard RFs grow trees by minimizing pooled MSE, assigning constant leaf values equal to local empirical means. The key innovation here is to replace this pooled assignment with an optimization targeting the maximum risk across environments. For a fixed tree structure, determining optimal leaf values under MaxRM is formulated as a convex optimization problem. The constraints are quadratic and can be efficiently solved via second-order cone programming (SOCP), e.g., by interior-point solvers or, for very large instances, via extragradient or block-coordinate descent algorithms.
Three approaches to incorporate MaxRM are detailed:
- Post-hoc adjustment: Assign traditional partitions, then re-optimize all leaves to minimize the maximum risk (MaxRM-RF-posthoc).
- Local strategy: After each split, immediately optimize only the new leaves (efficient for moderate K).
- Global strategy: Jointly re-optimize all leaf values after each split (more expensive, marginal empirical benefit).
Tree weights in the ensemble can also be learned according to the MaxRM principle, but empirical benefits are minimal due to sample-splitting requirements that reduce tree accuracy.
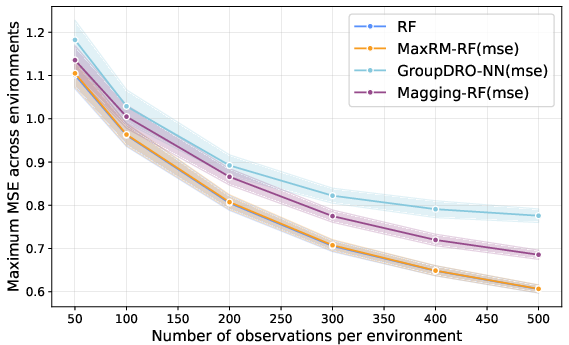
Figure 2: Maximum MSE across test environments when all environments are identical, so MaxRM and ERM objectives coincide and MaxRM-RF matches the pooled RF baseline.
Theoretical Guarantees
The authors rigorously establish that, for MSE, NRW, and regret risk functions, minimizing the max risk across training environments is statistically equivalent to minimizing the worst-case risk over the convex hull of the corresponding environment-specific distributions. Theoretically, this ensures that MaxRM estimators are optimal under any convex combination of observed environments at test time—a direct generalization of group DRO results but now extended to complex, nonparametric forests with piecewise-constant partitioning.
They also provide a consistency result for the empirical MaxRM-RF estimator, proving convergence of post-hoc adjusted leaf values to the population min-max solution under mild, standard regularity assumptions.
Numerical Results: Simulations and Real Data
Simulation Studies
A comprehensive battery of experiments explores robustness and practical performance:
- Model selection among MaxRM-RF variants: Post-hoc adjustment offers nearly identical max-risk performance relative to more computationally expensive local/global strategies while being dramatically faster; adding tree weight learning brings minimal benefit.
- Robustness under OOD shifts: MaxRM-RF delivers the lowest worst-case MSE across a variety of OOD shifts—when either only the conditional PeY∣X or both conditional and marginal PeX distributions vary across environments. MaxRM-RF reliably outperforms both GDRO (neural network-based) and magging-based estimators, especially when PeX changes invalidate the convex aggregation structure needed for magging.
- Consistency in the i.i.d. regime: In the absence of distribution shift (identical environments), MaxRM-RF collapses to the standard RF solution, demonstrating no loss compared to ERM (see Figure 1).
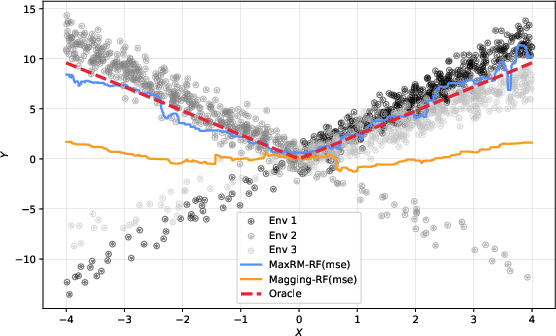
Figure 4: Three-environment data with different covariate distributions; MaxRM-RF outperforms magging and recovers the oracle under covariate shift.
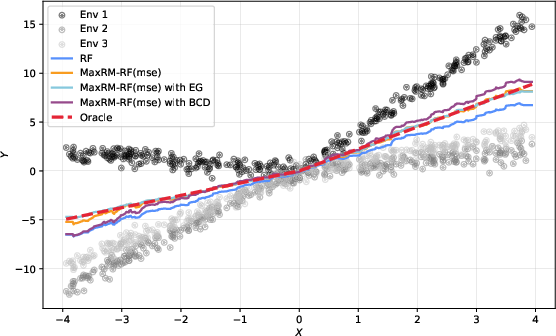
Figure 6: MaxRM-RF variants fit the oracle more closely than RF or magging; block-coordinate descent accelerates computation for large forests.
