- The paper introduces a hierarchical latent variable causal model that formalizes compositional generalization through modular, transferable components.
- It demonstrates that sparse, invariant causal mechanisms enable robust analogical transfer in text-to-image generation using diffusion models.
- Empirical results and ablation studies confirm that hierarchical conditioning and sparsity regularization significantly enhance compositional fidelity.
Learning by Analogy: A Causal Framework for Composition Generalization
Introduction and Context
Compositional generalization is central to human and machine intelligence, involving the ability to extrapolate and synthesize novel concept combinations from limited experience. The work "Learning by Analogy: A Causal Framework for Composition Generalization" (2512.10669) introduces a rigorous formalization of this ability, leveraging principles from causal inference. The authors propose that compositional generalization depends on two intertwined mechanisms: decomposition of high-level concepts into modular, low-level components and the re-use of these components across contexts inspired by human analogical reasoning.
The primary contributions are: (1) a hierarchical latent variable causal model for data generation, (2) formal conditions under which such structure supports compositional generalization, (3) theoretical identification guarantees for learning these latent structures from observed data, and (4) implementation of these insights within diffusion models for text-to-image (T2I) generation, demonstrating significant empirical gains.
Causal and Hierarchical Foundations of Composition
The proposed hierarchical data-generating process formalizes the intuition that high-level combinatorial concepts (e.g., "peacock eating rice") can be generated by composing reusable low-level mechanisms learned from simpler contexts (e.g., "chicken eating rice" and "peacock"). The authors draw on the concepts of causal modularity—the invariance and transferability of causal mechanisms—and the minimal change principle—the idea that only minimal differences exist between related high-level concepts, enabling efficient analogical transfer.
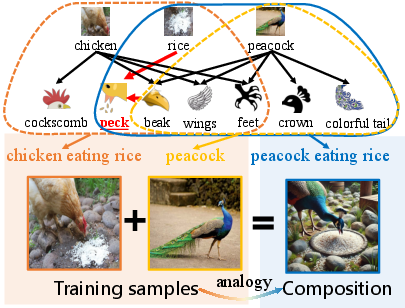
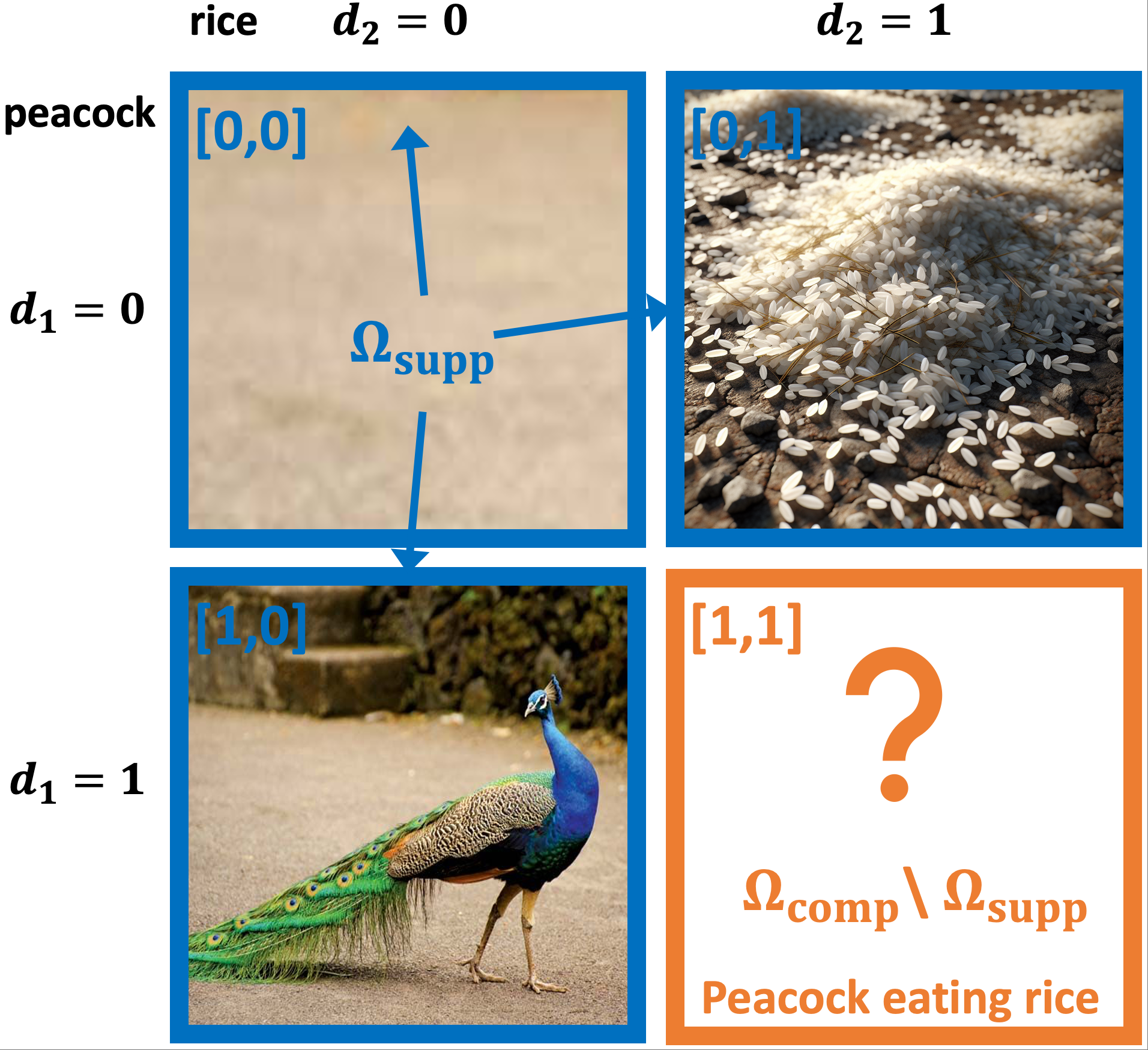
Figure 1: The compositional process by analogy, in which an unseen combination ("peacock eating rice") is synthesized by transferring low-level "beak {content} rice" interaction learned from "chicken eating rice".
This generative process is modeled as a hierarchy of latent variables, where the observable (e.g., an image) is the outcome of sequential transformations, each corresponding to a different conceptual level. The graphical representation is a directed acyclic graph mapping discrete high-level concept indicators (driven by text prompts) down to observable outputs via multiple latent layers that encode both basic and composed concepts.