Real-World Application: California Housing Data
On a real dataset comprising California housing block groups, environments are defined according to counties (see Figure 7). Methods are evaluated in worst-case cross-validation: for each fold, trained on 20 counties and evaluated on five held-out ones.
MaxRM-RF consistently yields the lowest maximum test MSE in 4 out of 5 cross-validation folds (statistically significant in three cases). Magging and group DRO confer no observable advantage over vanilla RF, especially since their theory does not account for non-invariant PeX. The county-by-county error matrix (not shown here) exposes non-uniform transferability between environments, explaining the observed performance differences.
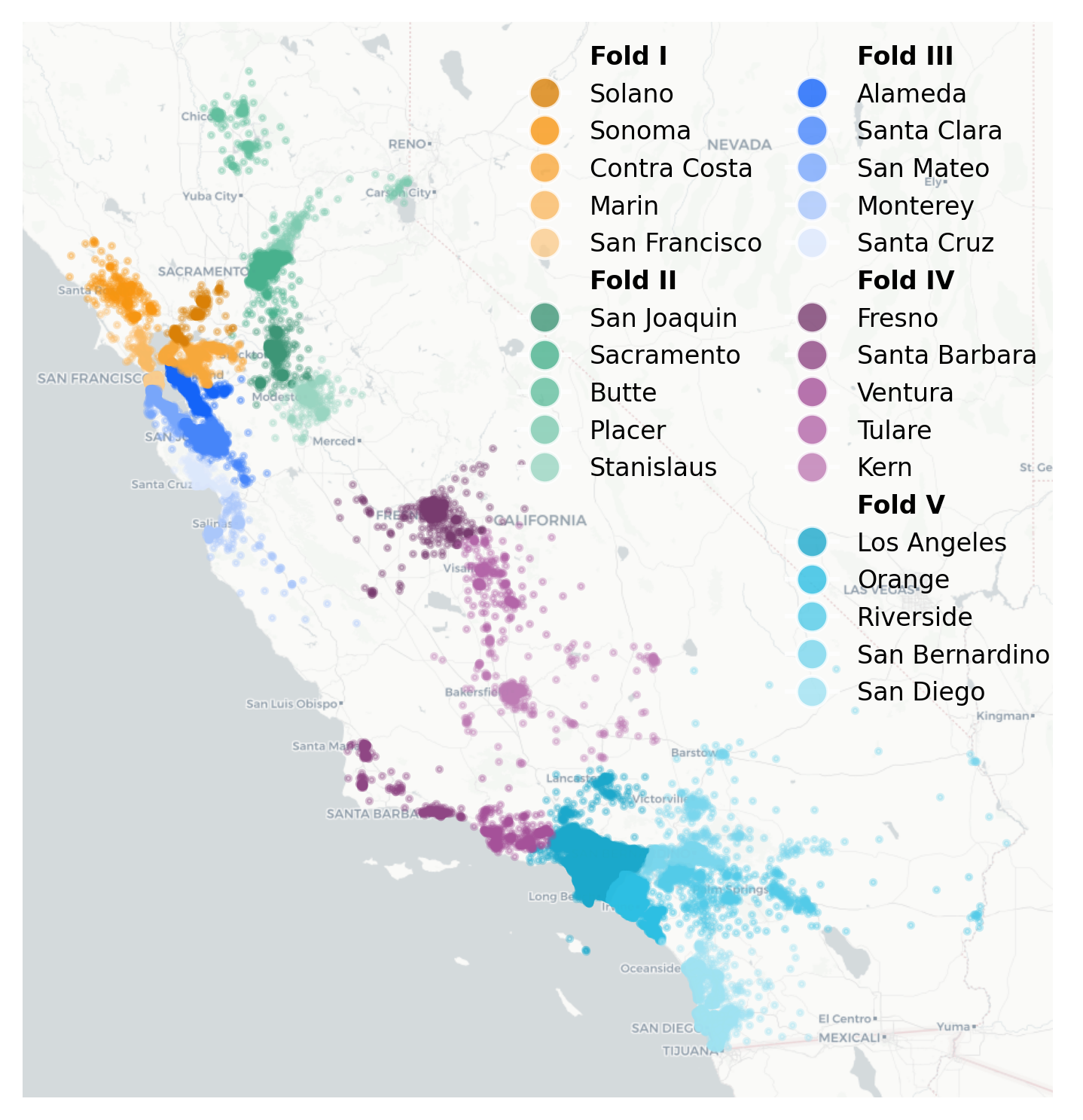
Figure 8: County-wise partition of CA housing data, spatial folds indicated by color.
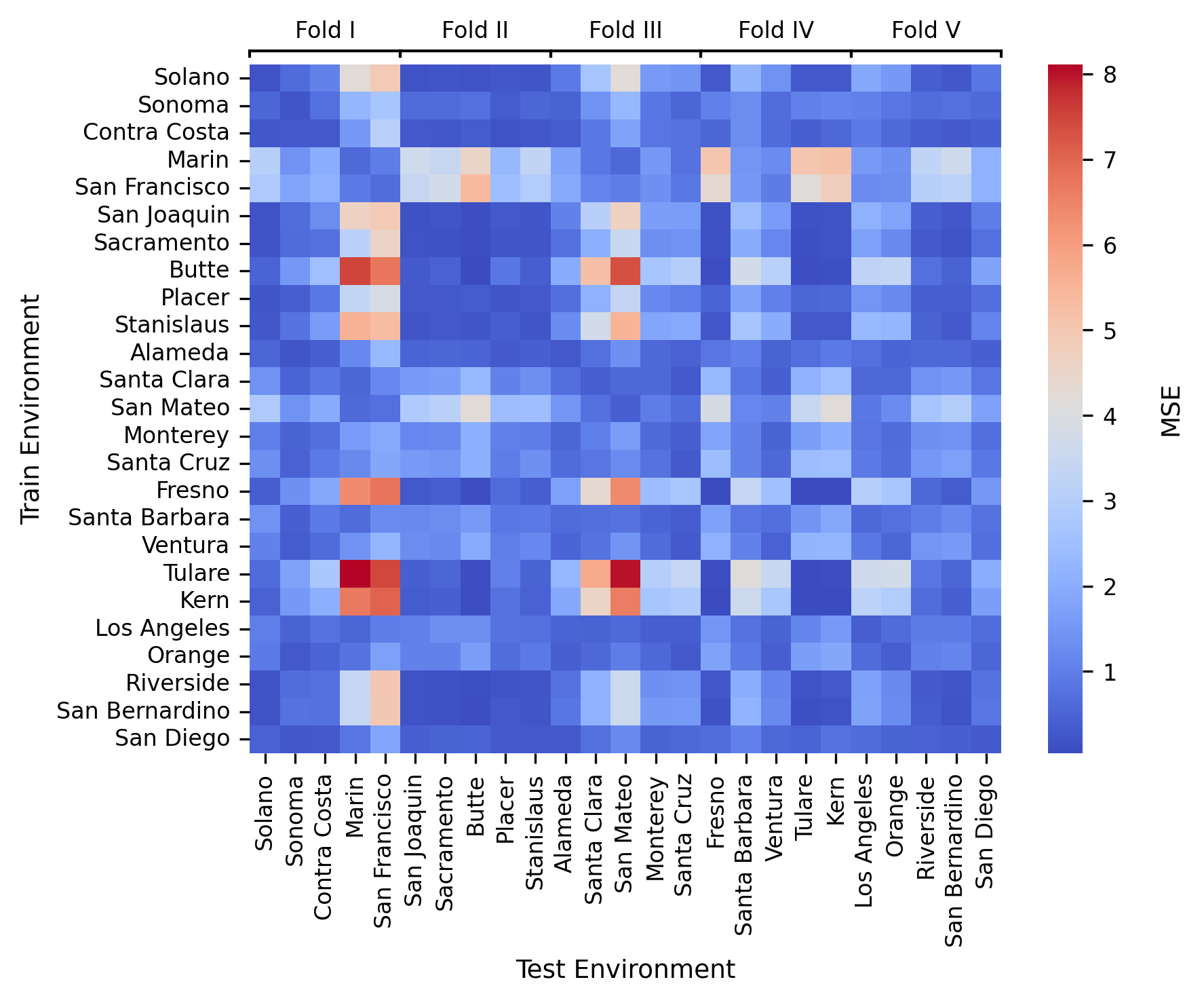
Figure 1: Matrix of train-on-A, test-on-B MSE; some counties are much harder to predict, motivating worst-case-aware MaxRM methods.