Critically, this approach departs from previous work by permitting arbitrary (nonparametric) forms of interaction between concepts, overcoming the limitations of additive or polynomial-only interactions assumed by prior models [lachapelle2023additive, brady2024interaction].
Theoretical Claims: Composition and Identifiability
The authors delineate precise conditions under which their framework yields compositional generalization. They show, via a pivotal theorem, that a new concept composition is generatable if, for each latent module in the hierarchical graph, there exists a training example so that the parents’ configuration required for the new composition has already appeared in the data. This facilitates modular transfer even for complex, non-additive interactions.
Sparsity in the latent causal graph is theoretically shown to be essential: sparser graphs have fewer parental dependencies for each latent, meaning that new combinations require less overlap between previously observed configurations, thus supporting broader generalization. The minimal-change principle further supports this by ensuring that only a few modules differ between closely related high-level concepts.
The identification analysis is rigorous: under invertibility, smoothness, conditional independence, and sufficient variability conditions (standard in the nonlinear ICA literature), the latent variables and their inter-level graph structure can be provably recovered—up to permutation and invertible transformation—from observed data such as text-image pairs. This guarantees that empirically training models on observable data can yield the disentangled, modular latents needed for robust compositional generalization.
Practical Framework: HierDiff for T2I Compositionality
To operationalize these theoretical principles, the authors instantiate them within the HierDiff model, a modified diffusion-based T2I generator. The design integrates two crucial ideas:
- Hierarchical conditioning: At each diffusion step, only the information relevant for that conceptual level is injected; higher diffusion steps receive high-level (global) descriptions, whereas lower (denoised) steps receive fine-grained, low-level component descriptions, typically generated via LLMs parsing the global prompt.
- Sparse control via regularization: Cross-attention maps, mediating text-to-image alignment, are regularized during training to reduce overlap between attention regions corresponding to different low-level concepts, encouraging independence and minimizing crosstalk in the latent graph.