Empirical Robustness to Hyperparameters
A hyperparameter sweep confirms that MaxRM-RF delivers inferior max-risk across a broad spectrum of choices (e.g., mtry, tree depth, minimal leaf size), indicating that its robustness is not incidental to tuning, but emerges from the objective.
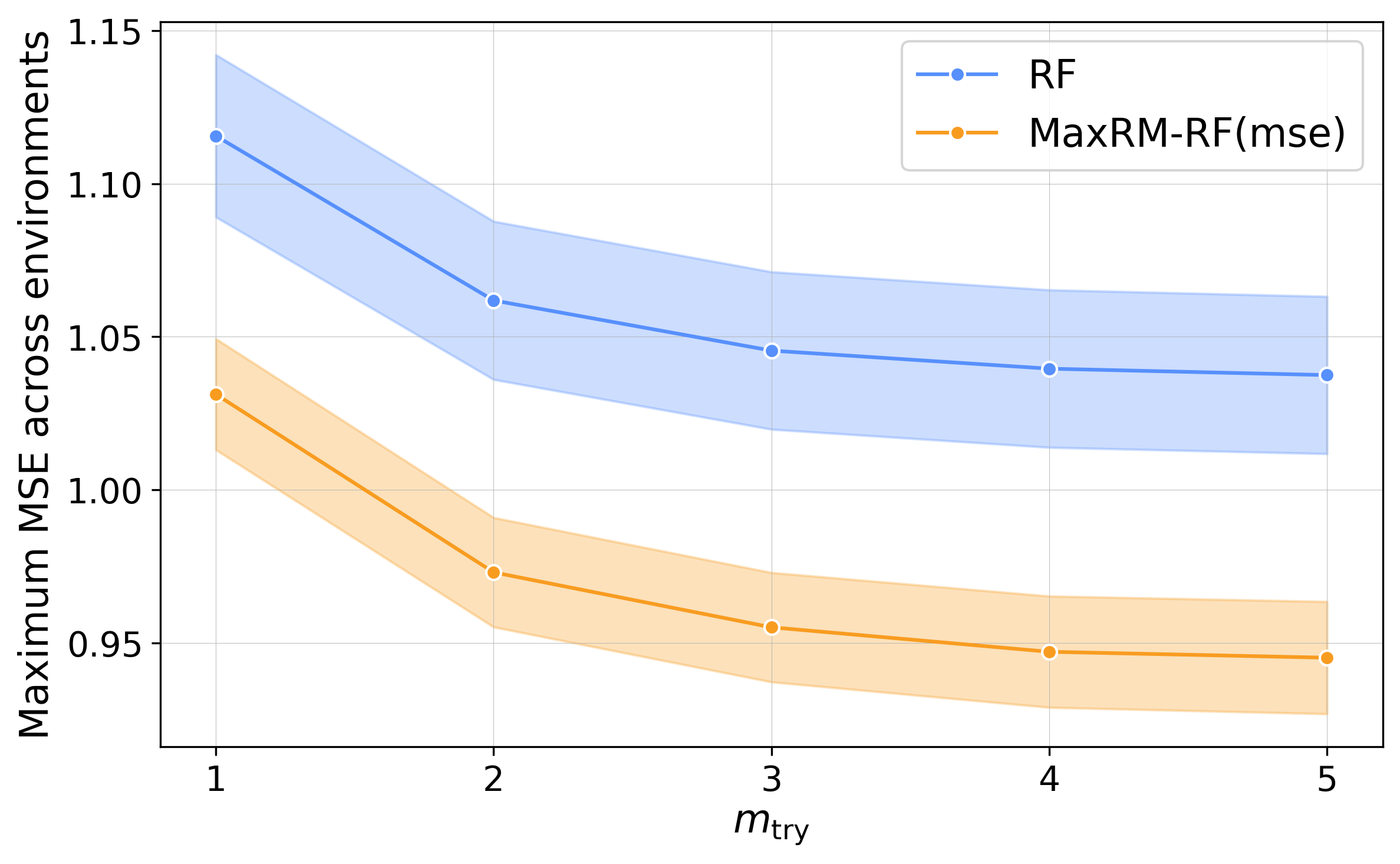
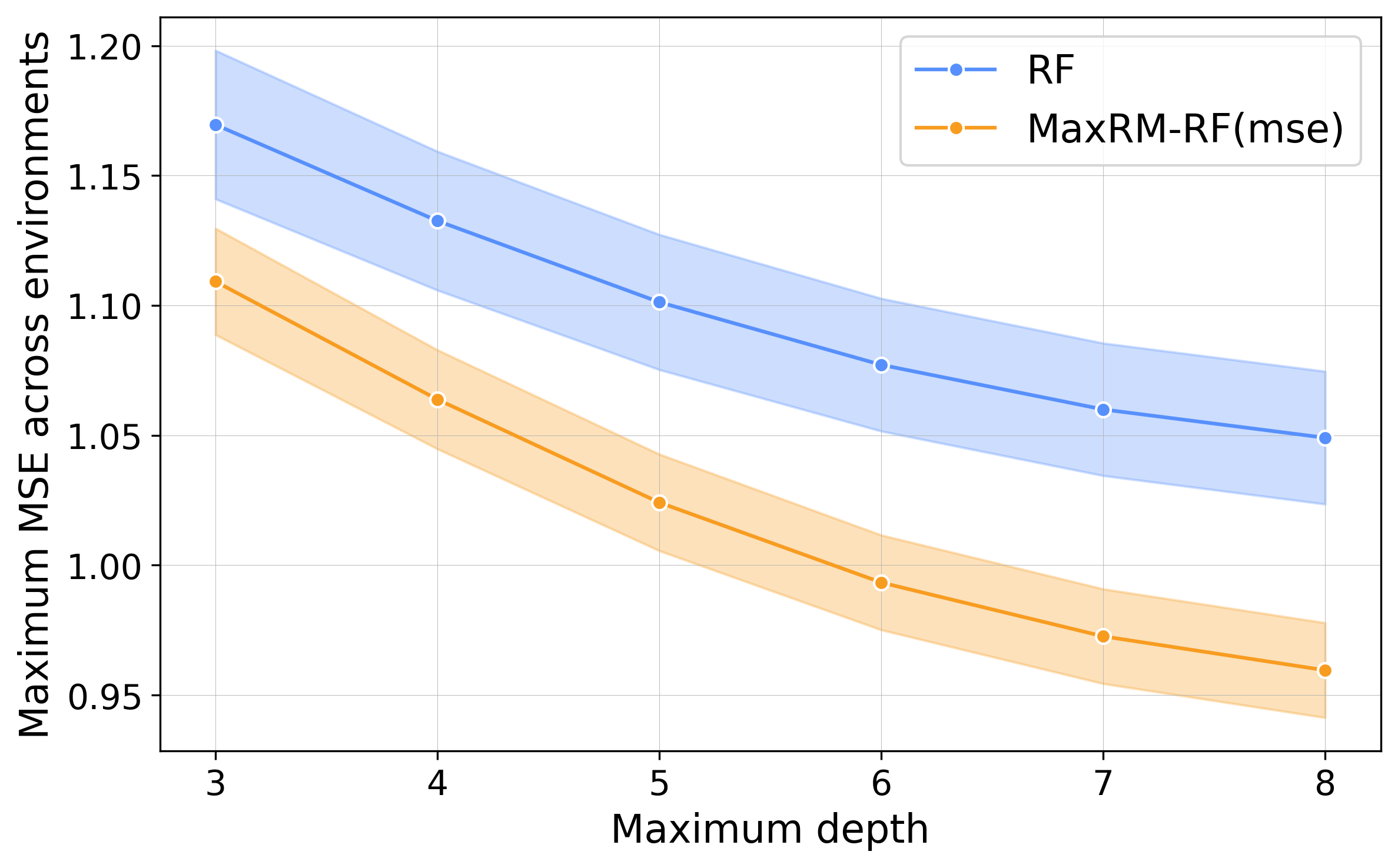
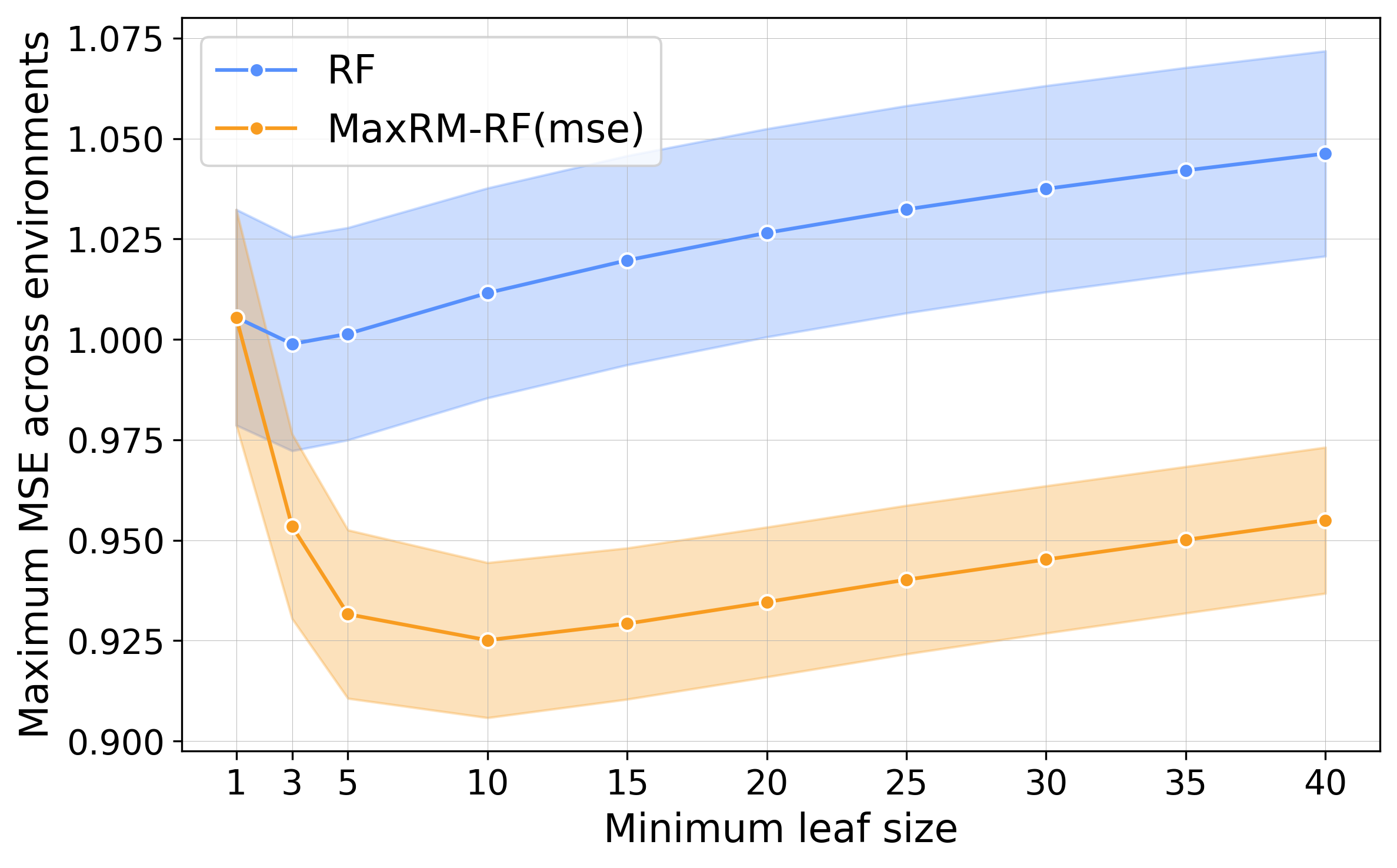
Figure 7: MaxRM-RF robustly outperforms RF in max MSE for all hyperparameter settings, indicating solution stability.
Implications and Future Directions
Theoretical
- Extension of MaxRM theory to nonparametric ensembles under highly flexible, partition-based regression models.
- (Novel) population and finite-sample guarantees for regret-based max-risk minimization in forests, complementing prior work restricted to parametric or ERM objectives.
Practical
- MaxRM-RF provides a principled and computationally viable approach to robust regression under distribution shift, particularly for cases with high environmental heterogeneity (e.g., multisite biomedical and geospatial data).
- Unlike magging, MaxRM-RF is not restricted by the constancy of PeX, enabling broader deployment in realistic, non-i.i.d. population structures.
Limitations and Prospects
While MaxRM-RF demonstrates significant empirical success and theoretical support for regression tasks, adapting such methodology to classification (cross-entropy or multiclass objectives) introduces nonlinearity that may challenge SOCP-based optimization. The authors suggest that mirror-prox or other first-order methods could be promising for further research. Additionally, separating step sizes in extragradient algorithms may yield computational improvements.
Conclusion
The MaxRM random forest methodology provides a statistically grounded and empirically superior solution for OOD-robust regression. By integrating the MaxRM principle with the representational power and computational scalability of RFs, this framework delivers optimal worst-case guarantees under arbitrary convex combinations of training environments—crucial for applications with heterogeneous, multi-domain data. Theoretical extensions to broader risk classes and future adaptations to classification remain compelling avenues for future work.