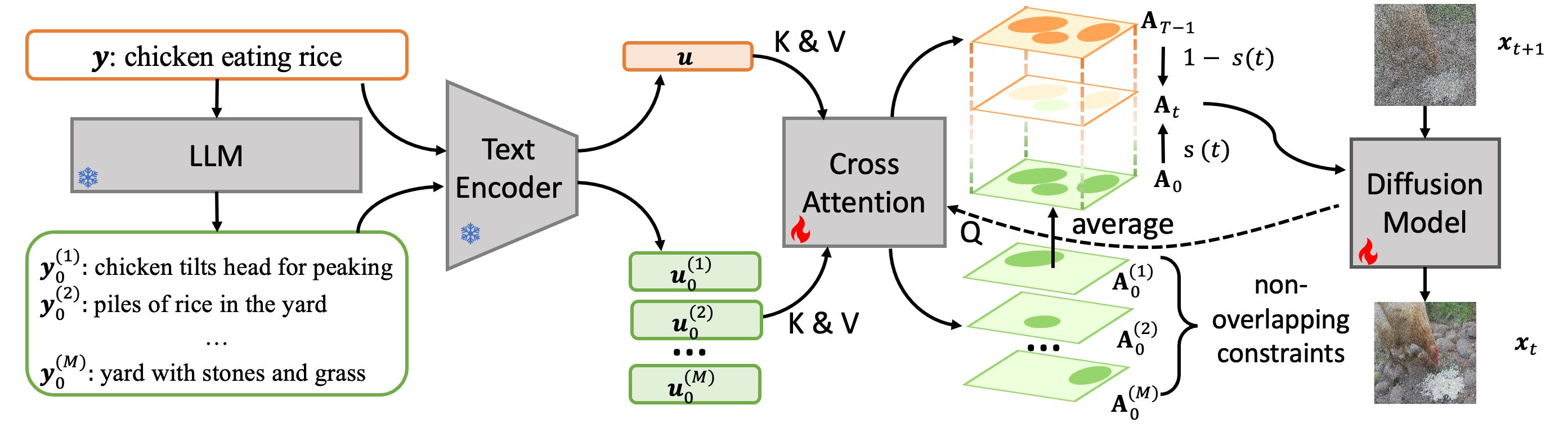
Figure 3: HierDiff decomposes high-level text into component-level descriptions, interpolates conditioning information across diffusion steps, and applies sparsity-promoting regularization on concept cross-attention maps.
This approach closely mirrors the theoretical insights: diffusion steps correspond to transitions across concept levels in the hierarchy, while sparsity regularization approximates the theoretical requirement for sparse latent causal graphs.
Empirical Results and Ablations
HierDiff demonstrates strong empirical results on established compositional T2I benchmarks, surpassing prior models on several fine-grained metrics reflecting global, entity, attribute, and relational fidelity.

Figure 2: HierDiff produces more semantically precise image generations, accurately reflecting distinguishing entities and relations from complex prompts.
Ablation studies highlight the criticality of both hierarchical conditioning (time-dependence) and sparsity regularization; removing either degrades performance, especially in relation and entity control settings.

Figure 4: Ablation results confirm that both time-dependent conditioning and sparsity constraints are essential for precise compositionality.
Visualization of attention maps over the diffusion trajectory indicates an emergent, stepwise localization and disentanglement of concept regions, verifying the intended correspondence with the hierarchical model.

Figure 5: Cross-attention maps become increasingly focused and less overlapping as the denoising process proceeds, corroborating hierarchically structured and sparse concept representations.
Implications, Limitations, and Outlook
This work directly addresses key open problems in causally-motivated compositionality research, reframing compositional generalization as a question of causal identifiability in hierarchical latent spaces. The nonparametric, modular approach removes stringent assumptions, and the linkage between theoretical identifiability and practical generation is explicit.
The implications are significant: diffusion models, when structured and regularized along hierarchically causal lines, can achieve robust and reliable compositional generalization, with LLMs assisting in modular concept decomposition. This bridges advances in causality, unsupervised representation learning, and generative modeling.
However, a limitation is that the conditional independence at each hierarchy level may not always hold in natural data; cross-level correlations or lateral dependencies may be necessary for some compositions. Potential avenues include richer latent graph structures or adaptive hierarchical depth.
Future AI systems may benefit from compositional architectures informed by these principles, not only for vision but for general sequence, planning, and reasoning domains. Further, advances in hierarchical causal discovery in high-dimensional generative models could yield more expressive and controllable models for learning and synthesis across modalities.
Conclusion
"Learning by Analogy: A Causal Framework for Composition Generalization" presents a unified theoretical and practical framework for composition in generative models. By modeling composition as identification and transfer in sparse, modular, hierarchical causal graphs, and tightly coupling these ideas to the architecture and learning dynamics of diffusion models, the work provides a clear, empirically validated, and extensible foundation for future advances in compositional machine intelligence.